推荐|xlearn:大规模稀疏数据的机器学习库,提速13陪!

在机器学习里,除了深度学习和树模型 (GBDT, RF) 之外,如何高效地处理高维稀疏数据也是非常重要的课题,Sparse LR, FM, FFM 这些算法被广泛运用在实际生产和kaggle比赛中。现有的开源软件例如 liblinear, libfm, libffm 都只能针对特定的算法,并且可扩展性、灵活性、易用性都不够友好。基于此,(北大马超博士)我在博士期间开发了 xLearn,一款专门针对大规模稀疏数据的机器学习库,曾在之前 NIPS 上做过展示。经过打磨,现开源 O网页链接。我们的 vision 是将 xLearn 打造成和 xgboost,MXNet一样的工业事实标准。相比于已有的软件,xLearn的优势主要有

(1)通用性好,我们用统一的架构将主流的算法(lr, fm, ffm 等)全部囊括,用户不用再切换于不同软件之间。

(2)性能好。xLearn由高性能c++开发,提供 cache-aware 和 lock-free learning,并且经过手工 SSE/AVX 指令优化。 在单机MacBook Pro上测试 xLearn 可以比 libfm 快13倍,比 libffm 和 liblinear 快5倍(基于Criteo CTR数据 bechmark)。
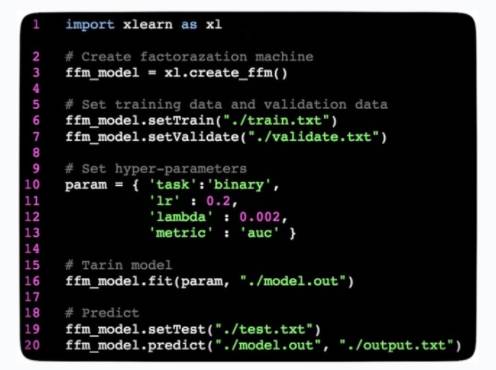
(3)易用性和灵活性,xLearn 提供简单的 python 接口,并且集合了机器学习比赛中许多有用的功能,例如:cross-validation,early-stopping 等。除此之外,用户可以灵活选择优化算法(例如,SGD,AdaGrad, FTRL 等)
(4) 可扩展性好。xLearn 提供 out-of-core 计算,利用外存计算可以在单机处理 1TB 数据。
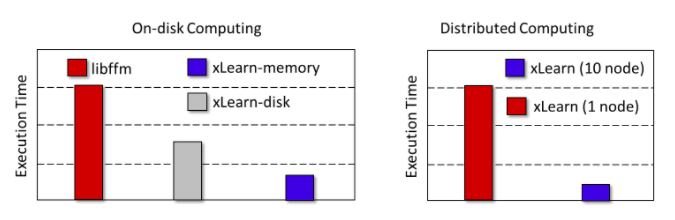
除此之外,xLearn 也提供分布式训练功能。这里我希望更多的朋友加入这个开源项目!
开源地址:https://github.com/aksnzhy/xlearn
招聘|AI学院长期招聘AI课程讲师(兼职):日薪5k-10k