嗯?DeepMind开了个心理学实验室

夏乙 允中 编译整理
量子位 出品 | 公众号 QbitAI
最近,DeepMind开了个心理学实验室,名叫Psychlab,地点就在DeepMind Lab里。
当然,不是为人类开的。

Psychlab所处的DeepMind Lab是个第一人称视角3D游戏世界,这个心理学实验室当然也是个模拟环境,研究对象是其中的深度强化学习智能体(Agents)。Psychlab能够实现传统实验室中的经典心理学实验,让这些本来用来研究人类心理的实验,也可以用在AI智能体上。
关于这个实验室,DeepMind刚刚公开了一篇论文:Psychlab: A Psychology Laboratory for Deep Reinforcement Learning Agents,在里边详细介绍了Psychlab的环境、API,还展示了一些示例任务。

他们在论文里说,有了Psychlab,就可以直接用认知心理学和视觉心理物理学的任务来测试,将深度强化学习智能体与人类做比较,这种比较可以丰富我们对智能体的理解,有助于优化智能体的设计。
那么,
Psychlab究竟什么样?
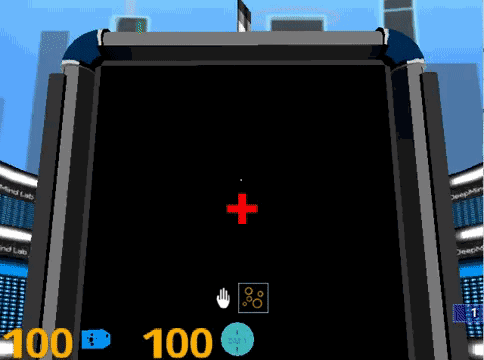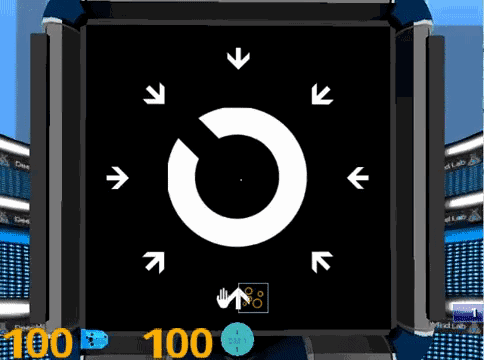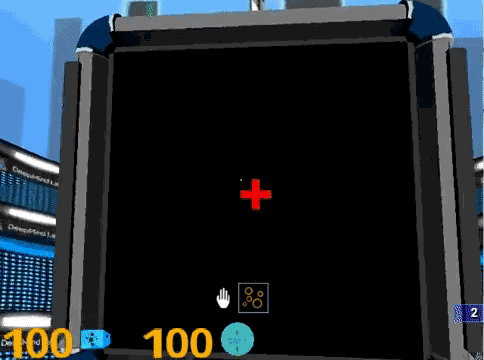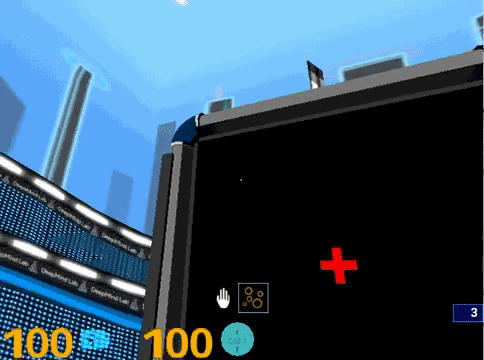
在Psychlab中,智能体站在一个平台上,面前摆着一个大屏幕,上面显示着刺激。这个智能体可以注视着屏幕,也可以环顾周围,看看地面看看天,都没有问题。

△ Agent在Psychlab中完成视觉搜索任务
就像上图所示,智能体的注视方向决定了画面显示的场景。①的智能体注视着屏幕中心,②和③的智能体都在搜索目标,④显示的是智能体找到了它的目标:洋红色的T。随着智能体注视方向的变化,屏幕上显示出它的不同视野。和你玩《使命召唤》时的视野变化差不多。

除了盯着屏幕找目标,智能体在这个实验室里还能干什么呢?DeepMind自己在论文中展示了8种任务:

△ Psychlab中的各种任务
为了与常见的行为测试方法保持一致,所有Psychlab的任务都被分割成离散的测试。这些测试也是基本的分析单位。在DM-Lab环节可以进行任意数量的测试,试验次数、时间等都可以自行配置。所有的测试都是通过注视屏幕中心的红十字来启动的。
下面,我们来看看Psychlab中这些测试任务的实例。
1. 持续识别,判断面前的物品是否曾经出现过,新的就往左看,旧的就往右看。
2. 任意的视觉映射,面前出现一个物体和四个标签,标签中只有一个是绿色。下次这个物体再出现的时候,要判断出对应的绿色标签在哪个位置。
3. 变化检测,判断前后出现的两组图,是否发生了变化。
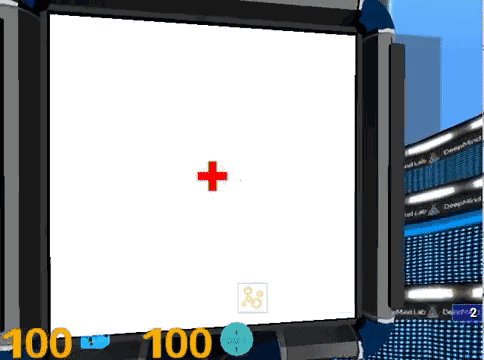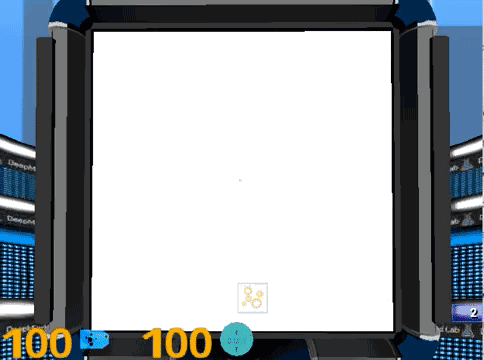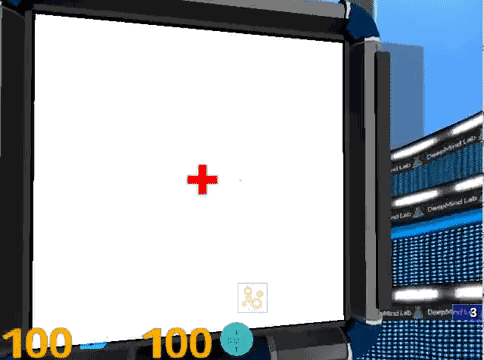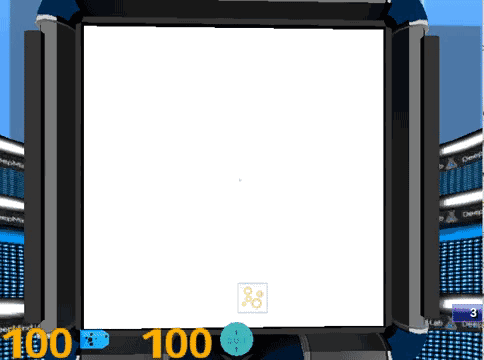
4. 视力和对比敏感度测试 (Landolt C)。画面中间有一个C型环,被测试者需要指出缺口的方向,C型环会不断的变小,对比度也会不断降低。
5. 玻璃图案测试,要判断两个图案中,哪一个是同心的玻璃图案。
6. 视觉搜索,在一堆物体中发现要寻找的目标。

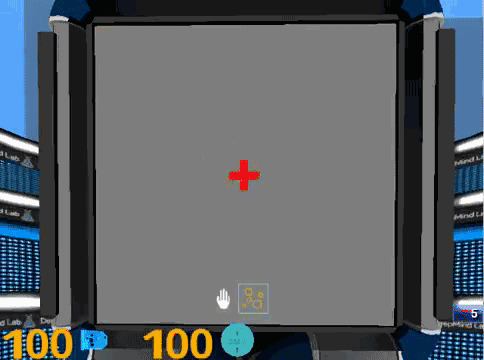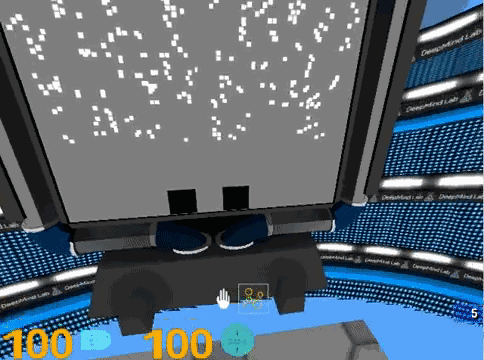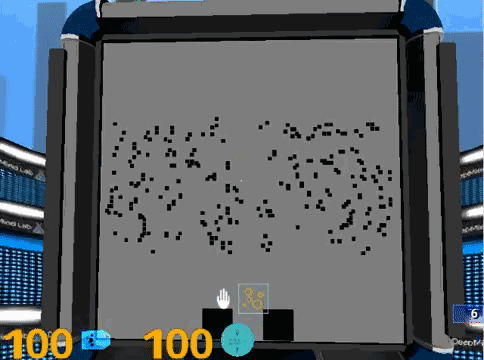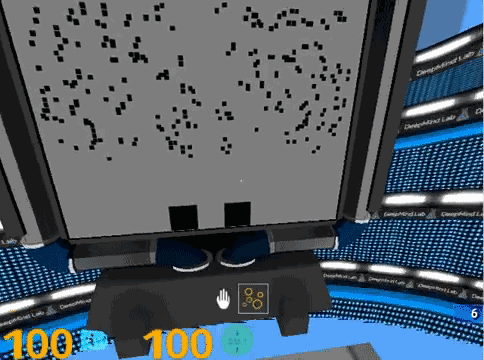
7. 随机点运动方向判断,画面中间的圆形区域,会出现大量的随机点,你需要指出主要的运动方向。随机点运动速度特别快的时候,真是一个挑战。
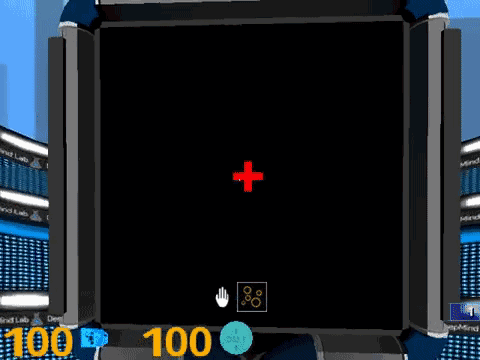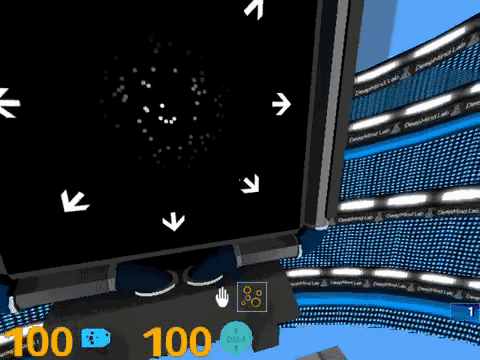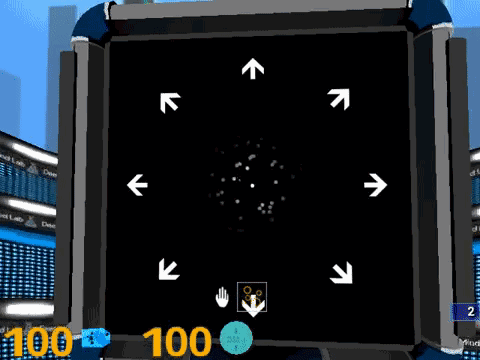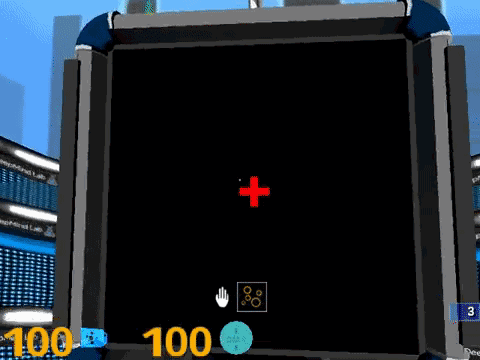
8. 多对象追踪。画面中有一组两种颜色的小球,随后全部变成统一颜色并开始移动,最后指定一个小球,你要判断原来这个球的颜色是什么。
其实看完这些任务,量子位很想说:
这……会不会有点为难AI了?
不过DeepMind在论文中说,既然深度强化学习智能体连“去找蓝色气球”这种自然语言指令都能听懂了,可见智商还不错,是时候把这些心理物理学、认知心理学领域实验方案拿出来让它们领教一下了。
为了让更多同行创造更多任务来给AI领教,DeepMind开放了一个Psychlab API。这个API是在lua中编写的一个简单的GUI框架,把部件(widget)放在Psychlab中的虚拟屏幕上,就可以创建任务。
这些小部件可以是任意的视觉形象,在事件发生时,比如当智能体的注视中心进入或离开小部件区域,小部件会调用回调。这个框架还支持在完成时使用定时器来调用回调。
在实验中,智能体也会获得奖励。当正确完成实验,智能体获得的奖励为1,其他步骤为0。
DeepMind建立这个“实验室”,是为了在心理学和现代人工智能之间建立一个联系点,这样,心理学找到了一种验证认知理论的新模式,而AI研究获得了更多能分离出认知核心方面的任务。
我们前面也说过,这样的研究有助于优化智能体的设计。空口无凭你大概不信,于是DeepMind又举出了一个栗子:一个Jaderberg等人2016年提出的非常厉害的智能体UNREAL,就可以用这些心理学测试来改进。
为了测试UNREAL智能体的视觉敏感度,DeepMind用上了上文列举的第4、5、6项测试:Landolt C。
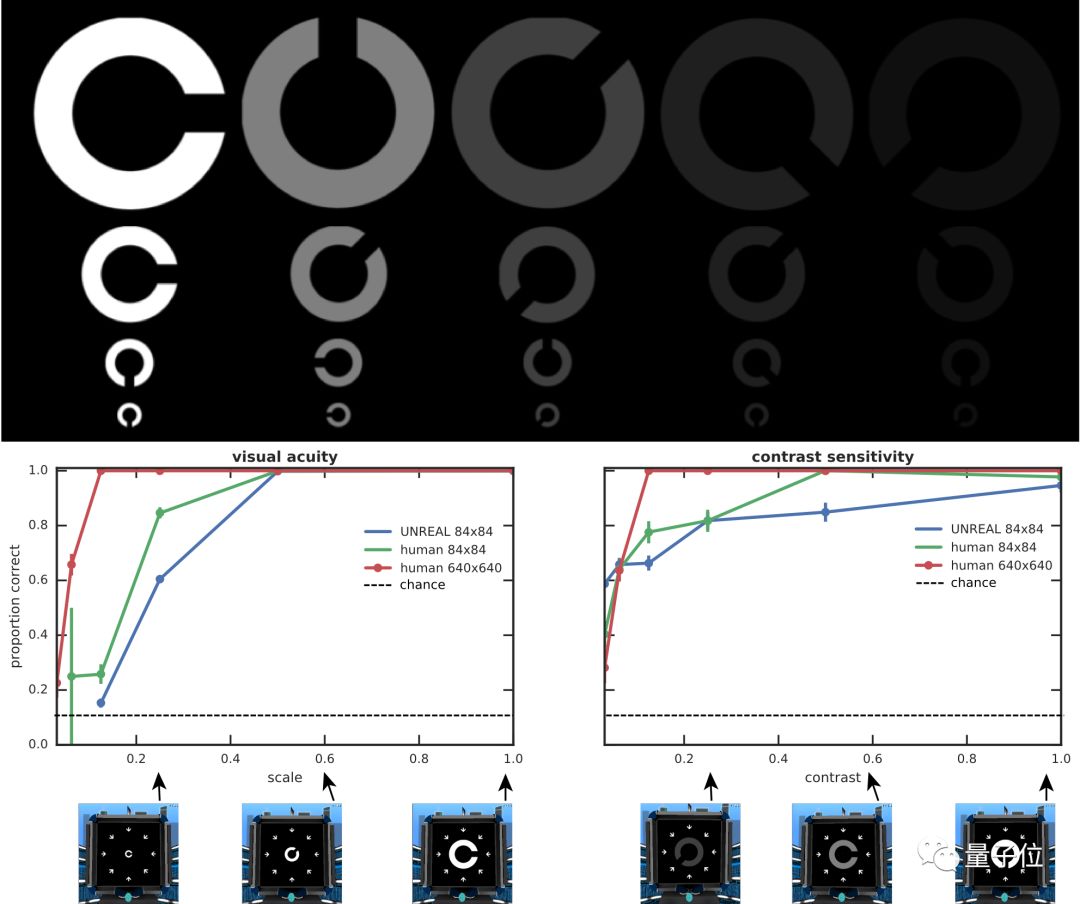
△ UNREAL和人类视觉敏感度的比较
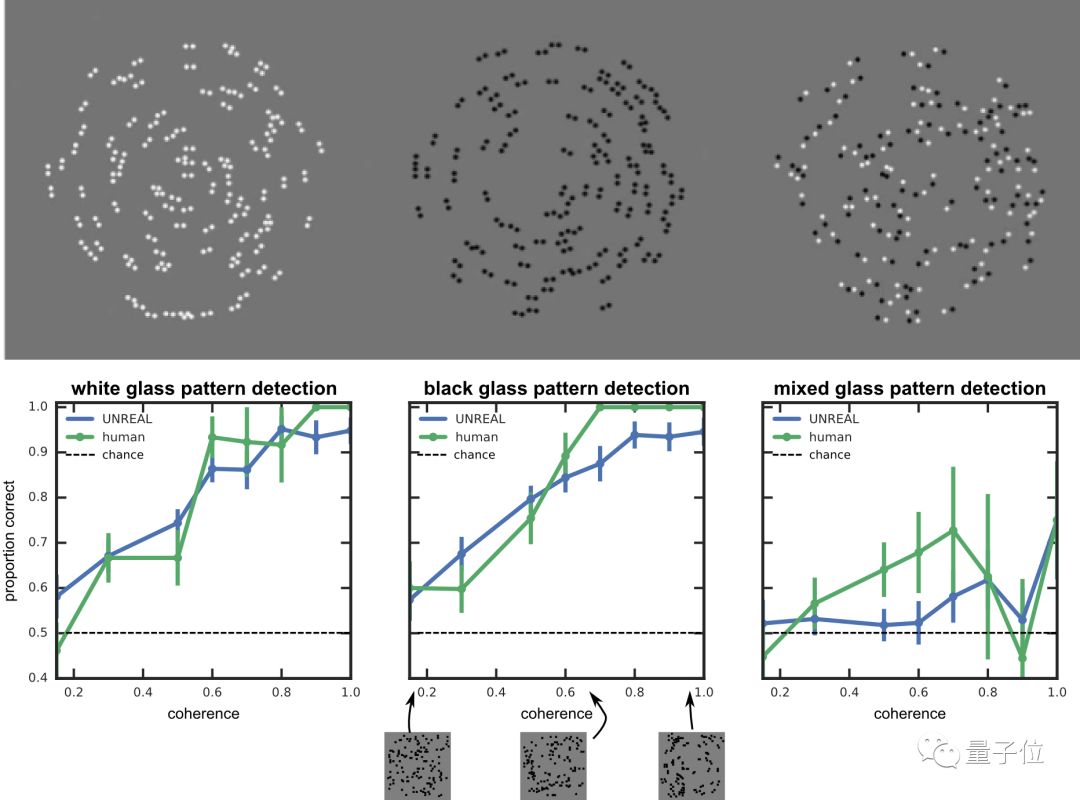
△ 在玻璃图案测试中,UNREAL和人类的心理测量曲线
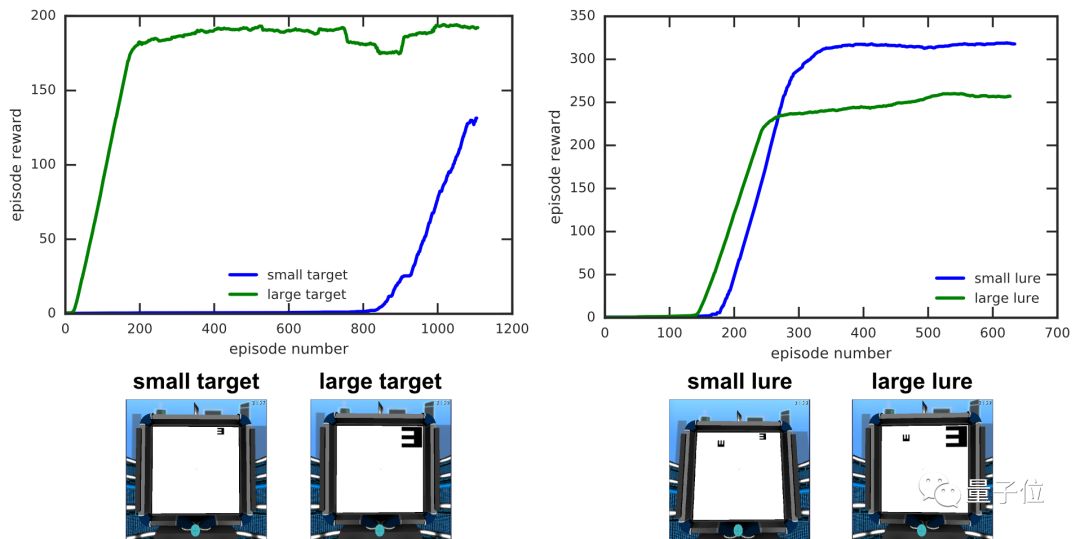
△ 在指向目标任务中,UNREAL对目标和诱饵的大小非常敏感,目标大时学习速度要快得多,诱饵大时最终性能不太理想
种种实验表明,UNREAL会更快地学习大的目标刺激,这种发现也带来了对一个简单的中央凹视觉模型的具体改进,显著提高了UNREAL在Psychlab任务和标准DeepMind Lab任务上的表现。
Psychlab这篇论文作者也不少,包括Joel Z. Leibo, Cyprien de Masson d’Autume, Daniel Zoran, David Amos, Charles Beattie, Keith Anderson, Antonio García Castañeda, Manuel Sanchez, Simon Green, Audrunas Gruslys, Shane Legg, Demis Hassabis, Matthew M. Botvinick,全部来自DeepMind。
如果你也想用一下这个Psychlab……论文里的确提到了是在DM-Lab里开源了的,不知更新出来没有,找到的同学吱一声儿~
https://github.com/deepmind/lab
论文地址:
https://arxiv.org/abs/1801.08116
目前有10000+人已关注加入我们,欢迎您关注






