更安心的 TensorFlow:全新隐私测试库现已推出!

文 / Shuang Song 和 David Marn
近日我们在 TensorFlow Privacy (GitHub) 中推出一个全新的实验性模块,可用于评估分类模型的隐私属性。
TensorFlow Privacy
https://github.com/tensorflow/privacyGitHub
https://github.com/tensorflow/privacy/tree/master/tensorflow_privacy/privacy/membership_inference_attack
隐私是机器学习社区中的新兴话题。虽然目前在生成私有模型方面尚未形成规范的指导原则,但越来越多的研究表明,机器学习模型有时会泄漏训练数据集的敏感信息,从而给训练集中的用户带来安全隐患。
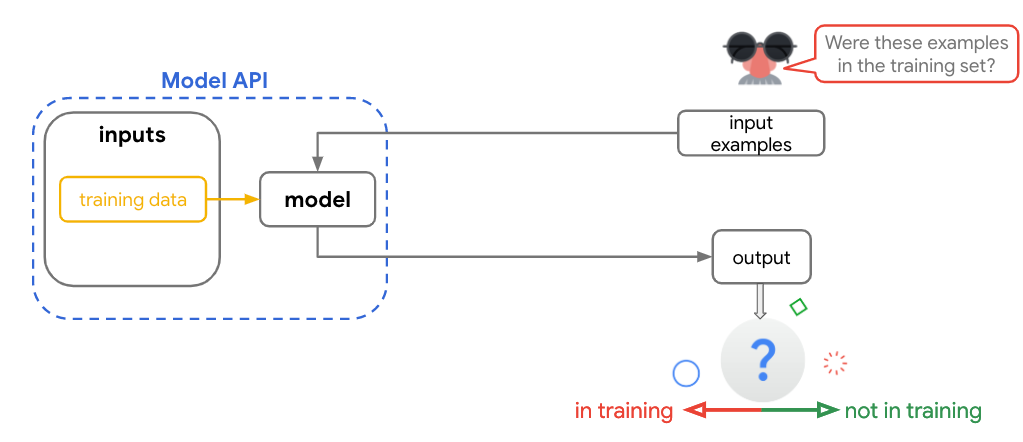
去年,我们推出了 TensorFlow Privacy,支持开发者使用差异化隐私 (Differential Privacy) 来训练模型。差异化隐私通过增加噪音 (Noise) 隐藏训练数据集中的单个示例。但是,该噪声是专为应对学术上的最坏假设情况而设计的,在实际训练中可能会严重影响到模型准确性。
差异化隐私
https://developers.googleblog.com/2019/09/enabling-developers-and-organizations.html
这些挑战使得我们尝试从另一个角度应对隐私问题。数年前,围绕机器学习模型隐私属性的研究开始出现。
具有成本效益的 “成员推理攻击 (Membership Inference Attacks)” 可预测在训练期间是否使用了某些特定数据。如果攻击者能够进行高精度的预测,那么很可能也会成功找出训练集中是否使用了某段数据。成员推理攻击的最大优势是易于执行,即无需进行任何重新训练。
测试生成的漏洞分数,可用于确定模型是否会从训练集中泄漏信息。我们发现,漏洞分数通常可通过启发式方法降低,例如提早停止训练或使用 DP-SGD 进行训练。
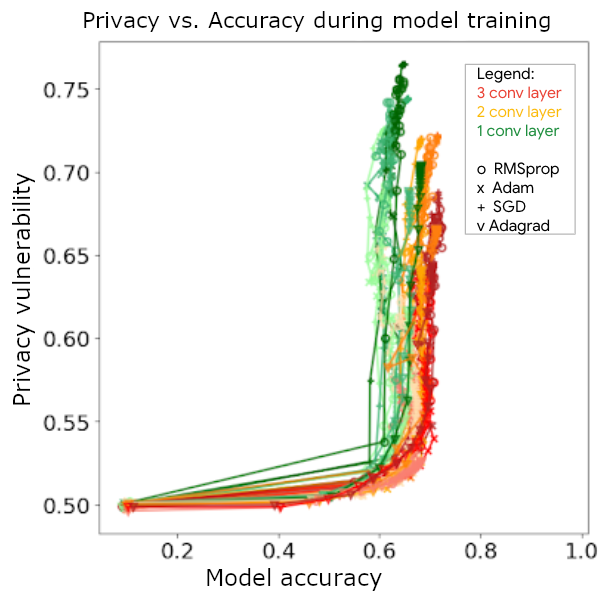
对 CIFAR10 模型的成员推理攻击:x 轴表示模型的测试准确率,而 y 轴表示漏洞分数(分数越低代表隐私性越高)。在测试准确率保持不变的情况下漏洞增加,因此提高泛化能力可防止隐私泄漏
毋庸置疑,差异化隐私可帮助降低此类漏洞分数。即便只有少量噪声,漏洞评分也会降低。
在内部使用成员推理测试后,我们将与开发者分享测试结果来帮助他们构建隐私性更高的模型、探索更好的架构选择、使用正则化技术(如提早停止训练、dropout、权重衰减和输入增强)或收集更多数据。最终,此类测试将帮助开发者社区找到更多融入隐私设计原则和数据处理选项的基础架构。
我们希望能够以这个库为起点,开发出强大的隐私测试套件,并将其分享给世界各地的所有机器学习开发者。未来,我们将探讨将成员推理攻击扩展到分类器之外的可行性,并开发新的测试。我们还将探索将之与 TFX 集成,并融入到 TensorFlow 生态系统中。
TFX
https://tensorflow.google.cn/tfx
请发送邮件至 tf-privacy@google.com,告诉我们使用这个新模块的感受。期待着收到您的故事、反馈和建议!
致谢
Yurii Sushko、Andreas Terzis、Miguel Guevara、Niki Kilbertus、Vadym Doroshenko、Borja De Balle Pigem、Ananth Raghunathan。



了解更多请点击 “阅读原文” 访问 GitHub。
🌟将我们设为星标
第一时间收到更新提醒
不再错过精彩内容!

分享 💬 点赞 👍 在看 ❤️
以“三连”行动支持优质内容!



