微服务在微信的架构实践

相关阅读:
首先,我们需要敏捷开发。过去几年,微信都是很敏捷地在开发一些业务。所以我们的底层架构需要支撑业务的快速发展,会有一些特殊的需求。
另外,目前整个微信团队已经有一千多人了,开发人员也有好几百。整个微信底层框架是统一的,微信后台有千级模块的系统。比如说某某服务,有上千个微服务在跑,而集群机器数有几万台,那么在这样的规模下,我们会有怎么样的挑战呢?
我们一直在说“大系统小做”,联想一下,微服务与腾讯的理念有哪些相同与不同的地方呢?通过对比,最终发现还是有许多相通的地方。所以我挑出来讲讲我们的实践。
看过过去几个会议的内容,可能大家会偏向于讲整一个大的框架,比如整个云的架构。但是我这边主要讲的是几个特殊的点。
开始看一下我们的结构。全球都有分布,主要有上海、深圳、香港、加拿大几个数据中心。
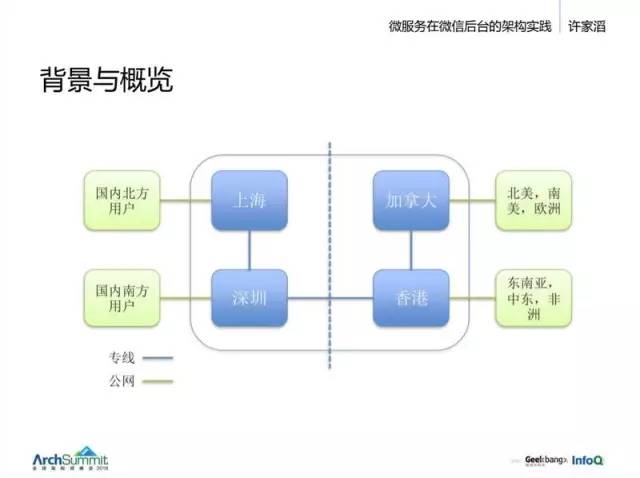
其中上海服务国内北方的用户,深圳负责南方用户,加拿大服务北美、南美和欧洲,香港服务东南亚、中东和非洲地区。
然后来看看我们的架构:
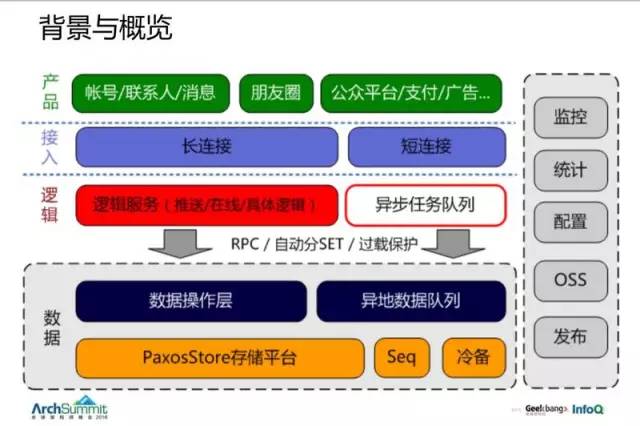
最上边是我们的产品;
然后有一个号称几亿在线的长连接和短连接的服务;
中间有一个逻辑层,后台框架讲的主要是逻辑层往后这块,包括我们的 RPC、服务分组、过载保护与数据存储;
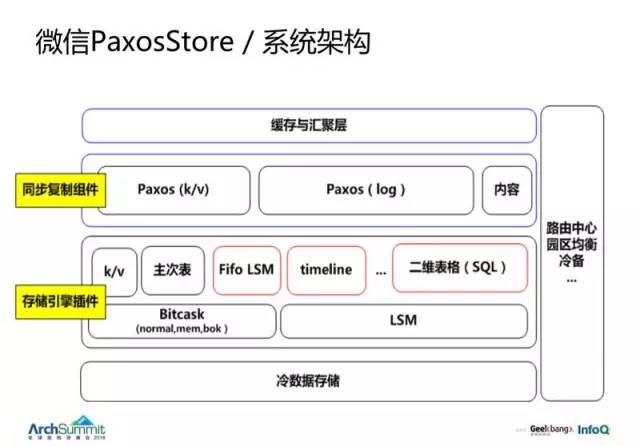
底层有个 PaxosStore 存储平台。
整套就是这么个体系。微服务很容易去构建,但是规模变大后有哪些问题,需要哪些能力?这里挑出三个点来讲一下:
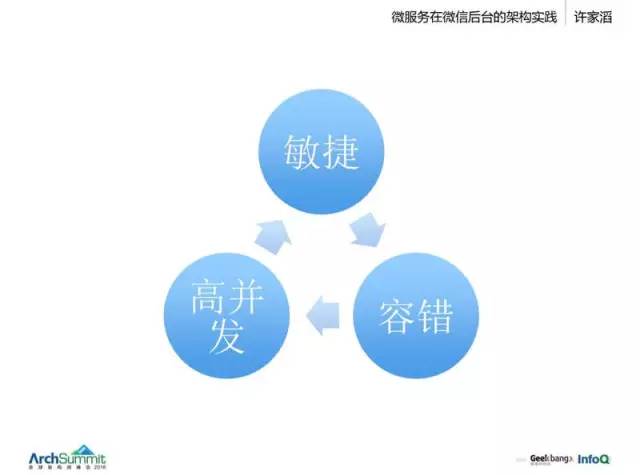
一、敏捷
希望你的服务很快实现,不太多去考虑。像我们早期互联网业务,甚至包括 QQ 等,我们很注重架构师的一个能力,他需要把握很多的东西。他设置每个服务的时候,要先算好很多资源,算好容灾怎么做。容灾这个问题直接影响业务怎么去实现的,所以有可能你要做一个具体逻辑的时候要考虑很多问题,比如接入服务、数据同步、容灾等等每个点都要考虑清楚,所以节奏会慢。
二、容错
当你的机器到了数万台,那每天都有大量机器会有故障。再细一点,可以说是每一个盘的故障更频繁一点。
三、高并发
接下来看看我们的基础架构。

整个微服务的架构上,我们通常分成这些部分:
服务布局
服务之间怎么做一些远程调用
容错(主要讲一下过载保护)
部署管理
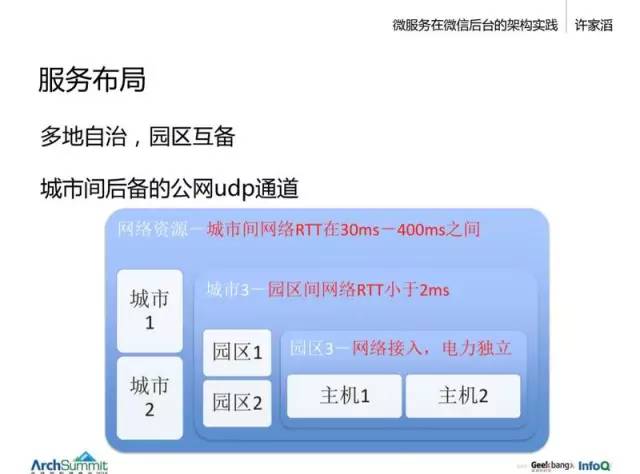
分两层,一个是城市间。城市之间的数据是相对独立的,除了少数账号全球同步,大部分业务都希望做成电子邮件式的服务,各自有自身的环境在跑,之间使用类似于电子邮件的通信。所以我们选择让每个城市自治,它们之间有一个 200-400ms 的慢速网络,国内会快点,30ms。
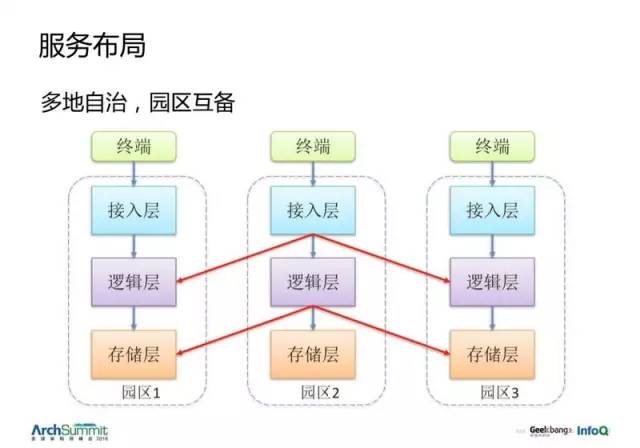
而城市内部,就是每个园区是一套独立的系统,可以互相为对方提供备份。要求独立的电源与网络接入。
城市内部会有整套的划分,终端 -->接入层 -->逻辑层 -->存储层 都是完全独立的一套系统。
看到很多框架,竟然是没有协程的,这很诧异。早年我们 QQ 邮箱、微信、图像压缩、反垃圾都是一个 web 服务,只有存储层会独立到后面去,甚至用 web 直连 MySQL。因为它早期比较小,后来变大之后就用微服务架构。
每个东西都变成一个小的服务,他们是跨机的。你可以想象一下,每天我们很多人买早餐的时候,掏出手机做一个微信支付,这一个动作在后台会引起上百次的调用。这有一个复杂的链路。在 2014 年之前,我们微信就是没有做异步的,都是同步的,在这么多调用里,A 服务调用 B,那要先等它返回,这样就占住了一条进程或者线程。所以其实 13 年的时候,我们发生了大大小小的故障,很大一部分原因就在这里。
然后 13 年底的时候,这个问题太严重了,严重到,比如发消息的时候,你去拿一个头像之类的,它只要抖动,就可能引发整一条调用链的问题,并且因为过程保护的不完善,它会把整个消息发送的曲线掉下去,这是我们很痛苦的时间。
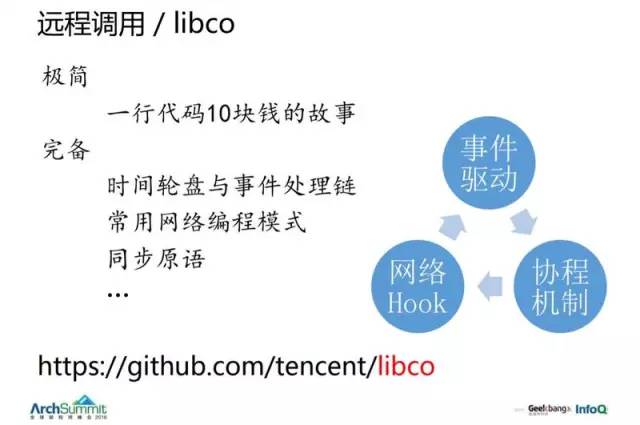
然后当时我们就去考虑这些方案,13 年的时候抽出 3 个人重新做了一个完整的库 libco。(两千行),实现时间轮盘与事件处理链、常用网络编程模式、同步原语等。它分为三大块,事件驱动、网络 HOOK 和协程机制。
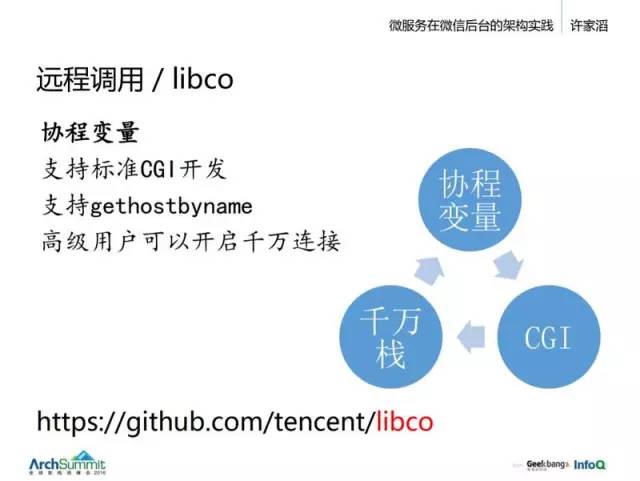
早期是多进程为主,当年切多线程的时候,也遇到一大波修改,后来线程里有了一个线程变量就好多了。如果没有这个东西,你可能要把许多变量改成参数再一层一层传递下去。有了线程变量就好多了。现在我们的协程变量也是这个意义,效果就像写一个宏一样。
另一个是,我们支持 CGI,早期库在 CGI 上遇到问题,所以没有推广。因为一个标准 CGI 服务是基于一些古老的接口的,像 getENV、setENV,就是说你的 coreString 是通过 ENV 来得到的,那么这个我们也把它给 HOOK 掉了,它会根据你的协程去分派。
最难的一个是 gethostbyname 方法,我发现很多人就连在异步编程里,处理 hostbyname 也可能是用了一套独立线程去做,或者你很辛苦地把整个代码抠出来重新写一遍,这个肯定是有很多问题的。所以我们 libco 就把这个 gethostbyname 给完整地支持了。
最后如果你还不爽,说一般业务逻辑可以这么干,那我还有很多后台代码怎么办呢?很多有经验的老的程序员可能要拿着他们那一堆很复杂的异步编程的代码来质疑我们,他们不认为他们的代码已经完全可以被协程所取代了。
他们有如下两个质疑:
质疑性能:协程有很多切换,会不会带来更大开销?
你可能处理几万并发就好,消耗个 1G 内存就行,但是我们这里是处理千万并发哦,这么大的规模,我不信任你这个东西。
这样我们其实是面临了一个问题,因为一些老代码,越是高级的人写的,它的技术栈越深,稍微改动一点代码,就出 BUG 了。
所以我们后来做了两个东西,一个是实际修改了相对简单的异步代码到 libco 里,然后性能更好了。因为在做异步编程的时候,你需要自己去维护很多的数据结构,做你的状态保存,它们的生存期有可能需要很久,你自然地会分配许多内存给它,当然你会用一些内存池去优化它,但是这些是有限的。
但是你用协程的话,很多变量就自然在一个连续的内存里了,相当于一个小的内存池,就比如 if……else……这个你没有必要去 new 一个东西保存状态的,直接放在栈里就行了,所以它的性能更好了。
第二个是,它要求很高的并发。由于协程要一个栈,我们一般开 128k,如果你对这个代码掌控得比较好,可能开 16k,就算是这样,你要开 1 万个协程,还是要 100 多 M 的内存。所以我们后来就在这基础上做了一个可以支持千万连接的协程模式。
Libco 是一个底层库,让你很方便开发,但是大部分开发人员不是直接面对 libco 的,我们花了一年时间把整个微信后台绝大部分逻辑服务、存储服务改成基于 libco,整个配置就直接通过配一台机器上的并发数配 10 倍甚至 20、30 倍,这样子就一下子把整个问题解决了。
并发数上去后容易引发另一个问题,早期的时候,后端服务性能高,逻辑服务性能相对弱,很容易被 hold,不可能给后端发起很多连接,不具有“攻击性”,但修改完成后,整个前端变得很强,那可能对后端产生很大的影响。这个时候就要来考虑一下过载保护了。
一般会提到几个点。
1.轻重分离:
就是一个服务里边不要又有重的操作,又有轻的,这样过载的时候,大量的请求都被某些小请求拦截掉了,资源被占满了。
2.队列:
过载保护一般是说系统内部服务在做过去的事情,做无用功。它们可能待在某个队列里边,比如服务时间要求 100ms,但它们总是在做 1s 以前的任务,所以整个系统会崩溃。所以老的架构师会注重说配好每一个服务的队列长度,估算好。但是在繁忙的开发中,是很难去控制的。
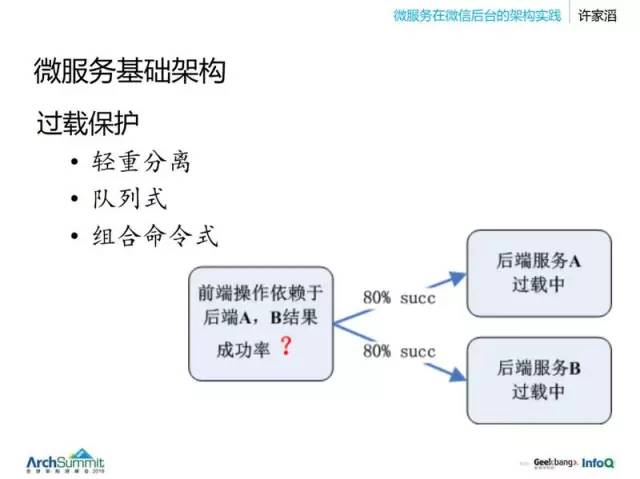
3.组合命令式:
后端服务并不是只有一个,上边这个图中的例子,想要调用很多服务,然后 AB 都过载,它们每一个其实都只是过载一点,通过率可达到 80%,但是前端需要这两个服务的组合服务,那么这里就可能只能达到 60% 的通过率。然后后边如果是更多的服务,那么每个服务的一点点过载,到了前端就是很严重的问题。怎么解决呢?

这本书在 12、13 年的时候很火,里边提到了两个对我们有用的点。
一个是“希望系统是分布式的,去中心化”,指系统过载保护依赖每一个节点自身的情况去做,而不是下达一个统一的中心指令。
二是“希望整个控制是基于反馈的”,它举了一些例子,像抽水马桶,像过去炼钢铁的参数很难配,但是只要有一个反馈机制就好解决了。
于是我们构建了一套看起来有点复杂的过载保护系统。
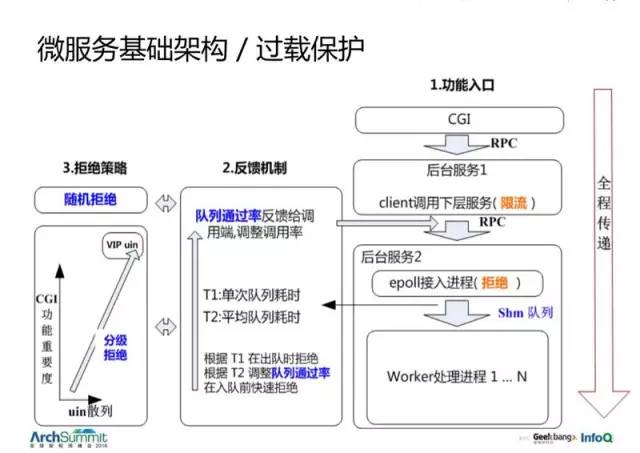
整个系统基于反馈,然后它把整个拒绝的信息全程传递了。看到最右边,有几个典型的服务,从一个 CGI 调用一个后台服务,再调用另一个后台服务,它会在 CGI 层面就把它的重要程度往下传。回到刚才那个前端调用 A、B 服务的例子,使用这样的一种重要程度传递,就可以直接拒绝那些相同用户的 20% 的请求,这样就解决了这个问题。
这个只是反映了生产者和服务者处理能力的差异,观察这个差异,就可以得到一个好的拒绝的数。你不需要去配它多长,只需要去看一个请求在队列里待的平均时间是否可以接受,是一个上涨趋势还是一个下降趋势。这样我们就可以决定要不要去拒绝。那这样几乎是全自动的。你只要配得相对大一点就行了,可以抗一些抖动。在接入之前就评估它,在过去一段时间内平均队列耗时多长,如果超过预支,我们就往下调。这样就把整个系统的过载能力提升了很多。
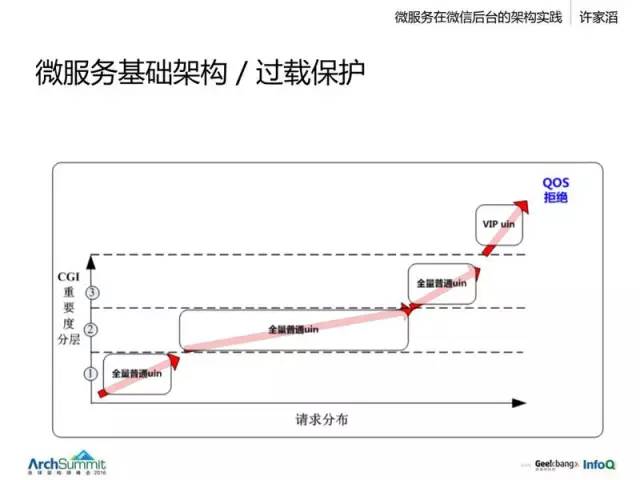
这是一个具体的做法,我们会考虑两个维度,一个是后台服务,可能服务很多不同的前端,它可能来源于一个支付的请求,经过层层调用,到达后台;或者是一个发消息的服务;它也可能是一个不重要的小服务,如果这个账户服务过载的时候,那么我们可以根据这个表来自动地优先去拒绝一些不那么重要的服务请求,使得我们核心服务能力可以更好地提供。这样整个系统就可以做到很好的过载保护。
上边提到一个数据层,那我们是怎么去做数据的呢?

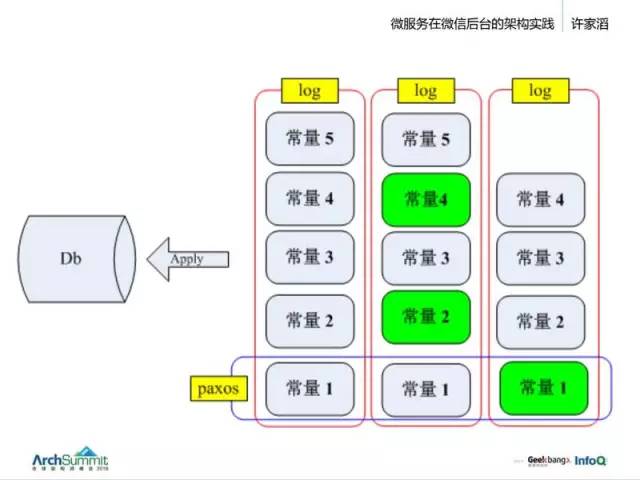
在过去很多年里,我们可能是尽可能去事务化、不追求强一致,一般是采用主备同步的方法。但我们的目标还是强一致的存储。
强一致是说,写一个数据之后,服务器的返回成功不会因为单机故障而丢失。早年我们用的是自己设计的协议,严格来证明的话,没有 Paxos 这么严谨,所以我们在过去一年多的时间内,重新做了一个 Paxos 存储。





Raft 的开源很有价值,它把互联网后台的数据一致性能力提升了很多,就算是一个很小的团队,它也能直接用 Raft 获得一个强一致能力,而这可能就已经超过了许多互联网后台的强一致能力,因为很多后台都是用了很古老的架构,比如长期用到主机架构。


作者介绍

看完本文有收获?请转发分享给更多人
欢迎关注“互联网架构师”,我们分享最有价值的互联网技术干货文章,助力您成为有思想的全栈架构师,我们只聊互联网、只聊架构,不聊其他!打造最有价值的架构师圈子和社区。
本公众号覆盖中国主要首席架构师、高级架构师、CTO、技术总监、技术负责人等人 群。分享最有价值的架构思想和内容。打造中国互联网圈最有价值的架构师圈子。
长按下方的二维码可以快速关注我们
如想加群讨论学习,请点击右下角的“加群学习”菜单入群