【2020新书】社交媒体挖掘,212pdf,Mining Social Media

-
第一章:你需要知道的编程语言,介绍了前端语言(HTML, CSS和JavaScript),以及为什么它们在社交媒体数据挖掘中很重要。您还将通过交互式shell中的实践练习学习Python的基础知识。 -
第2章:从哪里获取数据,解释了什么是api,什么类型的数据可以通过它们访问,并指导您如何访问JSON格式的数据。本章还涵盖了为数据分析制定研究问题的过程。 -
第3章:用代码获取数据,向您展示了如何收集从YouTube API返回的数据,并使用Python将其从JSON重构为电子表格,特别是.csv文件。 -
第4章:抓取你自己的Facebook数据定义, 抓取和描述如何检查HTML以将内容从web页面结构成数据。本文还介绍了社交媒体公司为用户提供的数据存档,以及如何将数据提取到.csv文件中。 -
第5章:抓取实时站点的解释, 抓取网站的道德考虑,并带领你完成为维基百科页面撰写抓取的过程。
-
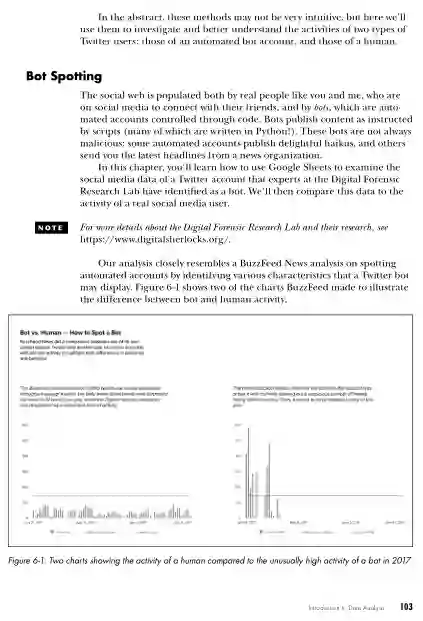
第6章:数据分析,导论介绍了涉及数据分析的各种过程,并通过分析来自自动帐户(bot)的数据介绍了谷歌表。 -
第7章:可视化数据探索可视化工具,如在谷歌表格中制作图表和使用条件格式突出显示数据变化,如何帮助我们更好地理解数据。 -
第8章:数据分析的高级工具,将您从分析谷歌表中的数据中学到的概念转移到编程分析领域。您将看到如何在Python 3中设置虚拟环境、浏览Jupyter笔记本(一个能够读取和运行Python代码的web应用程序)以及使用Python库panda。您还将研究数据集的结构和广度。 -
第9章:在Reddit数据中寻找趋势,以前一章为基础,介绍如何使用panda中的函数修改数据、过滤数据和运行基本聚合。 -
第10章:衡量政治参与者的Twitter活动,解释如何将数据格式化为时间戳,如何使用lambda函数更有效地修改它,以及如何在panda中对它进行时间上的重新采样。 -
第11章:从这里往哪里走,列出了用于成为更好的Python编码器、学习更多关于统计分析的知识以及使用自然语言处理和机器学习来解析文本的参考资料。
电子书部分截图





专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MSM2020” 可以获取《【2020新书】社交媒体挖掘,212pdf,Mining Social Media》专知下载链接索引


登录查看更多
相关内容

专知会员服务
41+阅读 · 2019年12月11日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日




相关VIP内容
专知会员服务
41+阅读 · 2019年12月11日
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日