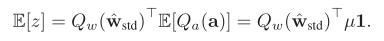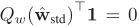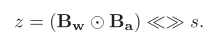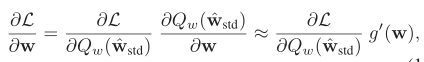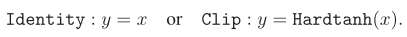点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
本文转载自:机器之心
近日,计算机视觉顶会 CVPR 2020 接收论文结果已经正式公布。在 6656 篇有效投稿中,最终有 1470 篇论文被接收,录取率约为 22%。本文将介绍一种旨在优化前后向传播中信息流的实用、高效的网络二值化新算法 IR-Net,研究者来自北航、北邮、电子科技大学、商汤研究院等机构,论文已被 CVPR 2020 接收。
这篇论文提出了一种旨在优化前后向传播中信息流的实用、高效的网络二值化新算法 IR-Net。不同于以往二值神经网络大多关注量化误差方面,本文首次从统一信息的角度研究了二值网络的前向和后向传播过程,为网络二值化机制的研究提供了全新的视角。同时,该工作首次在 ARM 设备上进行了先进二值化算法效率验证,显示了 IR-Net 部署时的优异性能和极高的实用性,有助于解决工业界关注的神经网络二值化落地的核心问题。
部署最先进的 CNN 模型需要昂贵的存储和计算资源,这在很大程度上限制了 DNNs 在手机和相机等便携式设备上的应用。二值神经网络因其存储量小、推理效率高而受到广泛关注,这受益于权值和激活的二值化以及按位运算实现的高效卷积。然而,尽管在二值化神经网络方面已经取得了很大的进展,但与全精度的对应方法相比,现有的量化方法的精度仍然存在显著的下降。
对神经网络的研究表明,网络的多样性是模型达到高性能的关键,
保持这种多样性的关键是:(1) 网络在前向传播过程中能够携带足够的信息;(2) 反向传播过程中,精确的梯度为网络优化提供了正确的信息。
二值神经网络的性能下降主要是由二值化的有限表示能力和离散性造成的,这导致了前向和反向传播的严重信息损失,模型的多样性急剧下降。在现有研究中,有两种方法被广泛应用于提高神经网络的多样性:增加神经元数目或增加特征映射的多样性。例如,Bi-Real Net[7] 过添加量化激活的全精度跨层连接来增加特征的多样性和表达能力,从而实现显著的性能改进。然而,随着浮点加法运算的增加,Bi-Real Net 不可避免地面临着比普通二值神经网络更差的效率。
在二值神经网络的训练过程中,离散二值化往往导致梯度不准确和优化方向错误。为了更好地处理这种离散性,许多方法寄希望于提高二值化的更新能力和减小 sign 函数与近似函数的不匹配区域,然而遗憾的是,训练初期和后期的差异往往被忽略,在实际训练中,训练过程开始时往往需要较强的更新能力,训练结束时小的梯度误差变得更为重要。仅从一个点上获取尽可能多的损失函数反映的信息是不够的。
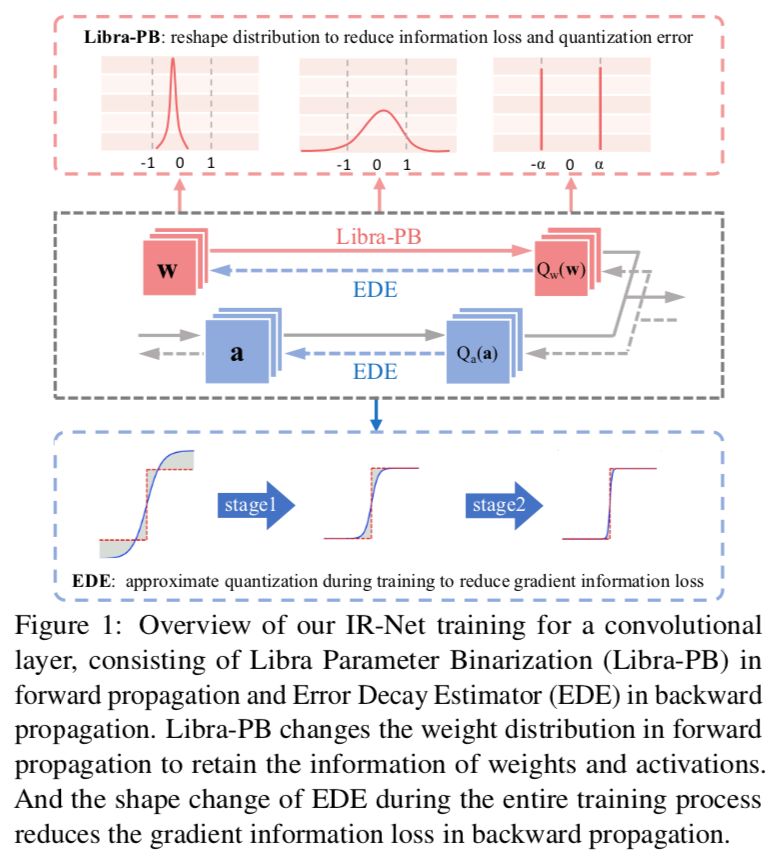
为了解决上述问题,本文首次从信息流的角度研究了网络二值化,提出了一种新的信息保持网络(IR-Net)(见图 1)。我们的目标是通过保留前向和反向传播中的信息来训练高精度的二值化模型:(1) IR-Net 在前向传播中引入了一种称为 Libra 参数二值化(Libra-PB)的平衡标准化量化方法。利用 Libra-PB,通过最大化量化参数的信息熵和最小化量化误差,可以使前向传播中的信息损失最小化,从而保证良好的推断准确率 (2) 在反向传播中,IR-Net 采用误差衰减估计器(EDE)来计算梯度,并通过更好地逼近 sign 函数来最小化信息损失,从而保证训练开始时的充分更新和训练结束时的精确梯度。
IR-Net 提供了一个全新的角度来理解二值神经网络是如何运行的,并且 IR-Net 的设计非常实用,除了在深度网络中具有很强的信息前向/后向保留能力外,它还具有很好的通用性,可以在标准的网络训练流程中进行优化。我们使用 CIFAR-10 和 image Net 数据集上的图像分类任务来评估我们的 IR-Net。实验结果表明,该方法在 ResNet-20、VGG-Small、ResNet-18 和 ResNet-34 等多种网络结构上都有很好的性能,大大超过了以往的量化方法。我们借助京东的开源二值化推理库 daBNN 进行了部署效率验证,我们首次在 ARM 设备上进行二值化算法效率的验证。
Preliminaries
在深度神经网络中,主要计算操作可表示为![]() 其中
其中![]() 表示权重向量,
表示权重向量,![]() 表示前一网络层计算的输入激活向量。
浮点精度的向量运算占据了全精度神经网络的大部分运算量,因此一种直接的压缩、加速思路是:(1) 减小单个参数的内存占用(缩小位宽);(2) 使用更高效的运算(位运算)取代代价高昂的浮点运算。因此,模型二值化作为一种极限压缩位宽的模型压缩策略,受到了研究者的广泛关注。模型二值化的目标是使用 sign 函数将模型中的参数缩小到原始模型的 1/32,即用 1 比特表示浮点权重和(或)浮点激活。通过量化的权重和激活,前向传播中的矢量乘法可以重新表示为
表示前一网络层计算的输入激活向量。
浮点精度的向量运算占据了全精度神经网络的大部分运算量,因此一种直接的压缩、加速思路是:(1) 减小单个参数的内存占用(缩小位宽);(2) 使用更高效的运算(位运算)取代代价高昂的浮点运算。因此,模型二值化作为一种极限压缩位宽的模型压缩策略,受到了研究者的广泛关注。模型二值化的目标是使用 sign 函数将模型中的参数缩小到原始模型的 1/32,即用 1 比特表示浮点权重和(或)浮点激活。通过量化的权重和激活,前向传播中的矢量乘法可以重新表示为![]() ,其中
,其中![]() 表示位运算(XNOR 和 bitcount)实现的
向量卷积,相比浮点卷积,该
操作可达到 58x 的理论加速。
在反向传播中 sign 函数的导数几乎处处为 0,无法直接使用在反向传播中。因此,一般在反向传播中使用「直通估计器(STE)」训练二值模型,STE 通过 Identity 函数或 Hardtanh 函数传播梯度。
Information Retention Network
我们的分析表明,高精度二值神经网络训练的瓶颈主要在于训练过程中严重的信息损失。前向 sign 函数和后向梯度逼近所造成的信息损失严重影响了二值神经网络的精度。为了解决以上问题,本文提出了一种新的信息保持网络(IR-Net)模型,它保留了训练过程中的信息,实现了二值化模型的高精度。
表示位运算(XNOR 和 bitcount)实现的
向量卷积,相比浮点卷积,该
操作可达到 58x 的理论加速。
在反向传播中 sign 函数的导数几乎处处为 0,无法直接使用在反向传播中。因此,一般在反向传播中使用「直通估计器(STE)」训练二值模型,STE 通过 Identity 函数或 Hardtanh 函数传播梯度。
Information Retention Network
我们的分析表明,高精度二值神经网络训练的瓶颈主要在于训练过程中严重的信息损失。前向 sign 函数和后向梯度逼近所造成的信息损失严重影响了二值神经网络的精度。为了解决以上问题,本文提出了一种新的信息保持网络(IR-Net)模型,它保留了训练过程中的信息,实现了二值化模型的高精度。
![]()
Libra Parameter Binarization in Forward Propagation
在此之前,绝大多数网络二值化方法试图减小二值化操作量化误差。然而,仅通过最小化量化误差来获得一个良好的二值化网络是不够的,也是困难的。因此,为了在前向传播中保留信息并最小化信息损失,我们提出了同时考虑量化误差和信息损失的 Libra 参数二值化(Libra-PB)。
Libra-PB 设计的关键在于使用信息熵指标最大化二值网络前向传播过程中的信息流。根据信息熵的定义,在二值网络中,二值参数 Qx(x) 的熵可以通过以下公式计算:![]() 如果我们单纯地追求量化误差最小化,在极端情况下,量化参数的信息熵甚至可以接近于零。
因此,Libra-PB 设计了全新的目标函数,其中将量化值的量化误差和信息熵同时作为优化目标,定义为:
如果我们单纯地追求量化误差最小化,在极端情况下,量化参数的信息熵甚至可以接近于零。
因此,Libra-PB 设计了全新的目标函数,其中将量化值的量化误差和信息熵同时作为优化目标,定义为:
![]()
在伯努利分布假设下,当 p=0.5 时,量化值的信息熵取最大值。这意味着量化值应该均匀分布。因此,我们通过减去全精度权重的平均值来平衡零均值属性的权重。此外,为了使训练更稳定,不受权重大小和梯度的负面影响,我们进一步规范化了平衡权重。通过以下标准化和平衡操作获得标准化平衡权重![]() 。该权重具有两个特点:(1) 零均值,使获得的二值化权重信息熵最大。(2) 单位范数,这使得二值化所涉及的全精度权重更加分散。因此,与直接使用平衡过程相比,标准化平衡过程的使用使权值稳定更新,使二值化权值
。该权重具有两个特点:(1) 零均值,使获得的二值化权重信息熵最大。(2) 单位范数,这使得二值化所涉及的全精度权重更加分散。因此,与直接使用平衡过程相比,标准化平衡过程的使用使权值稳定更新,使二值化权值![]() 在训练过程中更加稳定。
有趣的是,我们证明,对权重的简单变换也可以极大改善了前向过程中激活的信息流。由于
在训练过程中更加稳定。
有趣的是,我们证明,对权重的简单变换也可以极大改善了前向过程中激活的信息流。由于![]() 的值取决于
的值取决于![]() 的符号,且 w 的分布几乎是对称的,因此平衡运算可以使量化后的
的符号,且 w 的分布几乎是对称的,因此平衡运算可以使量化后的![]() 的信息熵最大化。同时,当使用 Libra-PB 作为权值时,网络中的激活信息流也可以得到保持。假设量化激活
的信息熵最大化。同时,当使用 Libra-PB 作为权值时,网络中的激活信息流也可以得到保持。假设量化激活![]() 的平均值
的平均值![]() ,z 的平均值可以通过以下公式计算:
,z 的平均值可以通过以下公式计算:![]()
因为在每层中使用 Libra-PB 处理权重,所以我们有![]() ,输出的平均值为零。因此,每一层激活信息熵可以最大化,这意味着激活信息可以被保留。
,输出的平均值为零。因此,每一层激活信息熵可以最大化,这意味着激活信息可以被保留。
在以往的二值化方法中,为了使量化误差减小,几乎所有方法都会引入浮点尺度因子来从数值上逼近原始参数,这无疑将高昂的浮点运算引入其中。在 Libra-PB 中,为了进一步减小量化误差,同时避免以往二值化方法中代价高昂的浮点运算,Libra-PB 引入了整数位移位标量 s,扩展了二值权重的表示能力。
因此最终,我们针对正向传播的 Libra 参数二值化可以呈现如下:
![]()
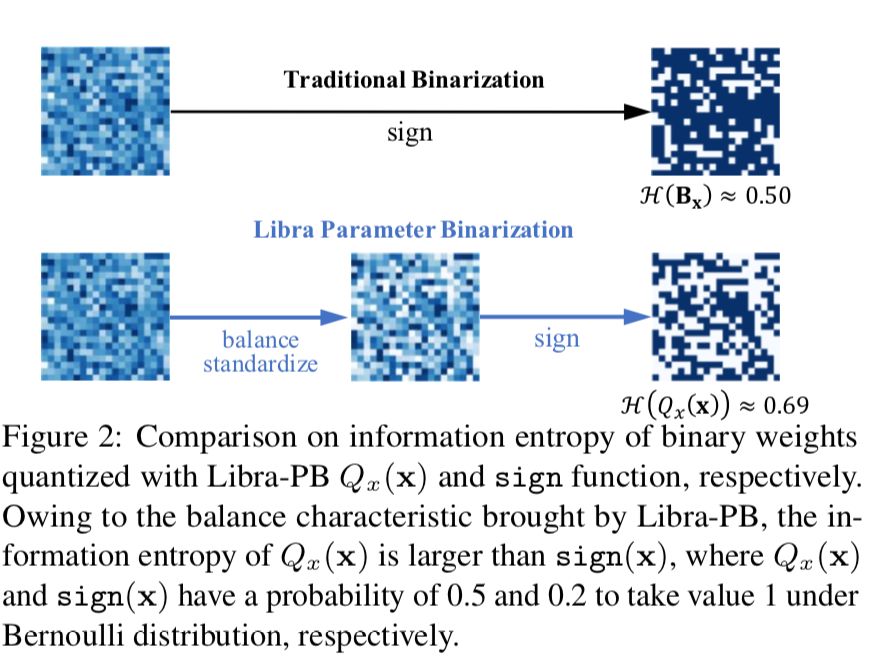
IR-Net 的主要操作可以表示为:![]() 如图 2 所示,在 Bernoulli 分布下,由 Libra-PB 量化的参数具有最大的信息熵。我们称我们的二值化方法为「Libra 参数二值化」,为保留信息,在二值化之前参数是平衡的。
值得注意的是,Libra-PB 提供了一个隐式整流器,它在二值化之前重塑数据分布。之前的一些研究中也意识到了这一改动对 BNNs 性能的积极影响,并采用了经验设置来重新分配参数。与这些工作不同的是,我们首先直接提出信息的观点,重新思考二值化前参数分布的影响,并通过最大化信息熵来保证最优解。此外,在该框架下,Libra-PB 只需在二值化前对权值进行平衡和标准化,就可以完成分布调整。这意味着我们的方法可以简单而广泛地应用于各种神经网络结构中,并且可以直接插入到标准的训练流程中,而且额外的计算成本非常有限。
如图 2 所示,在 Bernoulli 分布下,由 Libra-PB 量化的参数具有最大的信息熵。我们称我们的二值化方法为「Libra 参数二值化」,为保留信息,在二值化之前参数是平衡的。
值得注意的是,Libra-PB 提供了一个隐式整流器,它在二值化之前重塑数据分布。之前的一些研究中也意识到了这一改动对 BNNs 性能的积极影响,并采用了经验设置来重新分配参数。与这些工作不同的是,我们首先直接提出信息的观点,重新思考二值化前参数分布的影响,并通过最大化信息熵来保证最优解。此外,在该框架下,Libra-PB 只需在二值化前对权值进行平衡和标准化,就可以完成分布调整。这意味着我们的方法可以简单而广泛地应用于各种神经网络结构中,并且可以直接插入到标准的训练流程中,而且额外的计算成本非常有限。
![]()
Error Decay Estimator in Backward Propagation
由于二值化的不连续性,梯度的近似对于反向传播是不可避免的。由于量化的影响不能被近似精确地建模表示,这导致了巨大的信息损失。近似值可以表示为:
![]()
其中 L(w) 表示损失函数,g(w) 表示对 sign 函数的近似,g』(w) 是 g(w) 的导数。在以前的研究中,有两种常用的近似方法:
![]()
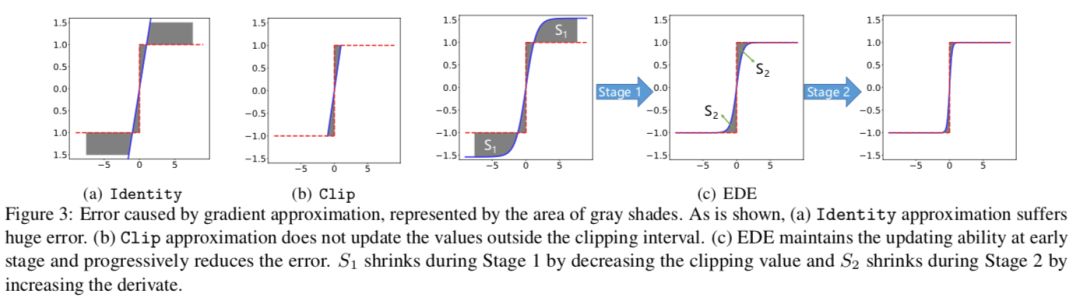
Identity 函数直接将输出值的梯度信息传递给输入值,完全忽略了二值化的影响。如图 3(a) 的阴影区域所示,梯度误差很大,并且会在反向传播过程中累积。利用随机梯度下降算法,要求保留正确的梯度信息,避免训练不稳定,而不是忽略由 Identity 函数引起的噪声。
Clip 函数考虑了二值化的截断属性,减少了梯度误差。但它只能在截断间隔内传递梯度信息。从图 3(b) 中可以看出,对于 [-1,+1] 之外的参数,梯度被限制为 0。这意味着一旦该值跳出截断间隔,就无法再对其进行更新。这一特性极大地限制了反向传播的更新能力,证明了 ReLU 是一个比 Tanh 更好的激活函数。因此,在实际应用中,Clip 近似增加了优化的难度,降低了精度。确保足够的更新可能性至关重要,特别是在训练过程开始时。
Identity 函数丢失了量化的梯度信息,而 Clip 函数则丢失了截断间隔之外的梯度信息。这两种梯度信息损失之间存在矛盾。
为了保留反向传播中由损失函数导出的信息,EDE 引入了一种渐进的两阶段近似梯度方法。
第一阶段:保留反向传播算法的更新能力。我们将梯度估计函数的导数值保持在接近 1 的水平,然后逐步将截断值从一个大的数字降到 1。利用这一规则,我们的近似函数从 Identity 函数演化到 Clip 函数,从而保证了训练早期的更新能力。
第二阶段:保持参数的精确梯度在 0 左右。我们将截断值保持为 1,并逐渐将导数曲线演变到阶梯函数的形状。利用这一规则,我们的近似函数从 Clip 函数演变到 sign 函数,从而保证了前向和反向传播的一致性。
各阶段 EDE 的形状变化如图 3(c) 所示。我们的 EDE 在第一阶段更新了所有的参数,并且在第二阶段进一步提高了参数的准确性。在两阶段估计的基础上,EDE 减小了前向二值化函数和后向近似函数之间的差异,同时所有参数都能得到合理的更新。
![]()
![]()
算法 1 总结了 IR-Net 的训练过程。在这一部分中,我们将从不同的角度分析 IR-Net。
由于 Libra-PB 应用于权重,因此在 IR-Net 中有额外的二值化激活操作。在 Libra-PB 中,与使用浮点标量(例如 XNOR-Net 和 LQ-Net)的现有解相比,使用新的位移标量可以降低计算成本,如表 1 中所示。稍后,我们将进一步测试在硬件上部署的实际速度,结果可以在部署效率部分看到。
![]()
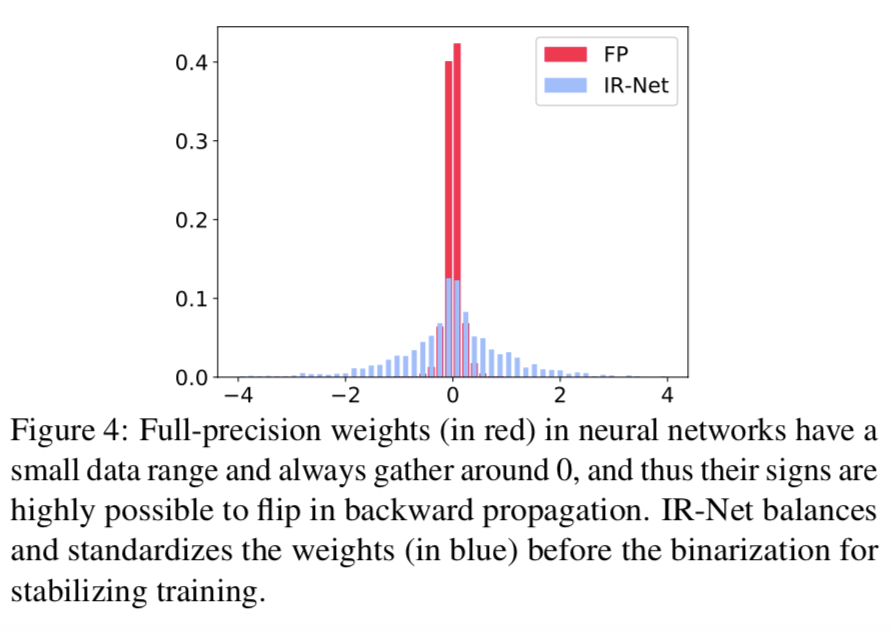
在 Libra 参数二值化中,引入了权值标准化,减少了全精度权值与二值化权值之间的差距,避免了二值化带来的噪声。图 4 显示的是没有标准化的权重数据分布,显然更集中在 0 左右。这种现象意味着大多数权值的符号在优化过程中容易发生变化,直接导致二值神经网络的训练不稳定。通过重新分配数据,权重标准化隐式地在正向 Libra-PB 和反向 EDE 之间建立了一个桥梁,有助于二值神经网络更稳定的训练。
![]()
在本节中,我们对两个基准数据集:CIFAR-10 和 ImageNet(ILSVRC12)进行了实验,以验证所提出的 IR-NET 的有效性,并将其与其他最新方法(SOTA)进行了比较。
在这一部分中,我们研究了 Libra-PB 和 EDE 技术对 BNN 性能的影响。
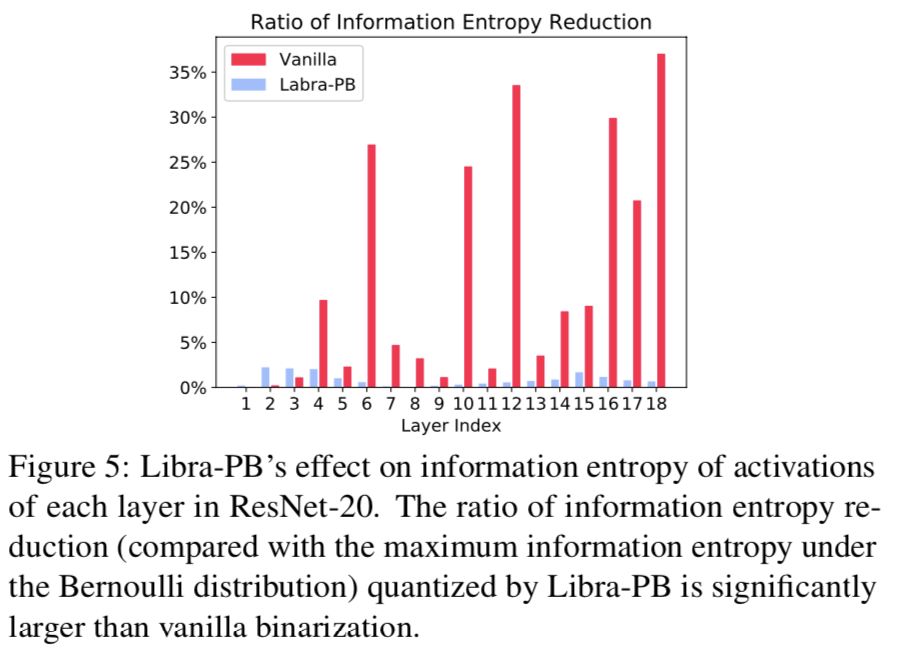
我们的 Libra-PB 可以通过调整网络中的权值分布来最大化 IR-Net 中二元权值和二元激活的信息熵。由于在二值化之前使用了显式的平衡运算,因此网络中每一层的二值权重具有最大的信息熵。受二元权重影响,IR-Net 中的二元激活也具有最大信息熵。为了证明 Libra-PB 在 IR-Net 中的信息保留,在图 5 中,我们展示了通过单普通二值化和 Libra-PB 量化的网络中每一层二进制激活的信息损失。普通的二值化使二值激活的信息熵大大降低。在 Libra-PB 量化的网络中,在 Bernoulli 分布下,每一层的激活都接近最大信息熵。而在前向传播中,一般的二值化引起的二值激活的信息损失是逐层累积的。幸运的是,图 5 中的结果显示 Libra PB 可以在每一层的二进制激活中保留信息。
![]()
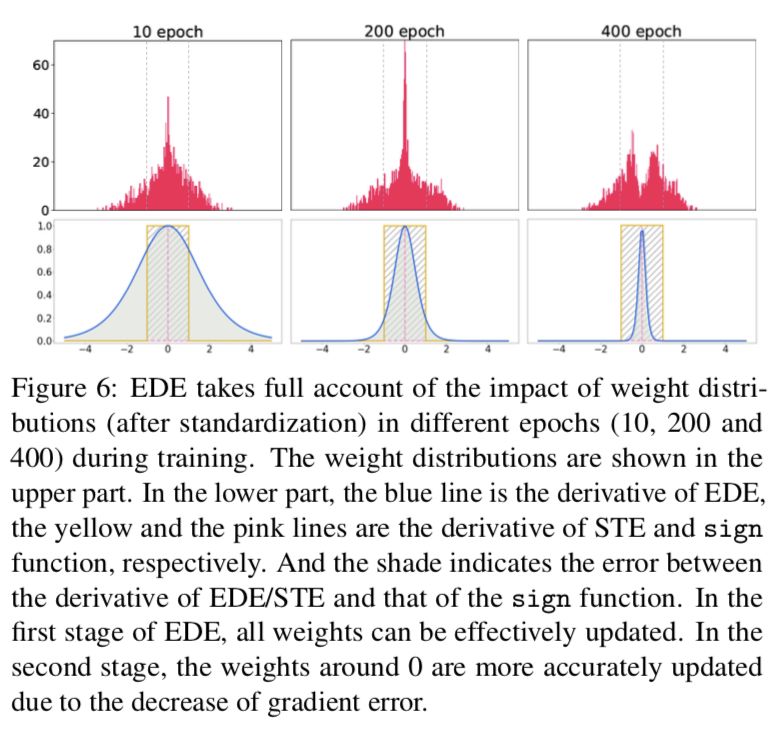
为了证明我们 EDE 的必要性和效果,我们展示了不同训练阶段的权重数据分布,如图 6 所示。第一行的图形显示分布,第二行的图形显示相应的导数曲线。在导数曲线中,蓝色代表 EDE,黄色表示普通的 STE(带截断)。可以看出,在 EDE 的第一阶段(图 6 中的 epoch 10 到 epoch 200),有很多数据在范围 [-1,+1] 之外,因此不应该有太多对更新能力有害的截断。此外,在训练开始时,权重分布的峰值很高,大量的数据聚集在零左右。在这个阶段,EDE 保持了与 Identity 函数相似的导数,以保证零附近的导数不太大,从而避免了训练的严重不稳定性。幸运的是,随着二值化引入训练,在训练的后期,权重将逐渐接近-1/+1。因此,我们可以缓慢地增加导数的值,并近似一个标准 sign 函数来减少梯度失配。可视化结果表明,我们的反向传播 EDE 近似与实际数据分布一致,这是提高精度的关键。
![]()
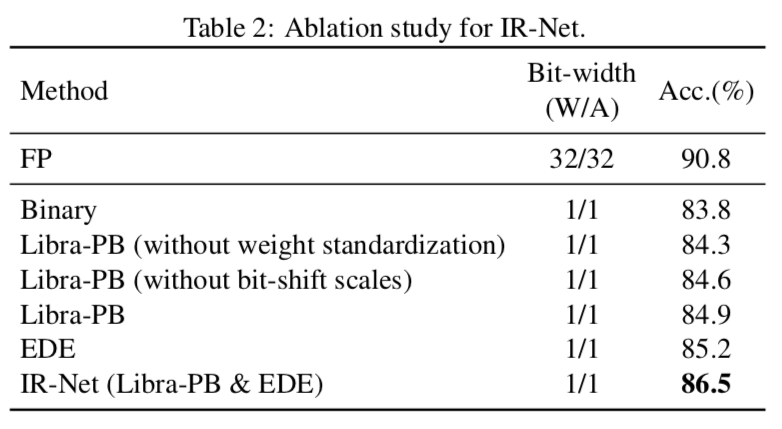
我们在 CIFAR-10 上使用 ResNet-20 模型进一步研究了 IR-NET 的不同部分的性能,这有助于理解我们的 IR-NET 在实际中是如何工作的。表 2 显示了不同设置下的性能。从表中可以看出,单独使用 Libra-PB 或 EDE 可以提高精度,而权重标准化在 Libra-PB 中也起着重要作用。此外,这些部分带来的提升可以叠加在一起,这就是为什么我们的方法可以训练高精度的二值化模型。
![]()
Comparison with SOTA methods
我们通过与现有的 SOTA 方法的比较,进一步对 IR-Net 进行综合评价。
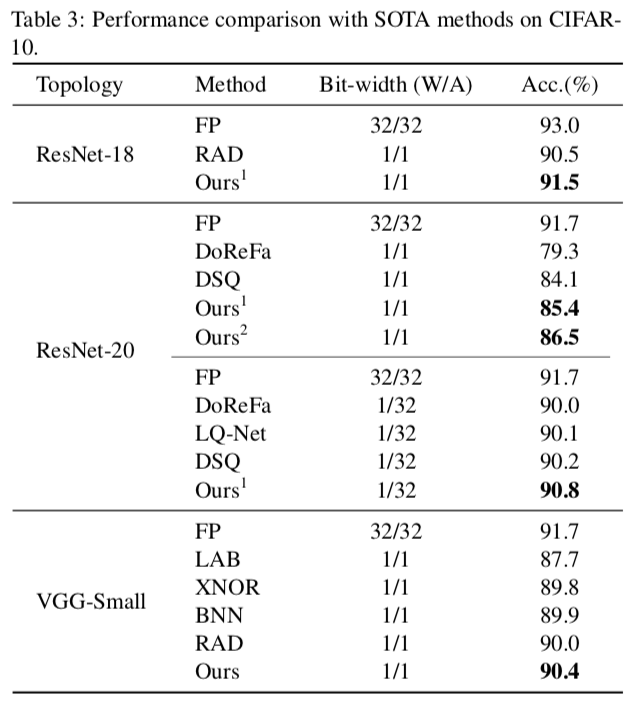
表 3 列出了在 CIFAR-10 上使用不同方法的性能,包括 ResNet-18 上的 RAD、DoReFa-Net、LQ-Net、ResNet-20 上的 DSQ、BNN、LAB、RAD、XNOR-Net 在 VGG-Small 上。在任何情况下,我们的 IR-Net 都能获得最佳性能。更重要的是,我们的方法在使用 1 位权重和 1 位激活(1W/1A)时,无论是使用原始 ResNet 结构还是使用 Bi Real 结构,都比 SOTA 方法有显著的改进。例如,在 1W/1A 比特宽度设置中,与 ResNet-20 上的 SOTA 相比,绝对精度提高高达 2.4%,与对应全精度(FP)模型的差距降低到 4.3%。
![]()
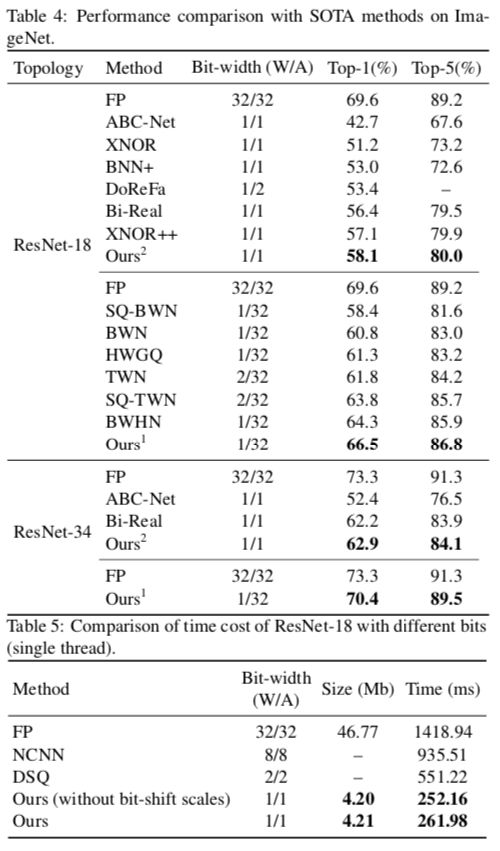
对于大规模的 ImageNet 数据集,我们研究了 ResNet-18 和 ResNet-34 上的 IR-Net 性能。表 4 显示了 ResNet18 和 ResNet-34 上的许多 SOTA 量化方法,包括 BWN、HWGQ、TWN、LQ-Net、DoReFa-Net、ABC-Net、Bi-Real、XNOR++、BWHN、SQ-BWN 和 SQ-TWN。我们可以观察到,当仅对 ResNet-18 上的权重进行量化时,使用 1 位的 IR-Net 在很大程度上优于大多数其他方法,甚至超过使用 2 位权重的 TWN。在 1W/1A 设置中 IR-Net 的 Top-1 准确度也明显优于 SOTA 方法(如 ResNet18 的 58.1% 和 56.4%)。实验结果表明,我们的 IR-Net 比现有的方法更具竞争力。
![]()
为了进一步验证 IR-Net 在实际移动设备中的部署效率,我们在拥有 1.2GHz 64 位四核 ARM Cortex-A53 的 Raspberry Pi 3B 上进一步实现了 IR-Net,并在实际应用中测试了其真实速度。我们利用 ARM-NEON 上的 SIMD 指令 SSHL 使推理框架 daBNN 与我们的 IR-Net 兼容。我们必须指出,到目前为止,很少有研究会公开它们在实际设备中的推理速度,特别是在使用 1 位二值化时。在表 5 中,我们将我们的 IR-Net 与现有的高性能推理实现(包括 NCNN 和 DSQ)进行了比较。从表中我们可以很容易地发现,IR-Net 的推理速度要快得多,IR-Net 的模型尺寸可以大大减小,而且 IR-Net 的位移操作几乎不会带来额外的推理时间和存储消耗。
本文提出了用 IR-Net 来保留二值神经网络中传播的信息,主要包括两种新的技术:保持前向传播信息的 Libra-PB 技术和反向传播中减小梯度误差的 EDE 技术。Libra-PB 从信息熵的角度对权重进行简单而有效的转换,同时减少了权重和激活的信息损失,而无需对激活进行额外的操作。因此,二值神经网络的多样性可以尽可能地保持,同时不会影响效率。此外,设计良好的梯度估计器 EDE 保留了反向传播过程中的梯度信息。由于具有足够的更新能力和精确的梯度,EDE 的性能大大优于 STE。大量实验证明,IR-Net 的性能始终优于现有的最先进的二值神经网络。
[1] Rastegari M, Ordonez V, Redmon J, et al. Xnor-net: Imagenet classification using binary convolutional neural networks[C]//ECCV. Springer, Cham, 2016: 525-542.
[2] Li F, Zhang B, Liu B. Ternary weight networks[J]. arXiv preprint arXiv:1605.04711, 2016.
[3] Zhu C, Han S, Mao H, et al. Trained ternary quantization[J]. arXiv preprint arXiv:1612.01064, 2016.
[4] Lin X, Zhao C, Pan W. Towards accurate binary convolutional neural network[C]//NeurIPS. 2017: 345-353.
[5] Cai Z, He X, Sun J, et al. Deep learning with low precision by half-wave gaussian quantization[C]//CVPR. 2017: 5918-5926.
[6] Zhang D, Yang J, Ye D, et al. Lq-nets: Learned quantization for highly accurate and compact deep neural networks[C]//ECCV. 2018: 365-382.
[7] Liu Z, Wu B, Luo W, et al. Bi-real net: Enhancing the performance of 1-bit cnns with improved representational capability and advanced training algorithm[C]//ECCV. 2018: 722-737.
推荐阅读
2020年AI算法岗求职群来了(含准备攻略、面试经验、内推和学习资料等)
重磅!CVer-学术微信交流群已成立
扫码添加CVer助手,可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、TensorFlow、PyTorch、图神经网络等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
麻烦给我一个在看!


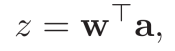 其中
其中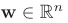 表示权重向量,
表示权重向量,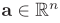 表示前一网络层计算的输入激活向量。
表示前一网络层计算的输入激活向量。
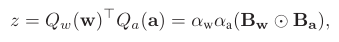 ,其中
,其中 表示位运算(XNOR 和 bitcount)实现的
向量卷积,相比浮点卷积,该
操作可达到 58x 的理论加速。
表示位运算(XNOR 和 bitcount)实现的
向量卷积,相比浮点卷积,该
操作可达到 58x 的理论加速。
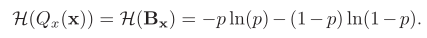 如果我们单纯地追求量化误差最小化,在极端情况下,量化参数的信息熵甚至可以接近于零。
因此,Libra-PB 设计了全新的目标函数,其中将量化值的量化误差和信息熵同时作为优化目标,定义为:
如果我们单纯地追求量化误差最小化,在极端情况下,量化参数的信息熵甚至可以接近于零。
因此,Libra-PB 设计了全新的目标函数,其中将量化值的量化误差和信息熵同时作为优化目标,定义为:
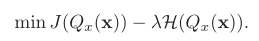
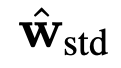 。该权重具有两个特点:(1) 零均值,使获得的二值化权重信息熵最大。(2) 单位范数,这使得二值化所涉及的全精度权重更加分散。因此,与直接使用平衡过程相比,标准化平衡过程的使用使权值稳定更新,使二值化权值
。该权重具有两个特点:(1) 零均值,使获得的二值化权重信息熵最大。(2) 单位范数,这使得二值化所涉及的全精度权重更加分散。因此,与直接使用平衡过程相比,标准化平衡过程的使用使权值稳定更新,使二值化权值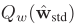 在训练过程中更加稳定。
在训练过程中更加稳定。
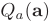 的平均值
的平均值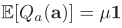 ,z 的平均值可以通过以下公式计算:
,z 的平均值可以通过以下公式计算: