干货 | 中科院曹婍:基于深度学习的社交网络流行度预测研究
AI科技评论按:随着诸如 Twitter、Facebook、新浪微博等社交平台的兴起,每天有成千上万的消息在这些平台上产生并传播。在如此大体量的消息中,如何能提前预测某条消息在未来的关注转发量(流行度),对于用户和平台而言都具有很大的意义。因此,本文将为大家介绍目前的网络信息流行度预测研究进展,以及中科院博士生曹婍提出的基于深度学习技术的端到端流行度预测框架(DeepHawkes 模型)。该工作已被国际会议 CIKM 2017 录用并发表。
曹婍,目前就读于中国科学院计算技术研究所的网络数据科学与技术重点实验室,硕博生。硕士导师为沈华伟研究员,博士导师为李国杰院士。本科毕业于中国人民大学信息学院。目前主要研究方向为社交网络上的信息传播建模及预测。
分享题目:基于深度学习的社交网络流行度预测研究

分享大纲如下:
社交网络上消息流行度预测问题的背景简介
现有消息流行度预测的方法以及存在的问题
介绍本人最新提出的基于深度学习技术的端到端流行度预测框架(DeepHawkes 模型)
对于流行度预测问题的一些思考以及心得体会
相关背景
现有的社交平台的兴起,为我们信息的产生和转播带来了极大的便利。光新浪微博每天至少有一千万条微博产生,但并不是所有信息都能获得同样的关注度。在社交网络上,消息之间的关注度也是很不均匀的,大致也遵从二八法则。

信息在社交网络上的传播有什么特性?
不同于传统的信息传播平台,像电视,报纸,更像是一对多的广播平台,也就是有一个源发者。而在微博等社交网络上存在一个关注关系和转发关系,所以在信息的传播上过程中,会产生一个级联现象。
这种现象在社交网络上是独有的,同时也给社交网络上的信息传播预测带来很大的困难。中间任何一个人的参与转发,最终都可能导致信息在最后的流行度有很大的变化。比如有一个大V转发,信息传播可能就会有一个爆发式的增长。

如何形式化定义这个问题?
第一种是把它当做分类问题,也就是预测消息在未来的流行度是否达到一个特定的预值,或者呈现一个翻倍的情况。第二种是把它当做回归问题,也就是说预测消息在未来具体流行度的量级。相对来说,第二个回归问题较难。

把它当做一个回归问题后,如何定义这个问题?
首先给定一个观测时间后,我们能够观测到消息在观测时间内的转发情况。要预测的目标就是在观测时间窗口到最终预测时间窗口之间的流行度的增长量。
为了能更好体现预测的难度,我们把已知的观测时间窗口内的流行度直接去掉,直接来预测观测时间到预测时间中间的增量流行度情况。
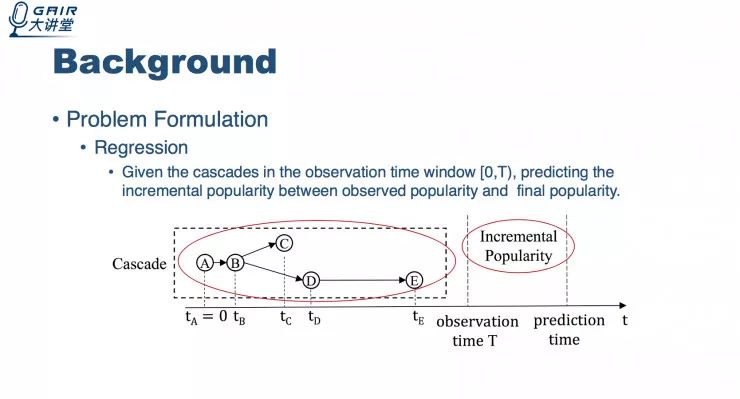
现有的研究方法都有哪些?
现有方法可分为两类。第一类是基于特征的方法,第二类是基于生成式过程的方式。
第一类是站在非常传统经典的机器学习角度来做的,大家的主要贡献点在于特征的提取上。现有的方法主要提取以下这四类特征:
消息内容特征
原发者或转发者相关特征
传播结构特征
时序特征

以内容特征为例,在提取内容特征的时候,包括会提取文字里面是否包含特定特征,还有整篇文字情感的正负向比例。这些都属于消息的内容特征。
用户的特征,包括原发用户和转发用户特征,原发用户特征提取包括年龄,性别,注册时间,活跃度以及他的粉丝数等等。转发用户的特征提取和原发用户类似。
结构特征包括两个,第一个是在原始的社交网络上形成的结构,第二个是在某条特定消息传播过程中所形成的传播图结构。会提取图的连通性,广度,深度,以及初度,入度等等。
时序特征,主要是指在传播过程中,传播速率有什么变化。
这样一类通过特征提取,然后利用机器学习方式来进行流行度预测建模的方法是比较传统和比较宽泛的。但我们可以看到在这过程中,并没有对信息传播的深入动态过程进行理解。而只是通过提取各种各样特征尽可能拟合这样一个结果。它是直接受未来流行度预测监督指导的,一般这样的模型预测比较好,但对于我们理解信息传播过程是有缺陷的,因为没有对传播过程进行建模。
第二类生成式方法,是在原有的特征提取基础之上,能够建模信息传播动态过程,能够探寻信息在传播过程中的一些机制,把这些机制建模好。

自增强泊松过程

Hawkes过程,每一次的转发都会对未来消息带来新的激励。

生成式方法中,它是为每一条消息单独建模训练的,它会对观测时间窗口内的每一个事件进行观测,建模的时候,是通过使观测时间内的事件发生概率最大化来学习得到参数的。它一方面有非常好的可理解性,但同时由于监督的数据是观测时间窗口内的每个事件的发生,而不是未来要预测的增量流行度。预测的性能是有缺失的。
因此促使我们希望能够设计一个模型,在受未来流行度监督之下,怎样把生成式过程中关键机制和因子刻画到,这样就能即具有比较好的预测性能,同时也对消息的传播过程有一个较好的理解能力。我们提出了DeepHawkes模型。
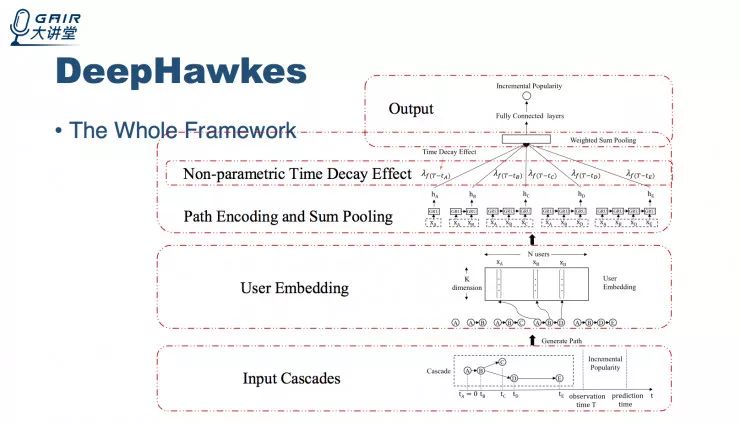
DeepHawkes 整体运行框架
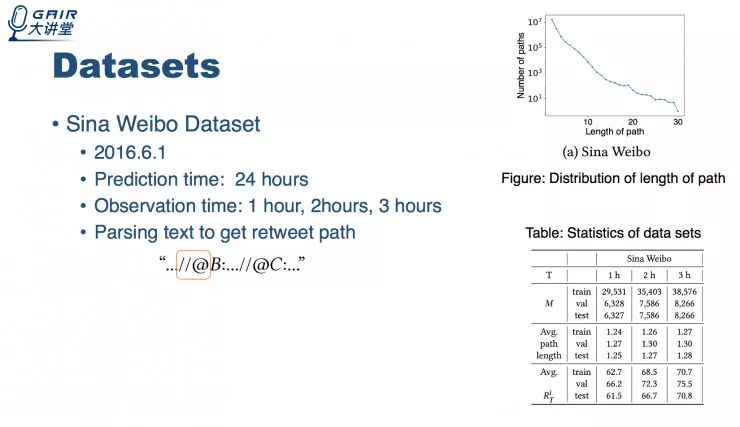
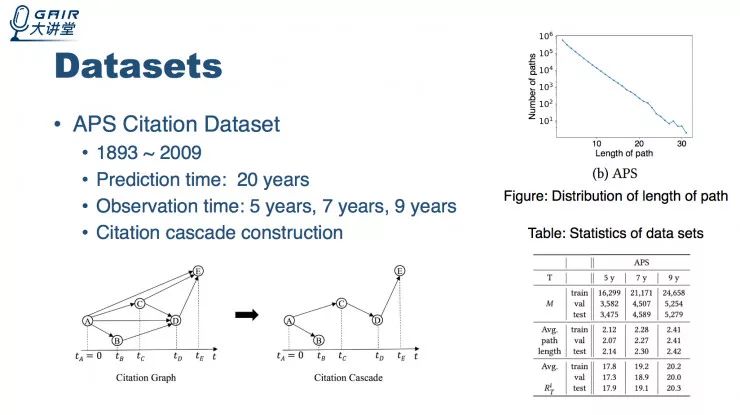
实验数据来源及场景
以下分别是微博场景下预测一条消息在未来的转发度和在论文场景下预测未来论文引用量。
总结:我们提出DeepHawkes模型,在端到端直接通过未来流行度监督的深度学习框架之下,刻画了已有的Hawkes模型当中的信息传播过程中比较关键的因子或机制。同时,我们对这三个机制也进行了一定的改进和扩展,包括用用户学到的embeding来替代原先启发式的用户粉丝数,以及建模了整个转发路径的影响,而不仅仅是当前的转发用户。还有,我们使用了非参方式来灵活刻画学习特征和学习时间的衰减效应。
感兴趣的同学可以在ACM的论文库里下载这篇论文。论文题目:DeepHawkes:Bridging the Gap between Prediction and Understanding of Information Cascade
如果您对DeepHawkes模型的细节感兴趣,点击阅读原文观看 GAIR 大讲堂完整回放视频。
————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
上海交通大学博士讲师团队
从算法到实战应用,涵盖CV领域主要知识点;
手把手项目演示
全程提供代码
深度剖析CV研究体系
轻松实战深度学习应用领域!
详细了解请扫码入群
▼▼▼

————————————————————





