ICLR 2020 | 用ELECTRA实现更高效的NLP模型预训练
背景
题目:ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
机构:斯坦福、Google Brain
作者:Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning
论文地址:
https://www.aminer.cn/pub/5e5e18d593d709897ce33b3c/electra-pre-training-text-encoders-as-discriminators-rather-than-generators
摘要
MLM(Masked language modeling)方式的预训练语言模型如 BERT 是在输入上用 [MASK] 遮蔽掉部分 tokens,再训练一个模型以重建出原始的 tokens。这种方式迁移到下游 NLP 任务时能够得到较好的结果,已然成为 NLP 任务中的标配。但是这种预训练方法往往需要大量的算力。为此,本文提出一种样本效率更为高效的预训练任务:替换 token 检测(replaced token detection, RTD)。RTD 不对输入进行遮蔽,而是从生成器中采样得到可信的 tokens,再替换掉原始输入上的 tokens。本文不再训练模型预测输入中的原始 tokens,而是训练一个判别器以辨别输入中每个 token 是否是由生成器生成。通过实验表明这种新的预训练任务比 MLM 更高效,该任务定义于全部的输入 tokens,而非仅仅被遮蔽掉的那一部分小小的输入子集。实验结果表明本文方案所学习到的上下文表征大大优于相同模型大小、相同数据量和相同算力下的 BERT。这种收益在小模型上更加显著,比如在 GLUE 自然语言理解基准上,单块 GPU 训练 4 天的结果优于 GPT(算力比其高 30 倍+)。本文的方法在大模型上也很有成效,只使用 RoBERTa 和 XLNet 四分之一算力即可取得与之比肩的结果,在相同算力下轻松超越对方。
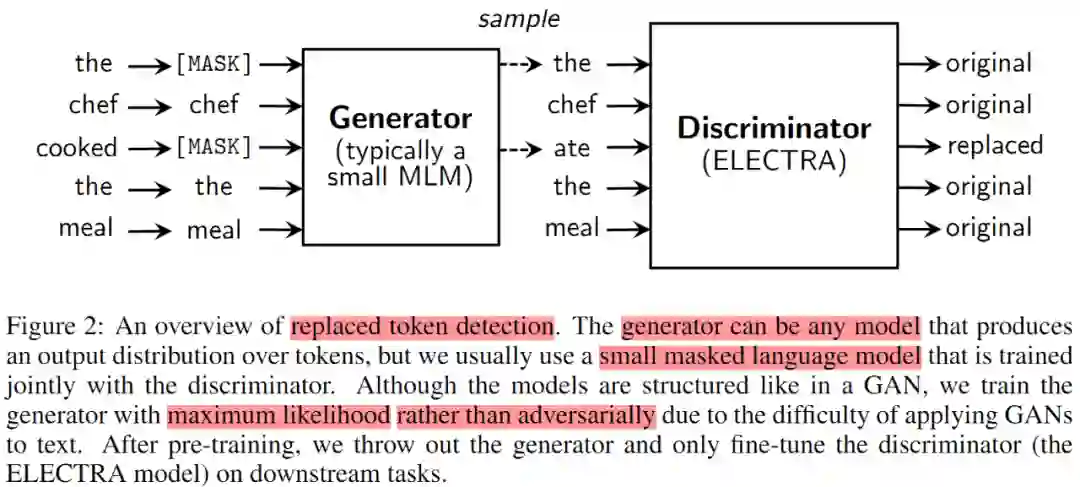
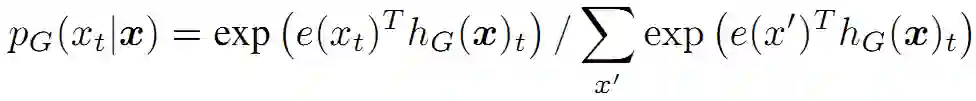
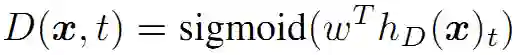
训练的生成器是为了执行MLM。给定输入列,MLM先选择一些随机的位置进行遮蔽,遮蔽集合记为m。这些被选中的 tokens 被用 [MASK] token 替换。生成器学习预测出被遮蔽掉的原始 token。至于训练的判别器则是为了能够鉴别出 token 是否是来自生成器。通过生成器生成的 token 替换原始字符,再训练判别器鉴别出哪些 token 和原始输入相匹配。
总结下,模型根据以下式子重建输入:
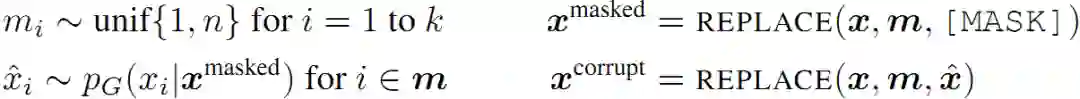
其中 REPLACE 是定义的替换操作。第一个是用 [MASK] 替换,第二个是用生成器生成的字符替换。
对应的损失函数分别如下:
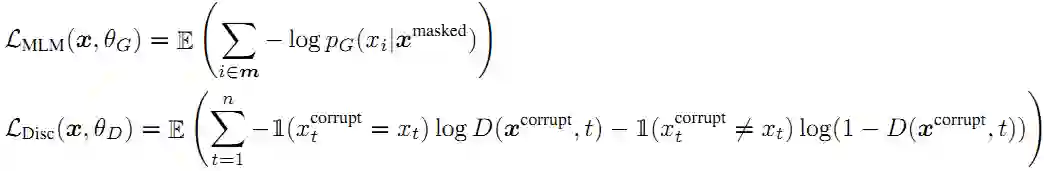
第一,当生成器碰巧生成正确的 token,则该 token 被视为真实的,而非假冒的。实验发现这种方式可以一定程度上地改善下游任务。
第二,生成器的训练是基于最大似然而非对抗训练。后者试图在训练过程中骗过判别器。对抗训练在这里很难实现,究其原因在于无法通过从生成器采样来进行反向传播。尽管本文也尝试使用强化学习的方式训练生成器从而绕开这个问题(附件 F),但是效果仍不及最大似然的训练方式。
第三,不像 GAN 那样在生成器的输入中添加噪声。
最终最小化联合损失:
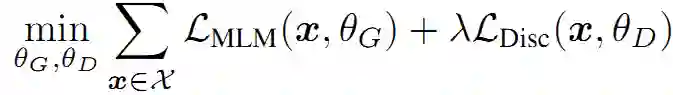
实验过程中用单样本来近似损失的期望。同时不把判别器的损失反向传播到生成器,采样的步骤也做不到。在预训练之后,丢弃生成器,并在下游任务中对判别器进行微调。
实验
实验设置
为验证文本方法的有效性,在 GLUE 和 SQuAD 上进行实验。预训练数据集分两种情况:第一种是和 BERT 对比,则采用 Wikipedia 和 BooksCorpus 数据集,合计大概 3.3 Billion tokens;第二种是和 XLNet 对比,则与其相同的数据集进行预训练,即 ClueWeb、CommonCrawl 和 Gigaword,合计 33 Billion tokens。
本文的模型架构和超参数总体上和 BERT 相同。在微调阶段,对于 GLUE 则在 ELECTRA 的顶部增加一个简单的线性分类器;对于 SQuAD 则借用 XLNet 中的问-答模块,将其加到 ELECTRA 的顶部。之所以这部分借用 XLNet,是由于该模块比 BERT 更精细,起始位置和终点位置是联合预测的,而不像 BERT 那样两者各自独立,另外对于 SQuAD2.0 该模块还有能否回答的分类器。需要注意的是,一些评估数据集很小,这意味着微调模型的准确性可能会随着随机种子的不同而发生很大的变化。因此,最终报告结果是从相同的预先训练的检查点运行 10 次微调的中位数。
模型拓展
第一,权重共享。
生成器和判别器权重参数共享可以提高预训练的效率。当生成器和判别器大小相同,则二者的所有 transformer 权重都可以密切相连。但是,实验中发现较小的生成器更为高效,这使得只能共享生成器和判别器的嵌入参数(包括 token 嵌入和位置嵌入)。这种情况下,使用的嵌入大小是根据判别器隐状态的嵌入尺寸。在生成器中添加一个线性变换层以将嵌入投射为生成器隐状态尺寸的表征。
实验对比了生成器和判别器相同大小的情况。在 GLUE 中,权重完全无关时的得分为 83.6,共享 token 嵌入时的得分为 84.3,共享所有权重时的得分为 84.4。可以猜想本文的模型得益于共享 token 嵌入的方案,可能是 MLM 在学习以下表征上更为有效:
- 仅当输入中有生成器生成的 token 时判别器才会更新。生成器的 softmax 在整个词典上密集更新所有的 token 嵌入。
- 完全关联生成器和判别器的权重几乎没有什么提升,却需要生成器和判别器大小完全相同,这得不偿失。
基于上述这些发现,最终选用共享嵌入参数。
第二,较小的生成器。
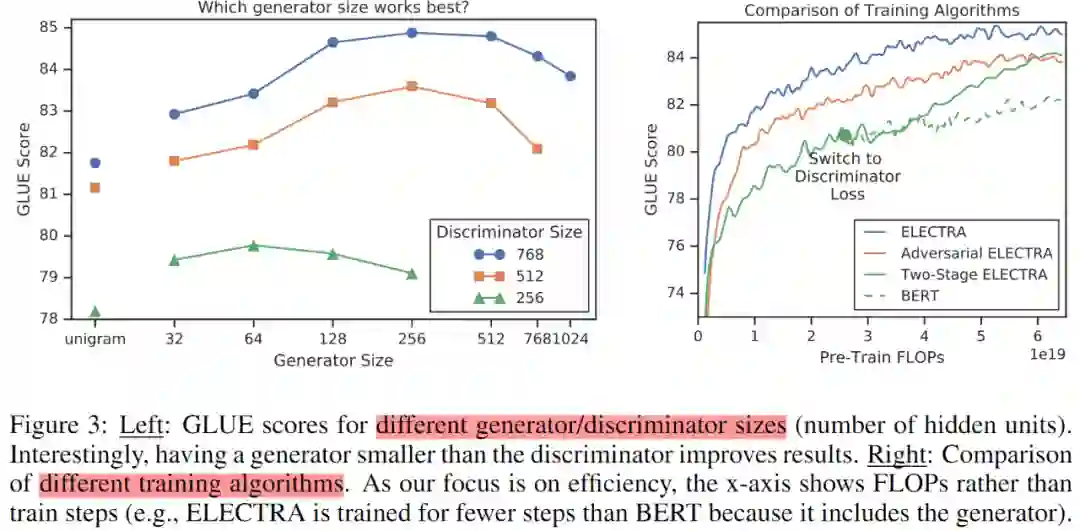
如果生成器和判别器大小相同,则训练 ELECTRA 每步需要的计算量大约是只使用 MLM 训练的两倍。为此,本文使用较小的生成器以降低该因素的影响。具体是降低层的大小,同时保持其他超参数恒定不变。此外,本文还尝试了一个极简的 unigram 生成器,该生成器根据训练语料中的频率采样生成假的 tokens。不同大小的生成器和判别器在 GLUE 上的得分如 Figure 3 中左图所示。
第三,训练方法。
本文还进一步探索了 ELECTRA 的其他训练方法。尽管这些探索性工作并没有最终改善结果。探索的训练方法使用以下两阶段的训练流程:
1. 只训练生成器,训练 n 步。
2.用生成器的权重初始化判别器。再训练判别器,训练 n 步,同时固定住生成器的权重。
上述提到的权重初始化要求生成器和判别器的大小相同。实验中发现,如果判别器没有这个权重初始化操作,那么有时会甚至在大多数类之外学习失败。这可能是由于此时的生成器已远远领先于判别器。联合训练的方式另一方面天然地为判别器提供了一个总纲,在这个总纲中,生成器一开始很弱,但在整个训练过程中变得越来越好。此外本文还探索了如同 GAN 那般使用对抗方式训练生成器,具体使用强化学习来适应离散操作的采样生成器。具体参考附件 F。
各种训练方法的对比如 Figure 3 右图所示。从中可以看出,对于两阶段的训练方法,当将生成目标转为判别目标后,下游任务的性能得到显著提升,但是最终没有超过联合训练方案。至于对抗训练方案,尽管超过了 BERT,但是仍然逊色于最大似然训练方法。这之间的差距可能源于以下 2 个因素:
第一,对抗方式训练生成器在 MLM 上表现更差,只能取得 58% 的准确率,而最大似然的训练方案可以取得 65% 的准确率。准确率较差的主要原因是在生成文本的庞大动作空间中,强化学习的样本效率较低。
第二,对抗方式训练的生成器产生一个低熵输出分布,其中大部分概率集中在单个 token 上,这意味着生成器生成的样本中没有太多的多样性。
先在 Small 版模型上对比本文预训练方案的有效性。Small 版模型与 BERT-Base 的超参数基本相同,只是将序列长度由原来的 512 缩短为 128,batch size 由原来的 256 降低为 128,隐层维度由原来的 768 缩减为 128。为公平起见,用上述超参数也训练一个 BERT-Small。各个模型的 Small 版在 GLUE dev 数据集上的对比详情如 Table 1 所示。
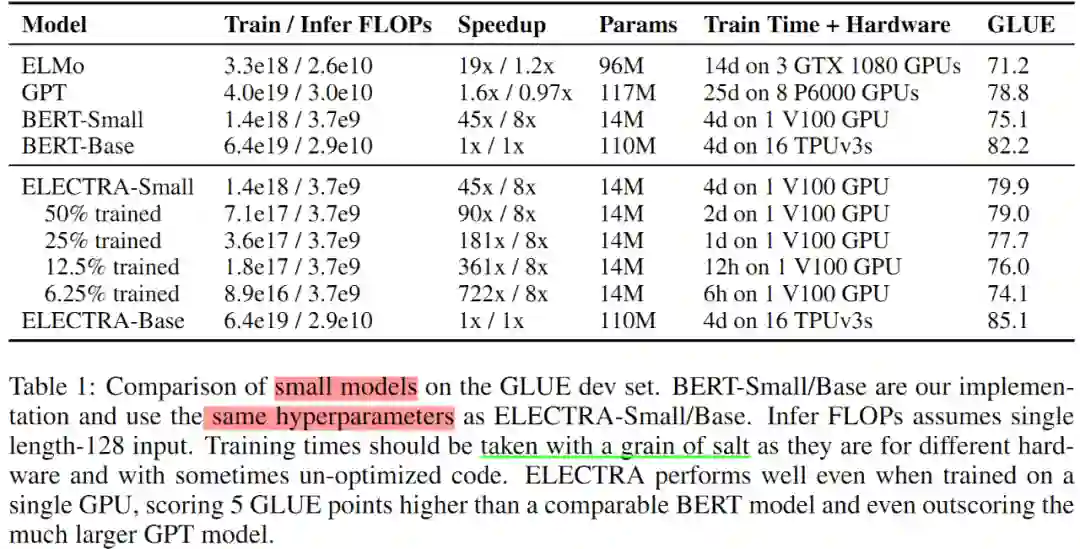
实验结果还表明 ELECTRA 在中度大小的模型上依然有效,ELECTRA-Base 显著优于 BERT-Base,甚至超越 BERT-Large(GLUE 得分为 84)。
此外,训练 ELECTRA-Large 以验证 RTD 预训练任务在大规模先进的 Transformers 模型中的有效性。ELECTRA-Large 和 BERT-Large 大小一致,但是后者训练耗时更久。ELECTRA-400k 模型仅训练 400k 个 steps,大概是 RoBERTa 的 1/4;ELECTRA-1.75M 模型则是训练了 1.75M 个 steps,所耗算力与 RoBERTa 相当。使用 2048 的 batch size,数据集是来自于 XLNet 的预训练数据集。Large 版模型在 GLUE dev 数据集上的实验结果如 Table 2 所示。
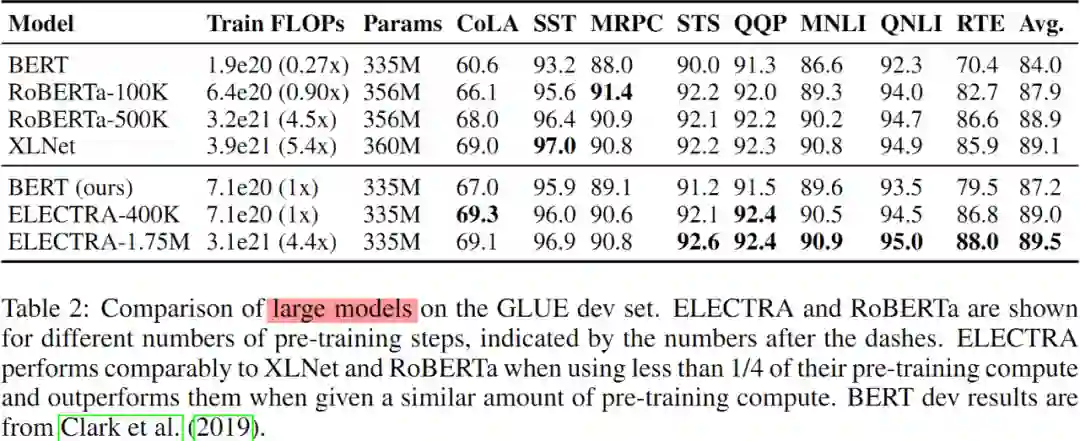
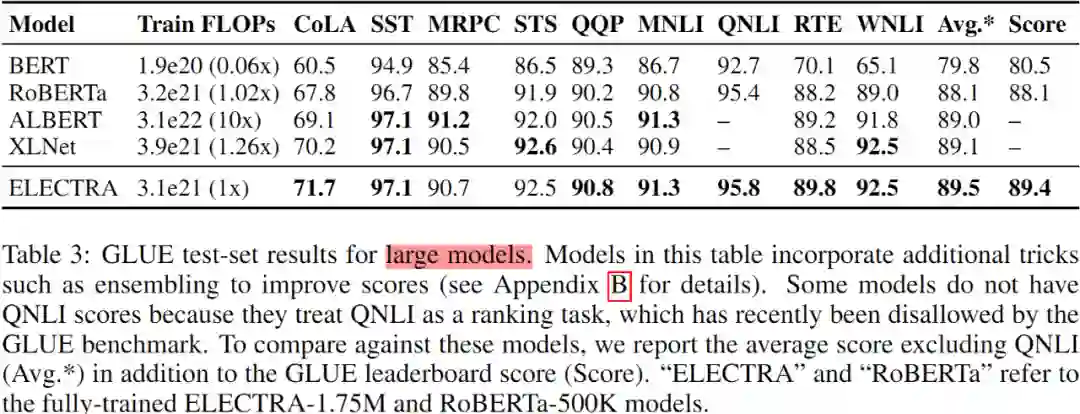
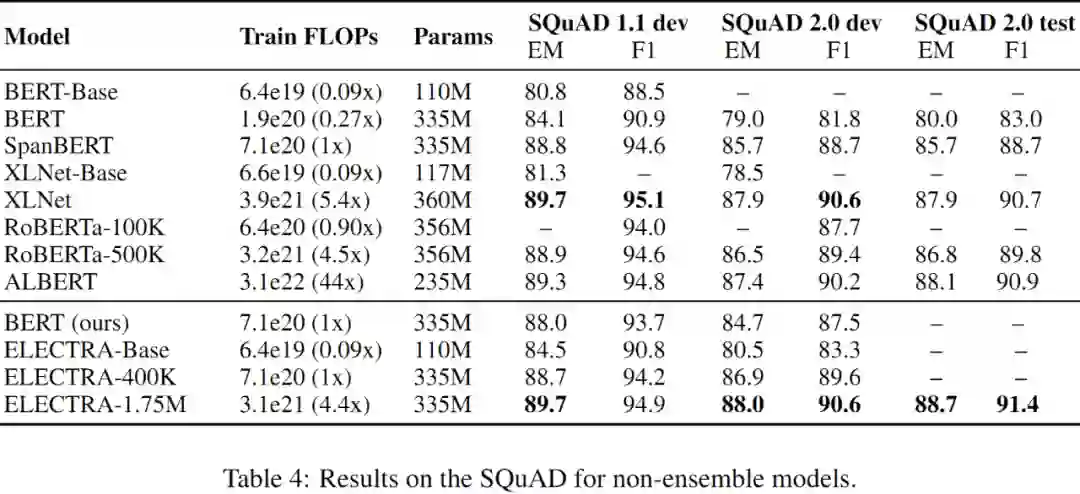
有效性分析
ELECTRA 15%:
这与 ELECTRA 大致相同,仅有的不同的在判别器的损失仅来自于输入中被遮蔽的 15%tokens。换句话说,$\mathcal{L}_{\mathrm{Disc}}$ 中 $i$ 的不再是 1-n,而是 $i \in m$。
Replace MLM:
该目标与 MLM 大致相同,所唯一不同的是不使用 [MASK] 替换 tokens,而是用生成器生成的 token 替换。这一目标测试了 ELECTRA 的收益在多大程度上来自于预训练期间解决的将模型暴露于 [MASK] tokens 的不一致问题,而不是微调阶段。
All-TokensMLM:
与 Replace MLM 类似,该目标的替换 token 也是来自生成器。所不同的是,模型预测输入中的所有 tokens,而不再仅仅是被遮蔽掉的那些。实验发现当模型有显性的拷贝机制时,效果更好。这种拷贝机制采用一个 sigmoid 层控制每个输入 token 的输出拷贝概率为 $D$。模型的输出分布由输入 token 的 D 权值,再加上 1-D 乘以 MLM softmax 的输出。该模型本质上是 BERT 和 ELECTRA 的结合体。需要注意的是,如果没有生成器生成替换字符,模型将很容易地学会从 [MASK] 标记的词汇表中进行预测,并从输入中直接拷贝其他 token。
上述的对比结果如 Table 5 所示:

第一,ELECTRA 很大程度上受益于基于所有输入 token 定义的损失。采用 15% 子集定义的损失逊色于 ELECTRA。
第二,从 Replace MLM 略胜 BERT,可以看出 BERT 预训练时引入的 [MASK] token 导致微调的不一致,确实略微有损性能指标。
第三,使用 All-Tokens MLM 方案的模型可以很大程度上缩减 BERT 和 ELECTRA 之间的差距。
总之:ELECTRA 模型的提升大部分可以归因于从所有 tokens 中学习,而小部分源于提升得益于减轻预训练-微调的不一致。
另外还对比了 BERT 和 ELECTRA 在不同模型尺寸下的表现,如 Figure 4 所示:
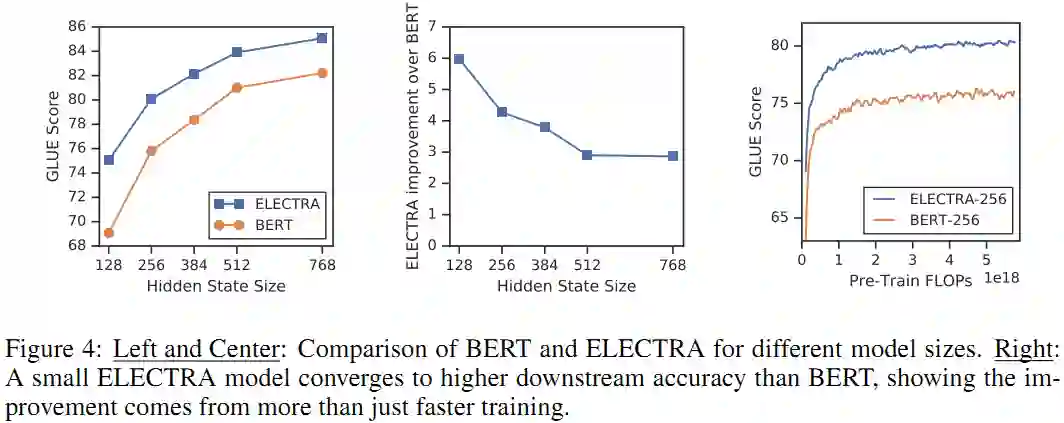
本文提出一个新的自监督任务:替换 Token 检测(RTD)。其核心是训练一个文本 encoder 以在输入 tokens 中鉴别出来自于小型生成器所生成的高质量负样本。对比于 MLM,本文的预训练目标计算更高效,在下游任务中能取得更优的结果。本文的方法即使在算力相对较少的情况下仍然有效,这对于算力贫困人士来说真是大大的福音。
作者:刘杰鹏(微信号:onepieceand)
毕业院校:华中科技大学
研究方向:机器阅读理解、文本生成等。
近期精彩集锦(点击蓝色字体跳转阅读):

点击阅读原文,一键直达 ICLR 2020 专题!




