阿里推出 PolarFS 分布式文件系统:将存储与计算分开,提升云数据库性能(附论文)
将存储与计算分开来大有意义,对于部署的云数据库而言更是如此。为此,阿里巴巴推出了一种新开发的名为PolarFS的分布式文件系统,旨在确保低延迟和高可用性。这个文件系统与阿里云上自己的PolarDB数据库服务搭配使用。

像PolarDB这样的云数据库服务(或者各大云提供商的平台上的同类云数据库服务)拥有一个更具可扩展性且安全的基础以便充分利用容器,并以快速I/O、检查点和数据共享来支持后端存储集群,从而充分发挥将存储资源和计算资源分开来的这种做法具有的好处。
然而,由于面向数据库服务的云I/O领域的种种创新,很难把大幅加快读写速度的硬件创新整合起来,比如包括RDMA和NVMe。从性能的角度来看,阿里巴巴的架构值得关注,原因在于它利用了RDMA、NVMe和SPDK等方面最新的创新技术,因而提供了与固态硬盘(SSD)上的本地文件系统不相上下的写入性能。
“PolarFS采用了新兴的硬件和最先进的优化技术,比如操作系统旁路(OS bypass)和零拷贝(zero-copy),因而得以拥有与SSD上的本地文件系统相当的延迟。为了满足数据库应用的高IOPS要求,我们开发了一种新的共识协议ParallelRaft。ParallelRaft放宽了Raft严格按顺序写入的要求,又不牺牲存储语义的一致性,从而提升了PolarFS并行写入的性能。在高负载情况下,我们的方法可以将平均延迟缩短一半,将系统带宽翻番。PolarFS在用户空间中实施类似POSIX的接口,这让POLARDB能够仅需少许改动即可提升性能。”
拥有数据库服务的云提供商提供最新的硬件调优从而提供高性能可能听起来合情合理,但实际操作起来不像听起来那么简单。正如阿里巴巴的研究人员解释的那样,云提供商使用实例存储作为服务的基础,使用本地SSD和高I/O虚拟机实例用于数据库。但是这种方法限制了容量,规模上去后更是如此。
此外,由于数据库需要自己处理复制,因此可靠性有所降低。最后,实例存储在其核心使用通用文件系统,试图采用RDMA或基于PCIe的SSD以提升性能时,内核与用户空间之间的消息传递成本带来了庞大的开销。
阿里巴巴自己的PolarDB服务过去存在着上述限制。现在,PolarFS已准备好充分利用I/O方面新的提升,包括RDMA和NVMe SSD,并结合用户空间中的轻量级网络堆栈和I/O堆栈,避免在内核中被锁定。PolarFS API类似POSIX,原因在于它可以编译到数据库进程中,并且可以取代操作系统提供的文件系统接口,而I/O路径继续留在用户空间中。
阿里巴巴团队还特别指出,PolarFS数据平面的I/O模型旨在消除锁定,并避免关键数据路径上的上下文切换(context switch)。“还消除了所有不必要的内存副本,而直接内存访问用于在主内存和RDMA网卡/ NVMe磁盘之间传输数据。”缩短延迟的效果在这环节来得尤为明显。
阿里巴巴在开发过程中也不得不考虑到可靠性。其硬件调优的核心是用于解决共识的Raft协议。“部署在云生产环境中的分布式文件系统通常有成千上万台计算机。在这样的庞大规模下,硬件或软件错误引起的故障很常见。因此,需要一种共识协议来确保所有已提交的修改都不会在极端情况下丢失,而副本总是可以达成协议,变成比特方面一模一样。”由于一开始就恪守这个理念,阿里巴巴开发出了ParallelRaft,确保这项功能在大规模环境下照样正常使用。
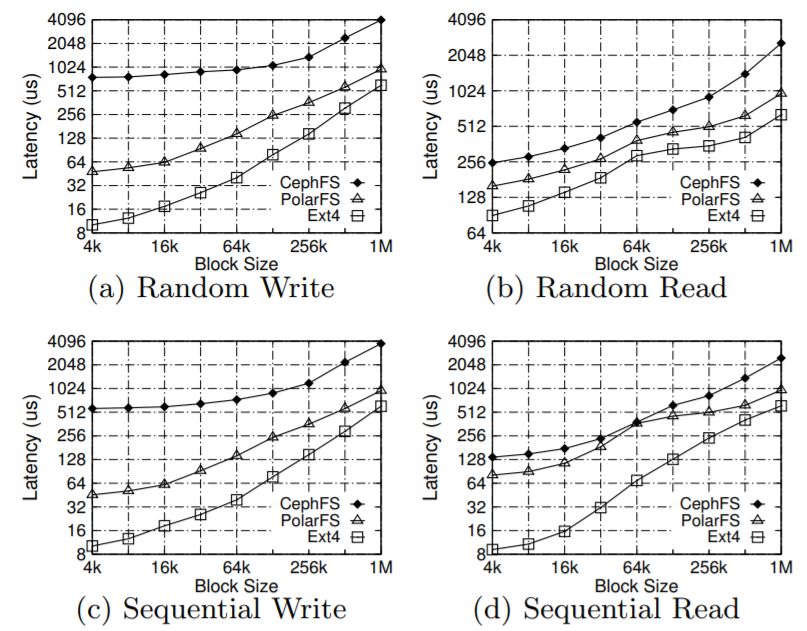
PolarFS的延迟是4000个随机写入约48μs,这相当接近本地SSD上的Ext4的延迟(约10μs),而相比之下,CephFS的延迟却长达约760μs。PolarFS的平均随机写入延迟比本地Ext4慢1.6倍到4.7倍,而CephFS的平均随机写入延迟比本地Ext4慢6.5倍到75倍,这意味着分布式PolarFS几乎提供了与本地Ext4相同的性能。
关于性能结果和硬件调优的完整内容可以在这篇详细的论文: