知识图谱从哪里来:实体关系抽取的现状与未来
本文是清华大学刘知远老师和学生韩旭、高天宇所写的关于知识图谱相关的介绍。文章回顾了知识图谱领域的发展历程,并综述了近年来的研究进展,机器之心获授权转载。
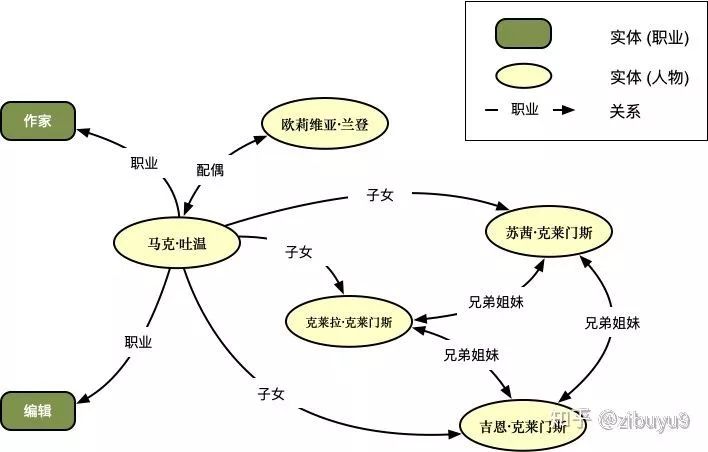

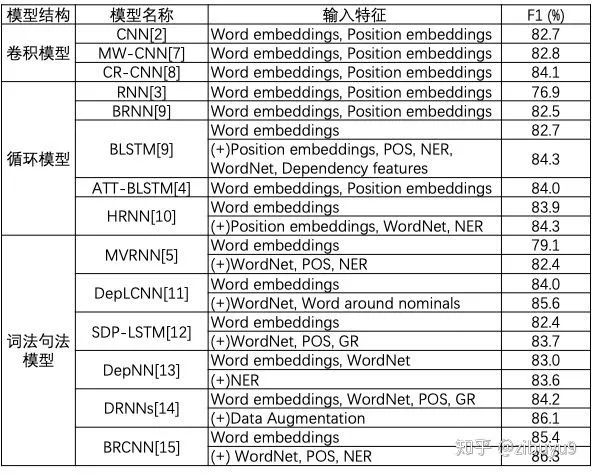
数据规模问题:人工精准地标注句子级别的数据代价十分高昂,需要耗费大量的时间和人力。在实际场景中,面向数以千计的关系、数以千万计的实体对、以及数以亿计的句子,依靠人工标注训练数据几乎是不可能完成的任务。
学习能力问题:在实际情况下,实体间关系和实体对的出现频率往往服从长尾分布,存在大量的样例较少的关系或实体对。神经网络模型的效果需要依赖大规模标注数据来保证,存在」举十反一「的问题。如何提高深度模型的学习能力,实现」举一反三「,是关系抽取需要解决的问题。
复杂语境问题:现有模型主要从单个句子中抽取实体间关系,要求句子必须同时包含两个实体。实际上,大量的实体间关系往往表现在一篇文档的多个句子中,甚至在多个文档中。如何在更复杂的语境下进行关系抽取,也是关系抽取面临的问题。
开放关系问题:现有任务设定一般假设有预先定义好的封闭关系集合,将任务转换为关系分类问题。这样的话,文本中蕴含的实体间的新型关系无法被有效获取。如何利用深度学习模型自动发现实体间的新型关系,实现开放关系抽取,仍然是一个」开放「问题。
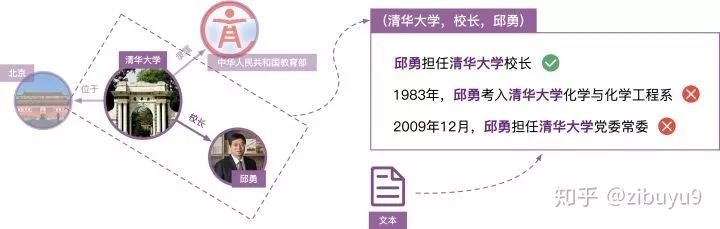
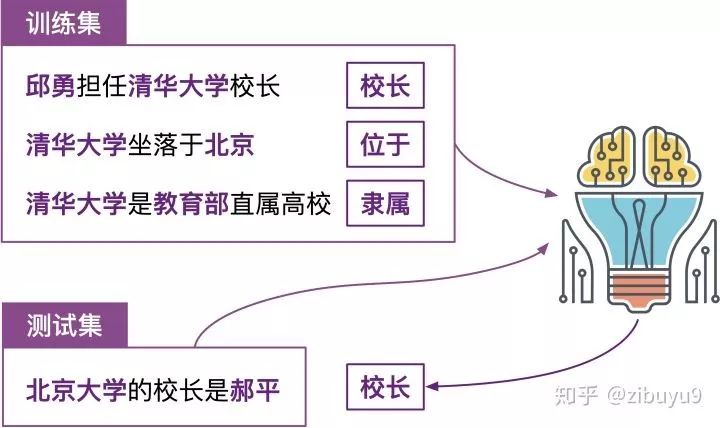
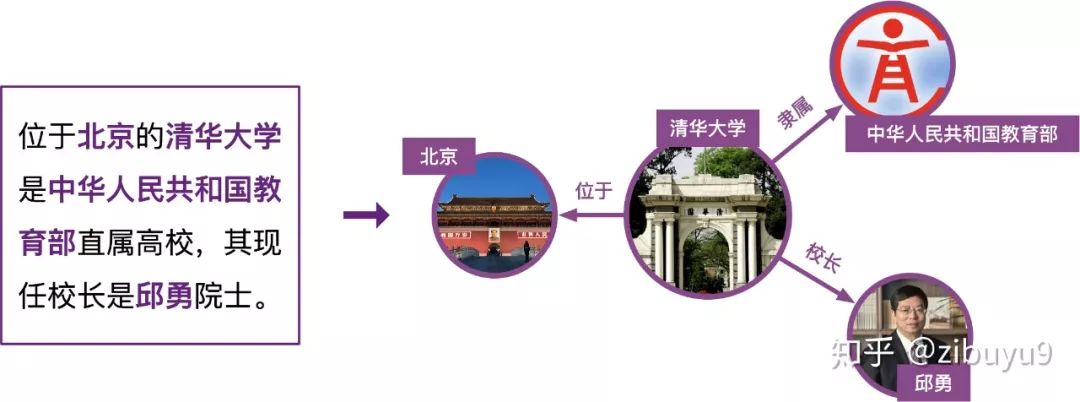


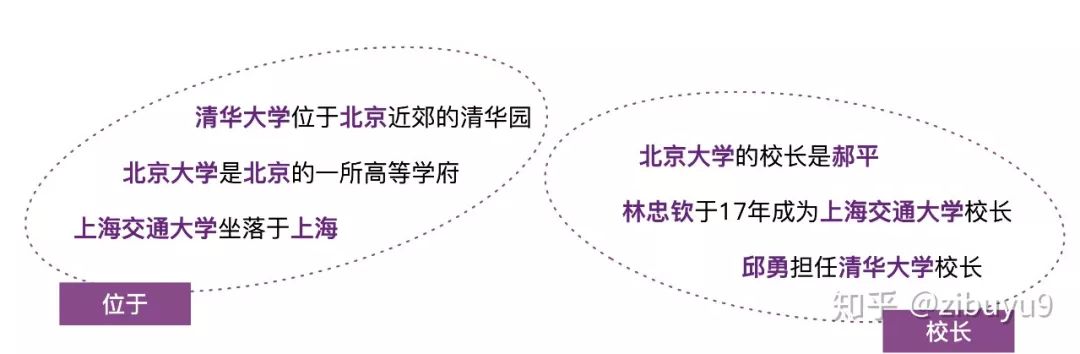


登录查看更多
相关内容

Arxiv
5+阅读 · 2019年9月26日
Arxiv
12+阅读 · 2019年9月26日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年9月26日
Arxiv
12+阅读 · 2019年9月26日