机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文包括腾讯 PCG 应用研究中心提出的利用生成人脸先验 GFP 的人脸复原模型 GFP-GAN;希伯来大学、特拉维夫大学、Adobe 等机构的研究者提出了一种名为「StyleCLIP」的模型;复旦大学自然语言处理实验室发布模型鲁棒性评测平台 TextFlint等。
Towards Real-World Blind Face Restoration with Generative Facial Prior
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
FP-NAS: Fast Probabilistic Neural Architecture Searc
Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations, and MoreStablePose: Learning 6D Object Poses from Geometrically Stable Patches
StablePose: Learning 6D Object Poses from Geometrically Stable Patches
Convolutional Neural Opacity Radiance Fields
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Towards Real-World Blind Face Restoration with Generative Facial Prior
摘要:
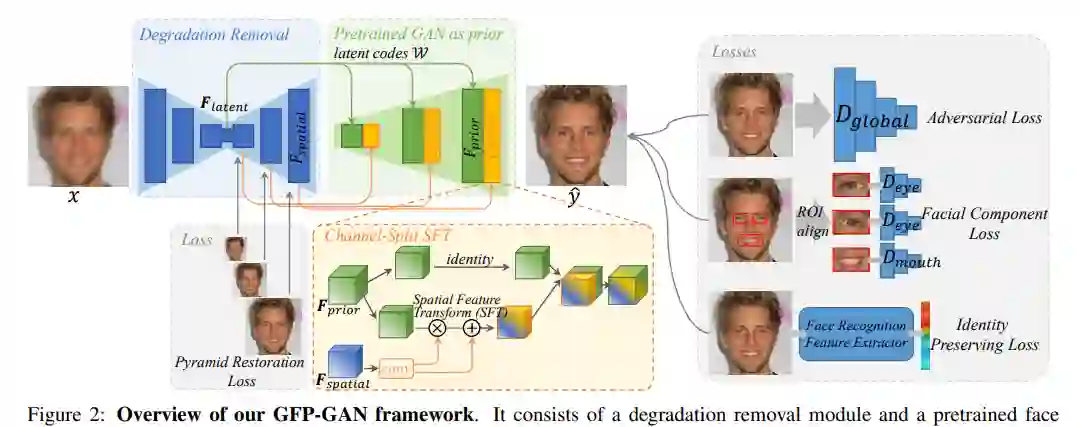
真实世界的人脸复原是一个盲问题,即我们不清楚降质过程, 在实际应用中,同时也面临着各种各样降质过程的挑战。对于人脸这个特定的任务, 之前的工作往往会探索人脸特定的先验, 并且取得了较好的效果。与此同时, 生成对抗网络 GAN 的蓬勃发展, 特别是 StyleGAN2 能够生成足够以假乱真的人脸图像给来自腾讯 PCG 应用研究中心 (ARC) 的研究者们提供了一个思路: 是否可以利用包含在人脸生成模型里面的「知识」来帮助人脸复原呢?
研究核心利用了包含在训练好的人脸生成模型里的「知识」, 被称之为生成人脸先验 (Generative Facial Prior, GFP)。它不仅包含了丰富的五官细节, 还有人脸颜色, 此外它能够把人脸当作一个整体来对待, 能够处理头发、耳朵、面部轮廓。基于预训练好的生成模型, 研究者们提出了利用生成人脸先验 GFP 的人脸复原模型 GFP-GAN。相比于近几年其他人脸复原的工作, GFP-GAN 不仅在五官恢复上取得了更好的细节, 整体也更加自然, 同时也能够对颜色有一定的增强作用。
![]()
![]()
CelebA-Test 数
据集上盲脸修复的效果对比。
![]()
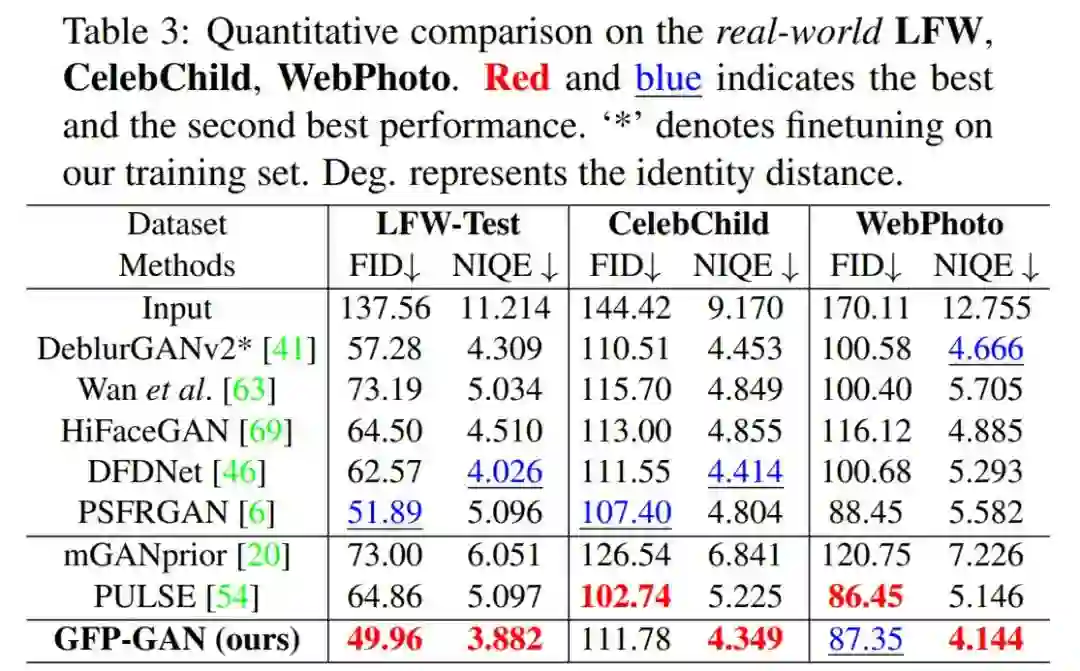
在实际人脸测试指标上,GFP-GAN 也具有较好的 FID 和 NIQE。
推荐:
五官复原效果惊艳,腾讯 ARC 利用 GAN 人脸先验来解决。本文也被 CVPR 2021 会议接收。
论文 2:StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
摘要:
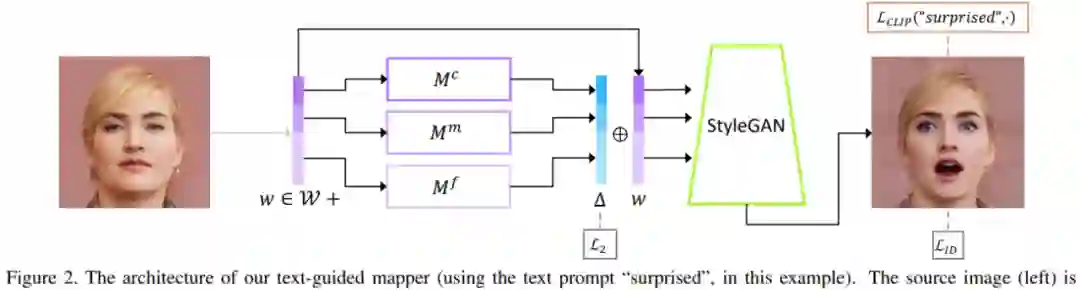
有人认为,自然语言将是软件的下一代接口:你有什么需求,「告诉」它就行了,剩下的不用你管。这种「动动嘴皮子就能把事儿办了」的场景似乎也越来越多。在最近的一篇论文中,来自希伯来大学、特拉维夫大学、Adobe 等机构的研究者提出了一种名为「StyleCLIP」的模型,几乎可以让你动动嘴皮子就把图修了。这里用「几乎」是因为研究者给出的接口其实还是文字版的。
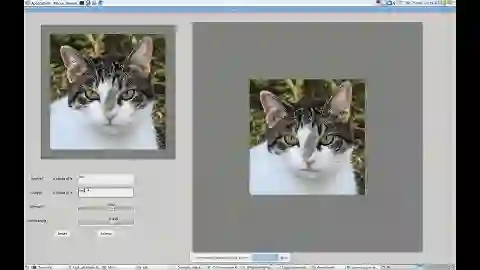
如下图所示,如果你想让一只猫看起来可爱一点,只需要输入「cute cat」,模型就能够把猫的眼睛放大,同时改变其他影响其可爱值的特征。
![]()
![]()
![]()
推荐:
修图动口不动手,有人把 StyleGAN 和 CLIP 组了个 CP,能听懂修图指令那种。
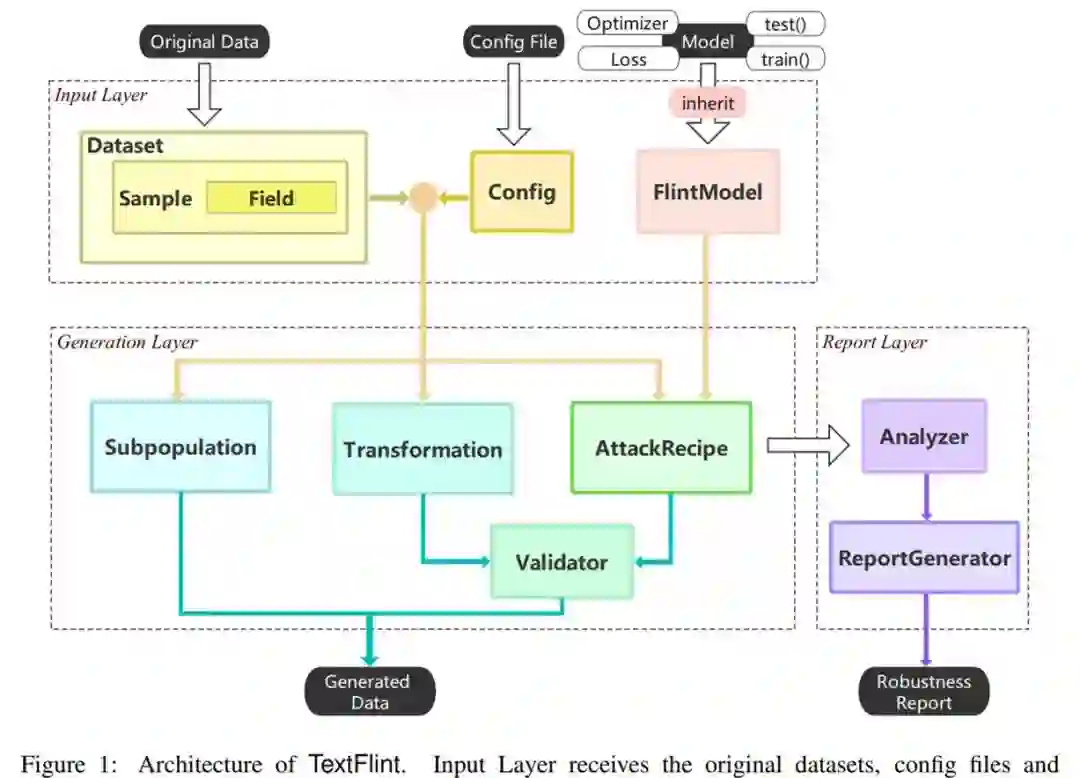
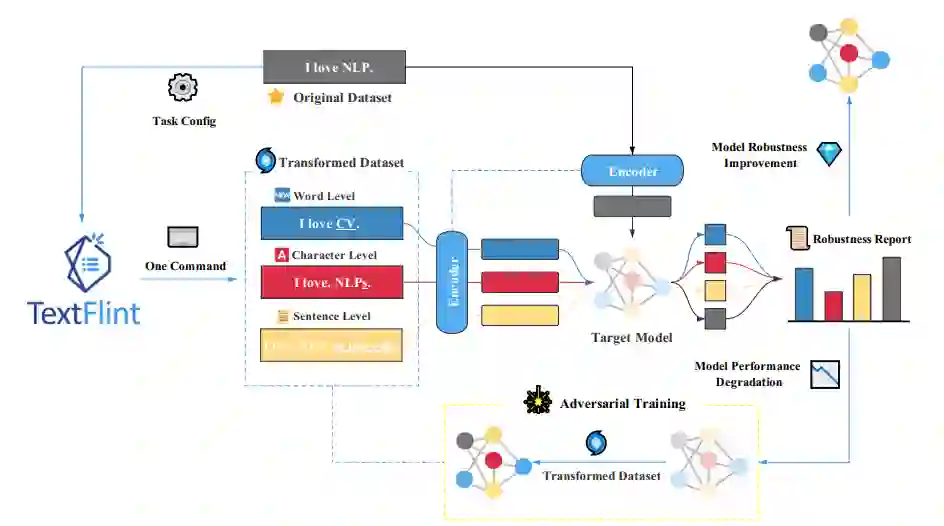
论文 3:TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
摘要:
复旦大学自然语言处理实验室发布模型鲁棒性评测平台 TextFlint。该平台涵盖 12 项 NLP 任务,囊括 80 余种数据变形方法,花费超 2 万 GPU 小时,进行了 6.7 万余次实验,验证约 100 种模型,选取约 10 万条变形后数据进行了语言合理性和语法正确性人工评测,为模型鲁棒性评测及提升提供了一站式解决方案。
![]()
![]()
![]()
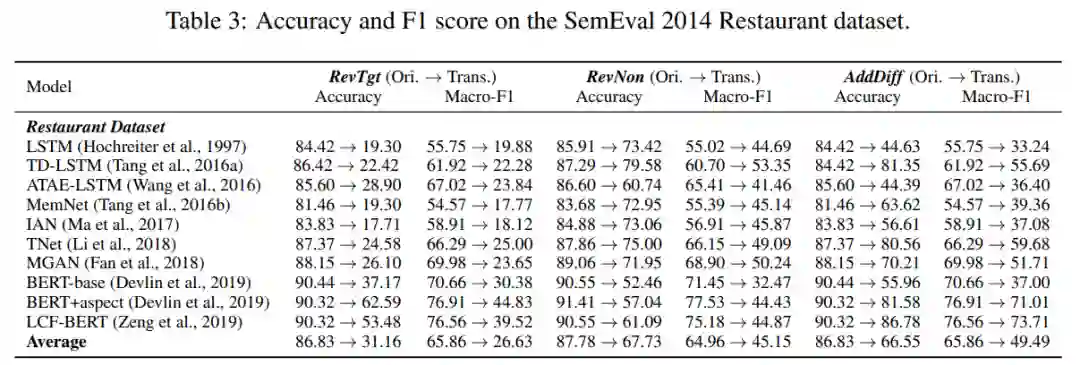
SemEval 2014 Restaurant 数据集上的准确率和 F1 分数对比。
推荐:
模型鲁棒性好不好,复旦大学一键式评测平台告诉你。
论文 4:FP-NAS: Fast Probabilistic Neural Architecture Search
摘要:
就职于 Facebook AI 的严志程博士和他的同事最近在 CVPR 2021 发表了关于加速概率性神经架构搜索的最新工作。该工作提出了一种新的自适应架构分布熵的架构采样方法来显著加速搜索。同时,为了进一步加速在多变量空间中的搜索,他们通过在搜索初期使用分解的概率分布来极大减少架构搜索参数。结合上述两种技巧,严志程团队提出的搜索方法 FP-NAS 比 PARSEC [1] 快 2.1 倍,比 FBNetV2 [2] 快 1.9-3.5 倍,比 EfficientNet [3] 快 132 倍以上。FP-NAS 可以被用于直接搜索更大的模型。搜索得到 FP-NAS-L2 模型复杂度达到 1.0G FLOPS,在只采用简单知识蒸馏的情况下,FP-NAS-L2 能够比采用更复杂的就地蒸馏的 BigNAS-XL [4] 模型,提高 0.7% 分类精度。
![]()
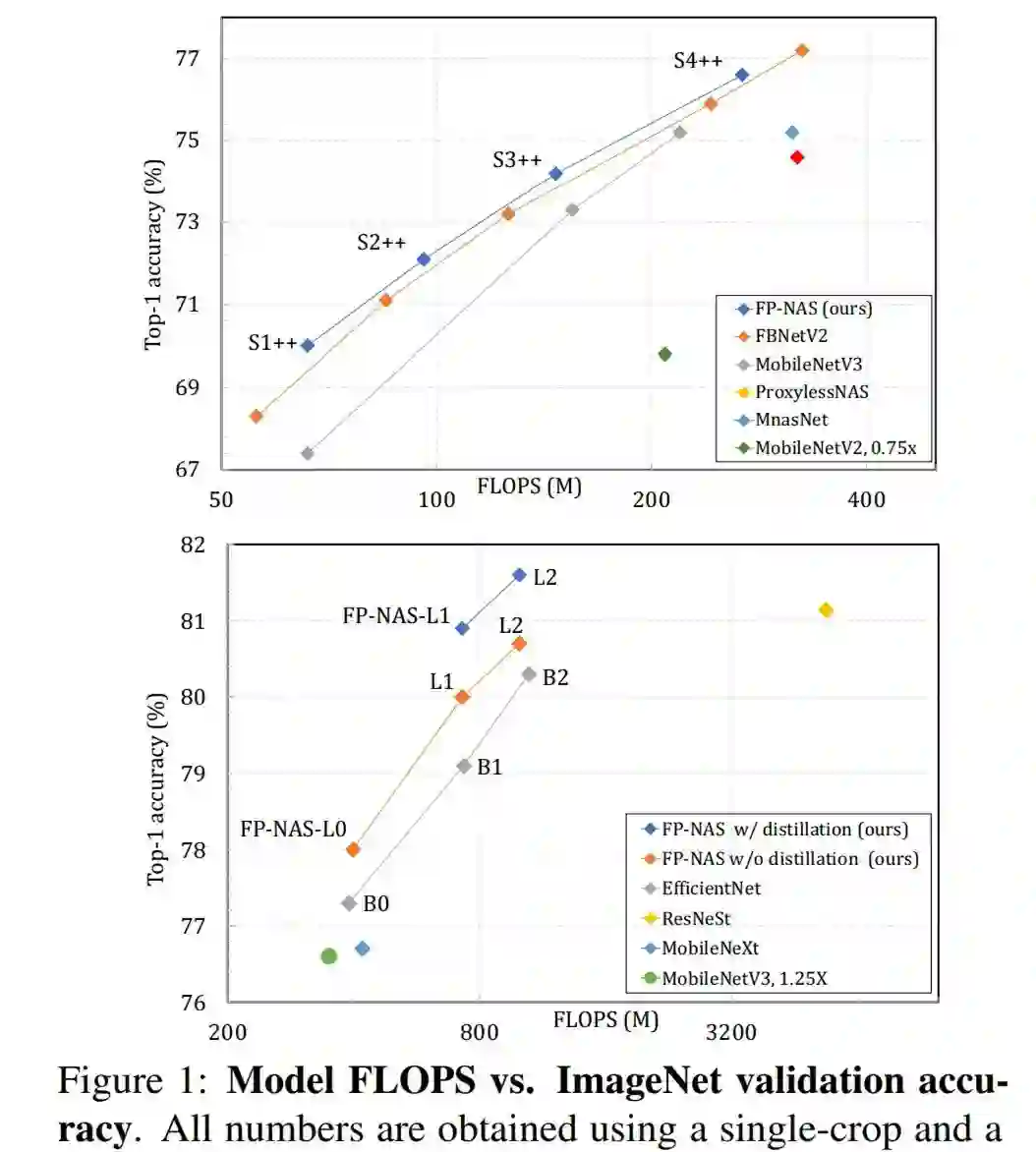
在 ImageNet 数据集上通过比较 FP-NAS 和其他 NAS 方法搜索得到的模型结果。
![]()
FBNetV2 和 FP-NAS 搜索空间的微架构。
![]()
三个包含不同复杂度模型的 FP-NAS 神经架构搜索空间。
推荐:
Facebook 提出 FP-NAS:搜索速度更快、分类精度更高、性能更好。本文被 CVPR 2021 会议接收。
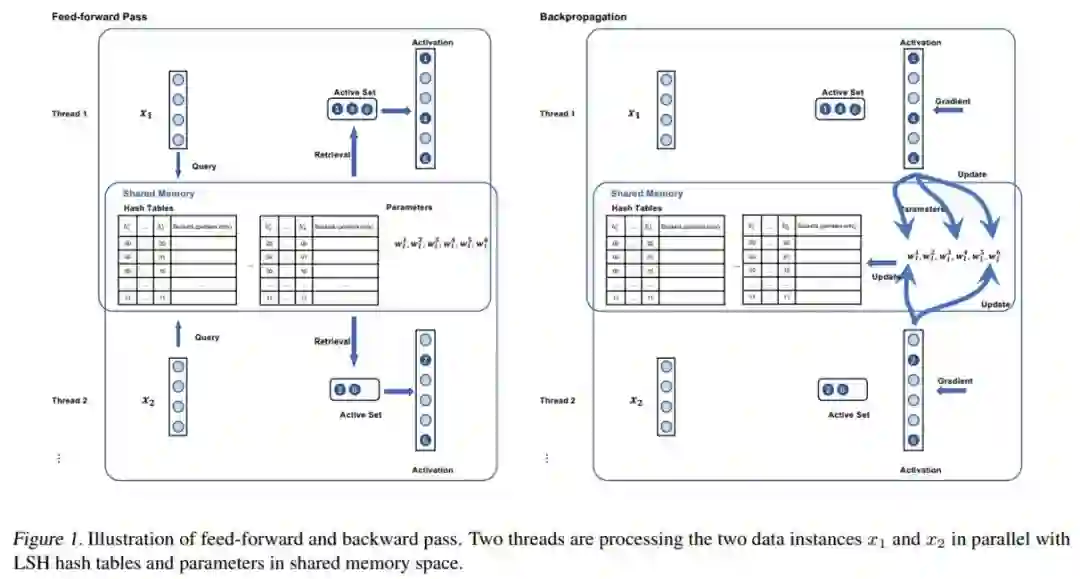
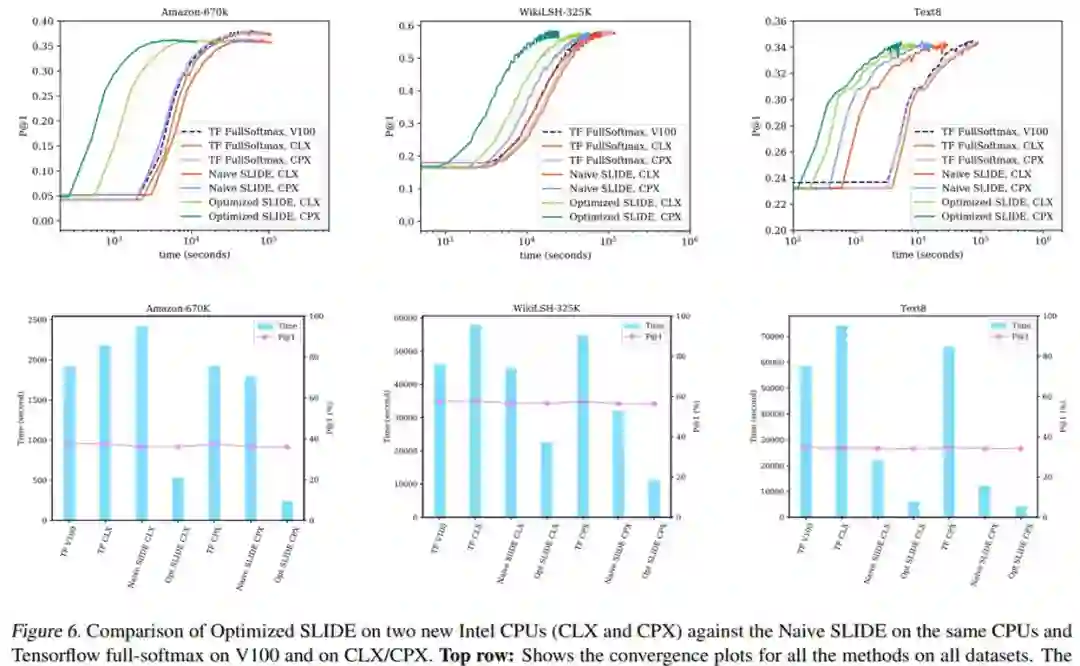
论文 5:Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations, and More
摘要:
在深度学习与神经网络领域,研究人员通常离不开 GPU。得益于 GPU 极高内存带宽和较多核心数,研究人员可以更快地获得模型训练的结果。与此同时,CPU 受限于自身较少的核心数,计算运行需要较长的时间,因而不适用于深度学习模型以及神经网络的训练。但近日,莱斯大学、蚂蚁集团和英特尔等机构的研究者发表了一篇论文,表明了在消费级 CPU 上运行的 AI 软件 SLIDE,其训练深度神经网络的速度是 GPU 的 15 倍。这篇论文已被 MLSys 2021 会议接收。
![]()
![]()
![]()
在英特尔 CLX 和 CPX 上,优化后的 SLIDE 与未优化的 SLIDE、英伟达 V100 和 CLX/CPX 上 Tensorflow full-softmax 的对比。
推荐:
CPU 比 GPU 训练神经网络快十几倍,英特尔:别用矩阵运算了。
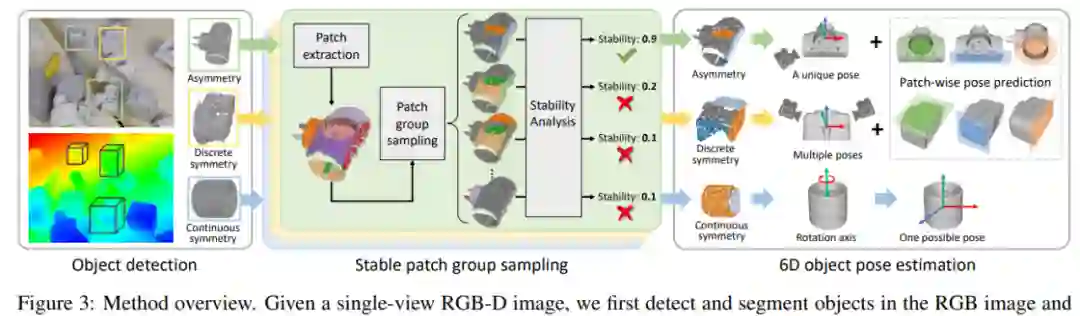
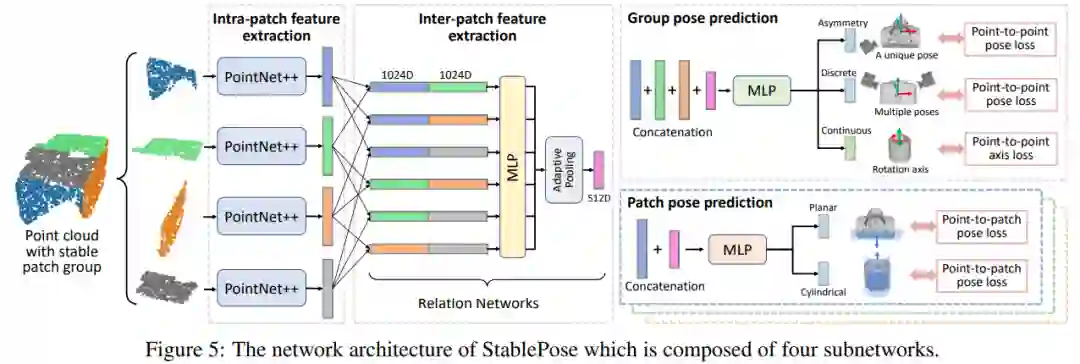
论文 6:StablePose: Learning 6D Object Poses from Geometrically Stable Patches
摘要:
近些年来,随着深度传感技术的快速发展,以 PPF 特征匹配算法为代表非学习方法和以 3DMatch 为代表的深度学习几何特征提取方法逐渐在位姿估计问题中崭露头角。这些方法虽然在多个公开数据集中取得了不错的效果,但是没有显式地约束几何特征提取和物体位姿的关系,因此制约了方法的可解释性和泛化性。针对这一问题,国防科技大学的研究人员将几何稳定性概念引入了物体 6D 姿态估计,并提出了利用物体表面几何稳定(Geometrically stable)的面片组合(Patch group)预测物体姿态的方法 StablePose。StablePose 物体位姿估计模块的输入只有物体的深度信息,不包括 RGB 图像,能够有效处理无纹理、弱纹理物体的位姿估计问题。实验表明,StablePose 在多个实例位姿估计和类别位姿估计数据集上取得了最佳性能,能够处理物体间遮挡,具有良好的泛化性。
![]()
![]()
由四个子网络组成的 StablePose 的网络架构图。
![]()
推荐:
基于几何稳定性分析的物体位姿估计方法。本文已被 CVPR 2021 会议接收。
论文 7:Convolutional Neural Opacity Radiance Fields
摘要:
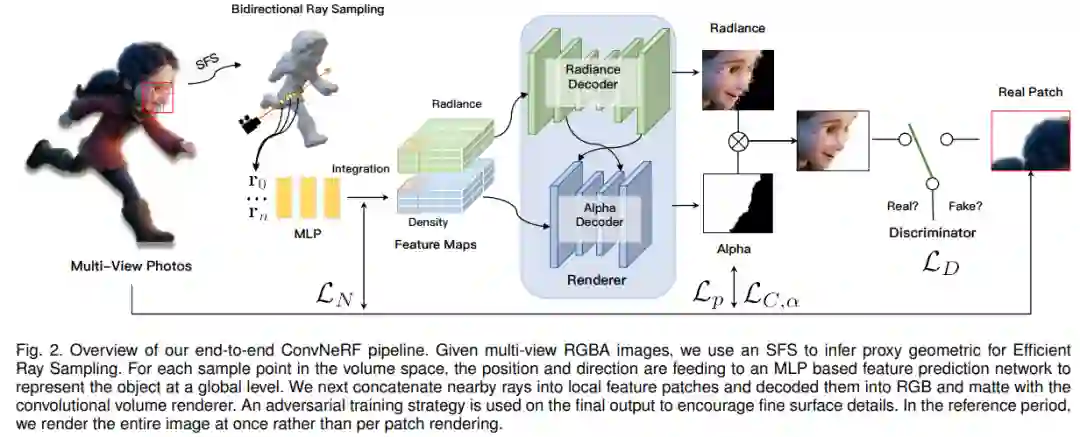
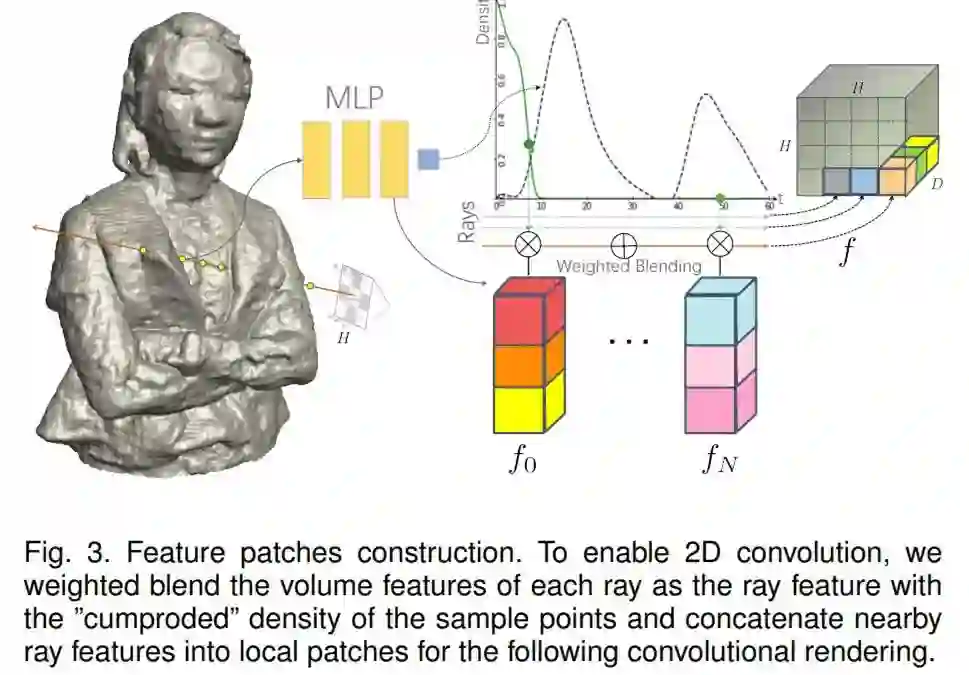
模糊复杂目标的高真实感建模和渲染对于许多沉浸式 VR/AR 应用至关重要,其中物体的亮度与颜色和视图强相关。在本篇论文中,来自上海科技大学等机构的研究者提出了一种使用卷积神经渲染器为模糊目标生成不透明辐射场的新方案,这是首个将显式不透明监督和卷积机制结合到神经辐射场框架中以实现高质量外观的方案,并以任意新视角生成全局一致的 alpha 蒙版。具体而言,该研究提出了一种有效的采样策略以及相机光线和图像平面,从而能够进行有效的辐射场采样,并以 patch-wise 的方式学习。同时,该研究还提出了一种新型的体积特征集成方案,该方案会生成 per-patch 混合特征嵌入,以重建视图一致的精细外观和不透明输出。此外,该研究进一步采用 patch-wise 对抗训练方案,以在自监督的框架中同时保留高频外观和不透明细节。该研究还提出了一种高效的多视图图像捕获系统,以捕获挑战性模糊目标的高质量色彩和 alpha 图。
![]()
![]()
![]()
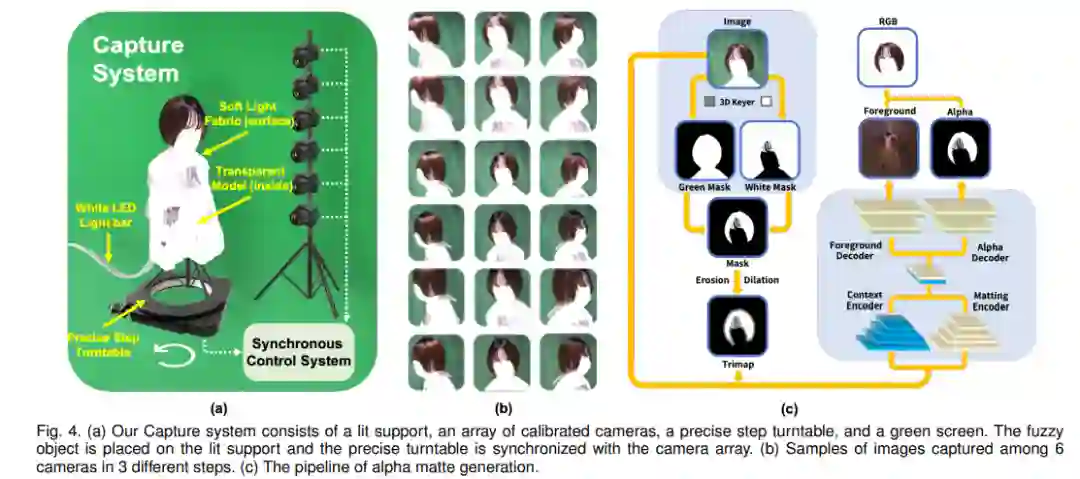
捕捉系统包含 lit support、一组校准摄像头、一个精确的步骤 turntable 和绿幕。
推荐:
在现有数据集和新的含有挑战性模糊目标的数据集上进行的大量实验表明,该研究提出的新方法可以对多种模糊目标实现高真实感、全局一致、外观精细的不透明自由视角渲染。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Who Should Go First? A Self-Supervised Concept Sorting Model for Improving Taxonomy Expansion. (from Jiawei Han)
2. Librispeech Transducer Model with Internal Language Model Prior Correction. (from Hermann Ney)
3. CURIE: An Iterative Querying Approach for Reasoning About Situations. (from Yiming Yang, Eduard Hovy)
4. Paired Examples as Indirect Supervision in Latent Decision Models. (from Dan Roth)
5. Statistically significant detection of semantic shifts using contextual word embeddings. (from Yang Liu)
6. Personalized Entity Resolution with Dynamic Heterogeneous Knowledge Graph Representations. (from Yang Liu)
7. StyleML: Stylometry with Structure and Multitask Learning for Darkweb Markets. (from Srinivasan Parthasarathy)
8. RNN Transducer Models For Spoken Language Understanding. (from Brian Kingsbury)
9. Action-Based Conversations Dataset: A Corpus for Building More In-Depth Task-Oriented Dialogue Systems. (from Yi Yang)
10. Multitask Recalibrated Aggregation Network for Medical Code Prediction. (from Erik Cambria)
1. C2CL: Contact to Contactless Fingerprint Matching. (from Anil K. Jain)
2. FedFace: Collaborative Learning of Face Recognition Model. (from Anil K. Jain)
3. Unified Detection of Digital and Physical Face Attacks. (from Anil K. Jain)
4. Localizing Visual Sounds the Hard Way. (from Andrea Vedaldi, Andrew Zisserman)
5. Local Metrics for Multi-Object Tracking. (from Cordelia Schmid)
6. Confidence Adaptive Anytime Pixel-Level Recognition. (from Trevor Darrell, Evan Shelhamer)
7. Strumming to the Beat: Audio-Conditioned Contrastive Video Textures. (from Alexei A. Efros, Trevor Darrell)
8. CAPTRA: CAtegory-level Pose Tracking for Rigid and Articulated Objects from Point Clouds. (from Hao Su, Leonidas J. Guibas)
9. Beyond Short Clips: End-to-End Video-Level Learning with Collaborative Memories. (from Larry Davis)
10. Learning Optical Flow from a Few Matches. (from Richard Hartley)
本周 10 篇 ML 精选论文是:
1. Hyperbolic Variational Graph Neural Network for Modeling Dynamic Graphs. (from Philip S. Yu)
2. STOPPAGE: Spatio-temporal Data Driven Cloud-Fog-Edge Computing Framework for Pandemic Monitoring and Management. (from Rajkumar Buyya)
3. The Multi-Agent Behavior Dataset: Mouse Dyadic Social Interactions. (from Pietro Perona)
4. Efficient Transformers in Reinforcement Learning using Actor-Learner Distillation. (from Ruslan Salakhutdinov)
5. Reinforcement Learning with a Disentangled Universal Value Function for Item Recommendation. (from Liang Chen)
6. Regularizing Generative Adversarial Networks under Limited Data. (from Ce Liu, Ming-Hsuan Yang)
7. PlasticineLab: A Soft-Body Manipulation Benchmark with Differentiable Physics. (from Hao Su, Joshua B. Tenenbaum)
8. Skillful Precipitation Nowcasting using Deep Generative Models of Radar. (from Karen Simonyan)
9. Deep Interpretable Models of Theory of Mind For Human-Agent Teaming. (from Katia Sycara)
10. Confidence Calibration for Domain Generalization under Covariate Shift. (from Thomas G. Dietterich)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com