TensorFlow的多平台基准测试

作者 | TensorFlow 团队
翻译 | 刘志勇
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
InceptionV3[2]、ResNet-50[3]、ResNet-152[4]、VGG16[5] 和 AlexNet[6] 使用 ImageNet[7] 数据集进行测试。测试环境为 Google Compute Engine、Elastic Compute Cloud (Amazon EC2) 和 NVIDIA® DGX-1™。大部分测试使用了合成数据和真实数据。使用合成数据进行测试是通过一个 tf.Variable 完成的,它被设置为与 ImageNet 的每个模型预期的数据相同的形状。我们认为,在基准测试平台中,包含真实数据的测量非常重要。这个负载测试底层硬件和框架,用来准备实际训练的数据。我们从合成数据开始,将磁盘 I/O 作为一个变量移除,并设置一个基线。然后,用真实数据来验证 TensorFlow 输入管道和底层磁盘 I/O 是否饱和的计算单元。
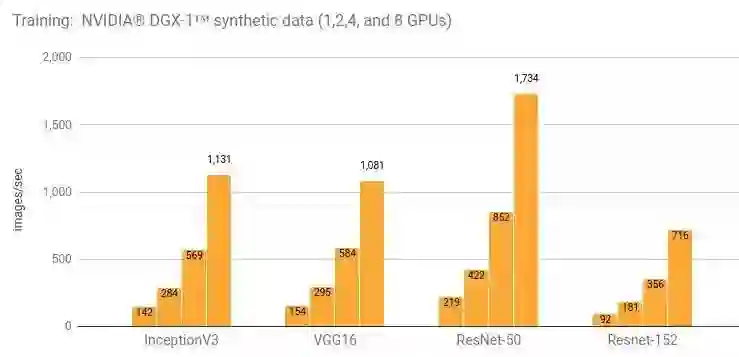
详情和额外的结果请参阅“NVIDIA® DGX-1™ (NVIDIA® Tesla® P100)”一节。
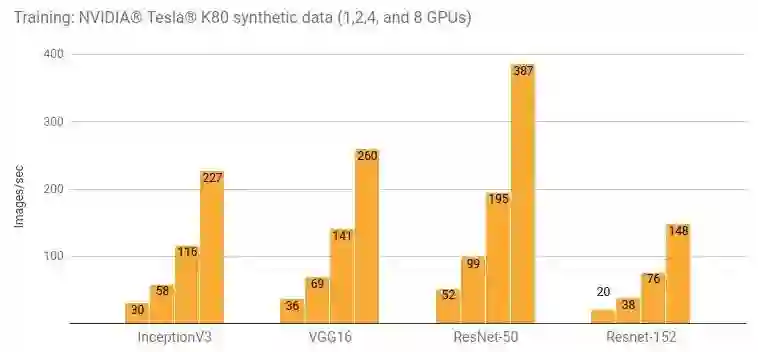
详情和额外的结果请参阅“Google Compute Engine (NVIDIA® Tesla® K80)”一节和“Amazon EC2 (NVIDIA® Tesla® K80)”一节。
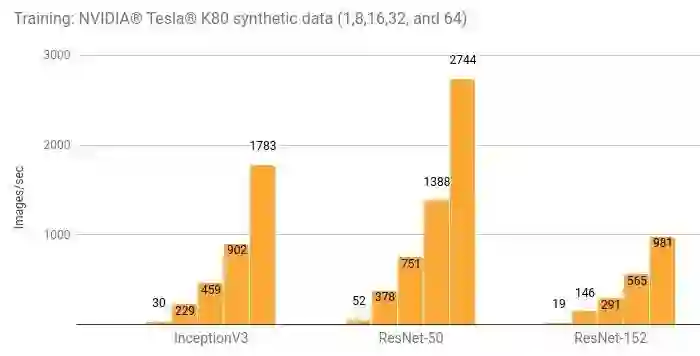
详情和额外的结果请参阅“Amazon EC2 Distributed (NVIDIA® Tesla® K80)”一节。
NVIDIA® Tesla® P100
NVIDIA® Tesla® K80
Instance type: NVIDIA® DGX-1™
GPU: 8x NVIDIA® Tesla® P100
OS: Ubuntu 16.04 LTS with tests run via Docker
CUDA / cuDNN: 8.0 / 5.1
TensorFlow GitHub hash: b1e174e
Benchmark GitHub hash: 9165a70
Build Command:bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
Disk: Local SSD
DataSet: ImageNet
Test Date: May 2017
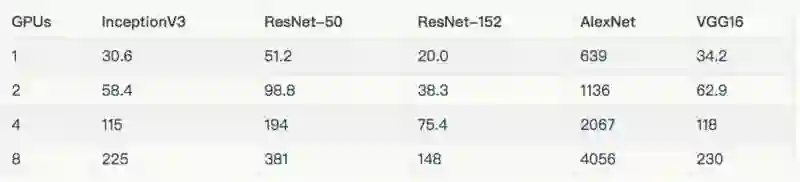
每个模型所使用的批量大小及优化器,如下表所示。除下表所列的批量大小外,InceptionV3、ResNet-50、ResNet-152 和 VGG16 使用批量大小为 32 进行测试。这些结果在“其他结果”一节中。

用于每个模型的配置如下表:
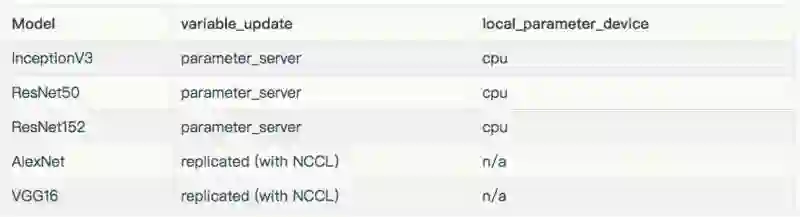
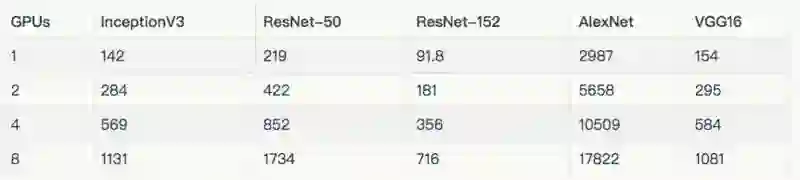
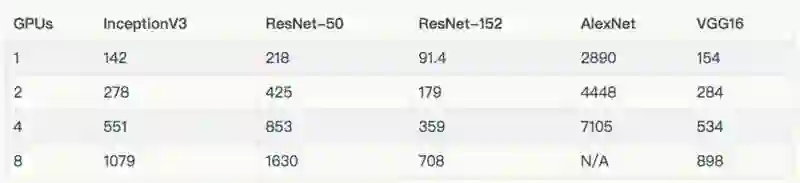
在上述图标和表格中,排除了在 8 个 GPU 上使用真实数据训练的 AlexNet,因为它将输入管线最大化了。
下面的结果,都是批量大小为 32。
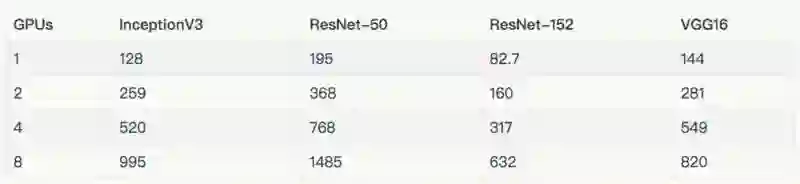

Instance type: n1-standard-32-k80x8
GPU: 8x NVIDIA® Tesla® K80
OS: Ubuntu 16.04 LTS
CUDA / cuDNN: 8.0 / 5.1
TensorFlow GitHub hash: b1e174e
Benchmark GitHub hash: 9165a70
Build Command:bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
Disk: 1.7 TB Shared SSD persistent disk (800 MB/s)
DataSet: ImageNet
Test Date: May 2017
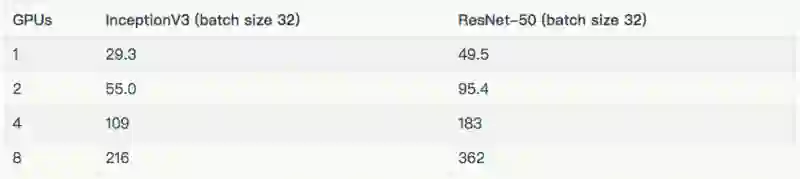
如下表所示,列出了每种模型使用的批量大小及优化器。除去表中所列的批量之外,Inception V3 和 ResNet-50 的批量大小为 32。这些结果在“其他结果”一节。

用于每个模型的配置的variable_update、 parameter_server、local_parameter_device 和 cpu,它们是相等的。
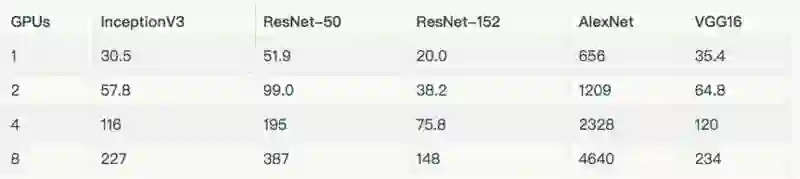
Instance type: p2.8xlarge
GPU: 8x NVIDIA® Tesla® K80
OS: Ubuntu 16.04 LTS
CUDA / cuDNN: 8.0 / 5.1
TensorFlow GitHub hash: b1e174e
Benchmark GitHub hash: 9165a70
Build Command:bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
Disk: 1TB Amazon EFS (burst 100 MiB/sec for 12 hours, continuous 50 MiB/sec)
DataSet: ImageNet
Test Date: May 2017
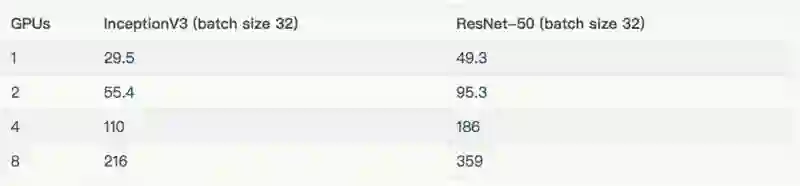
下标列出了每种模型所使用的批量大小和优化器。除去表中所列的批量大小外,InceptionV3 和 ResNet-50 的批量大小为 32。这些结果都在“其他结果”一节中。

用于每个模型的配置。
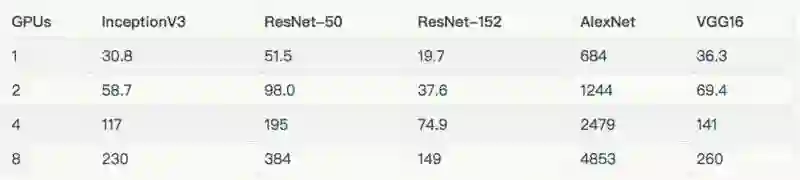
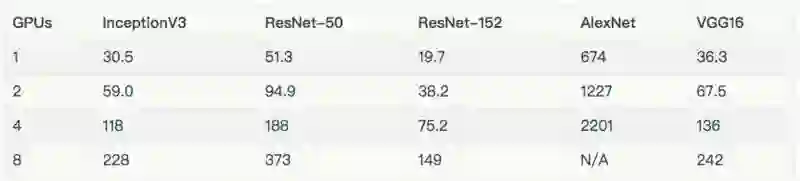
由于我们的 EFS 设置未能提供足够的吞吐量,因此在上述图标和表格中,排除了在 8 个 GPU 上使用真实数据来训练 AlexNet。
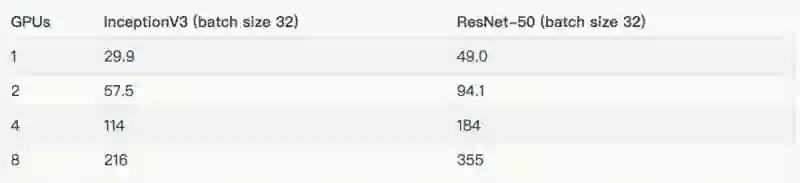
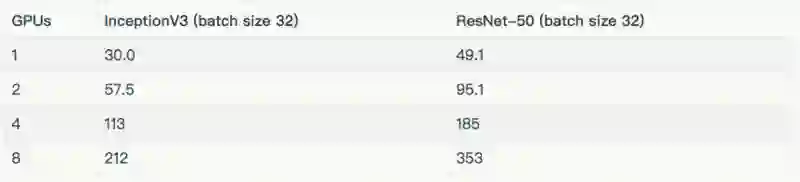
Instance type: p2.8xlarge
GPU: 8x NVIDIA® Tesla® K80
OS: Ubuntu 16.04 LTS
CUDA / cuDNN: 8.0 / 5.1
TensorFlow GitHub hash: b1e174e
Benchmark GitHub hash: 9165a70
Build Command:bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
Disk: 1.0 TB EFS (burst 100 MB/sec for 12 hours, continuous 50 MB/sec)
DataSet: ImageNet
Test Date: May 2017
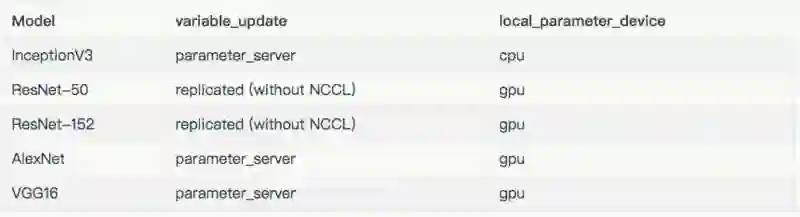
下表列出了用于测试的批量大小和优化器。除去表中所列的批量大小之外,InceptionV3 和 ResNet-50 的批量大小为 32。这些结果包含在“其他结果”一节。

用于每个模型的配置。

为简化服务器设置,运行工作服务器的 EC2 实例(p2.8xlarge)也运行着参数服务器。使用相同数量的参数服务器和工作服务器,不同之处在于:
InceptionV3: 8 instances / 6 parameter servers
ResNet-50: (batch size 32) 8 instances / 4 parameter servers
ResNet-152: 8 instances / 4 parameter servers
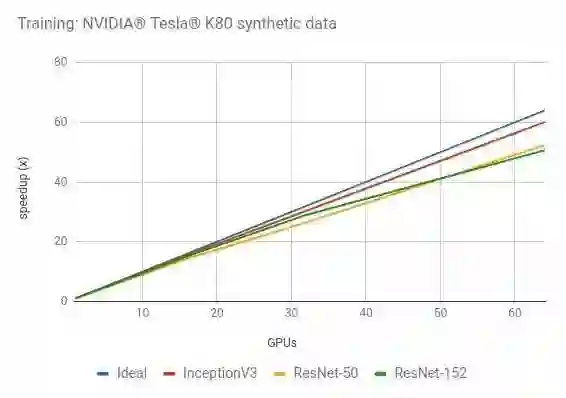
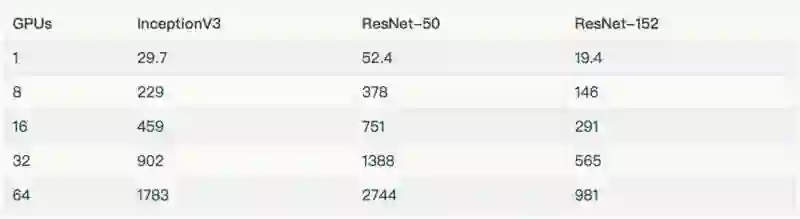
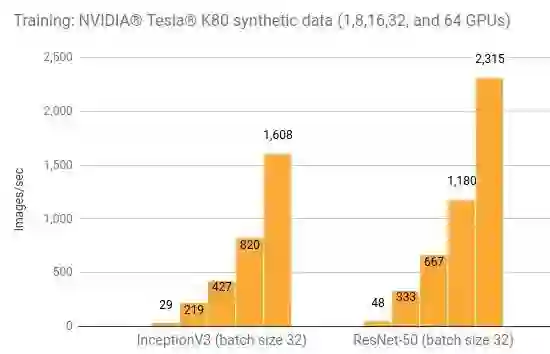
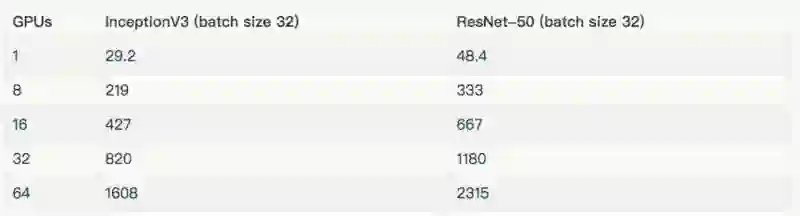
这个脚本 [8] 运行在不同的平台上,产生上述结果。高性能模型 [9] 详细介绍了脚本中的技巧及如何执行脚本的示例。
为了尽可能达到重复的结果,每个测试运行五次,然后平均一下时间。GPU 在给定平台上,以缺省状态运行。对于 NVIDIA®Tesla®K80,这意味着要离开 GPU Boost[10]。每次测试,都要完成 10 个预热步骤,然后对接下来的 100 个步骤进行平均。
参考链接:
[1] Benchmarks:
https://www.tensorflow.org/performance/benchmarks
[2] Rethinking the Inception Architecture for Computer Vision:
https://arxiv.org/abs/1512.00567
[3] Deep Residual Learning for Image Recognition:
https://arxiv.org/abs/1512.03385
[4] Deep Residual Learning for Image Recognition:
https://arxiv.org/abs/1512.03385
[5] Very Deep Convolutional Networks for Large-Scale Image Recognition:
https://arxiv.org/abs/1409.1556
[6] ImageNet Classification with Deep Convolutional Neural Networks:
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
[7] ImageNet:
http://www.image-net.org/
[8] tf_cnn_benchmarks: High performance benchmarks:
https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks
[9] High-Performance Models:
https://www.tensorflow.org/performance/benchmarks
[10] Increase Performance with GPU Boost and K80 Autoboost:
https://devblogs.nvidia.com/parallelforall/increase-performance-gpu-boost-k80-autoboost/





