要理解深度学习,必须突破常规视角去理解优化
选自offconvex.org
作者:Sanjeev Arora
机器之心编译
参与:韩放、shooting
普林斯顿计算机科学教授 Sanjeev Arora 认为,常规的优化观点只关注目标的价值和收敛的速度,而这对于日益重要的深度学习来说是远远不够的。深度学习算法有一些重要的特性并不总是反映在目标值中。所以,要加深对深度学习的理解,还得超越常规视角。
深度学习时代,机器学习通常归结为首先为手头的学习任务定义合适的目标/成本函数,然后使用梯度下降的某种变体(通过反向传播实现)来优化这个函数。
难怪每年有数以百计的机器学习论文贡献给优化的不同领域。但我认为,如果你的目标是对深度学习进行数学理解的话,那么从常规视角去理解优化明显是不够的。
优化的常规视角:尽快找到目标最小可能值的解决方案。
先验上来说,并不确定是否所有的学习都要优化一个目标。大脑中的学习是否也如此是神经科学中一个长期存在的开放性问题。大脑的组成部分似乎已经通过各种进化事件被重新利用/拼凑在一起,整个组合可能或不可以归结为目标的优化。详情见 Marblestone 等人的研究《Towards an integration of deep learning and neuroscience》。
我认为,深度学习算法也有一些重要的特性并不总是反映在目标值中。目前的深度网络是非常过度参数化的,因此有多个最优值。它们被训练到目标几乎为零(即接近最优),如果由此发现的最优(或接近最优)模型在未见过/保留的数据上也表现良好(即泛化效果好),则认为该训练是成功的。这里的问题是,目标的值可能和泛化并不相关(见《Understanding deep learning requires rethinking generalization》)。
当然,专家们现在会问:「泛化理论不正是因为这个原因而被发明为机器学习的「第二条腿」,而优化是「第一条腿」吗?」比如说,这个理论展示了如何给训练目标添加正则化器,以确保解决方案的泛化性。或者,即使在回归等简单任务中,早停(即在达到最佳值之前停止)或者甚至给梯度添加噪声(例如,通过调整批量大小和学习速率)都比完美优化更可取。
然而在实践中,即使是在具有随机标签的数据上,显式正则化器和噪声技巧都无法阻止深度网络达到较低的训练目标。当前的泛化理论旨在对特定模型的泛化原因进行后验解释。但它不知道如何获得解决方案,因此除了建议一些正则化方法之外,不能提供什么优化方法。(我在之前的博客里解释了描述性方法和规定性方法之间的区别,且泛化理论主要是描述性的。)主要的谜团在于:
即使是普通的梯度下降也能很好地找到具有合理泛化性能的模型。此外,加快梯度下降的方法(例如加速或自适应正则化)有时会导致更差的泛化。
换句话说,梯度下降天生就擅长寻找具有良好泛化性能的解决方案。沿着梯度下降的轨迹,我们会看到「魔法」的痕迹,而这魔法在目标值中是捕捉不到的。这让我们想起了那句古老的谚语:
过程比结果更重要。
我将通过在两个简单但具有启发性的任务中进行梯度下降分析来说明这一观点。
使用无限宽的深度网络进行计算
由于过度参数化似乎不会对深度网络造成太大的伤害,研究人员想知道参数到达无穷大这一极限会发生什么:使用固定的训练集(如 CIFAR10)来训练经典的深度网络架构,如 AlexNet 或 VGG19。
这些网络的宽度(即卷积滤波器中的通道数)和全连接内部层中的节点数允许参数增加到无穷大。注意,不管网络有多大,初始化(使用足够小的高斯权重)和训练对于任何有限的宽度来说都是有意义的。我们假设输出损失为 L2。
可以理解的是,这样的问题似乎是无望和无意义的:世界上所有的计算加起来都不足以训练一个无限的网络,而我们的理论家们已经在忙着寻找有限的网络了。
但有时在数学/物理学中,人们可以通过研究极限情况来洞察其中的问题。在这里,我们在有限的数据集(如 CIFAR10)上训练一个无限的网络,最优值的数目是无穷大的,而我们试图理解梯度下降的作用。
多亏了最近关于过度参数化深度网络可证明学习的论文中的见解(其中一些关键论文:《Learning and Generalization in Overparameterized Neural Networks, Going Beyond Two Layers》、《A Convergence Theory for Deep Learning via Over-Parameterization》、《Gradient Descent Finds Global Minima of Deep Neural Networks》和《Stochastic Gradient Descent Optimizes Over-parameterized Deep ReLU Networks》),研究人员已经认识到出现了一个很好的限制结构:
当宽度→∞时,对于一个核回归问题,轨迹接近梯度下降的轨迹,其中(固定)核是所谓的神经切线内核(NTK)。(对于卷积网络,内核是卷积的 NTK 或 CNTK。)
内核由 Jacot 等人鉴定并命名,同时也隐含在一些上述关于过度参数化网络的论文中,例如《Gradient Descent Provably Optimizes Over-parameterized Neural Networks》。
这个固定内核的定义在随机初始化时使用了无限网络。对于两个输入 x_i 和 x_j,内核内积 K(x_i,x_j) 是输出相对于输入的梯度∇x 的内积,分别在 x = x_i 和 x = x_j 处求值。随着网络大小增加到无穷大,可以发现该内核内积收敛到极限值。
我们与 Simon Du 等人的新论文《On Exact Computation with an Infinitely Wide Neural Net》表明,通过动态规划可以有效地计算 CNTK,这让我们得以为任何期望输入有效计算训练网络的结果,即使直接训练无限网络是不可行的。
另外:请不要将这些新结果与一些早期论文混淆,后者将无限网络视为内核或高斯过程,因为它们仅训练网络顶层,将较低层冻结并且随机初始化。
根据经验,我们发现这个无限网络(相对于 NTK 的内核回归)在 CIFAR10 上产生的性能比任何先前已知的内核都要好,当然,不包括那些通过图像数据训练手动调整或设计的内核。例如,我们可以计算与 10 层卷积网络(CNN)相对应的内核,并在 CIFAR10 上获得 77.4%的成功率。
求解矩阵完备化的深度矩阵分解
由推荐系统的设计推动,矩阵完备化已经经过了十多年的充分研究:给定未知矩阵的 K 个随机条目,我们希望恢复未知的条目。
解决方案通常不是唯一的。但是如果未知矩阵是低秩或近似低秩并且满足一些额外的技术假设(例如不相干),那么各种算法可以近似甚至精确地恢复未知的条目。
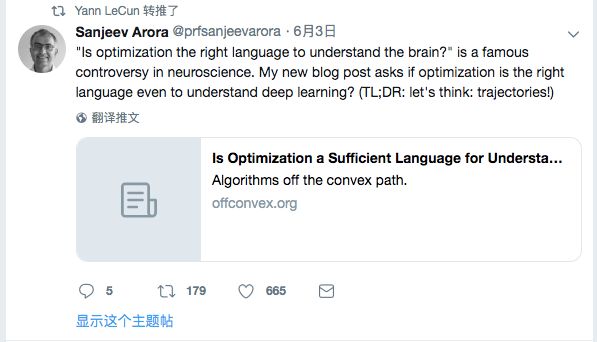
基于核/迹范数最小化的著名算法如下:找到适合所有已知观察并具有最小核范数的矩阵(注意,核范数是秩的凸松弛)。也可以将此作为常规视角所要求的形式的单个目标改写如下,其中 S 是已知条目的索引的子集,λ是乘数:
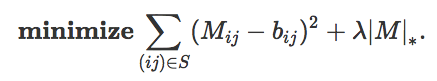
如果你不了解核范数,你会喜欢 Gunasekar 等人(2017)提出的有趣建议:先把核范数惩罚项丢到一边。尝试通过基于损失的第一项来简单地训练(通过简单的梯度下降/反向传播)具有两层的线性网络来恢复缺失的条目。
这个线性网络只是两个 n×n 矩阵的乘积,所以我们得到以下公式,其中 e_i 是所有为 0 的条目的向量:
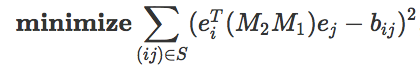
「数据」现在对应于索引 (i,j)∈S,并且训练损失捕获端到端模型 M_2M_1 与已知条目的拟合程度。由于 S 是在所有条目中随机选择的,因此如果在预测剩余条目方面做得很好就意味着「泛化」良好。
根据经验,通过深度学习来完成矩阵完备化工作(即,通过梯度下降来解决 M_1,M_2,并完全忘记确保低秩)和经典算法一样效果,因此有了以下猜想,如果这是真的则意味着在这种情况下,核范数捕获可以精确捕获梯度下降的隐式正则化效应。
猜想:当使用深度为 2 的线性网络解决上述矩阵完备化时,所获得的解恰好是通过核范数最小化方法获得的解。
但正如你可能已经猜到的那样,这太简单了。在与 Nadav Cohen 等人的新论文中,我们报告了新的实验,表明上述猜想是错误的。
更有趣的是,我们发现,如果通过进一步将层数从 2 增加到 3 甚至更高来过度参数化问题(我们将这称之为深度矩阵分解),这种解决矩阵完备化的效果甚至比核范数最小化更好。
请注意,我们正在使用略小于核范数算法精确恢复矩阵所需的值 S。在这种数据贫乏的设置中,归纳偏差最为重要!
我们通过分析梯度下降的轨迹以及它的偏置如何强烈偏向于寻找低秩的解决方案,提供了对深度 N 网络改进性能的部分分析,这种偏置比简单的核范数更强。
此外,我们的分析表明,这种对低秩的偏置不能被核范数或端到端矩阵的任何明显的 Schatten 准范数所捕获。
注意:我们发现,著名的深度学习加速方法 Adam 在这里也加快了优化速度,但略微损失了泛化。这与我上面所说的关于传统观点不足以捕捉泛化的内容有关。
结论
虽然上述设置很简单,但这些表明,要理解深度学习,我们必须超越传统的优化观点,后者只关注目标的价值和收敛的速度。
不同的优化策略如 GD、SGD、Adam、AdaGrad 等,会导致不同的学习算法。它们引发不同的迹,这可能导致具有不同泛化特性的解。
我们需要开发一个新的词汇(和数学)来推理迹。这超出了静止点、梯度范数、Hessian 范数、平滑度等通常的「景观视图」。注意:迹取决于初始化!
如果在大学里学到一些关于 ODE / PDE /动力系统/拉格朗日的技巧,可能会更好地理解迹。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


