数据库存储引擎大揭秘,不看不知道这里面的骚操作可真多!


innoDB存储引擎支持事务,其设计目标是面向在线事务处理的应用,行锁设计、支持外键,默认度操作不会产生锁,从MySLQ 5.5.7版本开始,InnoDB存储引擎作为默认的存储引擎存在于MySLQ中。
MyISAM存储引擎不支持事务,表锁设计,支持全文索引,主要面向离线事务处理的数据库应用,在InnoDB引擎成为默认引擎之前,MyISAM存储引擎一直霸占着默认存储引擎的位置,直到他被InnoDB取代,这是个悲伤的故事。

MySQL架构
MySQL可能是世界上最流行的开源数据库引擎,但使用基于文本的工具和配置文件管理起来可能很困难。SQLyog提供了一个完整的图形界面,即使对于初学者来说,使用MySQL的强大功能也很简单,SQLyog直观的图形用户界面使您可以轻松管理MySQL数据库的各个方面。
-
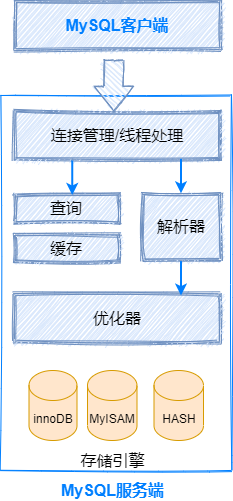
第一层:连接管理层。MySLQ是典型的CS模型软件,所谓CS就是客户端/服务端的意思,作为一个靠网络连接的服务,必不可少的要有连接管理层,用于管理和维护MySQL服务端和客户端之间的连接、鉴权等等。 -
第二层:这一层是MySQL的核心服务功能层,包括了查询缓存、解析器、优化器等所有跨存储引擎的功能都在这一层实现,屏蔽掉存储引擎间的差别,对上层也就是连接管理层提供统一的接口。 -
第三层:存储引擎层就在这一层实现,负责MySQL中数据的存储和提取,这其中有我们今天的主角InnoDB存储引擎和它实现的B+树索引。

如何指定存储引擎类型
show engines;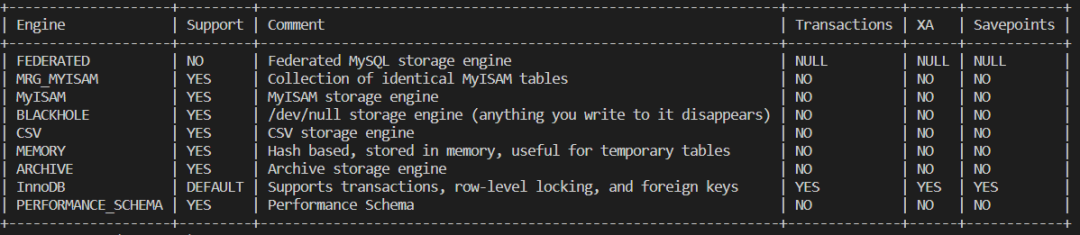
https://dev.mysql.com/doc/refman/8.0/en/storage-engines.html
CREATE TABLE BigOld (id INT,name CHAR (32),PRIMARY KEY (id)) ENGINE=InnoDB;
alert table BigOld engine = InnoDB
索引


存储形式
1、B树索引
定义任意非叶子结点最多只有M个儿子,且M>2; 根结点的儿子数为[2, M]; 除根结点以外的非叶子结点的儿子数为[M/2, M],向上取整; 非叶子结点的关键字个数=儿子数-1; 所有叶子结点位于同一层; k个关键字把节点拆成k+1段,分别指向k+1个儿子,同时满足查找树的大小关系。
-
非叶子节点只存放「索引」和指向子节点的「指针」。 -
叶子节点存放「索引」和「数据」,且叶子节点之间没有关联。
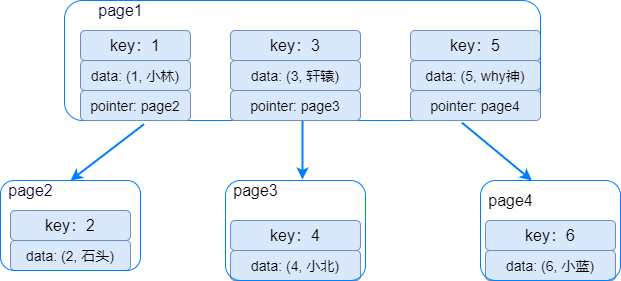
2、B+树索引
有n棵子树的非叶子结点中含有n个关键字(b树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(b树是每个关键字都保存数据)。 所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。 所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。 通常在b+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。 同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素。
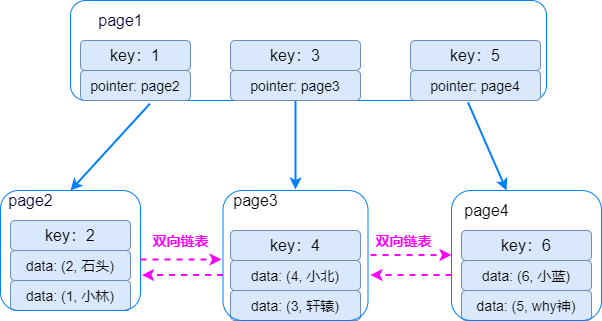
-
「数据」只存放叶子节点上面的,非叶子节点存放「索引」和「指针」。 -
叶子节点按大小顺序通过双向链表连接起来,可以像遍历链表一样遍历整棵B+树。

innoDB的选择
1、性能瓶颈
[lemon/test]$ getconf PAGE_SIZE4096


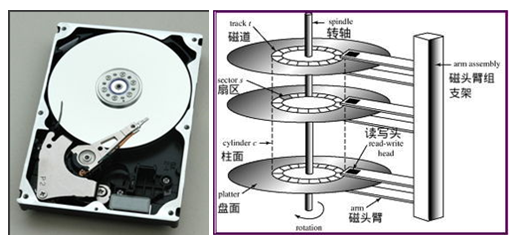
2、内存VS外存
-
沿着B+树索引来查找一个给定关键字(或者范围关键字)的所在的数据行。 -
找到数据行所在的磁盘页,把这个磁盘页加载到内存中。 -
在内存中进行查找(比如二分查找),最终得到目标数据行内容。

Why B+树?
1、B树索引
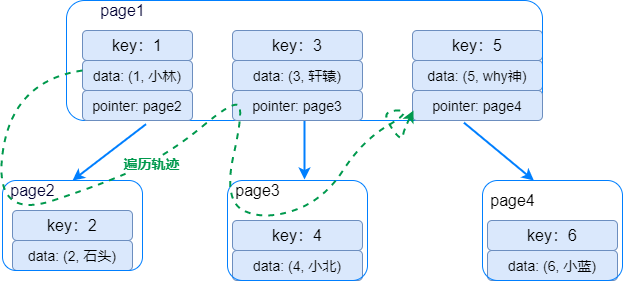
-
从索引树根节点开始,加载磁盘页 page1 找到第一个节点 key=1 数据行(1,小林)不符合。 -
继续通过指针找到磁盘页面page2,加载磁盘页page2到内存,key=2 符合,读取数据行(2, 石头) -
重新加载磁盘页 page1 找到第二个节点 key=3符合,读取数据行(3,轩辕)。 -
继续通过指针加载磁盘页 page4 到内存,key=4 符合,读取数据行(4,小北)。 -
重新加载磁盘页 page1 找到第三个节点 key=5 符合,读取数据行(5,why神)。
2、B+树索引
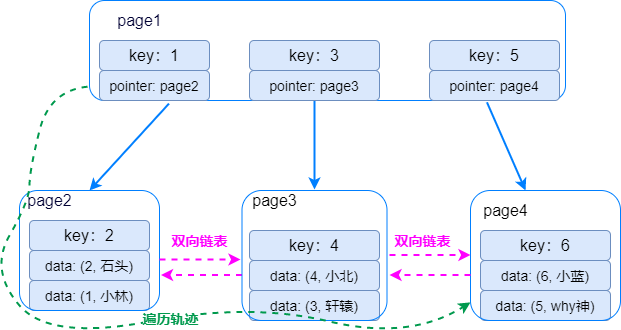
-
从索引树根节点开始,加载磁盘页 page1 找到第一个节点 key=1不符合,继续往下搜索。 -
通过指针找到磁盘页page2, 加载磁盘页page2 到内存,其中存放了key=1、2的数据行,读取符合条件数据行。 -
由于叶子节点间组成双向链表,直接顺着page2 加载磁盘页page3 、 加载磁盘页page4,读取其中符合条件的数据行。

再谈B树
MongoDB is a cross-platform document-oriented database program. Classified as a NoSQL database program, MongoDB uses JSON-like documents with optional schemas. MongoDB is developed by MongoDB Inc. and licensed under the Server Side Public License (SSPL).



更多精彩推荐
☞苹果发布首款 Mac 自研芯片 M1,贯通生态快人一步!☞腾讯竟然是这样招人的,哈哈哈哈哈
![]()
点分享
![]()
点点赞
![]()
点在看



登录查看更多
相关内容

Arxiv
0+阅读 · 2021年1月29日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月29日