git的基本架构欣赏
原来一直黑盒地使用git的基本功能,最近需要频繁地反复整理一个很长的PatchSet,把git的基础数据原理看了一下,把主要内容整理在这里。
以前好像看过Linus有一个论述,说一个模块,只要数据关系定了,这个模块就定了,具体怎么说的忘了,大概是这个意思吧。我觉得从Linux和git的构架控制来看,都反映了Linus的这个核心思想。也正因为如此,两者的架构控制都相当漂亮。
git的核心需求是一个文件树版本管理工具。这个事情的本质,是需要在磁盘上保存一个目录树,以及这个目录树的版本。要表示一个目录树,我们只需要保存:目录(tree),文件(blob)。目录本质上是自己的父目录和内容的索引。所以,在基础数据结构上,只要能保证可以存储文件和索引,而且很快地访问这个索引,这个问题就解决了。
而要表示一个版本,只要能记录一条链表,让每个链表的节点记录一个合入记录就可以了。这同样是一个索引和文件内容的问题。
所以,git的核心数据结构是一个Object管理系统,Object是一个文件,对文件内容取一个数字摘要(现在用的是SHA1算法),就形成它的索引,这样这个结构就只和存储有关,可以被移植到任何支持文件存储的系统上。
比如说,你创建一个目录树是这样的:
./dir
./dir/file
你记录它的内容:
040000 tree e1b8ecbb1f19709f3a4867a0ffe08bb2e07acf19 dir
100644 blob 9daeafb9864cf43055ae93beb0afd6c7d144bfa4 file
用e1b8...作为文件名,放dir的描述,用9dae...作为文件名,放file的内容,这个数据结构可以被复现在任何文件系统上,这样这个架构,就会有一个非常坚实的基础,任何时候,你实现的时候发现有什么搞不定了,你都可以回来想想:“我们基础数据结构的原始设计是什么?为什么当初这个原始设计没有能够Cover这种情况?是后面发展中什么东西限制了那个功能?”这样我们就能让整个架构发展在一个足够宽的道路上。
现在如果你更改了file的内容,新file的SHA1摘要不一样了,就会产生一个新的blob,原来的blob必须保留,新的blob直接放进来就可以了,新的blob进来了,tree就会发生变化(因为里面有这个blob的索引),这就导致一个新的tree object产生。object数据库中就会增加更多的object。但这都能满足原来的诉求。(object可以直接通过git hash-object命令直接创建的,如果你有兴趣可以不用高级的git add/commit这样的命令,直接用git hash-object/update-index/write-tree/commit-tree这样的命令手工建出相关的数据结构来)
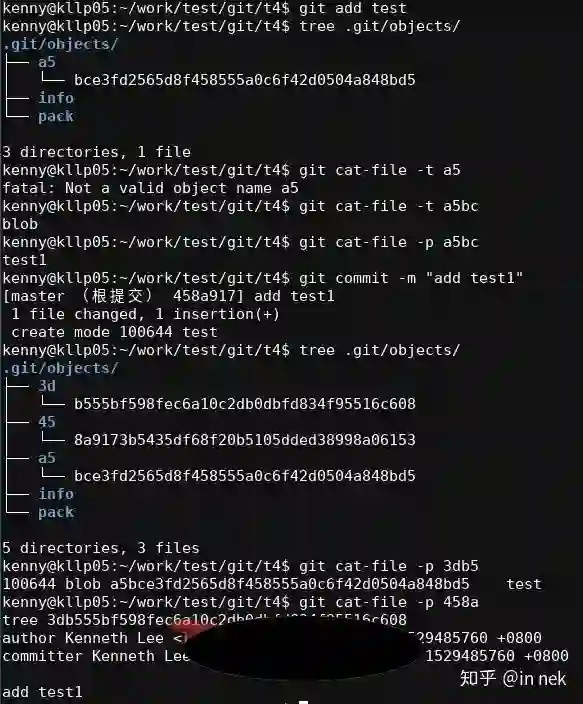
好了,这就是我要说到架构控制的点了,很多工程师会认为,新文件仅仅是对旧文件的修改,应该只保存新文件的变化才对。但从架构控制的观点来看,这个理解是错误的,因为那个是优化,不是核心诉求。核心诉求我们前面说过了,是“保存一条修改过程的链表”,减少存储是优化,它的优先级大不过核心诉求,既然我没有在核心诉求上引入更多的障碍,那么后面我必然是可以进行这种优化的,提前进行这个优化,就错过把最关键的诉求放在前面的的机会。而正如我在前面的博客中说过的那样,架构师的代码占不到整体代码的零头,架构师的代码优先引入低优先级的限制,整个架构控制就失败了。(我前面共享过《一个非常简单的CPU模拟器》<http://zhuanlan.zhihu.com/p/37128423>的思路也是这个,你也许会觉得那个指令的encoding太不真实了,指令空间利用很不充分,但这种优化,不是核心逻辑的一部分,就不应该出现在最初的版本上)
所以,正确的推演方向是如何保存commit的链表。根据我们前面的讨论,把commit作为一个Object节点去描述就可以了,比如(这是内容,如前所述,索引是内容的SHA1):
tree ae55eac3b5e20d2b924e61a6abfc6a7e47e8bb7f
author Kenneth Lee <xxxx> 1529480147 +0800
committer Kenneth Lee <xxxx> 1529480147 +0800
v1
commit索引了这个commit的tree,tree里面有它相关的tree和blob,所有内容都关联起来了。需求永远都在这个基础上,没有被新的限制左右了方向。
在我们描述这个架构的时候,或者在Linus开始实现这个架构的时候,引入了SHA1,但对每个熟悉架构控制的工程师来说,应该很容易要分辨出,SHA1不是这个问题的本质,Hash才是这个问题的本质,你换一个Hash算法,上面的逻辑全部成立,这种情况下,我们就不能认为SHA1是架构定义的一部分,而是一个“代表”,代表一种Hash。我们要分清楚一个架构代码或者架构描述,哪部分只是一个“代表”,哪部分是架构的核心,要关注的是整个逻辑链,如果你修改一个概念的实现,逻辑链是不会变的,那么,我们就不认为那是一个架构限制。
同样,刚才提到的关于增量存储的优化,它是一个处于核心逻辑链之外的一个代表,我们很容易对此进行变化,实际上,git用了两个基本的优化手段来对此进行优化:
第一,把SHA1的前面两个字符作为目录分开保存object文件,这样降低操作系统在一个目录中查找的压力。同前面的道理,用几个字符,是基于目录查找效率来决策的,这个就和前面实现的逻辑完全独立了,也是为什么我们不能在前面这个逻辑中使用这个逻辑,这是一个独立的问题。
第二,实现一个gc功能,这个功能可以把具有相关性的object进行增量保存,这个问题就完全变成了:我具有一组包含大量重复数据的文件,如何对其进行压缩保存?这有无数的方法可以用,而且完全和主逻辑无关。就像下面这样:
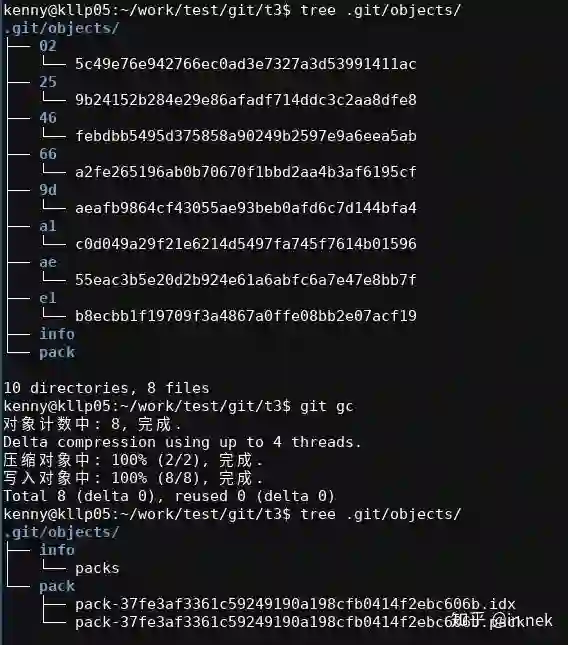
这样的优化,我们就可以完全聚焦在“压缩”这个主题上,和object能否被保存在不同的文件系统上完全无关了。
有一个这样的基础,实现其他功能就很方便了,比如你现在要取一个版本到本地,做git checkout <sha1_of_commit>。给定了commit,就拿到了tree,拿到了tree,就拿到了tree中的其他的tree或者blob,整个工作目录就有了。
然后我们加一个别名的概念,比如branch和tag的名字,本质就是一个commit:
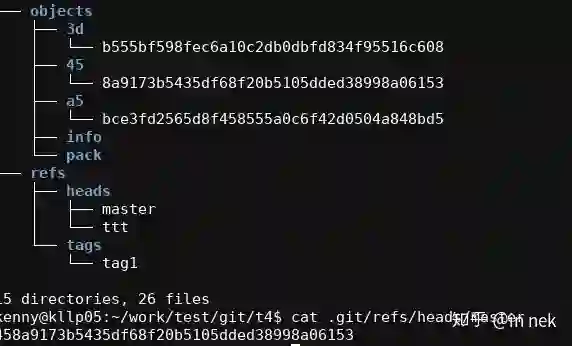
而当前的branch,用HEAD来标识,HEAD是branch的索引:
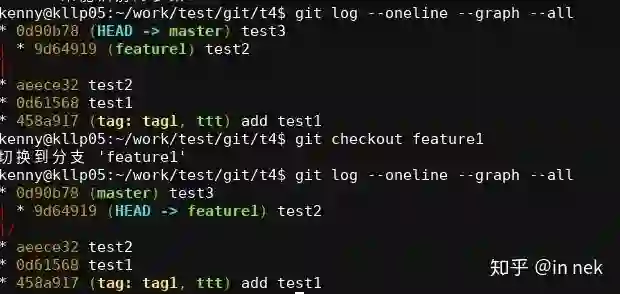
有了这样一个基础结构,后面能想象到的功能,怎么想都只是一个工作量的问题,这就能称为良好的架构控制了。
好的架构控制,是简单而无障碍,所以说架构设计更多从“情理”而不是“当前事实”来看的,架构以简单为美,但这种简单的是以对未来的复杂度的良好容忍为前提的。身边看到的不少糟糕的架构设计,主要问题就是要解决的所有问题域,都在同一个,或者同一层名称空间内。比如实现一个系统库,用户用不用线程都不知道呢,就开始在数据架构上下加锁,美其名曰“线程安全”,这就是典型的把两个互相独立的逻辑空间混合了,以后增加功能的时候,一脚踩进去,会踩死多少个功能都完全无法预期了。
所以,架构设计的代码或者文档,都是以有述无,写的是你看得见的代码,心思都在没有写的代码身上。如果你把心思都放在写的那些代码上,那架构设计就变成详细设计了。架构设计无法学样子,问题就在这个地方。
出处:https://zhuanlan.zhihu.com/p/38245039
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。

架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文