【1小时训练ImageNet】Facebook贾扬清+何恺明论文
新智元编译
来源:venturebeat.com,research.fb.com
VentureBeat 报道作者:Blair Hanley Frank
译者:文强、张易
【新智元导读】Facebook 人工智能实验室与应用机器学习团队合作,提出了一种新的方法,能够大幅加速机器视觉任务的模型训练过程,仅需 1 小时就训练完ImageNet 这样超大规模的数据集。系统使用 Caffe 2 开源框架训练,可以拓展到其他框架上。
Facebook 开发了一种新的方式训练计算机视觉模型,能够大大加速公司人工智能工作。使用新技术,Facebook 可以在一小时内训练图像分类模型,同时保持其准确性。
在最高性能的情况下,Facebook 今天推出的新系统,在不牺牲生成模型质量的前提下,每秒使用 256 颗 GPU 训练 40,000 张图像。这项工作帮助数据科学家更快地测试假说,有助于提高未来研究的质量。
加速机器视觉训练的时间对于 Facebook 来说十分重要,因为机器视觉是增强现实和机器学习的关键,这两项都是 Facebook 未来业务的关键。
论文其中一位作者、FB 应用机器学习团队的软件工程师 Pieter Noordhuis 在接受 TechCrunch 采访时表示,加速模型的生成(creation),意味着公司的数据科学家可以每天运行多个模型排列,而不必花一天时间进行单次测试。
Noordhuis 说,使用新系统,原本需要一周的 6 次试运行一天能够完成。
Facebook 实现这一加速工作的方法是扩展训练中处理的图像小批量的(mini-batch)大小,从而在大量 GPU 运行加速学习的过程。然而,增加小批量的大小也需要增加学习率,这在过去会导致精度的降低。
Facebook 团队提出的方法是增加一个新的预热阶段(a new warm-up phase),随着时间的推移逐渐提高学习率和批量大小,从而帮助保持较小的批次的准确性。
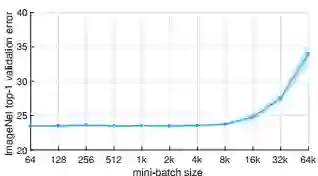
确保模型扩展的有效性:上图显示了 ImageNet top-1 验证错误率 vs 小批量(minibatch)大小,误差范围正/负 2 个标准差。我们提出一种简单通用的技术,能够将分布式同步 SGD minibatch 大小最多扩展到 8k 张图像,同时保持 minibatch 训练前 Top-1 位的错误率不变。对于所有大小的 minibath,我们将学习率设置为 minibatch 的线性函数,并对前几个训练时期(epoch)应用一个简单的预热(warm-up)。所有其他超参数保持固定。使用这种简单的方法,我们的模型精度对于 minibatch 尺寸是不变的。这项技术使我们可以在线性拓展 minibatch 大小的情况下,以高达 90% 的 efficiency 减少训练时间,在 1 小时内在 256 颗 GPU 上训练出了精确的 ResNet-50 模型,minibatch 大小为 8k。来源:论文图1。
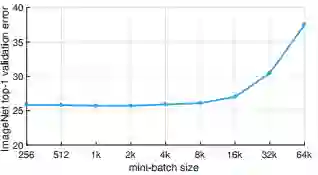
如果刚才那张图让你觉得不够漂亮,那么再看一下这张。上图显示了在训练 epoch 固定为 90 的情况下,ImageNet-5K top 1 验证错误 vs minibatch 大小。从图中可见,训练数据量增加 5 倍对扩展的有效性(efficiency)没有显著影响。来源:论文图6
用这种方法,他们能够为一个小批量为 8192 张的图像,保持小批量大小 256 图像大致相同的错误率。
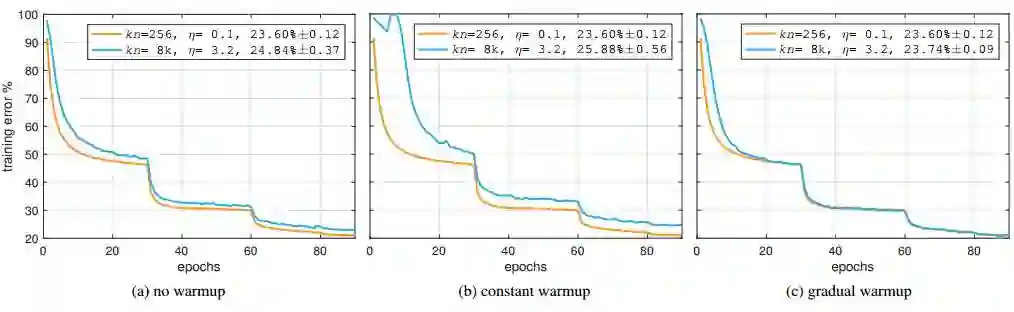
通过不断更新,使 minibatch 为 8192 与 256 的错误率大致相同:上图显示了使用不同预热策略时,miniibatch 大小为 256 张图像(红)与 8192 张图像(蓝)的训练误差曲线(验证误差为 5 次运行的平均值±标准差)。其中,minibatch 大小为 kn,推理学习速率为 η。来源:论文图2
这项研究的好处并不局限于 Facebook 公司内。所有计算都使用开源 Caffe2 框架在服务器上运行,使用其他服务器和其他框架的人也可以根据论文中列出的技术,看到类似的增益。
话虽如此,目前尚不清楚这种技术对于不同的问题会产生什么结果。Noordhuis 还表示,这项研究的另一大主要优点是,证明了 Facebook 的 AI 研究团队(FAIR)的价值。
这一工作是由 Facebook 与人工智能相关的两个组织合作完成的。FAIR 提出了逐渐扩大批量大小和新增加预热阶段的想法,Facebook 的应用机器学习团队(AML)则利用其专业知识,将相关系统应用于数据中心工作。
论文- 精确大规模小批量 SGD:1 小时内训练完 ImageNet 数据集

摘要
深度学习受益于大规模神经网络和大规模数据集的蓬勃发展。然而,较大的网络和更大的数据集会导致更长的训练时间,阻碍研究与开发进展。分布式同步随机梯度下降( SGD)通过在一组并行工作的处理器中划分 SGD 小批量,为这个问题提供了一个潜在的解决方案。然而,为了使这个方案有效,每次预处理的工作量必须很大,这意味着 SGD 小批量大小会产生显著的增长。在本文中,我们通过实验表明,在 ImageNet 数据集上,大型的小批量会引起优化困难,但当这一问题被解决时,训练过的网络会拥有很好的泛化性能。具体来说,我们展示了使用最高达 8192 张图像的大规模 minibatch 进行训练时,不会造成准确性的显著损失。为了实现这一结果,我们采用线性缩放规则调整学习率,作为 minibatch 的函数,并开发了一种新的预热方案,在训练早期克服优化困难。通过这些简单的技术,我们基于 Caffe2 的系统可以在一小时内训练在 256 颗 GPU 上运行的 ResNet-50(minibatch 大小为 8192),并使其精确度与小 binibatch 相匹配。使用市售硬件,从 8 颗 GPU 扩展到 256 颗 GPU 时,我们的实现了大约 90% 的精度保持。这一系统使我们能够高效地对互联网级规模的数据进行视觉识别模型的训练。
方法:
为了克服 minibatch 过于巨大的问题,我们使用了一个简单的、可泛化的线性缩放规则来调整学习率。虽然早期研究中已经开始使用这一指导方针,但其在实践中的局限性并没有被很好地理解,而起,我们发现它并不为研究界所知。为了成功应用这一规则,我们提出了一个新的预热策略,即在训练开始时使用较低学习率的策略[16],以克服早期的优化困难。重要的是,我们的方法不仅符合基线验证误差,而且还产生与了小型 minibatch 基准线匹配的训练误差曲线。
实验:
我们的综合实验表明,与最近的一些研究相比,优化困难是大型 minibatch 的主要问题,而不是不好的泛化(至少在 ImageNet 上是这样)。此外,我们展示了,线性缩放规则和预热泛化到了更复杂的任务,包括对象检测和分割等。我们通过最近开发的 Mask R-CNN 证明了这一点。我们注意到,以前的研究中还没有一个强壮、成功的解决各种 minibatch 的指导方针。
我们的目标是在保持训练和泛化精度的同时,使用大型的 minibatch 代替小型的 minibatch。这对分布式学习尤其有意义,因为它可以让我们通过简单的数据并行来扩展到多个工作者(本文中即为 GPU),也不会减少每个工作者的工作量,而不会牺牲模型的准确性。
正如我们将在综合实验中展示的,我们发现以下学习率缩放规则对于大范围 minibatch 大小上都惊人地有效:

我们的策略适用性和框架无关,但是实现高效的线性缩放需要非平凡的通信算法。我们使用了最近开源的 Caffe2 深度学习框架和 Big Basin GPU 服务器,它们使用标准的 Ethnet 网络(而不是专门的网络接口)高效运行。
编译来源
论文地址:https://research.fb.com/publications/ImageNet1kIn1h/
VB 报道:https://venturebeat.com/2017/06/08/facebooks-new-technique-trains-computer-vision-models-super-fast/





