2018 NAACL语言学习建模竞赛:英语组冠军先声教育展望自适应学习技术

雷锋网 AI 研习社按:第十六届北美计算语言学会议 NAACL 于 6 月初在美国路易斯安那州的新奥尔良召开。NAACL 是自然语言处理与计算语言学领域的顶级学术会议之一。在语言学习建模竞赛中,国内人工智能企业先声教育在英语组赛事中夺得第一。其他参赛者包括来自全球顶尖学术界和产业界的研究团队,如剑桥大学、纽约大学、加利福尼亚大学等。
英语组冠军团队先声教育由其联合创始人及 CTO 秦龙博士带队参赛,参赛队员还包括首席语音科学家陈进和自然语言处理科学家徐书尧。秦龙博士毕业于卡内基梅隆大学,拥有 10 多年的人工智能行业经验。由于这一赛事对自适应学习技术的进步有巨大意义,雷锋网 AI 研习社特邀秦龙博士,与他交流了大赛中的自适应领域最新研究成果。
官网:
https://www.cs.rochester.edu/~tetreaul/naacl-bea13.html
值得一提的是,本次赛事夺冠也为先声教育在雷锋网(公众号:雷锋网)学术频道 AI 科技评论旗下数据库项目「AI 影响因子」获得加分。
雷锋网 AI 研习社:我们都知道 NAACL 是国际自然语言处理与计算语言学领域的顶级学术会议,为什么 NAACL 举行语言学习建模这一竞赛的用意是什么?
先声教育 CTO 秦龙:把自然语言处理技术应用到教育相关领域一直是 NAACL 的重要议题之一,每一届 NAACL 都会举办 BEA 教育技术专题研讨会,今年已经是第 13 届。今年 BEA 有两个公开任务,一个是单词复杂度识别(Complex Word Identification),一个是第二语言习得建模(Second Language Acquisition Modeling)。第二语言习得建模是指根据学生过去的答题 (第二语言学习) 历史,预测该学生能否对未来的题目作出正确应答。这对于构建能够作出智能推荐的自适应学习系统具有重大意义,是自适应学习最核心的模块。

(图为大会组织方进行 SLAM 竞赛的总结报告)
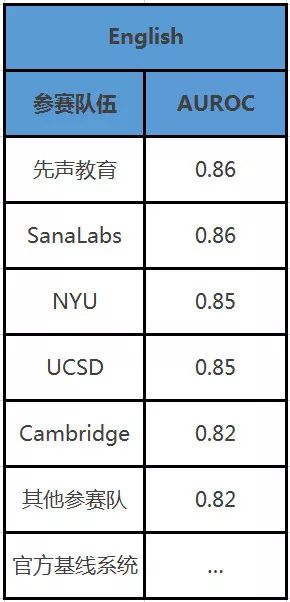
此次 SLAM 竞赛是由语言能力测试的权威机构 ETS 与世界上最大的语言学习应用 Duolingo 联合组织的。Singsound AI 团队参加了该任务的全部三个子任务:英语学习、西班牙语学习以及法语学习。先声教育的 CLUF 模型在英语学习上取得了第一名的好成绩,在西班牙语学习及法语学习上取得了第二名的成绩。
雷锋网 AI 研习社:比赛过程中的最大难点是什么?
先声教育 CTO 秦龙:主要难点有二:一是语言类学习以词汇、短语量庞大,且语法、搭配复杂著称,是自适应学习最难落地的学科,此外本次大赛考察多个语种,包括英语、西班牙语、法语;二是学习行为数据时间跨度长达 3 个月,数据量极其庞大,超过 100 万个句子,覆盖 6000 多名学生,使学习行为的数学模型更加复杂。
随着近年来互联网、人工智能等技术与教育的融合,计算机应用程序增加,教育行业积累了大量学生学习数据,可以利用来驱动实现个性化学习,目前数学学科方面也取得了一些进展。但对于一门语言的学习,知识点更细微、涉及词汇的互动知识、形态句法处理等更为复杂,加上需要分析极其庞大的数据群,对于数学模型的训练难度极大。
雷锋网 AI 研习社:据我们了解,目前国内自适应学习大多是基于知识图谱这样的一个系统,第二语言习得建模这样的任务跟知识图谱有什么区别吗?
先声教育 CTO 秦龙:自适应学习可以分为两个阶段:1)以推荐系统为基础的浅层自适应阶段;2)以学习行为建模为基础的深度自适应阶段。目前国内大多数企业仍处于浅层自适应阶段,从本次大赛英语第一的成果看,先声教育自适应系统已成功率先步入自适应学习的核心深度阶段。
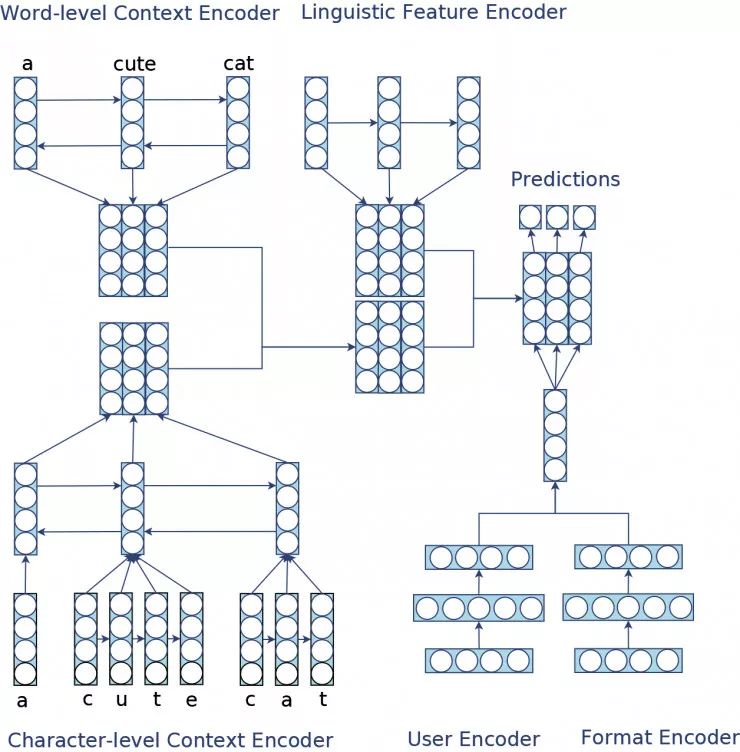
我们先声团队使用的 CLUF 是一种基于深度学习的 Encoder-Decoder 模型,它由四个 encoder 构成,分别是语境编码器 Context Encoder、语言学特征编码器 Linguistic Encoder、用户信息编码器 User Encoder、题型信息编码器 Format Encoder,最后由解码器利用编码器输出的高维特征作出预测。
语境编码器用来编码句子的语言环境,它由一个字母级别的编码器与一个单词级别的编码器构成。字母级别编码器是一个层级式的循环神经网络结构,单词级别编码器则是一个双向长短期记忆神经网络 LSTM;语言学特征编码器也是一个 LSTM 结构,主要用于编码提取的语言学特征,为语境编码器提供额外的信息;用户编码器是一个全连接的结构,用于记录用户的第二语言能力与学习历史;题型编码器则是用来编码题型、答题方式等信息。
雷锋网 AI 研习社:先声的模型和其他参加团队具体有哪些不同,优势在哪里呢?
先声教育 CTO 秦龙:我们的 CLUF 模型最大的优势在于,通过把不同类型的特征分组,用符合相应特点的网络结构进行编码来挖掘数据的内在模式,CLUF 取得了非常出色的效果,在该任务上 Singsound AI 团队击败了来自于剑桥大学、纽约大学、首都东京大学、加州大学等团队。
在其他参赛队伍中,纽约大学也取得了不错的成绩。他们的系统会提取用户、词汇、上下文等基于认知科学、语言学的特征,然后使用梯度提升决策树 GBDT 模型进行建模。在西班牙和法语学习中取得最好分数的是来自于瑞典的 SanaLabs,他们采用了 ensemble 的方法,也就是使用多个不同的模型进行预测,然后对多个模型的预测结果进行加权组合的方法。实际上,对于类似的竞赛任务,大会组织方是不提倡采用 ensemble 的方法的,因为这样无法判断具体的模型究竟对该任务是否有效。为此,在组织方的总结报告中,大会组织者进行了的 ensemble 模型融合分析。很显然,融合所有团队的系统能够取得更好的效果。同时,在该融合系统中,先声教育的 CLUF 的贡献最大,其次是纽约大学的系统,SanaLabs 的系统权重最低。

(图为自然语言处理/计算语言学领军人物、斯坦福大学计算机系 Christopher D. Manning 教授与先声教育参赛团队讨论 CLUF 技术细节)
雷锋网 AI 研习社:对于本次大赛所有参赛团队的整体成绩,您对于自适应学习技术的未来抱有怎样的看法呢?
先声教育 CTO 秦龙:从大赛的整体结果看,现阶段自适应学习技术的成果比较乐观。在同自然语言处理/计算语言学领军人物、斯坦福大学计算机系 Christopher D. Manning 教授的交流过程中,Manning 教授点评道:「在自然语言处理与计算语言学领域,近年来不断地有新的方法新的问题被提出,引起了学术界工业界的广泛关注,在相关领域的研究人员队伍也在不断壮大。通过今年的 NAACL SLAM 竞赛,可以看到自适应学习技术落地的显著效果,也期待未来自适应学习技术跨界教育,应用于更广泛的领域。」
先声教育创始人及 CEO 陆勇毅对于企业的发展和愿景曾这样表示:「先声作为一家人工智能企业,目前已经服务业内近百家企业,我们一直保持着开放的心态,非常愿意将每个阶段的研究成果开放给国内外更多企业,助力 AI 升级教育行业。并且未来希望借助技术的优势,跨界赋能更多行业,推动智能化时代到来。」AI 研习社也将持续关注先声教育在自适应学习技术的发展。

CCF-GAIR 大会即将开幕!
▼▼▼




