百度 Apollo2.0 数据开放平台 :“云 + 端”研发迭代新模式


各位开发者朋友,大家好,我是来自百度自动驾驶事业部的杨凡。很高兴有机会与大家分享百度和 Apollo 在自动驾驶汽车方面的一些进展。

我的分享分这几部分:
首先是介绍 Apollo 和车端开放能力
接着是介绍资源开放与研发迭代新模式
之后是介绍数据开放平台与训练平台实战
最后是介绍基于能力开放和资源开放的阶段性成果

我们先来看第一部分,Apollo 能力开放简单介绍。
先向大家介绍一下百度做自动驾驶的背景。就像百度总裁 COO 陆奇在 CES 大会上再次提到的,百度已经是一家 AI 公司。并跟大家分享百度是怎样以中国速度在加速 AI 创新的以及通过开放平台我们可以怎样来共同改变世界,并让世界变得更好。
我们可以看到科技大潮的演进,已经从命令行、客户端服务器、互联网、移动互联网一路走来,进入到了 AI 时代。
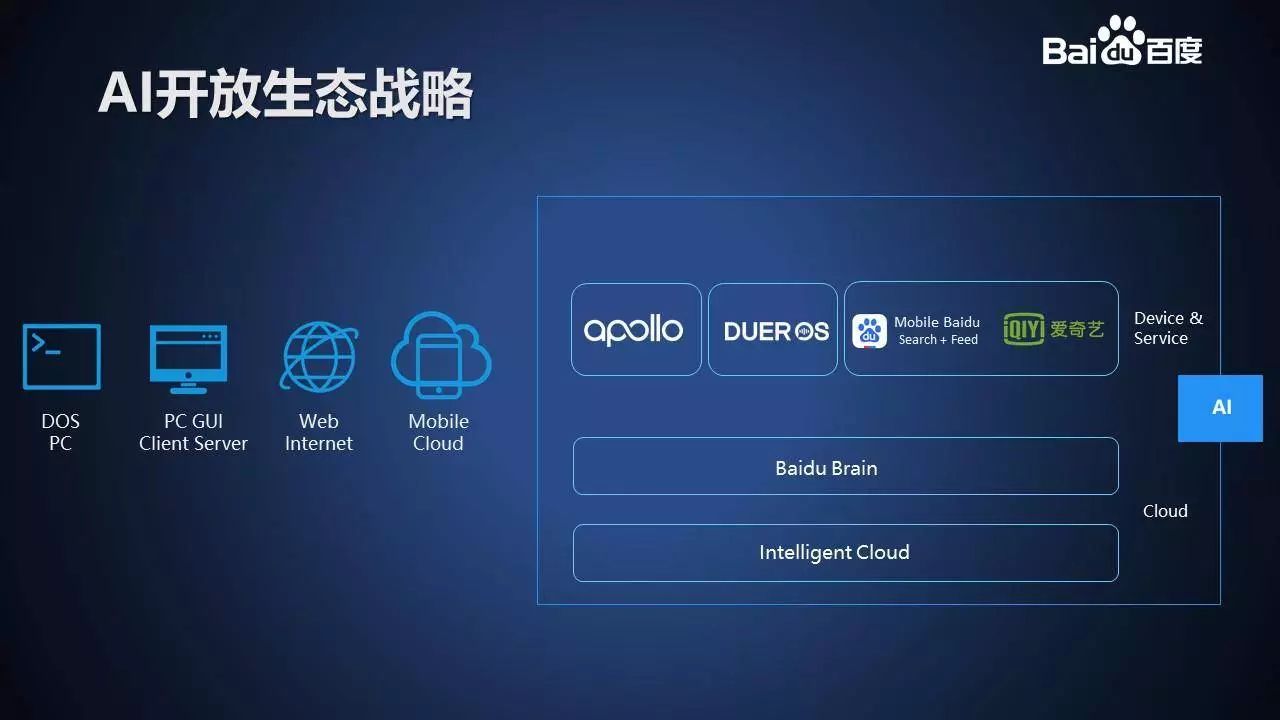
在百度 AI 开放生态战略中,体系分成云和端,支撑的云技术是智能云和百度大脑,而端的输出就是自动驾驶 Apollo 生态和唤醒外物的 DuerOS 生态。
同时更重要的,更振奋人心的是 AI 把移动互联网带入一个全新的时代,我们把它叫做新移动。
在这个新移动时代手机有很强的感知能力,有更多的 AI 基产能力,每个手机都能听、能看、能说、能学习、能懂用户。百度的核心产品,手机百度,爱奇艺等等,将充分利用这新的能力,全面推进新的技术和产品来引领新一代的移动时代的用户体验。特别是手机百度,手机百度将把搜索和个性化有机融合在一块,打造新一代的更懂用户的体验。Apollo 生态是百度 AI 重要的、最先落地的生态之一。

自 4 月 19 号宣布开放后,收到很多伙伴的反馈,其核心总结为 Apollo 宣言。自动驾驶行业正在快速走向未来,而最大的痛点在于技术壁垒太高,每个企业需要技术与人力的多年积累,才可以进入实质的研发。百度起步较早,有将近 4 年的技术积累,投入较早,将把能力开放给每一个合作伙伴,从 0 到 1,很快进入到无人驾驶的研发,从而提高无人驾驶行业的创新速度,避免重复造轮子。大家都把精力放在更有效的创新上。共享资源,合作伙伴使用 Apollo 技术资源,拿来即用;同时,每个合作伙伴,都可以贡献资源,贡献得越多,得到的越多。Apollo 受益,合作伙伴更受益。加速创新:数据加创新,汇集数据资源,公里数,覆盖的场景数,以后将远远大于任何一个封闭的体系持续共赢:百度的商业模式,基于百度的核心能力。能力与合作伙伴互补,Apollo 将是汽车工业的里程碑,Apollo 将产生核心的影响力。

Apollo 从 2017 年 4 月份宣布开放计划,到 7 月份发布 1.0,9 月份发布 1.5,2018 年 1 月的 CES 发布 2.0,迭代与发布速度非常快。
Apollo Roadmap 可以看到,Apollo 开放由两部分构成,开放能力和开放资源。
在 2017 年 7 月 1.0 中开放封闭场地循迹自动驾驶能力和资源,在 9 月 1.5 中开放固定车道自动驾驶能力和资源,在 2018 年 1 月 2.0 中开放简单城市路况自动驾驶能力和资源,之后会在 2018、2019、2020 年逐步开放特定区域高速和城市道路自动驾驶能力和资源,高速和城市道路和自动驾驶 Alpha 版,并最终到达高速和城市道路与全路网自动驾驶能力和资源。
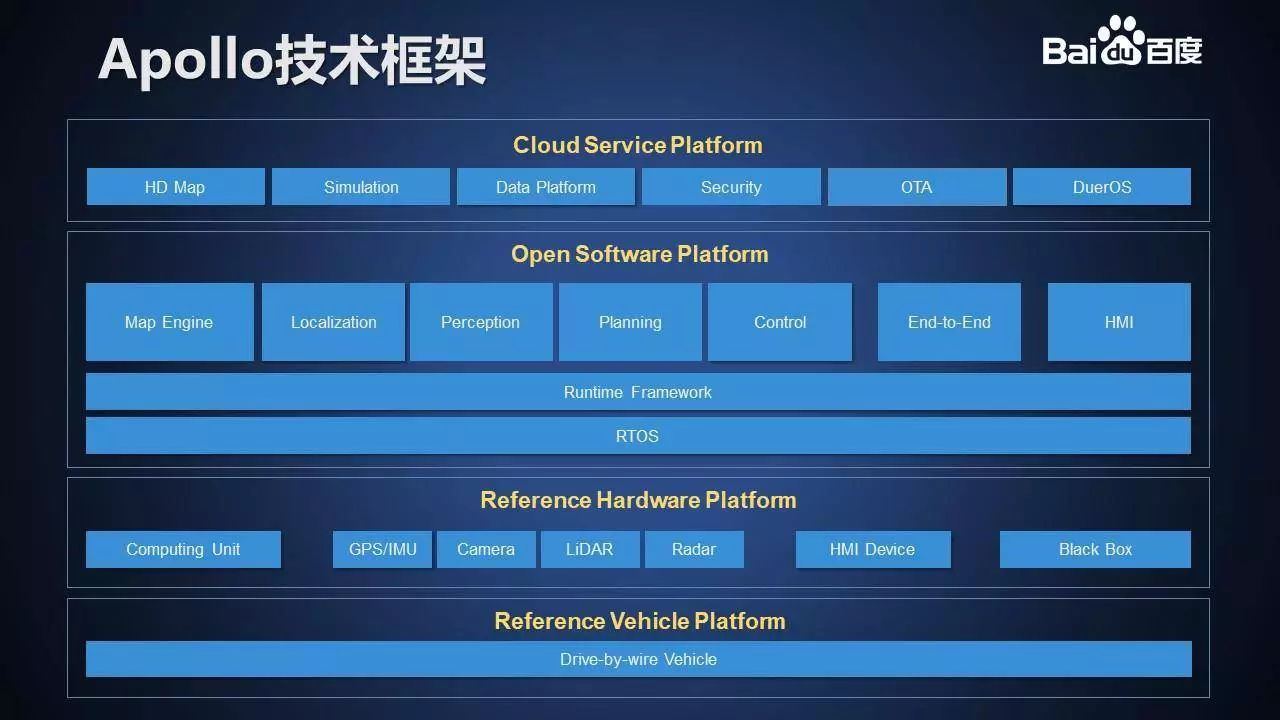
开放的框架是学术界、科技界、产业界的共同需求。Apollo 技术框架由 4 层构成。分别是
Reference Vehicle Platform
Reference Hardware Platform
Open Software Platform
Cloud Service Platform
各层各模块的基本介绍:
具体来说首先我们需要一辆能够受我们信号控制的车,那么就我们管它叫信号车。然后主要是我们和很多车厂和 Tier1 的这个方案厂商一同来推进的一层;
然后是 Reference Hardware,我们要想让车能动起来,需要计算单元、GPS/IMU、Camera、激光雷达、毫米波雷达、人际交互设备、BlackBox 等等硬件的支持。
开放软件层。它分成三个子层,有实时的操作系统。有承载所有模块的框架层。高精地图与定位告诉车辆身在何处,感知模块告知车辆周围环境,决策规划模块决定全局与细节规划。控制模块负责将决策规划产出的轨迹生成为具体的控制命令;
百度自动驾驶有非常强的能力来源于云端的。高精地图存储于云端,用以模拟驾驶的仿真服务也在云端,它加速了自动驾驶的研发效率。我们积累了大量的数据和对数据的理解。我们在云端也开放了数据平台,把数据加工的主线,在我们云端来体现出来。在云端还有我们的安全服务,保证软件的自动更新。
Apollo 2.0 新开放的模块包括了 Security、Camera、Radar 和 Black Box,这意味着 Apollo 平台包括云端服务、服务平台、参考硬件平台以及参考车辆平台在内的四大模块已全部点亮。Apollo 2.0 首次开放安全和 OTA 升级服务,只允许正确和被保护的数据进入车内,并进一步强化了自定位、感知、规划决策和云端方阵等能力。其中 Black Box 模块包括了软件和硬件系统,能够实现安全存储和大容量数据集传输,可以帮助我们及时发现异常情况,提升整个平台的安全可靠性。
硬件方面,增加两个前向摄像头(长焦 + 短焦)主要用于识别红绿灯,正前方保险杠上方新安装了毫米波雷达。所以很明显,在 Apollo 2.0 开放了 Camera 和 Radar 的模块后,整个平台更强调了传感器融合的能力,已进一步增加其对昼夜简单城市道路工况的适应能力。
就像百度智能驾驶事业群组总经理李震宇提到的,低成本低功耗一定是自动驾驶平台所追求的目标,但其实在从实验室走入量产产品这个过程中,安全最重要,百度首要解决的一定是安全问题。

智能汽车的“云 + 端”研发迭代新模式
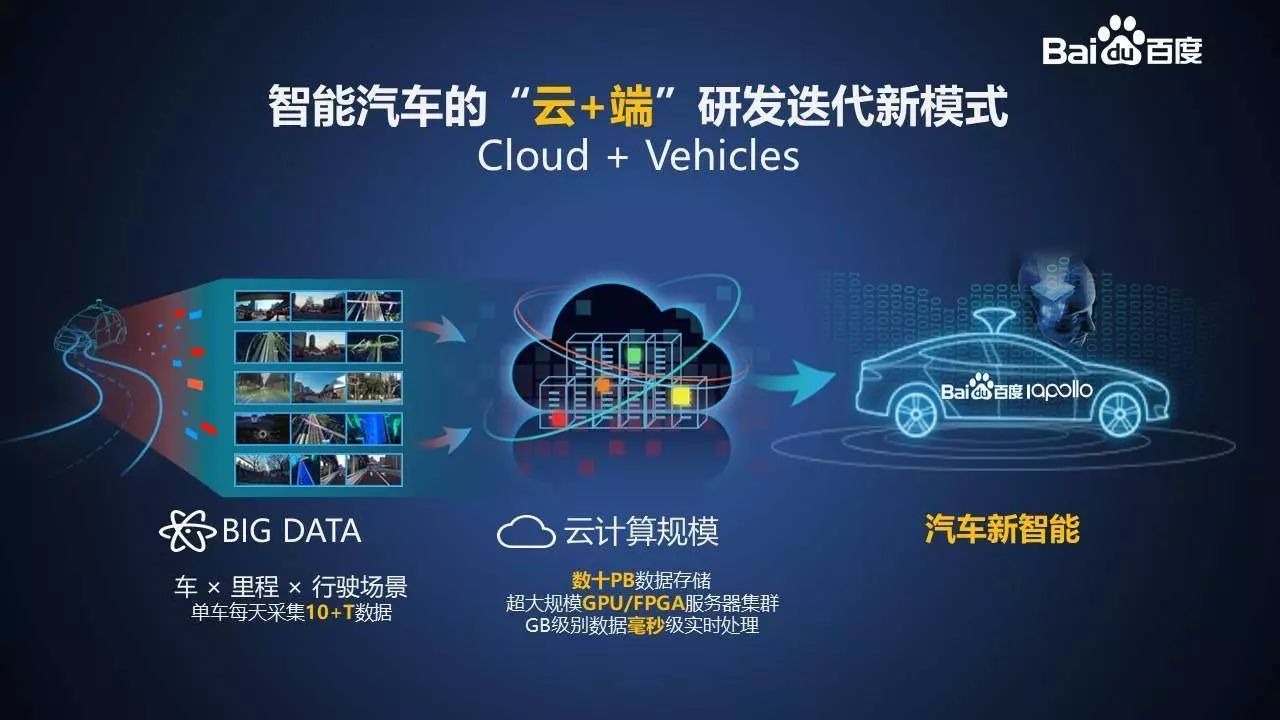
智能自动驾驶汽车需要一颗聪明的车载大脑。我们在自己的研发中一路探索过来,智能汽车的“云 + 端”研发迭代新模式是我们对于加速自动驾驶汽车研发效率提出的解决办法。我们在车辆上积累海量的数据。
把这些积累的数据用云端的服务器集群高效地生成人工智能的模型,也就是车辆大脑。把汽车大脑更新到车辆上,为车辆赋予自动驾驶的能力。
我们在自己研发过程中发现,研发 L4 自动驾驶量产车需要用非常复杂的算法策略解决非常复杂的场景。
根据兰德公司报告,量产需积累 100 亿公里自动驾驶里程经验,100 辆车 7*24 小时跑上百年;如果是传统的直接在车端研发、车端调试的效率是不够的。
所以我们提出的解决办法是通过“云 + 端”的研发迭代新模式提高研发效率。我们非常高兴向 Apollo 生态分享这种模式。
下面就开始介绍自动驾驶大数据部分。
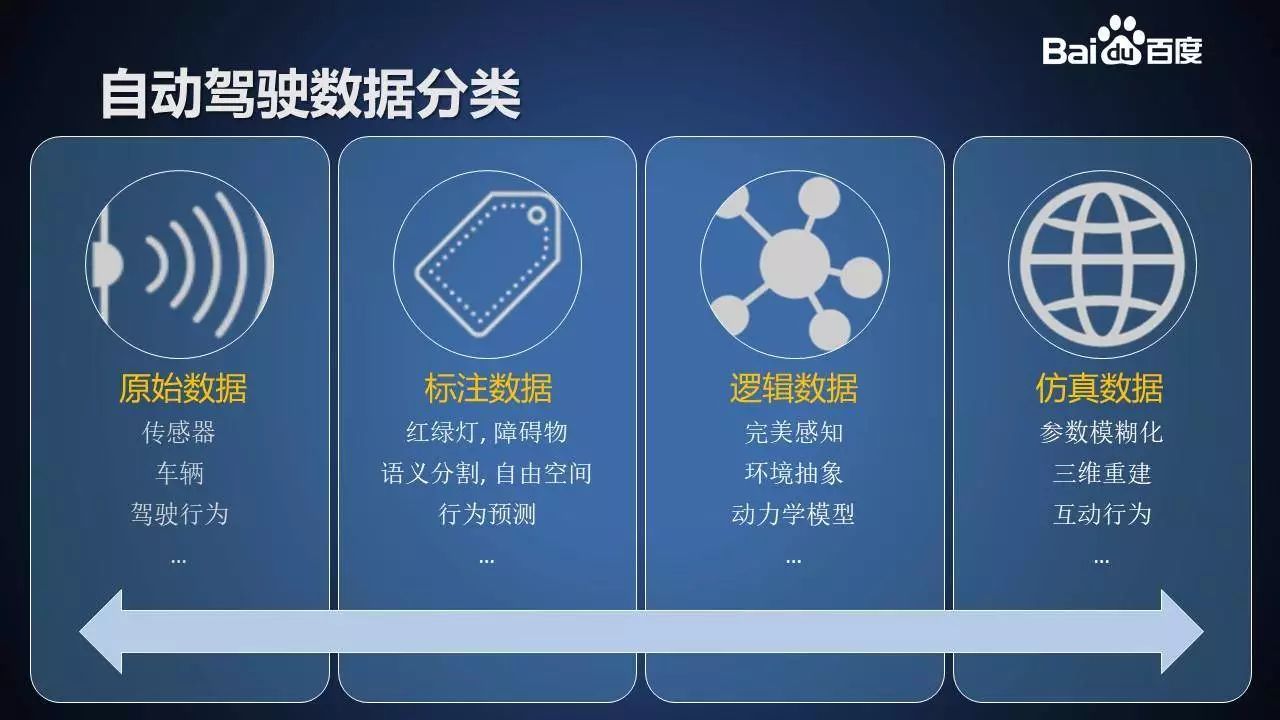
自动驾驶数据可以分为四大类:
自动驾驶车辆产生的数据首先是 原始数据。主要是传感器数据、车辆自身数据、驾驶行为数据等。这些数据的特点是数据量极大、类型多样、以非结构化半结构化数据为主。无论对存储、传输、处理都构成比较大的挑战。
为了在深度学习中使用数据,我们还需要大量 标注数据。主要有红绿灯数据集,障碍物数据集(2D、3D),语义分割数据集,自由空间数据集,行为预测数据集等等。
为了刻画自动驾驶行为,我们还需要将数据抽象成 逻辑数据。主要是完美感知数据,环境抽象数据,车辆动力学模型等。
最后,我们会用为仿真构建 仿真数据,主要是参数模糊化数据,三维重建数据,互动行为数据等。
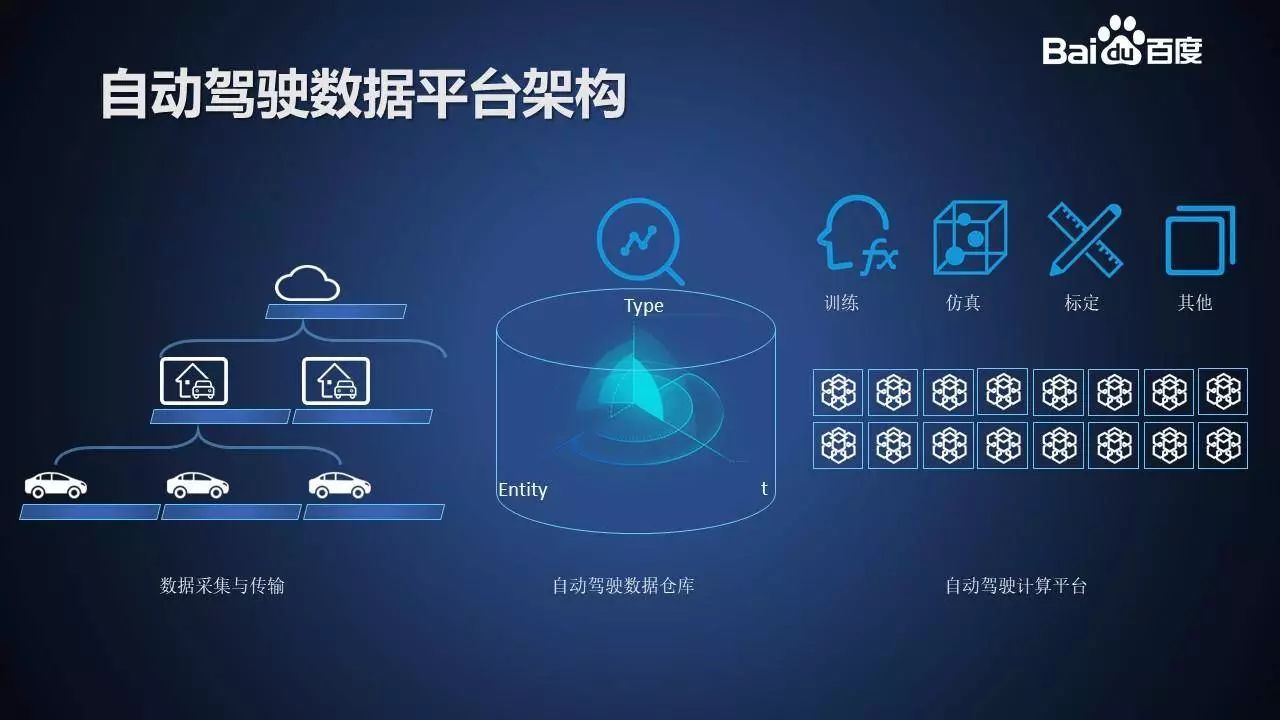
数据平台是我们支撑智能汽车的“云 + 端”研发迭代新模式的核心平台。
由数据采集与传输,自动驾驶数据仓库,自动驾驶计算平台三个部分构成。
首先是数据采集与传输部分。使用 Data-Recorder 会按 Apollo 数据规范产生,完整的、精确记录的数据包,可以完成问题复现,也同时完成数据积累。通过传输接口,可以将数据高效地传输到运营点和云集群中。
接着是自动驾驶数据仓库部分,会将全部海量数据成体系地组织在一起,快速搜索,灵活使用,为数据流水线和各业务应用提供数据支撑。
自动驾驶计算平台部分,基于云资源异构计算硬件提供超强算力,通过细粒度容器调度提供多种计算模型,来支撑起各业务应用。如训练平台、仿真平台、车辆标定平台等等。


Apollo 开放资源数据集分为以下三大部分:
仿真数据集,包括自动驾驶虚拟场景和实际道路真实场景;
演示数据集,包括车载系统演示数据,标定演示数据,端到端演示数据,自定位模块演示数据;
标注数据集,包括 6 部分数据集:激光点云障碍物检测分类,红绿灯检测,Road Hackers,基于图像的障碍物检测分类,障碍物轨迹预测,场景解析。
除开放数据外,还配套开放云端服务,包括数据标注平台,训练学习平台以及仿真平台和标定平台,为 Apollo 开发者提供一整套数据计算能力的解决方案,加速迭代创新。

我们还通过 Apollo 训练平台为每一个数据集提供类配套的计算能力。
训练平台的特色是:
通过 Docker+GPU 集群,提供提供与车端的一致硬件计算能力。
集成多种框架,提供完整的深度学习解决方案。通过交互式可视化结果分析,方便算法调试优化

我们在自动驾驶的算法开发中,最大的痛点之一就是需要对海量数据集,反复尝试。我们通过将深度学习算法的研发流程 (开发、训练、验证、调试) 在云端实现,可以在充分利用云端大量计算资源的同时,将数据的流动仅在云端的服务器内完成,从而大幅提高算法研发效率。
具体来说,首先开发者在本地开发机中基于 Docker 开发算法,并部署依赖环境。
接着将开发好的环境推到云端的私有 Docker Repository 中。
接下来在平台上挑选数据集,发起训练任务。Apollo 训练平台的云计算调度就会将任务调度到计算集群上执行。这个过程中,在云集群的内部,开发者的程序使用数据获取接口,获得自动驾驶数据仓库中的数据集。
最终由业务管理框架将执行过程、评估的结果和 Model 返回给可视化平台,完成可视化的调试。
接下来,我将介绍数据平台的实际操作。打开 Apollo 的官网 apollo.auto,可以看到首页。
Apollo 官网首页
点击 Github 可以查看 Apollo 车端开放能力的源代码。
在顶部菜单栏的“开发者”菜单中,选择“数据平台”即可进入 Apollo 数据开放平台。推荐使用 PC 打开使用,效果更佳。
登录
在 Apollo 数据开放平台的页面右上角,有登录菜单,点击后登陆百度帐号,会简化之后的使用流程。
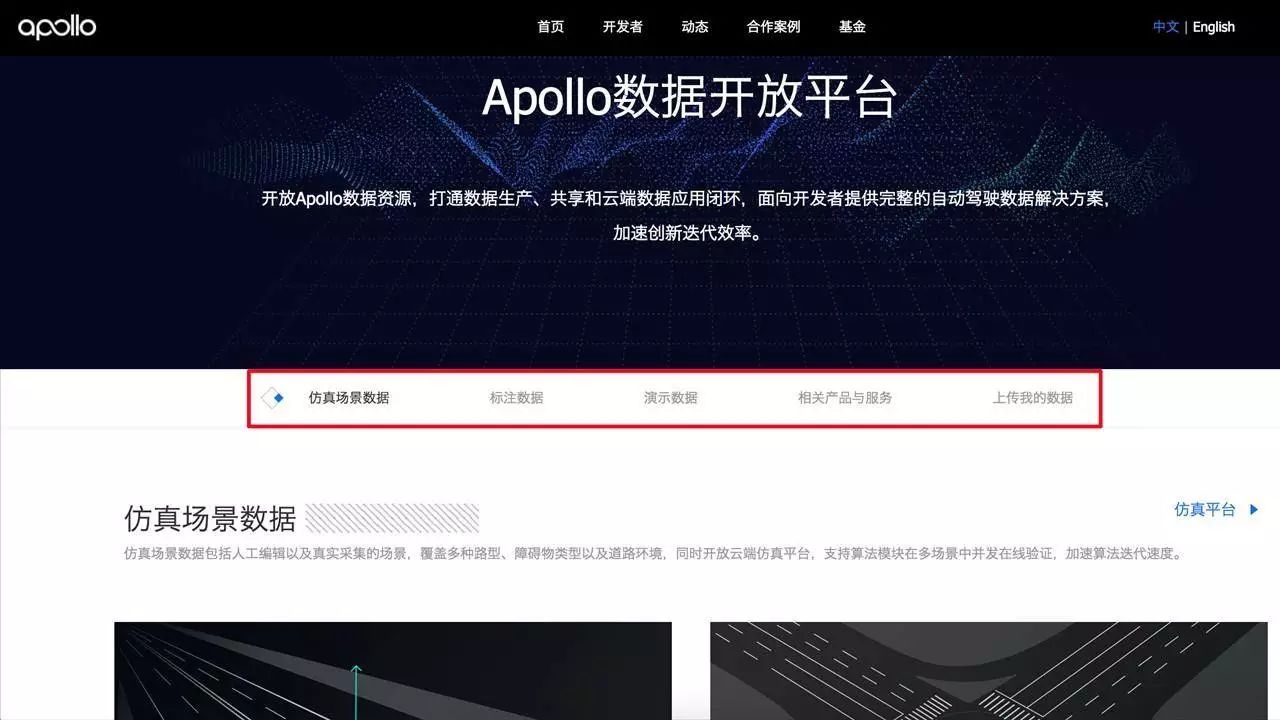
数据开放平台
数据开放平台的首页由几个小节构成,分别是仿真场景数据、标注数据、演示数据、相关产品与服务、上传我的数据。
开发者可以直接使用 Apollo 已经开放的数据,也可以通过 Apollo 的 Data-Recorder 记录数据上传到云上使用。
通过选择特定数据,可以进入特定数据的应用。
开发者可以在标定平台中标定车辆参数,通过上传数据,申请数据加工,使用数据标注服务,在训练平台中训练 Model,将前几步应用平台的结果合并到 Github 的 Apollo 代码中,将编译结果或源码提交到仿真平台中完成评估,这样就通过“云 + 端”完成了自有车载系统的研发迭代。

首先,可以看到仿真场景数据集。
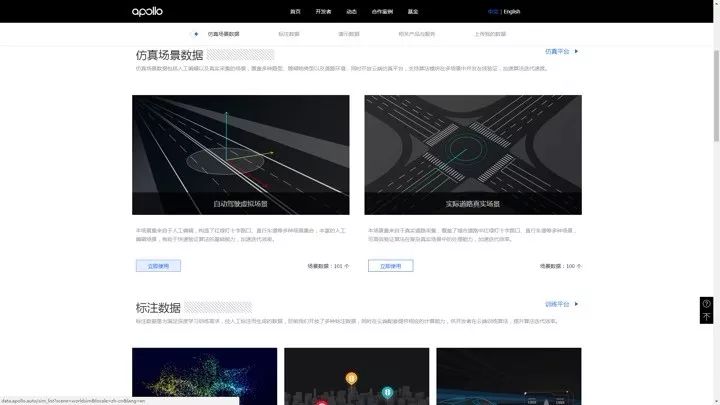
仿真场景数据集
仿真场景数据包括人工编辑以及真实采集的场景,覆盖多种路型、障碍物类型以及道路环境,同时开放云端仿真平台,支持算法模块在多场景中并发在线验证,加速算法迭代速度。
点击两个仿真数据集下的“立即使用”按钮,可以进入到仿真场景数据集详情页。
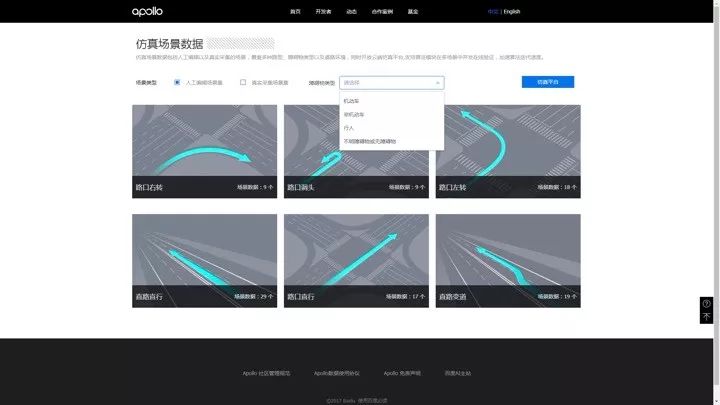
仿真场景数据
仿真场景数据的详情页中,可以进一步通过条件筛选,查看场景的细节。点击右上角的仿真平台按钮,可以进入仿真平台。
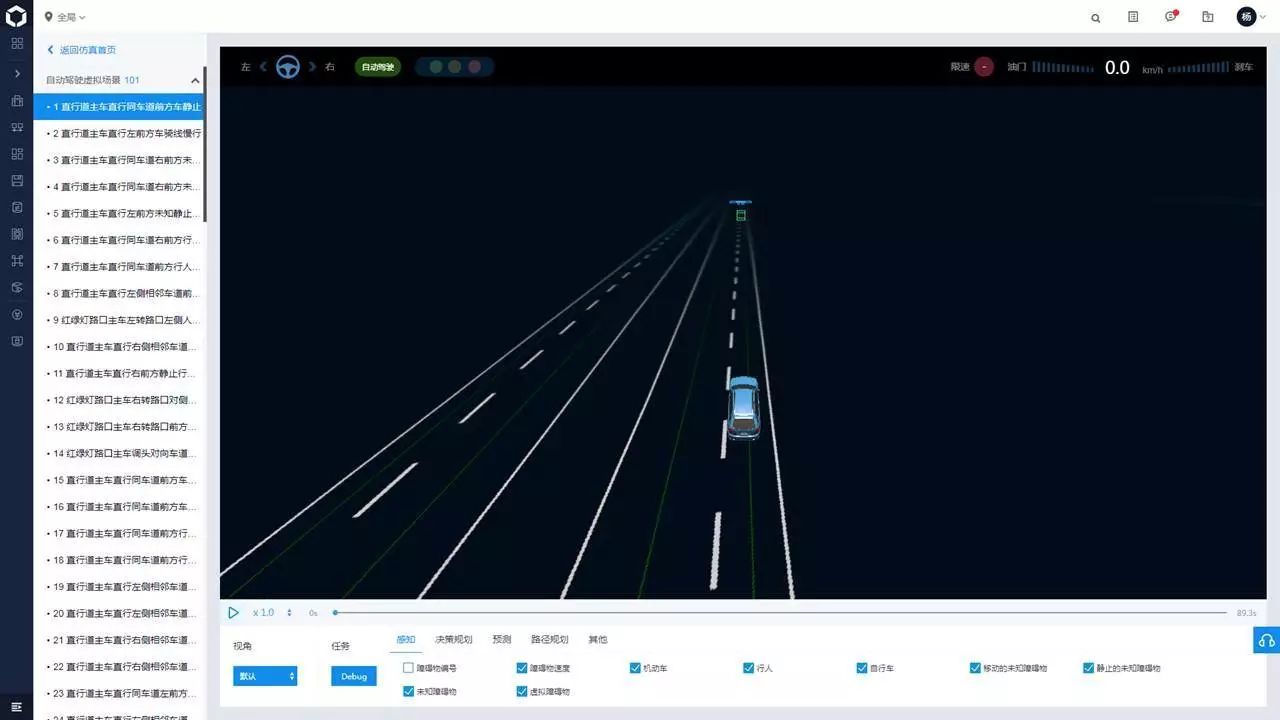
仿真场景
在打开的仿真平台中,可以以默认 Apollo 模块运行仿真场景,也可以提交自己的自动驾驶系统运行仿真场景。Apollo 仿真的具体使用,会有单独分享,这里由于时间关系就不再具体展开了。

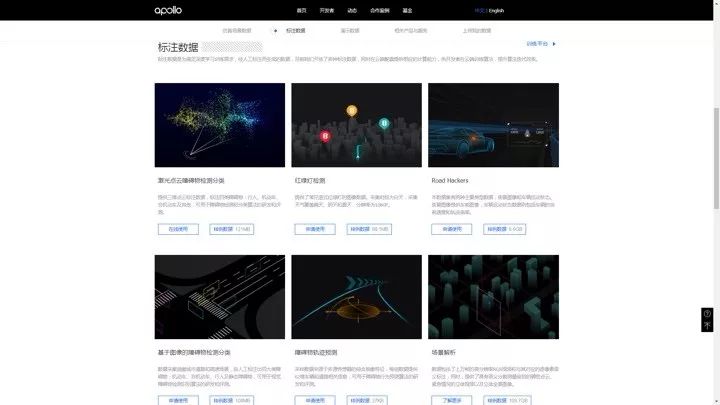
标注数据
标注数据是为满足深度学习训练需求,经人工标注而生成的数据,目前我们开放了多种标注数据,同时在云端配套提供相应的计算能力,供开发者在云端训练算法,提升算法迭代效率。
Apollo 开放了 6 个标注数据集和社区中比较流行的算法,以便开发者调试云端环境:
激光点云障碍物检测分类,我们提供基于规则算法的 Demo(传统机器学习);
红绿灯检测,我们提供基于 SSD 算法的 Demo(Paddle、Caffe);
Road Hackers,我们提供基于 CNN+LSTM 的 Demo(Keras、TensorFlow);
基于图像的障碍物检测分类,我们提供基于 SSD 算法的 Demo(Caffe);
障碍物轨迹预测,我们提供基于 MLP 算法的 Demo(TensorFlow);
场景解析。
下面我们看下“激光点云障碍物检测分类”,可以进入数据集详情页。其他的标注数据各位朋友可以自己查看。
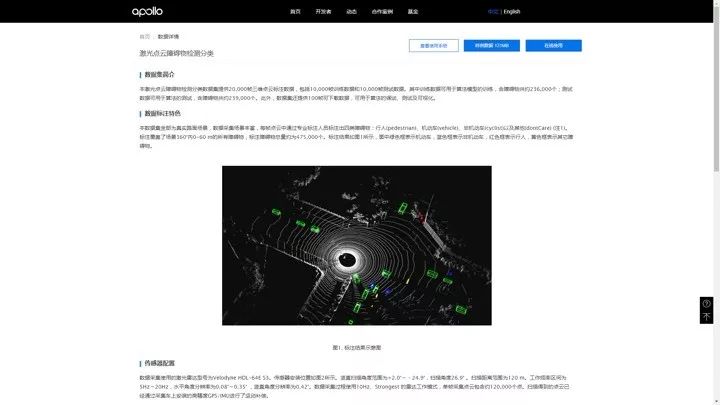
激光点云障碍物监测分类
在数据集详情页中,可以看到数据集的介绍。
点击右上角有一排操作按钮。
点击“查看使用手册”,可以查看更加详细的数据集说明和使用说明。这是“查看使用手册”后打开的 PDF 链接:
http://data.apollo.auto/static/pdf/lidar_obstacle_label.pdf
点击样例数据,可以下载少量的样例数据,具体理解数据格式。
点击“申请使用”,可以申请在云端使用数据集中的大量数据。
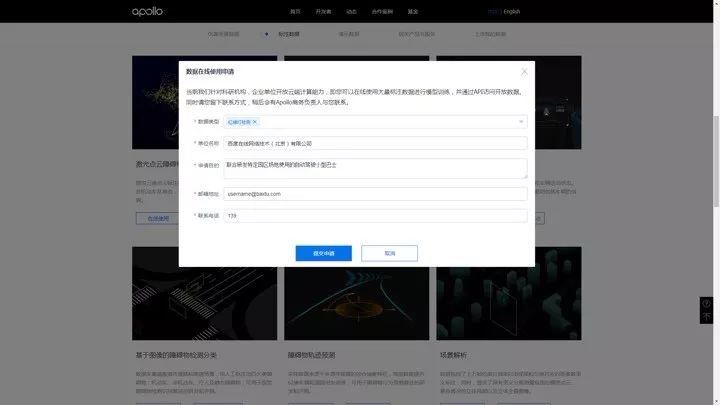
数据在线使用申请
这是点击“申请使用”后弹出的对话框。
当前我们针对科研机构,企业单位开放云端计算能力,即您可以在线使用大量标注数据进行模型训练,并通过 API 访问开放数据。在您申请后,稍后会有 Apollo 商务负责人与您联系。

在申请通过后,“申请使用”按钮会变成“在线使用”,点击后会进入 Apollo 训练平台的新建任务(Apollo 训练平台有着较高的安全校验机制。初次使用需要设定云属性和联系方式,并签订使用协议书;当登录后过长时间未使用时,需要再次登录)。
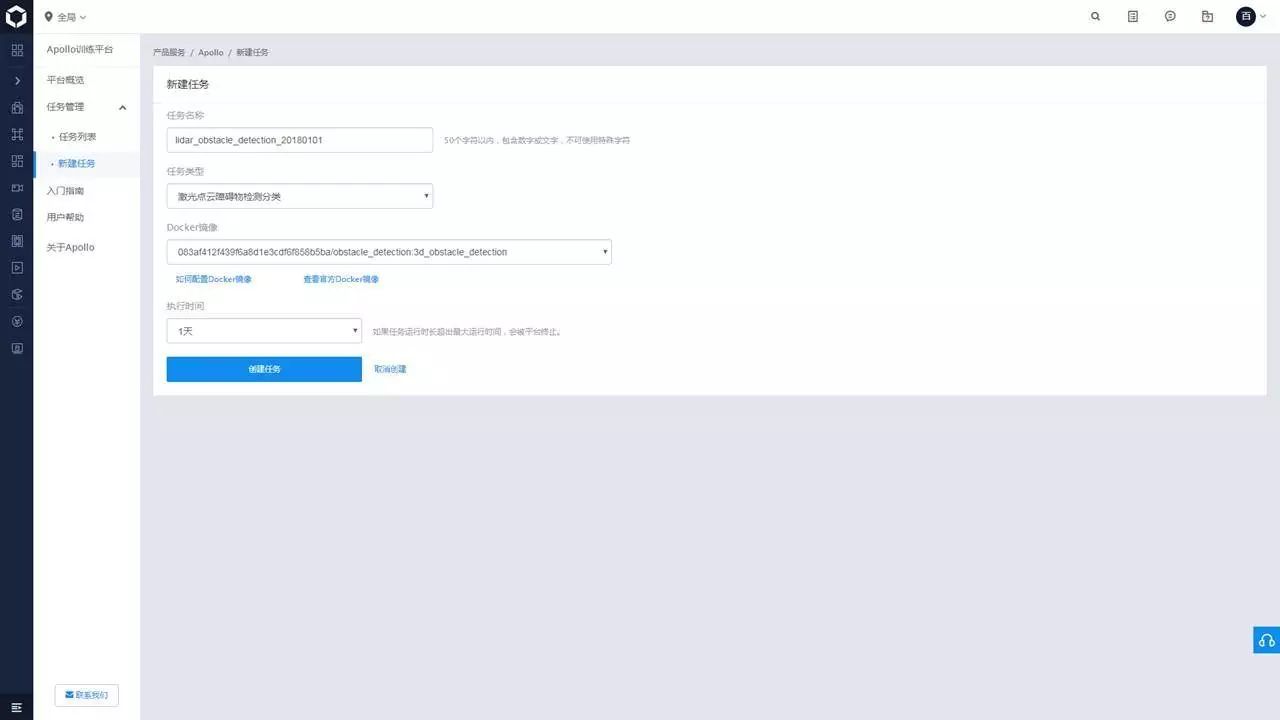
新建任务
在我们新建一个任务以前,我们先简单浏览一下训练平台的其他页面。
左侧的菜单栏有以下菜单:
平台概览
任务管理中的任务列表、新建任务
入门指南
用户帮助、关于 Apollo 功能简单,我们就不展开了,下面着重介绍下前四项。
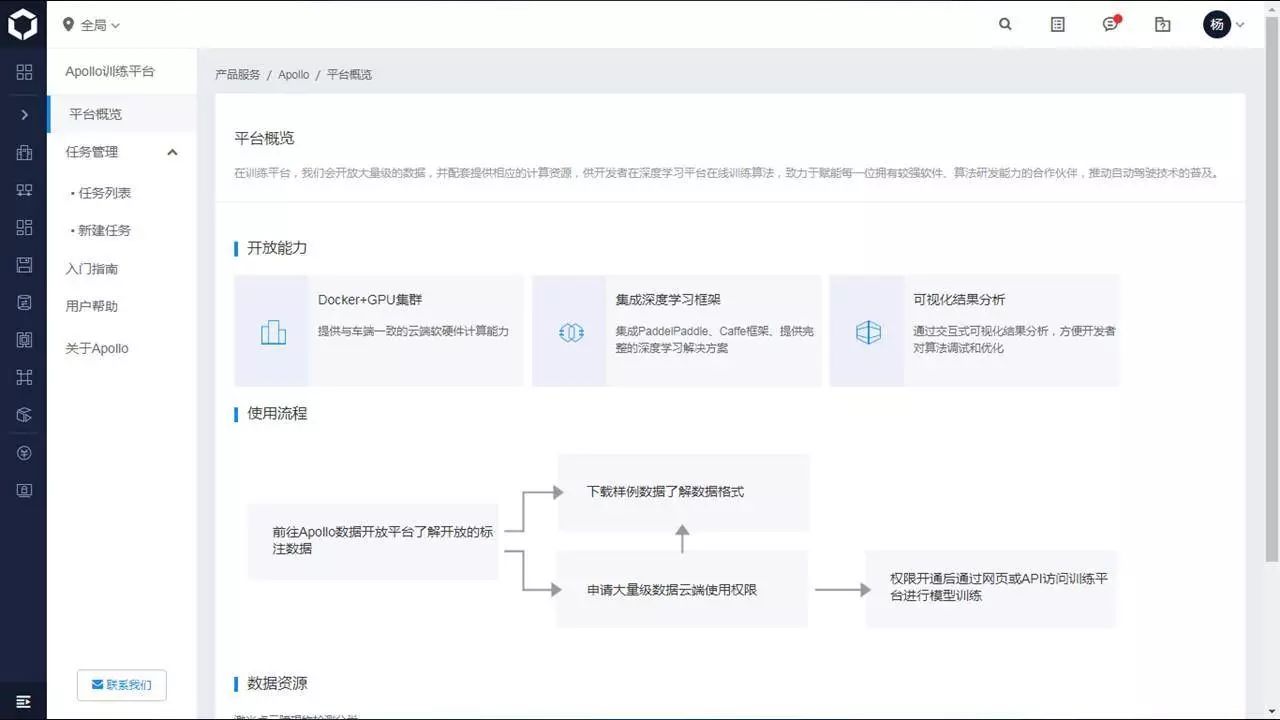
训练平台概览
平台概览页包含对训练平台整体的介绍。在训练平台,我们会开放大量级的数据,并配套提供相应的计算资源,供开发者在深度学习平台在线训练算法,致力于赋能每一位拥有较强软件、算法研发能力的合作伙伴,推动自动驾驶技术的普及。
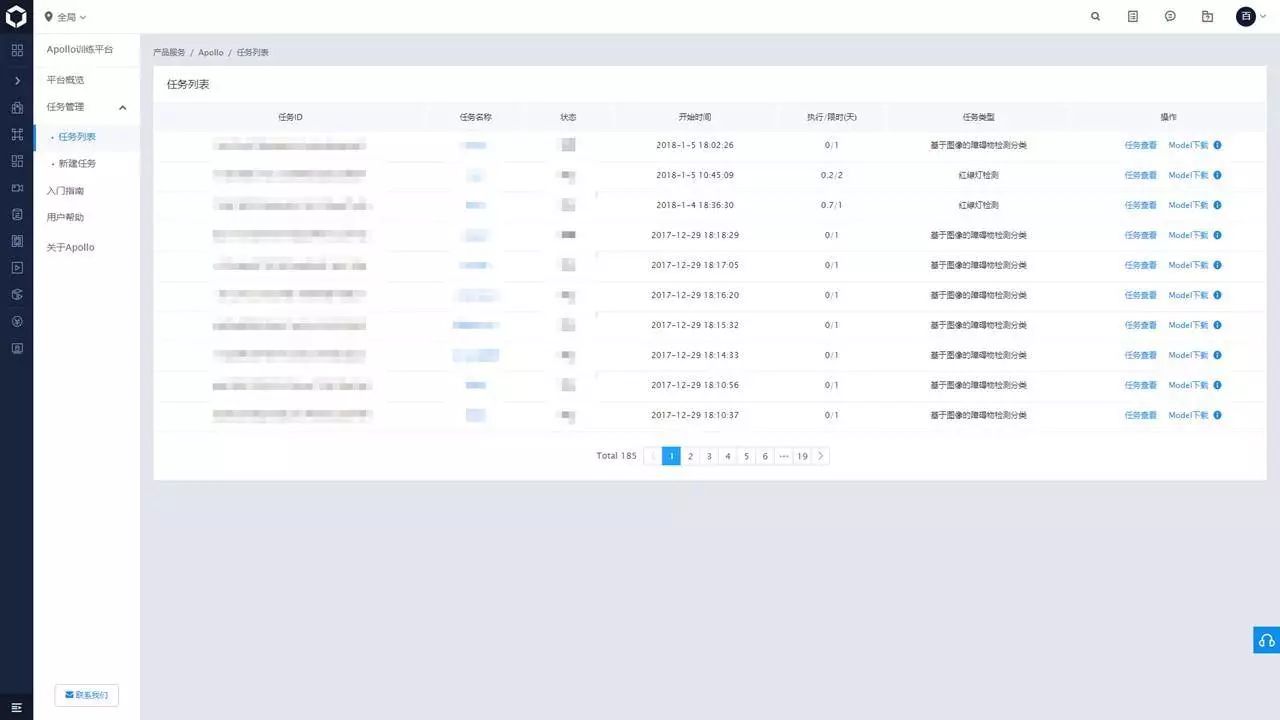
任务列表
任务列表页中有个人拥有任务的列表。
用户帮助中有一些常见问题的解答。
如果开发者有更多的问题,可以使用左下角的联系我们。也可以使用右上角的工单系统。
接下来,就让我们按入门指南,以红绿灯检测为例,讲解一下深度学习算法的研发。
在最上部显示的是为每个有权限的开发者分配的 docker 用户名和密码。
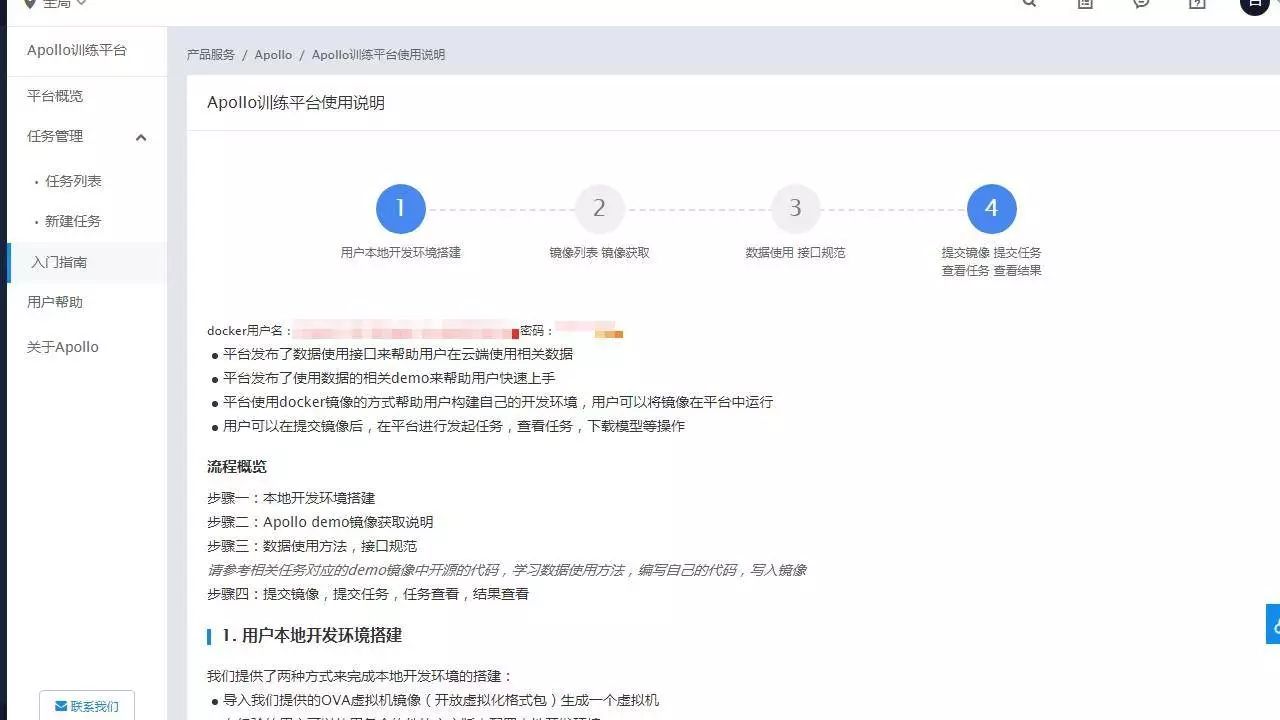
接下来是流程概览:
步骤一:本地开发环境搭建
步骤二:Apollo demo 镜像获取说明
步骤三:数据使用方法,接口规范
步骤四:提交镜像,提交任务,任务查看,结果查看
其中请参考相关任务对应的 demo 镜像中开源的代码,学习数据使用方法,编写自己的代码,写入镜像。
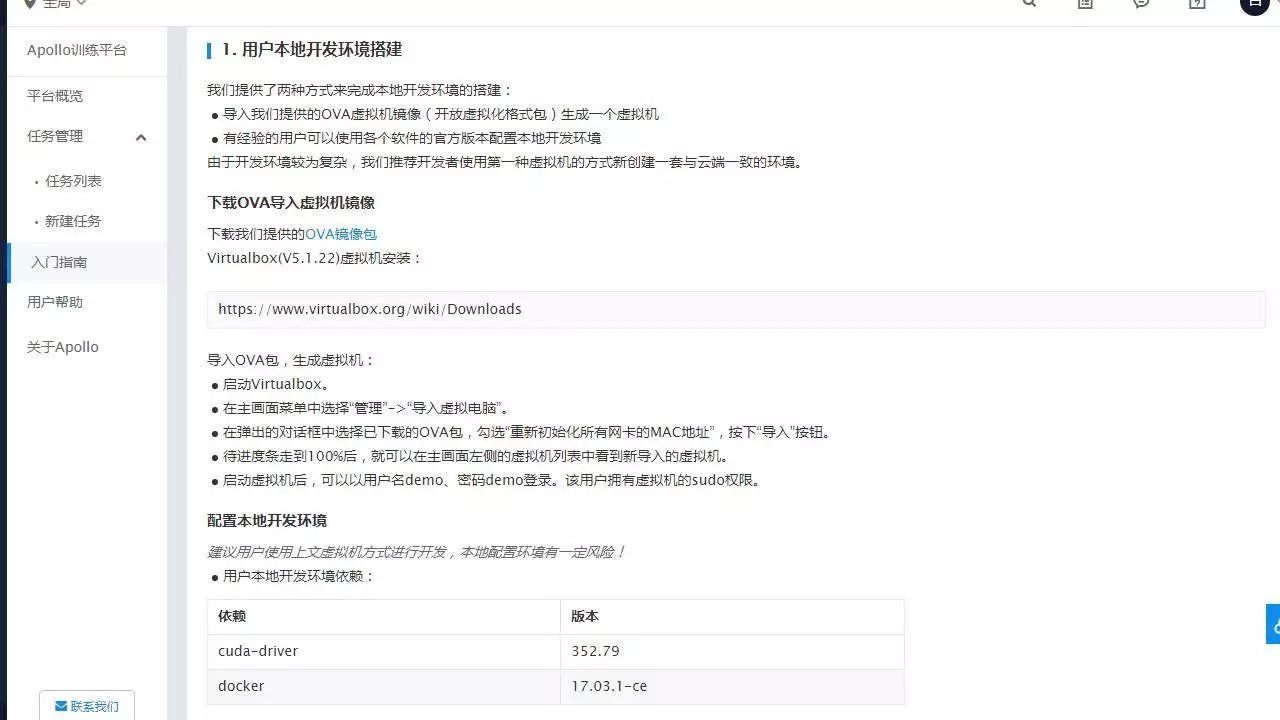
步骤一,为了搭建本地环境,可以下载 VirtualBox 对应的 OVA 镜像包,通过导入 OVA 创建一个预先配置好的虚拟机。
步骤二,Apollo 官方 demo 镜像列表,镜像获取说明。
我们挑选这个镜像作为开发基础:
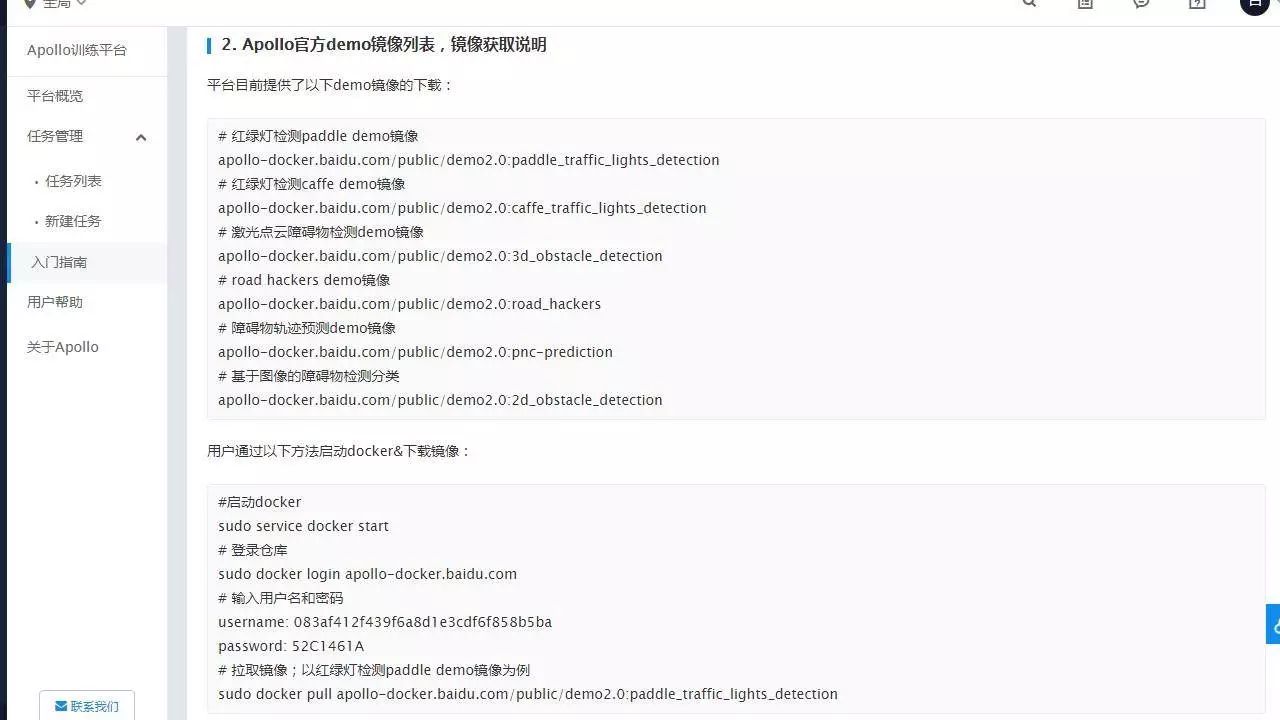
# 红绿灯检测 paddle demo 镜像
apollo-docker.baidu.com/public/demo2.0:paddle_traffic_lights_detection
通过一下步骤获取镜像
# 启动
docker sudo service docker start
# 登录仓库
sudo docker login apollo-docker.baidu.com
# 输入用户名和密码 (在页顶的红字中显示的 Docker 仓库用户名和密码)
username: … password: …
# 拉取镜像 以红绿灯检测 paddle demo 镜像为例
sudo docker pull apollo-docker.baidu.com/public/demo2.0:paddle_traffic_lights_detection步骤三,平台数据使用方法,接口规范。
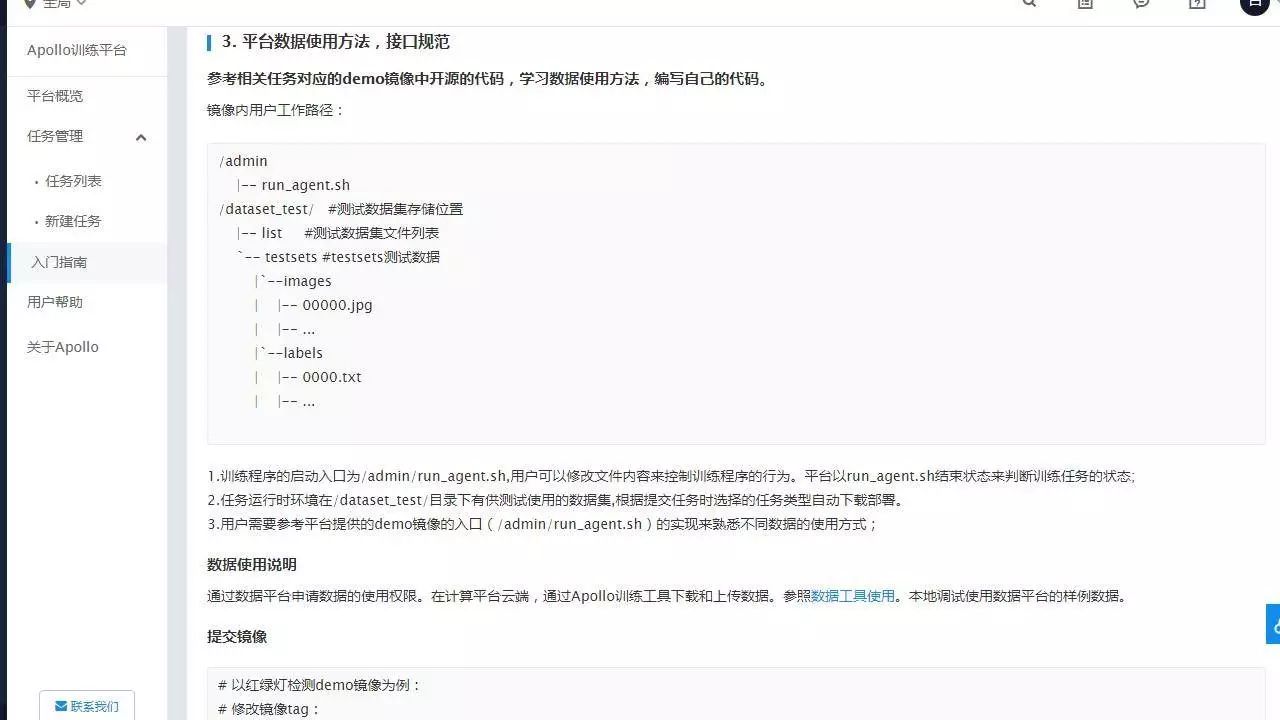
参考相关任务对应的 demo 镜像中开源的代码,学习数据使用方法,编写自己的代码:
训练程序的启动入口为 /admin/run_agent.sh,用户可以修改文件内容来控制训练程序的行为。平台以 run_agent.sh 结束状态来判断训练任务的状态;
任务运行时环境在 /dataset_test/ 目录下有供测试使用的数据集, 根据提交任务时选择的任务类型自动下载部署。
用户需要参考平台提供的 demo 镜像的入口(/admin/run_agent.sh)的实现来熟悉不同数据的使用方式;点击数据工具使用,可以了解开发者在计算平台云端,通过 Apollo 训练工具下载和上传数据的方式。
下面展开介绍下数据工具。
数据工具说明。

开发者可以使用以下三个接口程序,在自己的算法程序中动态获取数据、输出数据、输出日志、输出评测、输出图表、输出预测结果:
apollo_data_get dataSetId outputPath [tag] [offset] [limit]apollo_data_put …
更多的细节,参考:
https://console.bce.baidu.com/apollo/help/faq?name=cal_1_data_help_train6_downupload_data&locale=zh-cn#/apollo/home

我们的 Demo 中提供了作者原本的 Caffe 版,以及 PaddlePaddle 版。有兴趣的朋友可以 MIT 的论文和作者在 Github 上的源码。
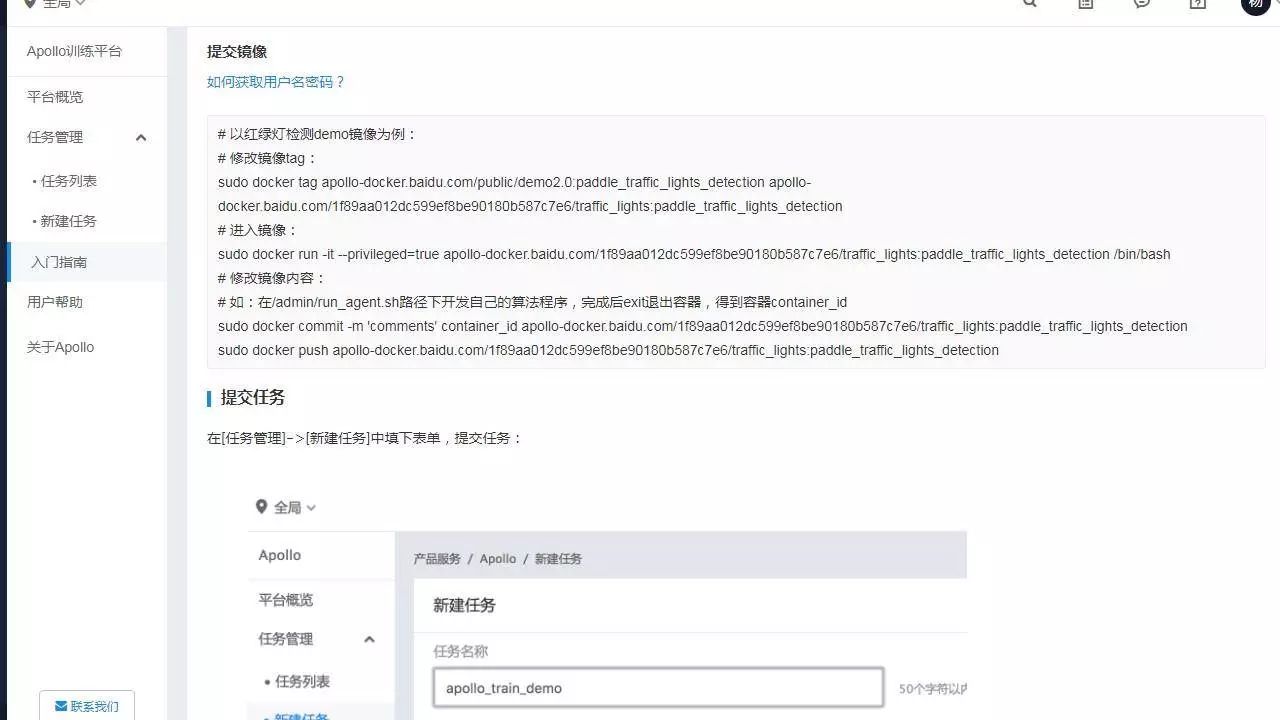
提交镜像
使用以下命令提交 Docker 镜像到仓库中:
# 以红绿灯检测 demo 镜像为例:
# 修改镜像 tag:
sudo docker tag apollo-docker.baidu.com/public/demo2.0:paddle_traffic_lights_detection apollo-docker.baidu.com/1f89aa012dc599ef8be90180b587c7e6/traffic_lights:paddle_traffic_lights_detection
# 进入镜像:
sudo docker run -it --privileged=true apollo-docker.baidu.com/1f89aa012dc599ef8be90180b587c7e6/traffic_lights:paddle_traffic_lights_detection /bin/bash
# 修改镜像内容:
# 如:在 /admin/run_agent.sh 路径下开发自己的算法程序,完成后 exit 退出容器,得到容器 container_id
sudo docker commit -m 'comments' container_id apollo-docker.baidu.com/1f89aa012dc599ef8be90180b587c7e6/traffic_lights:paddle_traffic_lights_detection
sudo docker push apollo-docker.baidu.com/1f89aa012dc599ef8be90180b587c7e6/tr
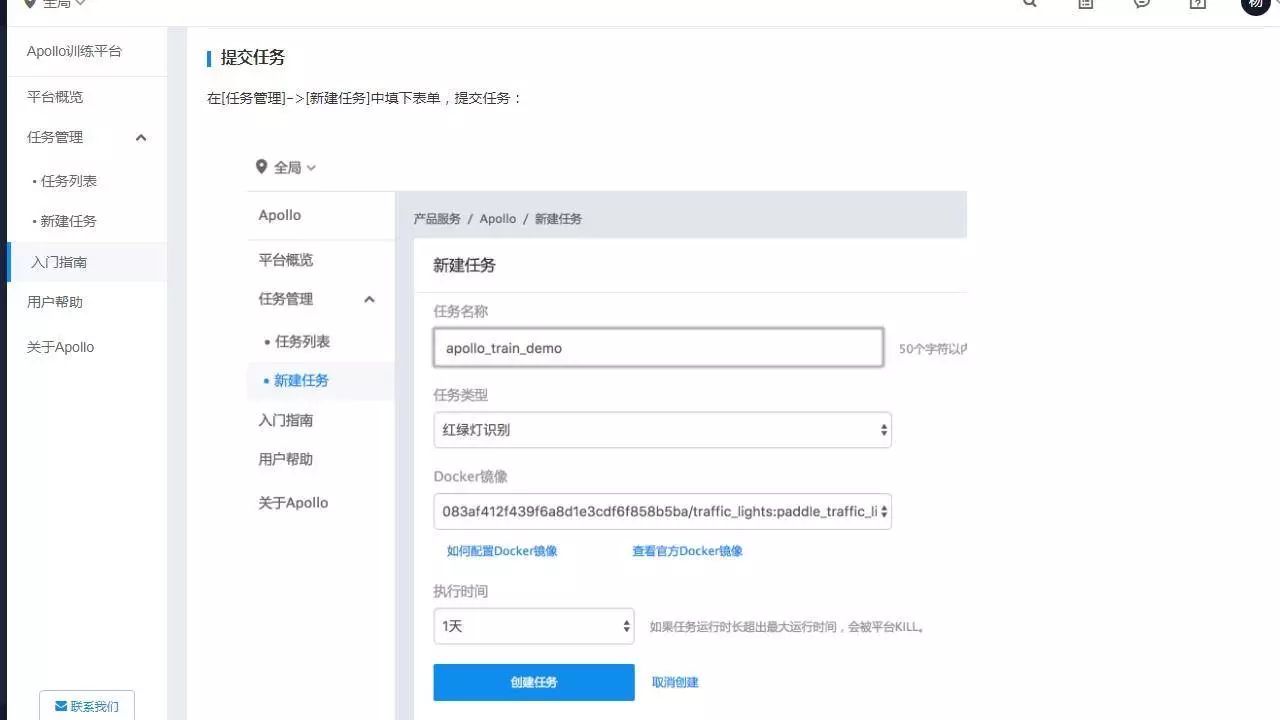
提交训练任务
进入到训练平台的新建任务中,填写任务信息后提交任务。
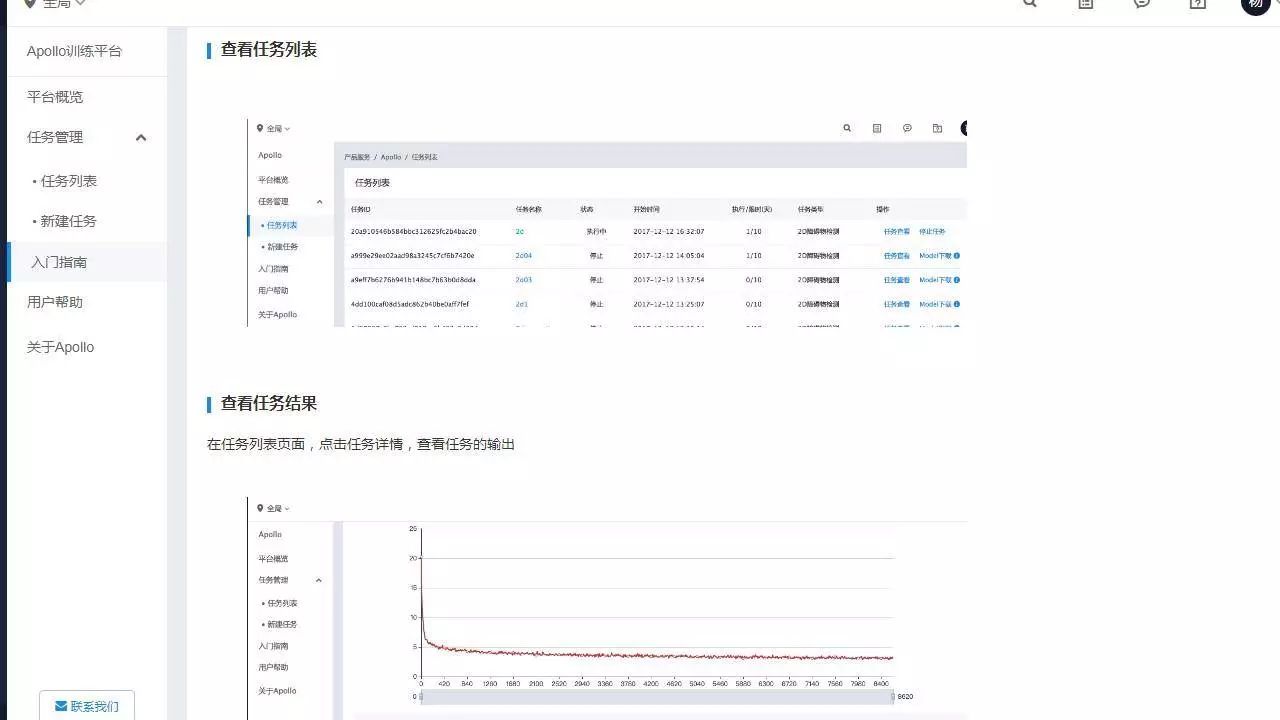
查看任务列表与详情
在任务列表中可以查看自己的任务,点击任务的任务详情链接,可以进入任务详情查看任务执行状态和结果。
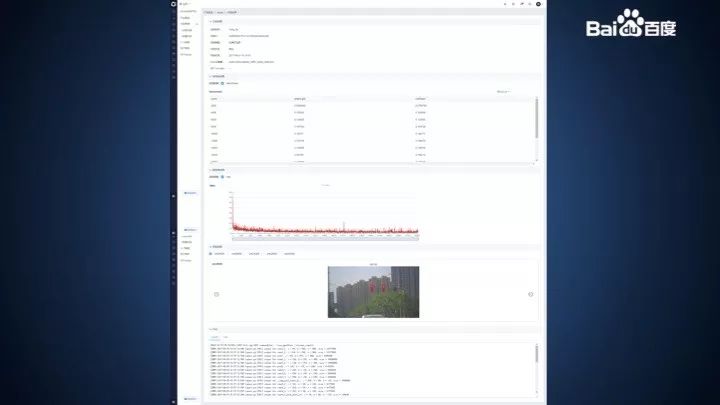
训练任务详情
我们为开发者准备了任务信息、表格信息、图表、日志等基本信息,也提供了每一种数据类型的显示,如 3D 点云。
开发者可以在此页面了解到任务的执行情况、loss 的收敛情况。页面加载时间随着数据量增长,可能需要一点加载时间。

演示数据是为了配合车端代码,通过演示数据体验各模块的能力。
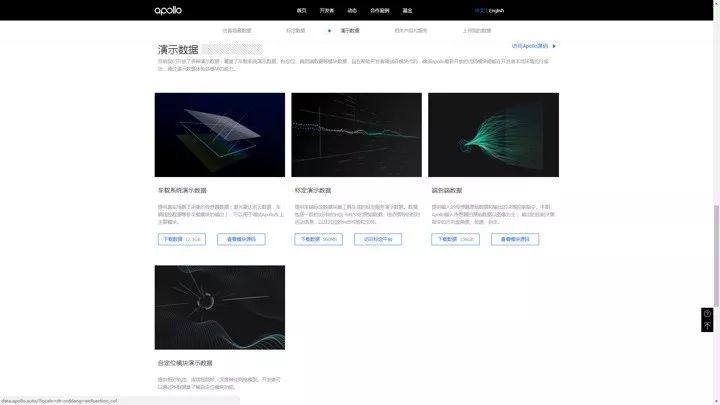
演示数据集
目前我们开放了多种演示数据,覆盖了车载系统演示数据、自定位、端到端数据等模块数据,旨在帮助开发者调试各模块代码,确保 Apollo 最新开放的代码模块能够在开发者本地环境运行成功,通过演示数据体验各模块的能力。
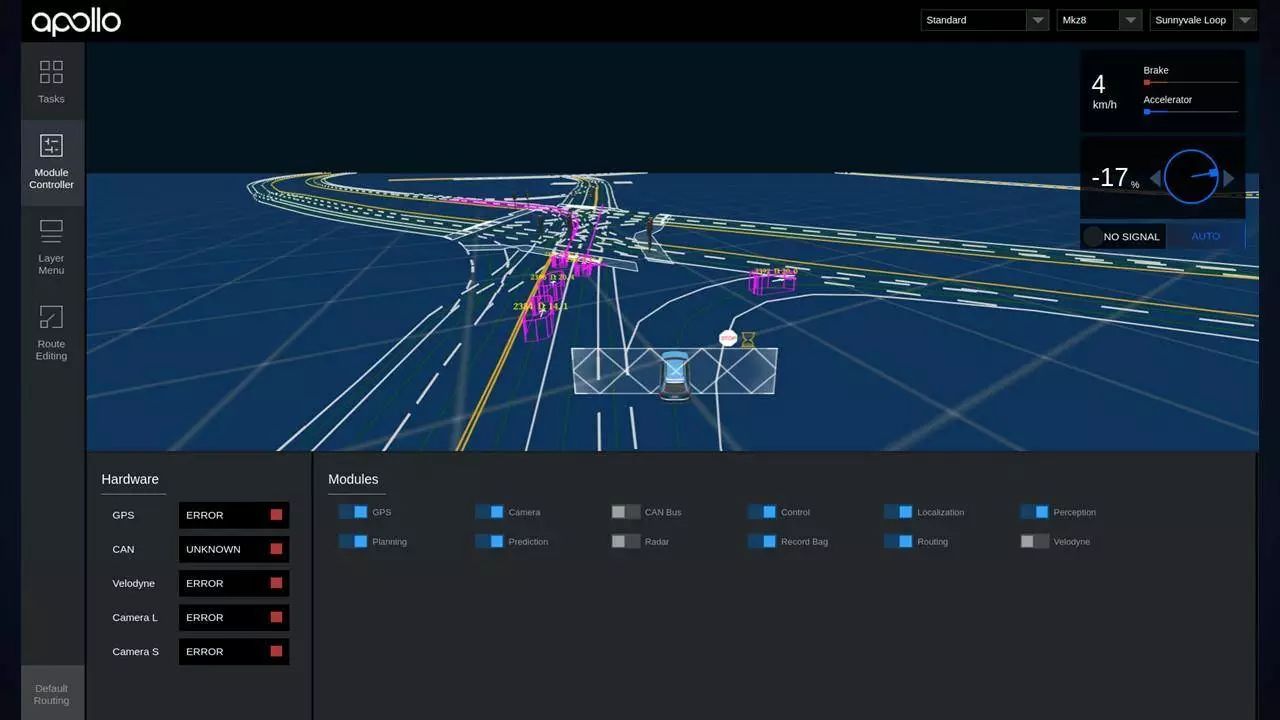
演示数据在 Apollo 中的使用
例如,下载车载系统演示数据,可以通过 Github 的 apollo 源码的编译执行步骤体验完整的 Apollo 车端能力。
该演示数据集包含传感器数据,下载该数据集。按照 Quick Start 的说明,编译 Apollo,使用 rosbag play –l 命令播放该数据集演示即可。

数据上传实战

数据上传实战入口:
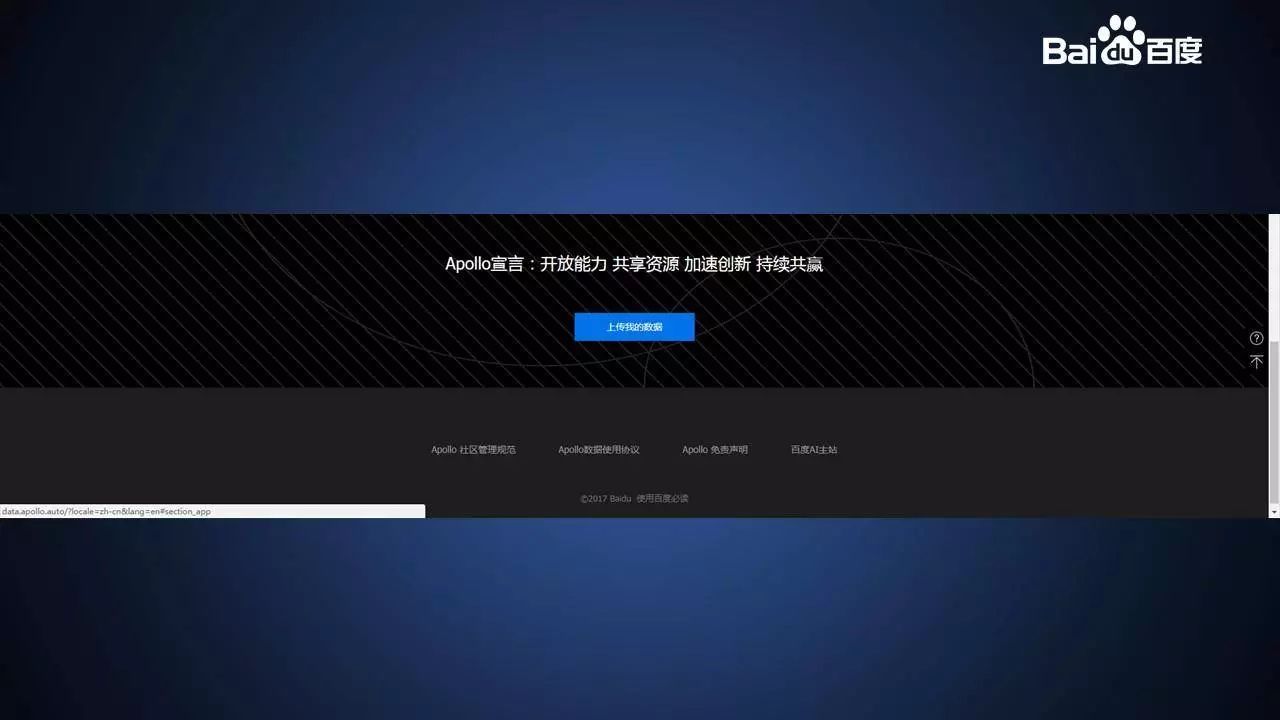
开发者需要填写名称、设备、采集区域、场景属性信息。
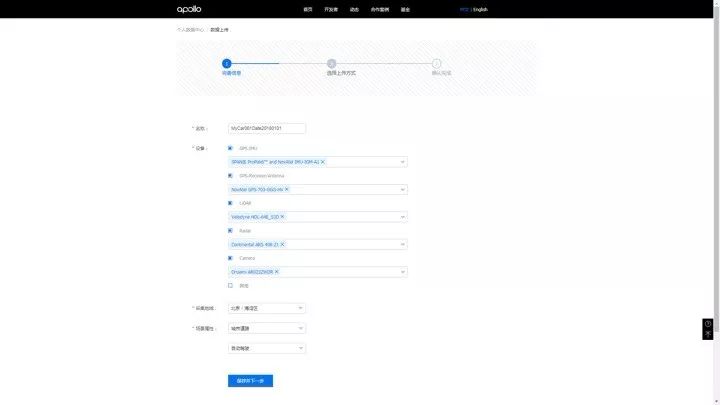
数据上传实战 -2:在线上传
我们提供三种数据上传方式,您可根据上传数据的大小以及宽带速度,选择合理的上传方式:
在线 < 5G 时
客户端 < 1T 时
线下磁盘提供 更大数据
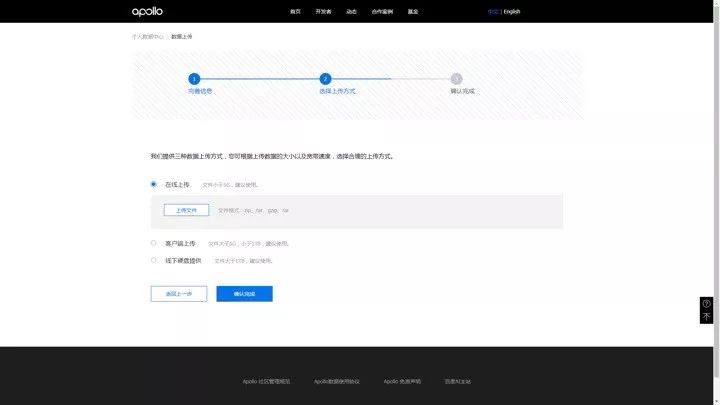
数据上传实战 -2.1:客户端上传
使用客户端上传需要下载上传工具,并下载一个传输配置文件。
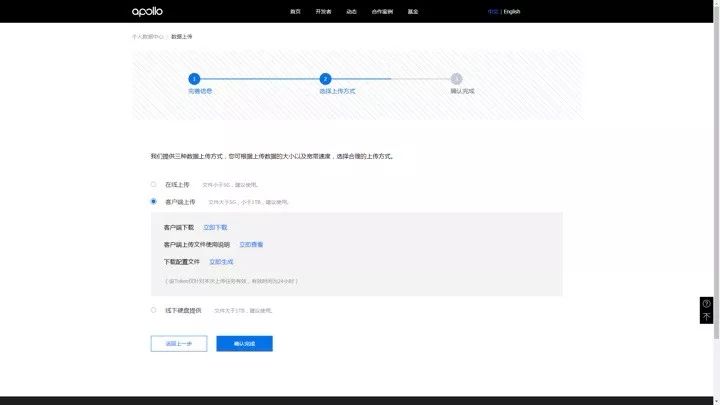
数据上传实战 -3:线下硬盘提供
线下交盘方式在填写好数据信息后,会由 Apollo 商务人员直接对接。
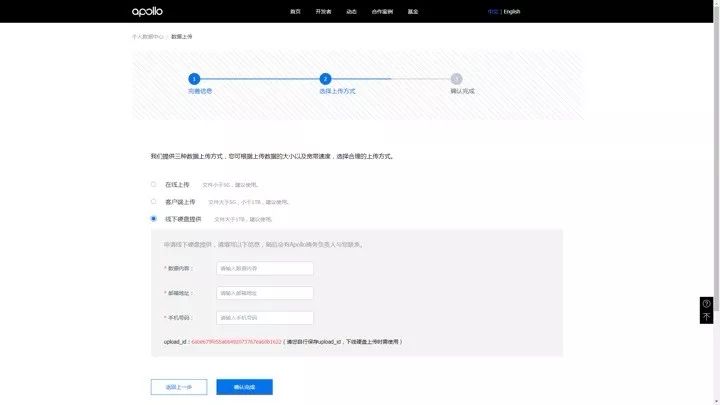
数据上传实战 -3.1:数据上传工具说明文档
上传工具的详细信息可以参考文档。
综上所述,开发者可以在标定平台中标定车辆参数,通过上传数据,申请数据加工,使用数据标注服务,在训练平台中训练 Model,将前几步应用平台的结果合并到 Github 的 Apollo 代码中,将编译结果或源码提交到仿真平台中完成评估,这样就通过“云 + 端”完成了自有车载系统的研发迭代。


Apollo自动驾驶国家队
上图从左至右:
Apollo 无人小巴“阿波龙” 2018 年实现量产,在国内率先实现自动驾驶巴士的商业化;
戴姆勒V260L
林肯MKZ
北汽EU260
奇瑞EQ
奇瑞瑞虎5X
奇瑞艾瑞泽5
长城 WEY
智行者扫路机 “蜗小白”
智行者物流车 “蜗必达”
Apollo 已经有 90 家合作伙伴,其中有超过 15 个汽车厂商(13 家国内自动品牌和 2 家海外品牌);博世、大陆、德尔福等 10 家一流 Tier1 供应商;包括英特尔、英伟达在内的一流芯片厂商;地图公司如 Tomtom;Velodyne、速腾、禾赛等激光雷达公司;地平线、智行者等创业公司;首汽约车、Grab、神州优车等出行服务公司;清华大学、同济大学等高校研究机构。

Apollo 合作伙伴
欢迎大家进一步关注官网 apollo.auto 和 GitHub 获取最新信息。也可以关注“apollo 开发者社区”公众号,关注最新进展。谢谢大家,今天的分享就到这里。

Apollo 2.0 is available
问答环节Q1:请问现在高精地图在 apollo2 上扮演的是个什么位置呢,百度内部高精地图到了什么程度呢?
A:在 Apollo 的自动驾驶中,高精地图和高精定位一直是关键模块。我们知道,在一般人的驾车行为中使用导航软件,比如使用了百度地图,与不使用相比,也会感受到巨大的差别;对于目前自动驾驶的车载大脑使用高精地图也是必要的。使用高精地图,不但可以把最精确的信息提前提供给车载大脑,还可以把传感器探测范围外的道路信息提供给车载大脑。弥补传感器的硬件性能边界;
百度在国内是首家实现的三维高精度地图 & 定位,有着厘米级精度、国际领先、国内最大的自动驾驶车队,并且精细化程度最高、生产效率最高、覆盖面最广。
我可以举一个例子,比如红绿灯难题:一个路口,特定的停止线关联对应红绿灯。如果没有路口的地图信息,仅靠摄像头感知来动态识别所有的语义,实时做出判断,是一个非常有挑战的课题。而在高精地图中,红绿灯包含精确位置、高度,即使在传感器探测范围外,我们也可以提前知道多远将有一个红绿灯提并做出准备,在开到路口处,结合地图语义做出判断,可以容易地探测红绿灯,极大降低了感知难度,避免误识别。
Q2:如果智能车行驶到没有信号的地方 脱离云端大脑 还可以正常自动行驶吗?
A:首先,有必要说明下车端和云端的关系。云端生产训练模型,在车端升级。确保车端本地有可靠的自动驾驶能力;
车辆的运行过程中,的确需要少量的通讯无线信号。比如多传感器融合定位模块,在有通讯条件时,通过通讯,可以帮助我们提高如定位模块的精度。同时多传感器融合定位模块提供冗余的在无信号时的高精定位能力,可以解决诸如在隧道中无信号、林荫道信号不稳定等场景。
在我们研发自动驾驶系统之初,就将 Safety 最关键因素考虑到系统的总体设计之中。在未来的迭代中,会有冗余的 Safety 保障机制。在车辆开出限定范围前或探测到车辆有危险兆候时,采取安全的驾驶行为,如寻找安全的位置靠边停车。
Q3: 对问题 1 和 2 有个后续问题,就是高精地图或模型已经升级,如何部署到车端呢?
A:模型可以通过安全升级套件 ( Sec-OTA) 升级。提供车端及云端 SDK 及运营工具,简单易用、易于运营、集成部署支持安装包双向身份认证、包加解密、防降级、防篡改、设备认证、TOKEN 失效机制支持业务数据电子信封传输,不依赖 TLS 实现数据安全传输支持安装包分片校验,减小内存占用,节省硬件成本支持网络升级及 USB 离线升级可以关注 Apollo 汽车信息安全页面:http://apollo.auto/platform/security_cn.html。
Q4: 怎样申请合作伙伴资格?
A:首先,可以通过 Apollo.auto 主页右侧的「联系我们」,填写合作咨询表单,说明公司简要信息及合作需求。我们的商务人员会尽快与您建立联系。
通过初步需求对接后,双方探讨有效合作模式,共同繁荣 Apollo 的生态,增强 Apollo 平台能力。签写 Apollo 合作协议后,便可以加入 Apollo 成为联盟一员,享受 Apollo 平台的成员权益和资源,参与 Apollo 的快速发展。
更多问题可以关注"Apollo开发者社区"讨论
今日荐文
点击下方图片即可阅读

没用过 TF,没摸过 GPU,我算不算是真正的数据科学家?

人工智能正在改变我们的生活。对于大多数的新手来说,如何入手人工智能其实都是一头雾水,比如到底需要哪些数学基础、是否要有工程经验、对于深度学习框架应该关注什么等等。
在“人工智能基础课”专栏里,王天一教授将结合自己的积累与思考,和你分享他对人工智能的理解,用通俗易懂的语言从零开始教你掌握人工智能的基础知识,梳理出人工智能学习路径,为今后深耕人工智能相关领域打下坚实的基础。

点「阅读原文」,免费试读精品文章




