免杀与特征码
一次性进群,长期免费索取教程,没有付费教程。
教程列表见微信公众号底部菜单
进微信群回复公众号:微信群;QQ群:16004488

微信公众号:计算机与网络安全
ID:Computer-network
如果说黑客技术的精髓在于ShellCode,那么免杀技术的精髓就在于特征码免杀。病毒与木马之所以能逃出反病毒软件的监控,很大一部分原因就是因为有特征码免杀技术的存在。
本文将从简单的脚本木马免杀开始介绍,引导您逐步认识特征码、特征码免杀,进而了解如何修改特征码。愿您能透彻了解特征码免杀技术,从而研究出自己独特的反特征码免杀的方法,进而为以后防御病毒和木马的入侵打下坚实基础。
一、特征码免杀技术
1、理想状态下的免杀
首先,我们要知道黑客在从事病毒木马的免杀活动时是存在着非常多的变数的,也正是那些变数不利于我们直观地了解特征码免杀这一技术行为。为了方便理解,下面会以一个理想环境下的脚本木马为例,讲述黑客是怎样对其进行处理的。
这里以一款比较常见的脚本上传木马为例,用分割法对其进行免杀操作。所谓的分割法,就是指将一个文件分为数份,然后再用反病毒软件查杀,如果发现其中某一份有病毒,则说明这部分含有特征码,然后我们再将检测到病毒的这一份分割为数份,如此往复,直到定位出我们认为长度合适的特征码为止,其操作流程图如图1所示。
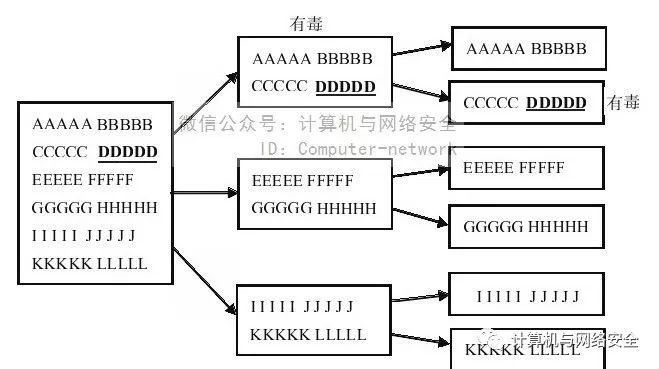
图1 用分割法发现特征码的过程
我们先将文件按图2那样分为两份。

图2 将脚本木马分成上下两份
然后用反病毒软件查杀,发现“默认木马.asp”与"2-0-0.asp"被查杀了,如图3所示。这就说明文件"2-0-0.asp"里含有特征码,下面我们再将"2-0-0.asp"分为两份,继续进行查杀,如果发现哪个文件有病毒就再次将其分割,直到将文件分割到足够小,方便我们更改特征码为止。这里假设我们定位出了特征码在"<%err.clear%>"里,那么只需将其字母大小写进行替换就可以了,例如替换为"<%ErR.clEaR%>"即可免杀。
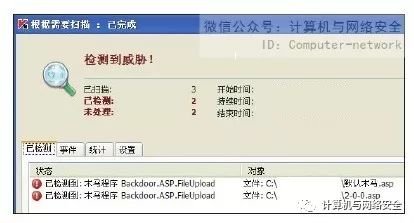
图3 发现2-0-0.asp中包含特征码
2、由脚本木马免杀理解特征码
上面通过分割文件进而逐渐缩小范围的方式讲解了特征码的查找方式,以及特征码的存在形态。但是,如果您跟着前面所讲的内容逐步操作,那么很可能会陷入一个尴尬的循环中,因为只要将文件分割到3份以上时,反病毒软件将不再能检测到病毒,可是如果将它们组合到一起再检测时却仍然会查出病毒。
这是因为某些反病毒软件的扫描器采用的是密码校验和技术,密码校验和技术指的是将一段病毒文件代码计算出特定的值,然后与病毒库的值进行比对,如果匹配到特征码则有毒,反之则无毒。但我们在分割文件时肯定会破坏它,因为原本在一起的代码让我们给分成了若干份,密码校验和自然也就不同了,所以就不会检测出病毒,但是一旦我们将其组合起来,又恢复了其原貌,因此会继续报毒。
在实际操作中,最多可以将文件分为两份,如果整个文件为30行代码,经检测是文件的上半部分报毒,那么也就是说此反病毒引擎获取校验和的代码在前15行。而且如果再将这15行代码分开后会发现不能被检测出病毒,那么我们就可以将目标盯在这15行代码上。
因为某些反病毒软件在密码校验和扫描算法上对字母大小写并不十分敏感,因此如果仅靠更改大小写来免杀,不免有些没“技术含量”了。
下面为您简单介绍一下黑客的脚本木马花指令免杀方法。花指令本是软件安全领域早期的一种代码保护技术。脚本木马的花指令免杀操作起来特别简单,只需在如图4所示的第13行代码的下面添加一句"<%response.write""%>"代码即可。现在再用杀毒软件查杀后发现已经躲过了检测。
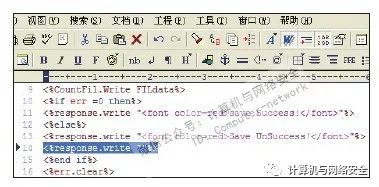
图4 为脚本木马添加花指令免杀
值得注意的是,某种扫描技术可能是某个反病毒厂商发明的,但这并不代表此技术就是某厂商所独有的,比如一些反病毒软件,在查杀例子中的这个木马时与本例中的密码校验和技术的表现是完全一致的。所以我们要更加注重现象,万不可钻牛角尖,认为某种反病毒技术就一定是属于某款反病毒产品的。
二、特征码定位原理
1、特征码逐块填充定位原理
逐块填充定位的方法在国内首先出现在CCL上,CCL是国内首款演示研究性的特征码定位工具,也是一款原理简单的单一特征码定位器。
为了更加直观地介绍各个特征码定位器的原理,制作了一个极其简单的例子程序,如图5所示。当然这个程序是不能运行的,只是为了演示所用。这个程序中的"1111……"代表的是有数据的地方,其中的"AA"就是我们假定的特征码。

图5 理想状态下的例子“程序”
当我们用CCL定位特征码时,它会从区段头部开始填充“00”数据,因为“00”往往都表示“此处为空”,所以如果将某一段数据替换为“00”,也就相当于删除了这段数据。为了让演示效果更加明显,这里将整个文件作为一个区段来定位。现在来看看CCL生成的第一个无后缀文件OUT_00000000_00000010,如图6所示。不难发现,第一行已经被无意义的“00”给填充了,我们假设的特征码"AA"现在已经不存在了,很显然这个文件是不会被反病毒软件查杀的。

图6 被CCL填充后的效果
下面再看看生成的第二个文件OUT_00000010_00000010,如图7所示。

图7 CCL生成的第二个文件
我们发现由于填充的部位变成了第2行,所以特征码"AA"这时又暴露出来,因此这个文件肯定会被反病毒软件查杀。再来看第三个文件OUT_00000020_00000010,如图8所示。

图8 CCL生成的第三个文件
很显然,这次是文件的第3行被“00”填充了,这个文件依然包含特征码。到了现在,我们可以猜得出来,第四个文件肯定是第4行被填充了,而且由于没有覆盖住特征码"AA",因此它同样会被杀,如图9所示。

图9 CCL生成的第四个文件
在这次操作中CCL总共生成了4个文件,其中3个被杀,经过简单的推理可以确定,是第一个文件覆盖掉了特征码,又因为第一个文件中的第一行数据被“00”填充了,进而可以很自然地推断出—特征码就在第一行。
但是这个特征码的范围是不是有些大呢?其实在真正操作的时候,如果我们想得到比较小的特征码范围,可以将CCL一次填充“00”的字节数减少,例如由默认的16字节减少到4字节。为了便于您的理解,做了一张比较形象的CCL特征码定位示意图,如图10所示。通过这张图可以更加透彻地理解CCL特征码定位原理了。
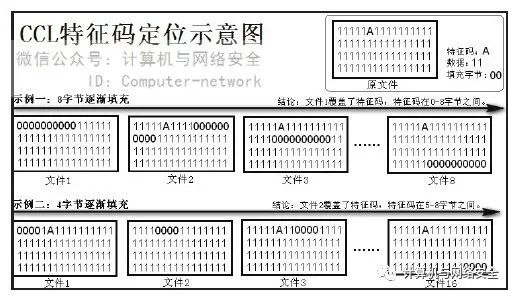
图10 CCL特征码定位示意图
2、特征码逐块暴露定位原理
所谓的逐块暴露其实就是一个与逐块填充相反的过程,MyCCL是现在应用最广泛的一款特征码定位器,也是一款采用逐块暴露定位原理的特征码定位软件,它因反病毒软件采用复合特征码定位而诞生。所谓的复合特征码,就是一个病毒定义了一套以上的特征码,只有改掉所有的特征码后才不会被查杀。
为了便于演示MyCCL的复合定位方法,这里准备了如图11所示的示例程序,其中的"AA"、"CC"为两个特征码,如果这两个特征码有一个存在,反病毒软件就会报毒。现在我们看看MyCCL究竟是怎样工作的吧。

图11 一个用于实验的多特征码程序
将MyCCL文件的分块个数设置为3,MyCCL会将“例子.exe”按照其特有的填充方式生成3个文件,并用“00”填充不同的位置。第一次分为如图12所示的3个文件。由图12可知,第一个文件暴露出了1/3的数据,剩下的被“00”填充了,第二个文件暴露了2/3的数据,而第三个文件则全部暴露了。根据MyCCL生成文件的规律可知,它生成第一批文件采用的是由头到尾的暴露方式。但是在图中可发现,这3个文件或多或少都含有特征码,当反病毒软件将这3个文件全部删除后,用MyCCL生成了第二批文件。
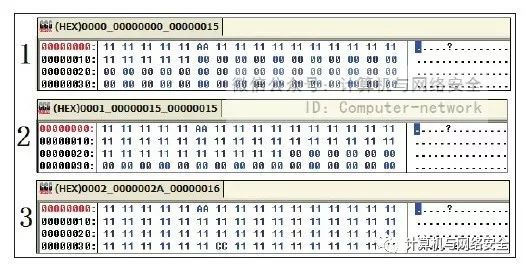
图12 MyCCL生成的第一批文件
当然,第二批生成的文件仍然是3个,如图13所示。
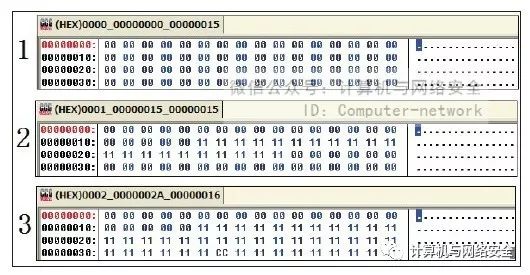
图13 MyCCL生成的第二批文件
这次MyCCL采用的方式有些特别,它首先默认上次生成的第一个文件中有特征码,也就是说MyCCL先默认第一个文件暴露的那块数据中含有特征码,所以这次它生成的3个文件都不含有这一块数据,而是直接从第二块数据开始暴露。
这3个文件生成完毕后,在使用反病毒软件查杀时只有暴露了第三块数据的文件被删掉了,由此MyCCL就很容易地判断出在第三个文件中包含特征码。在用反病毒软件将第三个文件查杀之后,再用MyCCL生成第3批文件,如图14所示。
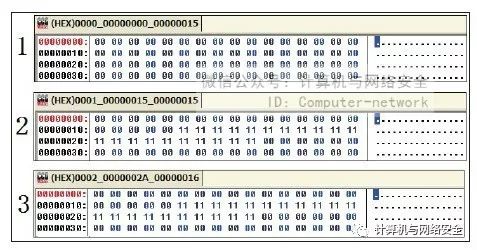
图14 MyCCL生成的第三批文件
在图14中,我们发现特征码已经被完全覆盖了,由此MyCCL得出了如图15所示的结果。

图15 MyCCL生成的特征码分布报告
为什么MyCCL最后一次生成的文件中,其中两个是一样的呢?其实很简单,用一句话概括就是“由上到下逐渐暴露,遇到特征码以后则始终将其覆盖,直到覆盖掉所有特征码”。因为在生成第二批文件时MyCCL已经知道第三个文件中包含有特征码了,但是遵循“遇到特征码以后则始终将其覆盖”的原则,所以本该暴露的第三块数据并没暴露,于是就造成了两个文件内容一致的奇怪现象。
下面制作了一张MyCCL特征码定位原理示意图,如图16所示。通过这张示意图可以帮助您更清楚地了解MyCCL的特征码定位原理。
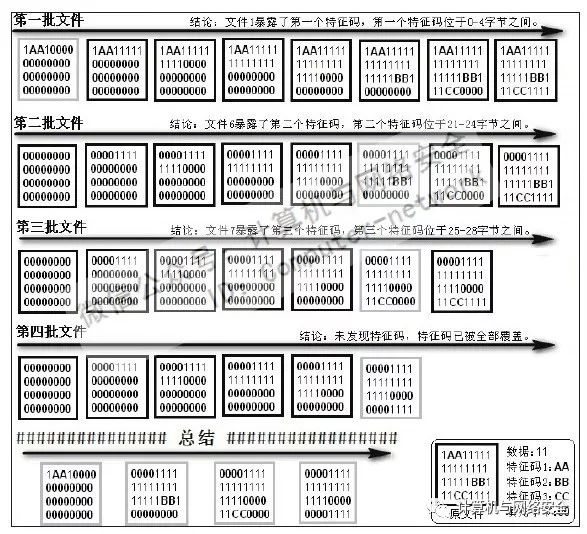
图16 特征码逐块暴露定位原理
3、特征码混合定位原理
特征码的混合定位一般是应用二分法或逐块暴露法定位出含有特征码的较小区域,然后再采用逐位测试法探测出特征码的具体位置及长度。
应用特征码混合定位原理比较成熟的工具是MultiCCL定位工具,它的具体思路是先使用二分法定位出特征码的粗略位置,再用逐位测试法探测出特征码的具体位置与长度。
由于上面在介绍脚本木马免杀技术时已经介绍过二分法,因此下面主要探索逐位测试法的定位原理。
首先假设我们拥有如图17所示的测试数据块。
再假设这个数据块已经被特征码定位软件(简称“定位软件”)用粗略定位的方式确定里面含有特征码。而由图17可知,这个数据块含有4组特征码,这其实应该是一个比较罕见的情况。

图17 含有特征码的测试数据块
一般情况下定位软件会从头部开始逐位后退,直到后退到如图18所示的位置时,反病毒软件才报毒。

图18 第一段特征码暴露出来
这时定位软件已经知道第一段特征码的末尾在哪里了,随后定位软件会逐位向前移动测试,如图19所示。

图19 逐位向前移动测试
在图19所示的这组文件中,进行到最后一步时反病毒软件才会报毒,这时定位工具确定了这一段特征码的头部位置。到此为止定位软件已经精确地定位出了特征码的开始与末尾偏移,于是将此特征码填充掉,然后开始对第二个特征码进行定位,如图20所示。

图20 开始定位第二段特征码
定位软件按照此逻辑如此往复后,最终会生成一个如图21所示的文件。至此所有的特征码都被精确定位完毕。

图21 最终生成的文件
三、脚本木马定位特征码
为了让您更直观地了解特征码定位技巧,下面以脚本木马的特征码定位为例进行讲解,因为它相对更容易理解。俗话说“磨刀不误砍柴工”,下面先为您介绍一下MyCCL特征码定位器这个工具,相信会对大家日后的深入研究与自学有帮助。打开MyCCL程序后的界面如图22所示。为了便于理解,我将MyCCL分为“参数区”与“控制区”来进行讲解。
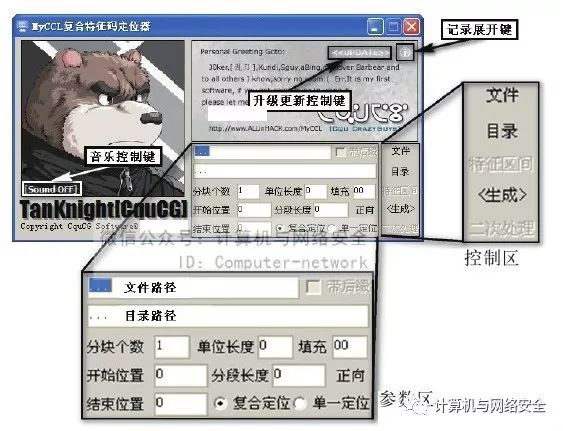
图22 MyCCL的主界面
(1)参数区
参数区各个参数及其说明如下。
文件路径:将进行特征码定位的木马文件的路径(必填项)。
目录路径:存放MyCCL即将生成的特征码样本的目录,默认是与木马同文件夹下的OUTPUT目录(必填项)。
分块个数:生成特征码样本的数量,数量越多,定位结果越精确(必填项)。
单位长度:填充无效字节的单位长度,例如填120,就是每次填充120个无效字节。
填充:填充数据设定,默认为“00”,也可以是其他十六进制信息。
开始位置:第一个特征码样本将会从此处指定的位置开始填充。
分段长度:填充字符的总长度。
结束位置:最后一个特征码样本填充到此处指定位置便结束了。
“正向”按钮:选择填充方向,例如“正向”就是从文件头部开始暴露。
复合定位:超过一处特征码时便需要选择此定位方法,推荐选择此方法。
单一定位:单一特征码定位。
(2)控制区
控制区各个按钮及其说明如下。
“文件”按钮:用来选择要进行免杀的木马文件。
“目录”按钮:用来选择生成特征码样本文件的目录,默认即可,无需选择。
“特征区间”按钮:用来展开存放已定位出来特征码的信息栏。
“<生成>”按钮:用来执行特征码定位样本生成的命令。
“二次处理”按钮:单击“<生成>”按钮,并删除带毒样本后,用来二次精确定位。
关于MyCCL就先介绍到这里,由于MyCCL存在后缀名Bug问题,所以不能生成带有后缀名的文件,但是现在的大多数反病毒软件都已经不查杀无后缀的脚本木马了,所以需要用一款工具来辅助完成任务。
现在就用海阳顶端脚本木马(简称“海阳木马”)做一个针对某反病毒软件的免杀案例。打开MyCCL后选择海阳木马,分块个数填写为100,如图23所示。为什么这个MyCCL变样了呢?其实这是一款改造过的MyCCL,它比原先的版本更加稳定,而且也没有了背景音乐,并且它对程序的一些资源与区段进行了删减,所以其体积也减小了20%,更利于您研究与试验。
图23 MyCCL安静稳定版
单击“<生成>”按钮后,运行文件名批量更改工具Bulk Rename Utility,打开特征码样本文件夹OUTPUT,依次单击菜单栏的“动作”→“全选”,如图24所示。
图24 依次单击菜单栏的“动作”→“全选”
然后在“添加”框架内的“后缀名”里填入.asp,如图25所示。最后单击右下角的“重命名”按钮即可。
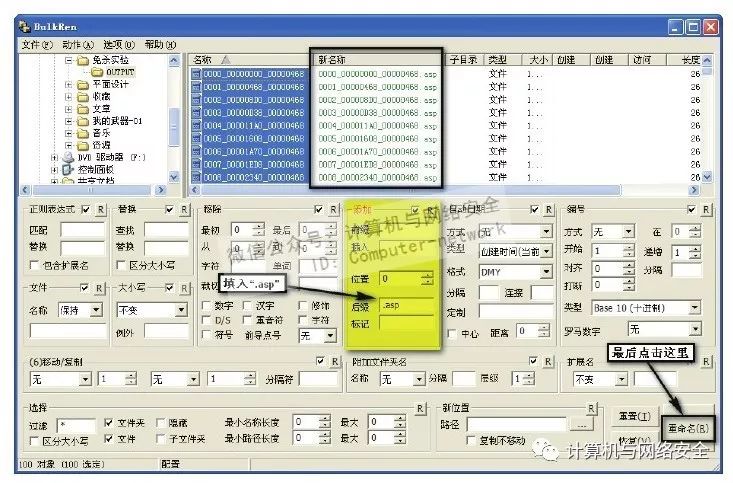
图25 在“添加”框架内的“后缀名”里填入.asp
现在找到特征码样本文件夹OUTPUT,并进行查杀,查出了8个带毒文件。删除报毒样本后,还需将文件名更改回来,这样才能被MyCCL正确识别,否则将会定位出错误的结果。
再返回到MyCCL界面,单击“二次处理”按钮,并用前面的方法将文件重命名之后再次查杀。如此反复,最后得到的结果如图26所示。
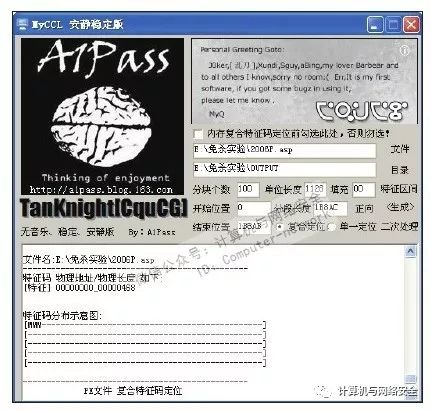
图26 最后结果
应该怎样理解MyCCL提供的以下报告呢?下面就带领您一点点来了解。

其实MyCCL提供的报告已经比较详尽了,需要重点关注的就是“[特征]00000000_00000468”这段报告信息。正如上面所标示的,从偏移地址为0x00000000的地方开始,其后面0x00000468偏移量的数据内含有特征码。
也许您还不明白偏移地址是什么意思,拿0x000000A0这个偏移地址来说,如果想知道它指定的偏移地址是什么数据的话,先用WinHex等十六进制查看工具打开这个文件,然后在这个工具中看看“日光海岸.mp3”这个文件的0x000000A0处是什么信息。
首先打开WinHex十六进制编辑工具,按【Ctrl+O】快捷键打开文件对话框,选择“日光海岸.mp3”,在Offset栏下的第11行就是我们的目的地,如图27所示。这个位置的内容是一个十六进制数据D3。
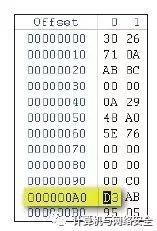
图27 文件“日光海岸.mp3”偏移0x000000A0处的十六进制信息
知道怎样寻找偏移地址后,那么找到刚才定位出来的特征码“[特征]00000000_00000468”也就容易了。但是在这之前需要注意的是,MyCCL生成的报告有个缺陷,虽然前面的地址信息是十六进制的,但是后面的长度信息却是十进制的,所以在使用前要将其转换一下才行。
由此我们找到了特征码所在的位置,也就是如图28所示的地方。当然,一般情况下是不会出现这么长的特征码的,这里是为了便于您理解,所以举了一个比较特殊的例子。
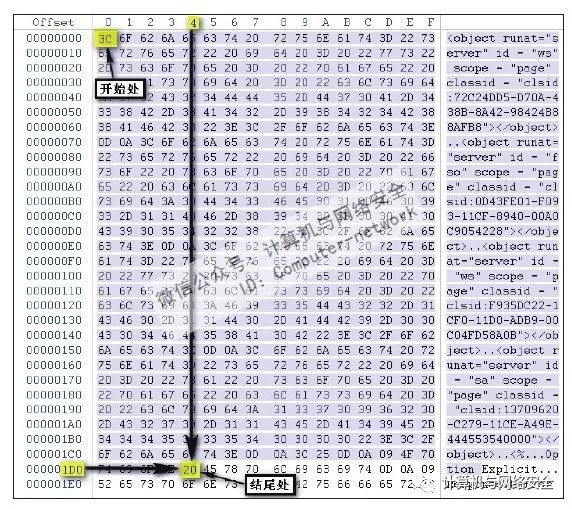
图28 特征码的开始与结尾偏移
四、MyCCL查找文件特征码
1、MyCCL的典型应用
NBSI是国内SQL注入工具的代表作品之一,今天我们就用MyCCL定位一下NBSI的卡巴斯基特征码,为大家演示一下黑客是怎样制作免杀的,以及黑客在免杀中会思考什么问题。
首先找到一个无壳版的NBSI,运行MyCCL后选择NBSI,并在“分块个数”中填写20。您或许有些疑问,这里的分块个数为什么设为20,是以什么为依据的呢?其实设置分块个数不外乎就涉及两个问题,一个是时间问题,另一个是成功率问题。
从时间上来讲,分块个数越多,定位的特征码就越精确,就拿NBSI来讲,如果第一次生成330 895个特征码样本的话,甚至不用“复合定位”进行二次处理就可以定位出精度为1个字节的特征码。但是这33万个文件没有1个小时恐怕是处理不完的。
因此,第一次完全可以少生成一些,例如先定位出500字节的特征码,由于文件的绝大部分区域不含有特征码,所以在二次复合定位时完全可以把那些不含特征码的区域忽略掉,这样一来就可以在极小的区域内查找特征码了。如果就像上面所说的,第一次定位出500字节精度的特征码,那么进行第二次符合定位时,只需生成250个特征码样本即可完成特征码的查找工作。这样一来总共生成的文件不超过2000个,效率一下提高了200多倍。
当然,究竟生成多少个样本还是要靠个人把握的。就我个人来讲,我一般第一次会先生成20个样本,第二次则以精度优先,在生成样本个数不超过500的前提下,将精度控制在50字节以内。如果将精度控制在50字节以内会超过500个样本,我便会考虑降低一些精度了。总之我的原则就是将样本个数控制在500个以内,而精度则控制在50字节以内,这样,针对大多数体积在100KB~1000KB的木马文件来说,定位的效率会比较高。至于成功率问题,后面会单独探讨。
现在回到免杀现场,在设置完生成个数后,单击“<生成>”按钮生成样本文件。用卡巴斯基反病毒软件扫描后删除所有带毒的文件,然后单击“二次处理”按钮,再用卡巴扫描。如果这一次并没有发现病毒,再次单击“二次处理”按钮,将会出来如图29所示的结果。
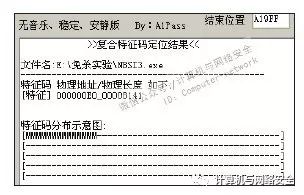
图29 定位NBSI的卡巴斯基特征码结果
通过结果可以看出NBSI中只存在一处特征码。但由于这是第一次定位,所以特征码精度有些吓人,竟然是8141个字节!这肯定要进行复合定位了,单击“特征区间”按钮后弹出一个名为“填充/特征码区间设定”的界面,如图30所示。
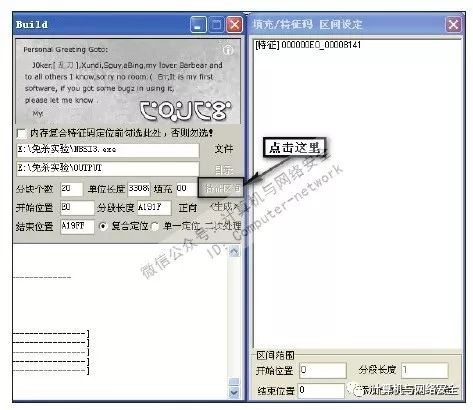
图30 “填充/特征码区间设定”界面
不要被它的名字给唬住了,其实它就是一个记录特征码的地方,只不过加了一些针对特征码进行二次处理的功能而已。由图30不难发现,刚刚定位出来的特征码就在那里。接下来右键单击这段特征码,由于特征码的精度仍然有些大,所以在弹出的菜单里选择“复合定位此处特征码”,然后在“单位长度”里填写80,也就是说这次定位出来的特征码精度为80字节,如图31所示。

图31 填写单位长度
然后重复上面的步骤,单击“<生成>”→用反病毒软件扫描并删除→单击“二次处理”→用反病毒软件扫描并删除→单击“二次处理”……
需要注意的是,由于生成的文件个数较多,在单击“<生成>”按钮后会出现计算机假死状态,不过等待一段时间即可生成完毕。
经过几次重复操作后,最终得到的特征码为00003AFB_0000005C。
2、针对MyCCL的一点思考
上面我们提到分块个数除了会影响到特征码查找时间以外,还会涉及成功率问题,也许有过免杀经验的您会对此疑问重重,但是相信你看完以下两个问题后就不会有困惑了。
为什么有时候定位的特征码不尽相同?除了和反病毒软件所采用的部分技术有关之外,还有没有其他原因?
为什么定位特征码时,总是精度比较低,或者经常会出现一些奇怪的问题?
相信这两个问题会令一些读者沉思一下。可以确定的是,上面的问题必然是有原因的,不可能是随机出现的问题,而既然有原因,那么肯定就有办法找到原因。
要想找到相关的原因,我们还要从MyCCL的工作原理说起。举一个比较极端的例子,假设有如图32所示的一个文件。

图32 一个比较极端的例子
它的特征码"AA"正好位于文件的正中央,当我们将“分块个数”设为2时,就会出现如图33所示的流程。

图33 分块个数为2
由图33可知,文件被填充到一半时正好会破坏掉了特征码,此后无论怎样被填充都不会将特征码暴露出来了,所以MyCCL得出了“文件一与文件二掩盖了特征码,特征码在24~48字节之间”这个结论,也就是将半个文件都定位成特征码了。而当用这个结论来进行二次“复合定位特征码”时,却永远也找不到带毒文件,因为这处特征码在定位时已经被一分为二了。所以说此时用MyCCL定位的最高精度就是这一半文件的大小了。
而将文件数设为3时,则会出现如图34所示的流程,可见受其特征码位置的影响,定位出来的精度为1/3的文件长度,而后即便使用了粗略的复合定位法,特征码的长度仍然是整个文件的1/6。可以发现,文件数设为3时生成的文件个数虽然只比设为2时多了1个,但是在这种特殊情况下,特征码的精度却提高了3倍!那么如果将生成样本数设为6个呢?经过计算,特征码的精度与分为3个相比,其精度提高了2倍。
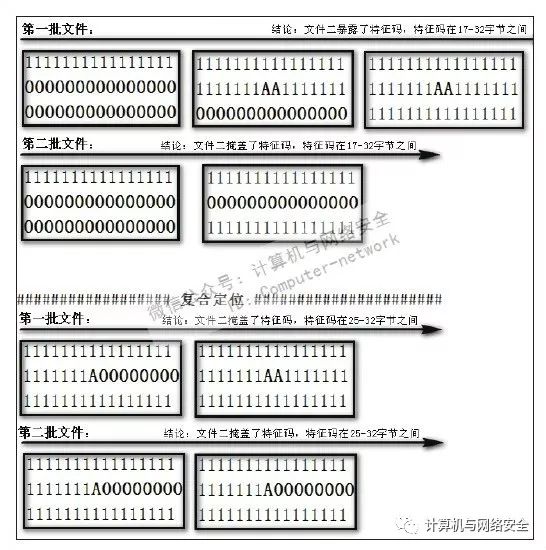
图34 分块个数设为3
因此,分块个数对特征码的定位是有很大影响的,但是如何才能让MyCCL按照黑客所期望的方式工作呢?这似乎并没有难倒他们。
通过上面的例子不难发现,初次所设置的样本文件生成个数越多,定位出来的结果自然也就越精确,而且生成样本的个数与特征码的精度是成正比的。但是随着生成样本数的增多,它对特征码精度的影响就会逐渐减小,所以在必要的时候选择一个比较适中的生成个数才是明智之举。
通过上面的讲解,也许您已经明白了生成个数对特征码定位成功率的影响,但是也许还会有人问:这仅仅是一个比较特殊的例子而已,恐怕在实际操作中很难碰到这类情况吧?请您注意,上面用的是基于特征码扫描的普通反病毒引擎做的实验,如果在基于卡巴斯基的密码校验和扫描方式下做这个实验的话,鉴于密码校验和的特征码体积之大,原理之特殊,碰到这种情况的概率就会成倍增长。
除此之外,MyCCL的“填充”项也是不容忽视的,虽然大多数用默认的“00”即可,但是现在已经有反病毒软件可以识别这种填充方式了,遇到特征偏移量位置全部被“00”填充的情况时,反病毒软件就会自动释放出伪特征码,导致黑客在定位最后一处特征码时受阻,从而会使整个免杀工作以失败告终。
所以黑客早已不再用简单的0x00来覆盖特征码了,如果我们在实验中碰到了类似情况,完全可以将填充字符改为其他字符,例如0x11、0x22、0xAA等。
而且从概率方面来讲,一个文件存在的空区段或空白处往往占整个文件体积的10%左右,也就是说“00”字节在文件中出现的概率大约为10%,而其他十六进制的那15个字符出现的概率仅为6.6%。那么特征码必然也会受影响,也就是说出现特征码数据为“00”的概率是比较大的,如果此时再用填“00”的方式来定位这种特征码,那是无论如何也定位不出来的!
一个简简单单的MyCCL的填充个数就引发出了这么多的问题,如果您在以后的学习中勤于思考,一定会想出应对特征码定位的就方法。
五、MyCCL查找内存特征码
如果想定位内存特征码,则需要注意两个问题,一个是断网,另一个就是一定要先做好文件的免杀,这样才能精确地找到所需要的内存特征码,否则定位结果将会非常不可信。
现在我们已经有了一个做好文件免杀的木马服务端Server.exe,用MyCCL打开后单击“内存复合特征码定位前勾选此处,否则勿选!”复选框,如图35所示。

图35 勾选复选框
然后单击“<生成>”按钮生成样本文件,最后用鼠标右键单击“目录路径”处,调出“用TK.Loader打开目录”菜单并单击即可,如图36所示。
图36 调出“用TK.Loader打开目录”菜单
随后便进入如图37所示的“内存辅助定位器TK.Loader”界面,单击“全部载入”按钮后即可进行内存查毒了。
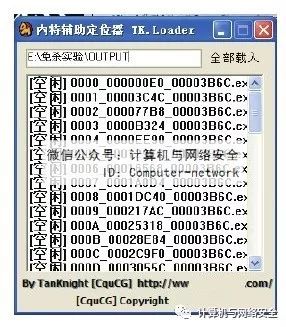
图37 “内存辅助定位器TK.Loader”界面
杀完毒之后,剩下的操作就与进行文件免杀一样了。内存定位的唯一不同之处就在于需要用TK.Loader将样本加载到内存中,再就是反病毒软件在查杀病毒时要选择内存扫描。需要注意的是,有时反病毒软件并不能顺利地删除所有的木马文件,如果出现这种情况,到目录里手工删除即可,不过在执行手工删除前,要先退出TK.Loader。
六、特征码修改方法
通过前面的学习,相信您对黑客是怎样查找特征码的已经比较了解了,但是单单查找出特征码并不能达到其想要免杀目的,如果想让文件免杀,又使文件正常运行,就要用到特征码修改技巧了。
在进行特征码修改实验时,并不需要拿个真正的木马来做,完全可以随便挑选一个体积比较小的软件来实验。下面就由浅入深地给您讲解特征码的修改方法。
1、简单的特征码修改
先说明一下,这里所讲的方法只适用于文件特征码。既然是简单的特征码修改,那么就从简单的大小写替换方法开始讲起,大家理解起来会比较容易。
(1)大小写替换修改
所谓的大小写替换方法就是将原有的大写或小写字母更改为相反的状态,例如特征码为code,那么不管是将其改为CODE还是Code或是coDe,都可以达到免杀的目的。
这种方法适用于所有特征区域出现字符的状况,如图38中所选定的区域就是一处特征码,我们可以发现这处特征码的每个字符之间都有个“.”,也就是“00”隔开,因此可以推断这属于Unicode类型。不过字符串的类型并不影响我们更改特征码,之所以介绍一下相关知识是为了让您掌握更多的基础知识。

图38 查找到的特征码
由图37可知,特征码其实就是"Explor"这段字符,因此只需要对其进行简单的大小写替换就可以了。
但是为什么在将字母大小写更改之后就会使反病毒软件“失效”呢?这实际上是基于Windows系统与反病毒软件的一个不同特性的,Windows系统在很多情况下对大小写并不敏感,但是反病毒软件则不同,它们大多数是根据字符的编码来判定病毒特征的,而大写字母与小写字母的编码是不同的,因此修改后的程序虽然对于反病毒软件来说已经完全变了,但在Windows系统下仍然可以正常运行。
那是不是碰到字母就采用大小写替换方法即可放心使用呢?事实上并非如此,个别的情况下还是不能使用的(例如系统的API函数)。
(2)用"00"字节填充
前面在讲解特征码查找原理时说过,在汇编里“00”表示空的意思,如果将某一个代码在十六进制下用“00”替换的话,那么就相当于删除了这段代码,所以在程序运行时就会存在出现一些问题的概率,如果想要尽量避免出现这些问题,那么就应该尽量少地使用“00”来填充,或者在操作时灵活运用。例如如果用这个字节填充失败,就应该换一个字节试试,如果所有的字节都不行,那么就在定位特征码时将精度调低一些,这样选择的余地就会更大。
(3)加1减1法
加1减1法所利用的就是十六进制值相近的部分汇编指令,其所代表的意思往往也大体相同,例如十六进制的0x74、0x75分别代表汇编指令中的JE与JNE,虽然它们所代表的含义相反,但都是具有跳转功能的指令。
知晓这些方法有利于我们在以后的反病毒工作中更加从容地处理一些看似不不合理的事件。
2、特征码修改进阶
以反汇编的方式修改特征码时,首先将得出的十六进制偏移量地址改为内存偏移地址,听起来似乎很模糊,其实操作起来却非常简单。
使用OC偏移量转换器即可将偏移地址转换为内存地址,转换后便得出了如图39所示的结果。其中,0x0100FAEE即为转换之后的内存地址。
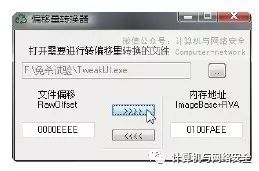
图39 将偏移地址转换为内存地址(虚拟偏移地址)
(1)空白区域跳转法
这种方法应该是修改特征码工作中最常用的一种方法了。当然,也应该是最好用的一种方法。但是对于入门不久的您来讲,也许在操作时会遇到一些小麻烦,这里所说的“小麻烦”指的是这种方法操作起来比较麻烦,由于刚入门的您可能之前没怎么使用过这类工具,所以很可能在操作时会粗心大意,造成修改失败。
假设我们找到一处特征码"0000EEEE_00000004",用OC转换之后得到内存地址"0x0100FAEE",现在用Ollydbg打开实验文件,如图40所示。
图40 Ollydbg主界面
1)按快捷键Ctrl+G调出“跟随表达式”对话框,并输入转换出来的内存地址"0x0100FAEE",然后用鼠标单击地址"0x0100FAEE"处的汇编指令,按快捷键Ctrl+C复制,并保存在记事本中,如图41所示。
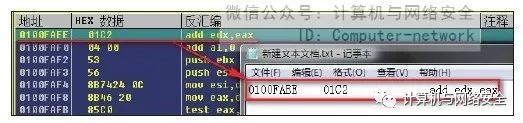
图41 保存一段汇编指令
2)找到如图42所示的一处空白区域,并记住其中的任意一个地址,这里选择的是"0x0101865E"这个地址。
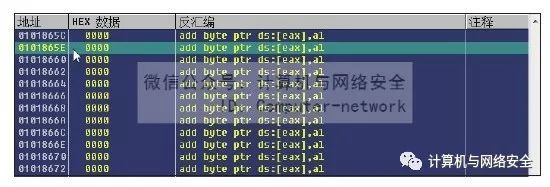
图42 找到空白区域
3)返回"0x0100FAEE"处,右键单击这句指令,在弹出的对话框中依次选择“二进制”→“用NOP填充”,如图43所示。然后再以同样的方式将地址"0x0100FAF0"与"0x0100FAF2"的内容也用NOP填充(在操作之前将位于这两个地址后面的汇编指令保存在记事本里)。
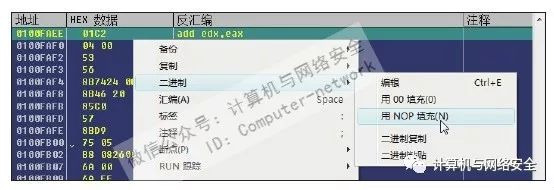
图43 用Nop填充
4)选中刚刚NOP的语句,在"0x0100FAEE"行单击右键,在弹出的如图44所示的菜单中选择“汇编”,然后写入指令jmp 0x 0101865E,无条件跳转到刚才找到的那个空白地址处。
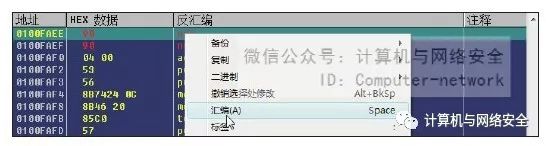
图44 汇编此处
5)记下"0x0100FAEE"下面的地址"0x0100FAF3",再到"0x0101865E"这个刚才找到的空白地址处右键单击,并在弹出的菜单中选择“汇编”,同时写入前面记录在记事本的3条指令,如图45所示。我想大家应该发现了,图45中的不就是刚才NOP掉的那个语句吗(参见图43)?正是如此,但是我们为什么要这样做呢?这个问题先放一放,将这次修改完成之后再说。
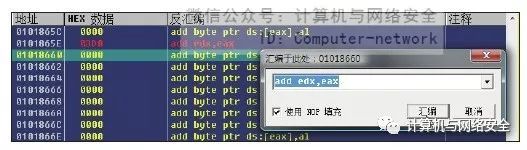
图45 汇编此处
6)将"0x0101865E"下面那条空指令汇编为jmp 0100FAF3。最后在这个窗口的任意区域单击右键,依次选择“复制到可执行文件”→“所有修改”,如图46所示。在弹出的对话框中单击“全部复制”按钮,然后在新界面中单击右键,并选择“保存文件”即可。
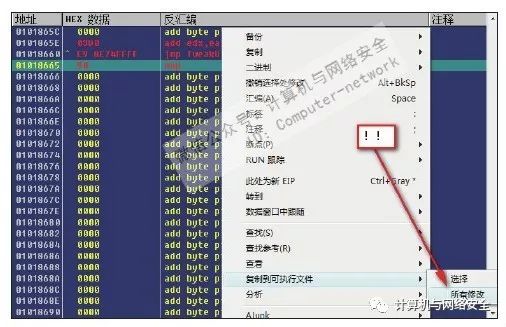
图46 复制到可执行文件
到这里已经修改完毕了,为了使您能更加清晰地了解这种修改方法,下面介绍一下关于“空白区域跳转法”的一点补充知识。
看了上面的操作,不知道您是否会有这样的疑问:这样跳来跳去的究竟是要达到什么目的呢?其实这是利用杀毒软件特征码查杀的弊端所创建的一种修改方法。我们知道,特征码的定位是有一个偏移量地址的,而这样更改之后在原来那个偏移地址里的内容就变成了跳转指令,原来的指令则被移动到了另外一个位置,所以杀毒软件自然也就不报毒了。而且由于那两个跳转的存在,所以整个程序仍然是连贯的,整体修改思路如图47所示。对此还不太明白的朋友可以根据这幅插图进一步理解一下。
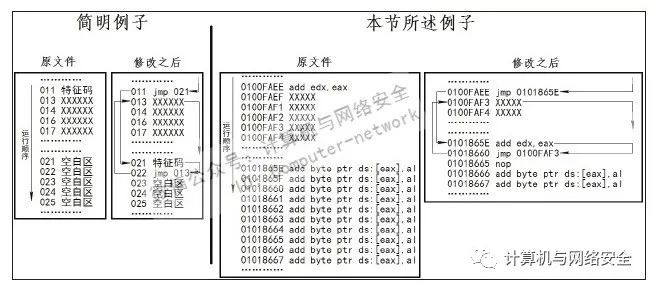
图47 “空白区域跳转法”的修改逻辑
另外还有一种叫做“nop位移法”的修改方式,使用它要有一个比较苛刻的条件,就是特征码附近(不超过10行)必须要有0x00区域。如果符合条件,操作方法就是将整段代码位移到下面,具体位移几行全凭0x00区域的大小限制与个人爱好。由于前面空出来的都用NOP填充,因此称为“nop位移法”。
(2)上下互换
其实上下互换与上面介绍的方法操作步骤基本上是一样的。我们仍然以特征码"0000EEEE_00000004"为例讲解。通过前面实验,我们已经知道将其转换为内存地址后为"0x0100FAEE",用Ollydbg打开实验文件,然后按快捷键Ctrl+G调出“跟随表达式”对话框,并进入地址"0x0100FAEE",选择将要互相替换的两端指令。然后按快捷键Ctrl+C复制,并将其保存在记事本中。回到Ollydbg后在那两段代码上面单击右键,在弹出的菜单中依次选择“二进制”→“用00填充”,如图48所示。
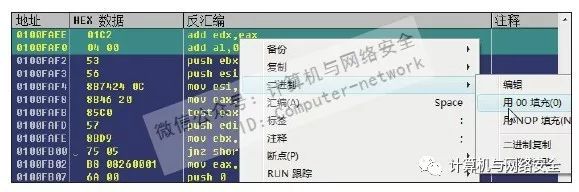
图48 用NOP填充
接下来将刚刚记录在记事本里的指令上下调换一下,并按上面讲的方式依次汇编回去,如图49所示。

图49 将上下互换后的指令汇编回去
最后按照上面的步骤(右击→“复制到可执行文件”→“所有修改”→“全部复制”→“保存文件”)将其保存。
这种方法利用的就是汇编对指令上下调换不是很敏感的这一特点来达到免杀目的的,因为上下调换指令之后,虽然大部分程序仍然能正常运行,但是作为特征码的十六进制信息已经互相调换了,那么依靠特征码查杀病毒的反病毒软件也就无能为力了。
(3)等值替换法
等值替换属于涉及知识层次比较深的一种修改特征码的方法,它的原理就是利用汇编语言中相近或有可能达到同一结果的指令,来替换原来被定义为特征码的指令。
很显然,这会涉及很多汇编语言方面的知识,但是您很可能可能并没有掌握多少汇编知识,所以这里只给出几个比较常用的例子,更深层的利用要等您自身的汇编功底提高以后,自然而然就会总结出更多的方法了。以我个人的经验来说,比较适合初学者的等值替换法主要用到以下几个指令:

上面3条指令的应用方法非常简单,就是一个替换的问题。我们重点讲解一下“Add与sub互换”。Add与sub在汇编里分别是加与减的意思,例如add xxx,5就是将"xxx"加上5的意思,很显然,sub xxx,-5则是将"xxx"减去-5的意思。但是我们仔细地想一想,加5与减去-5在结果上有何不同呢?很显然它们取得的结果是一样的啊!既然取得的结果一样,自然也就不会对程序的运行产生影响了,因此就可以利用这个原理来将这两个指令调换着使用。但是需要注意的是,这里加减运算所应用的都是十六进制数据。
而其他的指令互换仅仅考虑到了指令长度问题,并不是严格意义上的等价互换。
微信公众号:计算机与网络安全
ID:Computer-network




