![]() 作者 | 刘博、董秋雷、胡占义
本文对中科院自动化所胡占义团队完成,被AAAI-20录用的论文《Zero-Shot Learning from Adversarial FeatureResidual to Compact Visual Feature》进行解读。
作者 | 刘博、董秋雷、胡占义
本文对中科院自动化所胡占义团队完成,被AAAI-20录用的论文《Zero-Shot Learning from Adversarial FeatureResidual to Compact Visual Feature》进行解读。
![]()
近年来,零样本学习受到了计算机视觉领域的广泛关注。
目前的零样本学习致力于在一个嵌入空间中学习一种具有可判别性的特征,然而对于未见类别而言,这些特征往往会互相重叠,从而导致识别准确率不高。
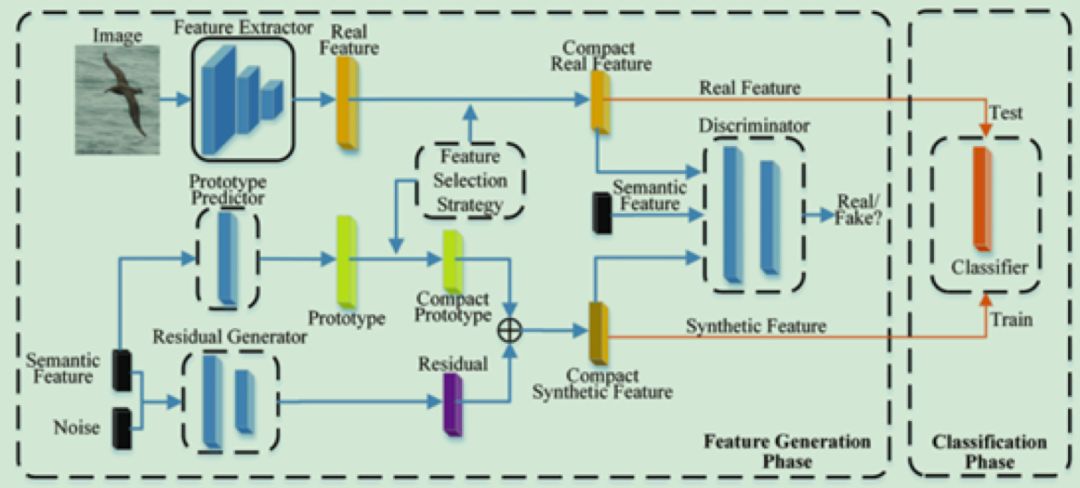
针对这个问题,本文提出了一种新的条件生成对抗网络来学习具有更强判别能力的特征。该网络包括一个用于生成视觉特征残差的条件生成器,一个用于预测视觉原型的预测器,一个视觉特征判别器,以及一个提取图像特征的特征提取器。条件生成器以语义特征为条件来生成视觉特征残差,原型预测器以语义特征为输入来预测视觉原型,将视觉残差和视觉原型结合,就可以合成一个视觉特征。
将合成的视觉特征与特征提取器提取的真实视觉特征输入特征判别器进行对抗训练,最终得到一个可以生成视觉特征残差的条件生成器。由于视觉特征残差在数值上一般小于不同类别视觉原型之间的距离,因此使用视觉特征残差和视觉原型合成的视觉特征可望获得更强的判别能力。
另外,为了减小视觉特征和语义特征之间的语义不一致性,本文提出了一种基于预测损失的视觉特征选择方法,它从原有的视觉特征中选择一些与语义特征更加一致的特征维度,构成一个更加紧凑的视觉特征。
本文方法在六个国际公共数据集上进行了测试,对比实验结果表明,本文方法相比于若干主流方法在计算精度方面得到了较大幅度的提升。
零样本学习近年来受到了广泛的关注,大部分文献的工作可以被分为两类:其中一类是基于视觉特征到语义特征的映射,另一类是基于语义特征到视觉特征的映射。
基于视觉特征到语义特征的映射的方法【1】首先使用一般的CNN提取视觉特征,然后通过一个全连接层将视觉特征投射到语义空间,最后在语义空间中利用最近邻分类器进行物体分类。
一些工作对该方法进行了进一步的改进,比如改进损失函数【2】,采用非线性的映射函数【3】等。语义特征到视觉特征的映射的方法可以被分为两个子类,其中一个是基于确定性的映射函数。该方法【4】直接将语义特征映射到视觉特征,然后在视觉空间中利用最近邻分类器分类。另一种是基于条件生成网络,该方法【5】利用条件生成对抗网络以语义特征为条件来生成大量的视觉特征,一旦生成了未见类别的视觉特征,零样本学习问题就被转换为了一般的分类问题。
由于基于CNN的视觉特征在特征空间中具有良好的聚类性质,使用视觉原型去表示某一类物体的大致的视觉特征是可行的。Changpingo等提出了一种通过在语义特征和视觉原型之间建立一个回归函数来预测其他类别的视觉原型的方法。
本文提出了一种新的条件生成对抗网络来解决零样本学习问题,如图1所示,它包含了一个用于生成视觉特征残差的条件生成器,一个用于预测视觉原型的预测器,一个视觉特征判别器,以及一个提取图像特征的特征提取器。
在特征生成阶段,条件生成器以语义特征为条件来生成视觉特征残差,原型预测器以语义特征为输入来预测视觉原型,将视觉残差和视觉原型结合,就可以合成视觉特征。将合成的视觉特征与特征提取器提取的真实视觉特征输入特征判别器进行对抗训练,最终得到一个可以生成视觉特征残差的条件生成器。
在分类阶段,利用生成的未知类别的视觉特征以及相应的标签,我们可以训练一个未知类别的分类器,该分类器可以用于识别真实的未知类别的视觉特征。下面详细介绍一下视觉原型预测器和视觉特征残差生成器。
![]()
视觉原型预测器的任务是利用某一类别的语义特征来预测该类别的视觉特征原型。一般而言,我们用同一个类别的视觉特征的均值来表示该类的视觉原型特征。这样,对一个包含C个类别数据集,我们就可以得到C对语义特征和视觉原型特征。
利用这C对语义特征和视觉原型特征,我们就可以学习一个从语义特征到视觉原型特征的预测函数。当这个预测函数训练好以后,给定一个新类别的语义特征,我们就可以预测该类别的视觉原型特征。
一般情况下,视觉特征是一个高维的特征向量。在本文的方法中,针对视觉特征的每一个维度,我们都会学习一个预测器。该预测器采用SVR模型,以语义特征为输入,输出一维的视觉特征。
实际上,语义特征和视觉特征存在语义不一致性问题,这将导致由语义特征预测的视觉原型特征与真实的视觉原型特征具有一定的偏差。针对这一问题,我们提出了一种基于预测损失的特征选择方法。该方法对每一个视觉特征维度的预测损失进行排序,选择前K个预测损失最小的视觉特征维度,并以这K个视觉特征维度代替原来的视觉特征。通过视觉特征选择,我们得到了一种与语义特征更加一致的更加紧凑的视觉特征。
视觉特征残差生成器的任务是以某一类别的语义特征为条件生成大量的视觉特征残差,通过结合这些视觉特征残差和其相应的视觉原型,我们可以合成视觉特征。将合成的视觉特征和用特征提取器提取的真实的视觉特征输入特征判别器进行对抗训练,我们就可以得到一个可以生成视觉特征残差的条件生成器。
现有的基于条件生成对抗网络的零样本学习方法一般都是利用对抗训练的方法训练一个条件生成器,该条件生成器以语义特征为条件直接生成视觉特征本身。在本文的方法中,我们同样利用对抗训练的方法训练一个条件生成器,不过该条件生成器生成的是视觉特征残差,然后通过将视觉特征残差和视觉原型结合合成视觉特征。
将视觉特征原型预测和视觉特征残差生成结合,我们可以合成一种具有更好的可判别性以及具有更好的语义一致性的视觉特征。更好的可判别性主要来自于视觉特征残差在数值上一般小于不同视觉原型之间的距离。更好的语义一致性主要来自于基于原型预测损失的视觉特征选择方法。
当视觉特征残差生成器训练好以后,给定某一未见新类别的语义特征,我们就可以合成该类别的视觉特征。这样,零样本学习问题就被转变为了一般的分类问题。
本文方法在现有的公开数据集上进行了广泛地测试,其中包括
4个粗粒度的数据集
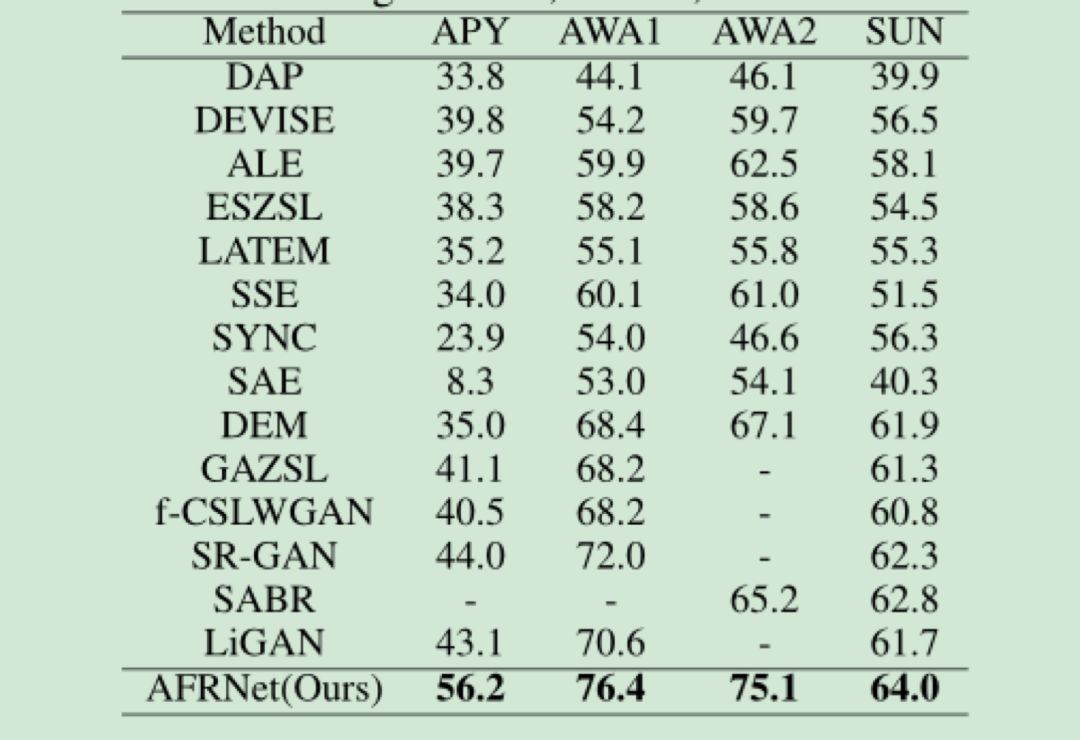
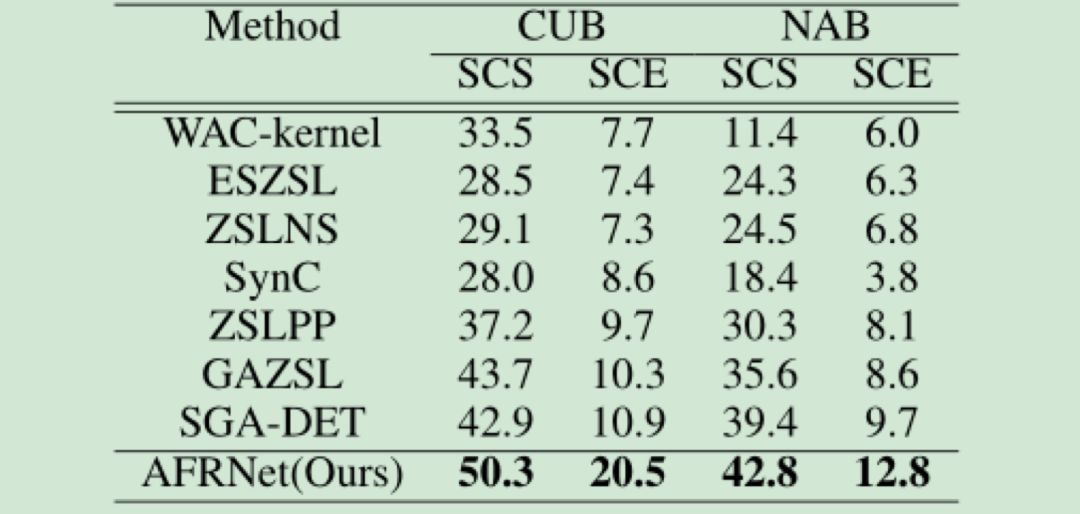
(APY,AWA1,AWA2,SUN)和2个细粒度的数据集(CUB,NAB)。在4个粗粒度的数据集上,我们采用了1种数据划分方法对已见类别与未见类别进行划分。在2个粗粒度的数据集上,我们采用了2种难度不同的数据划分方法划分已见类别和未见类别。在零样本学习中,实验结果评价方法一般采用未见类别上的准确率。本文方法的实验结果与当前的最好的结果进行了比较,结果如表1-2所示。
![]()
表1 列出了本文的方法与当前主流方法在4个粗粒度的数据集上的实验结果。从表1可以看出,本文的方法在每个数据集上都取得了最好的结果。在APY,AW1和AWA2数据集上,本文方法的识别准确率取得了较大的提升。在SUN数据集上,本文方法的识别准确率提升相对较小,这可能是因为SUN这个数据集的类别数目较多,每个类别的训练图像个数较少,不利于视觉原型的准确计算,从而导致了准确率的下降。
![]()
表2 列出了本文的方法与当前主流方法在2个细粒度的数据集上的实验结果。表2的实验结果表明,本文的方法不仅在粗粒度的零样本学习上具有较好的表现,在细粒度的零样本学习上的表现同样取得了较大的提升。对于两种不同难度的数据划分方法,本文的方法也都提升了识别的准确率。在较难的SCE数据划分方式中,本文方法的实验结果提升的更加明显。这表明本文的方法在不同难度的零样本学习问题中都具有良好的表现。
为了进一步分析本文提出的方法是否具有效果,我们进行了两个对比实验。在第一个对比实验中,我们在2个细粒度的数据集上对比了基于残差的对抗视觉特征生成方法与直接的对抗视觉特征生成方法的结果。结果如表3所示:
![]()
在表3中,AFRNet表示采用了基于残差的对抗视觉特征生成方法,AFRNet-non表示采用的是直接的对抗视觉特征生成方法。通过表3我们可以看出,基于残差的对抗视觉特征生成方法可以明显改进零样本学习的性能。
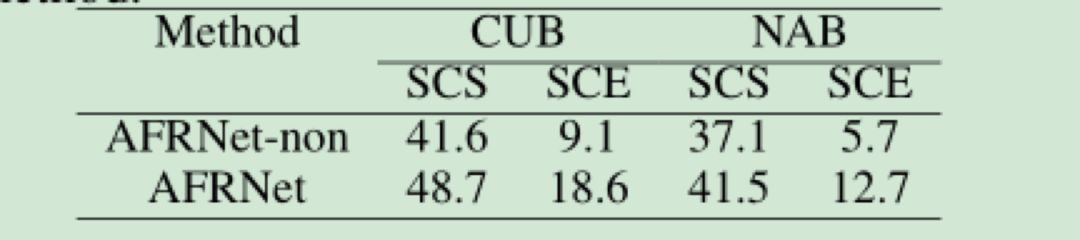
在第二个对比实验中,我们在2个细粒度的数据集上分析了基于预测损失的特征选择方法的作用。实验结果如表4所示:
![]()
在表4中,w/o表示没有采用基于预测损失的特征选择方法, w表示采用了基于预测损失的特征选择方法。表4的结果表明,通过选择预测损失较小的视觉特征维度代替整体的视觉特征,可以有效地增加视觉特征与语义特征之间的一致性。
【1】Frome,A.; Corrado, G. S.; Shlens, J.; Bengio, S.; Dean, J.; Mikolov, T.; et al. 2013.Devise: A deep visual-semantic embedding model. In NIPS, 2121–2129.
【2】Akata,Z.; Reed, S.; Walter, D.; Lee, H.; and Schiele, B. 2015. Evaluation of outputembeddings for fine-grained image classification. In CVPR, 2927–2936.
【3】Socher,R.; Ganjoo, M.; Manning, C. D.; and Ng, A. 2013. Zero-shot learning throughcross-modal transfer. In NIPS,935–943.
【4】Zhang,L.; Xiang, T.; and Gong, S. 2017. Learning a deep embedding model for zero-shotlearning. In CVPR, 2021–2030.
【
5】
Xian,Y.; Lorenz, T.; Schiele, B.; and Akata, Z. 2018b. Feature generating networksfor zero-shot learning. In CVPR,5542–5551.
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。
![]()
AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
18. [奥卢大学] 基于 NAS 的 GCN 网络设计(视频解读)
19. [中科大] 智能教育系统中的神经认知诊断,从数据中学习交互函数
20. [北京大学] 图卷积中的多阶段自监督学习算法
21. [清华大学] 全新模型,对话生成更流畅、更具个性化(视频解读,附PPT)
22. [华南理工] 面向文本识别的去耦注意力网络
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页
 作者 | 刘博、董秋雷、胡占义
作者 | 刘博、董秋雷、胡占义