业界 | 智能体只想看电视?谷歌新型好奇心方法让智能体离开电视继续探索
选自Google AI Blog
作者:Nikolay Savinov、Timothy Lillicra
机器之心编辑
参与:路、张倩、王淑婷
近日,来自谷歌大脑、DeepMind 和苏黎世联邦理工学院的研究人员提出一种新型好奇心强化学习方法,利用情景记忆(episodic memory)形成对新颖性的奖励。具体方法是基于当前观测结果与记忆中的观测结果的环境步距离来对比二者的差异,确定当前观测结果是否新颖,进而确定是否提供额外奖励,从而解决了大部分强化学习算法的稀疏奖励问题。
强化学习(RL)是机器学习领域最活跃的研究方向之一。在强化学习中,如果人工智能体执行合适的行为,它将获得正面奖励,否则将获得负面奖励(惩罚)。这种奖惩制度非常简单、通用,它帮助 DeepMind 教 DQN 算法玩 Atari 游戏,还被用于教 AlphaGoZero 学下围棋的过程中。OpenAI 教 OpenAI-Five 算法玩 Dota、谷歌教机械臂抓取新物品的原理也是如此。然而,尽管强化学习取得了很多成就,但要成为一项有效的技术还面临着一系列挑战。
伯克利 RL 算法在环境中遇到了挑战,因为智能体得到的反馈非常稀疏——更致命的是,这种环境在现实世界中非常常见。例如,想象一下你要如何在一家迷宫一样的大型超市里找到你最喜欢的奶酪。你找啊找,但就是找不到奶酪货架。如果每一步都得不到奖励或惩罚,那你就无法知道自己走的方向到底对不对。在得不到反馈的情况下,你要如何避免自己原地打转?没有办法,除非借用你的好奇心,它将驱使你走进一个陌生的商品区找你想要的奶酪。
在《Episodic Curiosity through Reachability》(谷歌大脑团队、DeepMind 和 ETH Zürich 的研究人员共同发表)一文中,研究者提出了一种基于情景记忆(episodic memory)的新型 RL 奖惩模式,类似于好奇心,这种模式有助于探索环境。研究者希望智能体不仅可以探索环境,还能解决原始任务,所以他们在原始稀疏任务奖励的基础上增加了由新模型提供的额外奖励。叠加奖励不再稀疏,可以让标准 RL 算法从中学习。因此,这一新型好奇心方法拓宽了 RL 的适用范围。
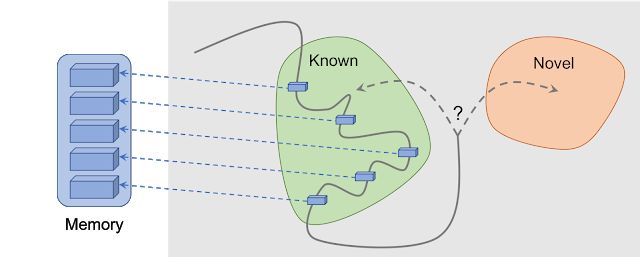
借助可达性(Reachability)的情景好奇心:将观测结果添加到记忆中,根据当前观测结果与记忆中最相似的情景之间的差距来计算奖励。当智能体当前看到的情景尚未出现在记忆中时,它会得到更多奖励。
该新方法的核心理念是将智能体对环境的观测结果存储在情景记忆中,在智能体发现记忆中不存在的情景时对其进行奖励。新方法将「不在记忆中」定义为「新」(novelty),寻找这种观测结果意味着寻找不熟悉的事物。这将把人工智能体带到新的地点,避免其在环境中转圈,并最终帮它找到目标。正如接下来将要讨论的,谷歌的方法可以避免一些其他方法容易出现的不良行为。出人意料的是,这些行为存在一些共性,也就是外行所说的「延误」(procrastination)。
之前的好奇心方法
过去有很多工作尝试使用好奇心方法 [1][2][3][4],本文着重介绍在近期论文《Curiosity-driven Exploration by Self-supervised Prediction》(通常被称之为 ICM 方法)中发现的一种非常流行的自然方法:基于预测惊讶的好奇心。要说明惊讶如何引起好奇心,我们还要用到超市里寻找奶酪的例子。
by Indira Pasko(图源:https://www.behance.net/gallery/71741137/Illustration-for-an-article-in-aigoogleblogcom)
你在超市中漫步时会尝试预测(「现在我在肉类区,拐过这个弯应该是鱼类区,这家超市里这两类区域往往是挨着的)。如果你的预测错误,则你会感到惊讶(「天啊,竟然是蔬菜区。真是没想到!)并因此得到奖励。这会使你未来更有动力四处晃悠,探索新的区域,只为看看自己的期望与现实是否相符(希望能够偶遇奶酪)。
类似地,ICM 方法对这个世界的动态构建了一个预测模型,并在模型预测错误时(标志是惊讶或新颖性)给予智能体奖励。注意:探索没见过的区域不属于 ICM 好奇心。对于 ICM 方法,访问这些区域仅仅是获取「惊讶」的方式,从而最大化整体奖励。事实证明,在某些环境中会出现其他带来惊讶的方式,导致未曾预料的结果。

具备基于惊讶的好奇心的智能体在遇到电视时就被绊住了。(图源:https://www.youtube.com/watch?v=C3yKgCzvE_E&feature=youtu.be)
「延误」的风险
在论文《Large-Scale Study of Curiosity-Driven Learning》中,ICM 方法的作者和 OpenAI 的研究人员一起展示了「惊讶」最大化的隐藏风险:智能体能够学习放任类似延误的行为,而不是为手边的任务做些什么。为了查看原因,考虑一下作者称之为「noisy TV problem」的常见实验,实验中智能体被放入迷宫,任务是找到奖励最高的物体(类似于前面超市例子中的「奶酪」。环境中还有一台电视,智能体可以用遥控器换台。电视上的频道有限(每个频道的节目不同),遥控器上的每个按键可转换到随机频道。智能体在这样的环境中会有什么行为呢?
对于基于惊讶的好奇心(surprise-based curiosity),换频道将带来大的奖励,因为每次换台的结果是不可预测、令人惊讶的。关键是,即使在所有频道换过一遍之后,随机频道选择也能确保之后的每次换台结果出人意料,智能体会对换台后的频道做出预测,预测很可能是错误的,并带来惊讶。重要的是,即使智能体已经看过每个频道的节目,换台结果仍然是不可预测的。因此,灌输了基于惊讶的好奇心的智能体将一直待在电视前面,而不是去寻找高奖励的物体,这种行为类似于延误。那么,不会导致此类延误行为的好奇心应该如何定义呢?
情景好奇心(Episodic Curiosity)
谷歌在论文《Episodic Curiosity through Reachability》中探索了基于情景记忆的好奇心模型,该模型较少「沉迷于」即时满足。为什么?还以上面的实验为例,所有频道都换过后,所有的电视节目都将存储在记忆里。因此,电视对智能体而言不再具备吸引力:即使电视节目出现顺序是随机且不可预测的,但所有节目都存在记忆里了!这是它与基于惊讶的好奇心的主要区别:谷歌的方法甚至不去尝试预测难以(甚至不可能)预测的未来。而是检查过去的记忆,了解它是否见过与当前场景类似的观测结果。因此谷歌的智能体不会被开着的电视机带来的即时满足感吸引走太多的注意力。它会探索电视机以外的环境,以得到更多奖励。
但是如何确定智能体看到的场景已经存在于记忆中呢?精确匹配是无意义的:在现实环境中,智能体很少两次看到同样的事物。例如,即使智能体返回同样的房间,它仍然会以不同于已有记忆的角度来看待这个房间。
因此谷歌研究人员不检查当前场景与记忆中的场景是否完全匹配,而是使用一个深度神经网络来衡量两种体验的相似度。为了训练该网络,研究人员让它猜测两种观测结果的体验时间是否接近。时间接近(temporal proximity)是判断两种体验是否属于同样经验的有效手段。这种训练导致了一种基于可及性(reachability)的新颖性(novelty)的通用概念,如下图所示。
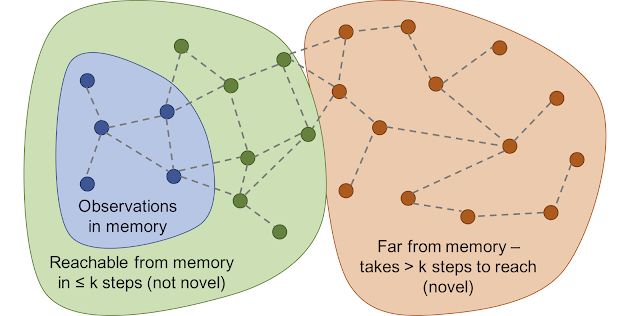
可及性图将决定新颖度。事实上,这个图是很难达到的,所以训练神经网络逼近器来估计观察之间的步数。
实验结果
为了比较好奇心模型不同方法的性能,谷歌在两个视觉丰富的 3D 环境 ViZDoom 和 DMLab 中测试了它们。在那些环境里,智能体有很多不同的任务,比如在迷宫中寻找目标或者收集好的并避免坏的东西。DMLab 给智能体提供的是类似激光的科幻小工具。在之前的研究中,DMLab 的标准设置是在所有任务中为智能体装备这个工具,如果在某个特定任务中智能体不需要这个工具,它也可以不用。有趣的是,与之前描述的嘈杂 TV 实验类似,基于好奇心模型的 ICM 方法实际上在大多数任务中都使用了这个工具,即使它对手头的任务没有帮助!当任务是在迷宫中寻找高回报物品时,智能体似乎更喜欢花时间标记墙壁,因为这样会产生很多「好奇心」奖励。理论上来说,预测标记结果是可能的,但实际上却很难,因为这样做需要更多的物理知识,而现有的标准智能体还达不到这个标准。

基于好奇心模型的 ICM 方法不断标记墙壁,而不是探索迷宫。
相反,谷歌的方法在同样的条件下学习合理的探索行为。因为它没有预测自己的行为结果,而是去观察,寻找那些已经在情景记忆中「难以」实现的观察。换句话说,智能体暗中追求记忆中需要更多努力才能实现的目标,而不是单单做一个标记动作。

谷歌的方法展示了合理的探索
有趣的是,谷歌授予奖励的方法惩罚了一个在转圈跑的智能体。这是因为在完成第一圈后,智能体没有进行新的观察(除了记忆中的那些),因此没有获得奖励。

奖励可视化:红色表示消极奖励,绿色表示积极奖励。从左到右依次是:标有奖励的地图,标有记忆中位置的地图,第一人称视角
同时,谷歌的方法支持良好的探索行为。
奖励可视化:红色表示负面奖励,绿色表示正面奖励。从左到右:标有奖励的地图,标有记忆中位置的地图,第一人称视角
谷歌希望本项研究能够帮助引出一波新的探索方法——不只是惊讶,还能学习更多的智能探索行为。若要深入分析谷歌的方法,请查看研究论文。
论文:Episodic Curiosity through Reachability

论文链接:https://arxiv.org/abs/1810.02274。
摘要:现实世界中的奖励是稀疏的,目前大部分强化学习算法受制于这种稀疏性。一种解决方案是允许智能体自己创建奖励,从而使得奖励更加密集、更适合学习。具体来说,受动物好奇行为的启发,即观察一些新颖的事物会得到奖励。这种奖励可以和真实任务的奖励叠加到一起,使强化学习算法从这一叠加奖励中学习。我们提出了一种新型好奇心方法,利用情景记忆(episodic memory)形成对新颖性的奖励。为了确定是否符合这一奖励,需要把当前观测结果与记忆中的观测结果进行对比。关键是,该对比基于二者之间的环境步距离,其包括环境动态的丰富信息。这帮助我们克服了之前研究中的「沙发土豆」(couch-potato)问题——智能体利用带来不可预测结果的动作寻求即时满足。我们在 VizDoom 和 DMLab 中的视觉 3D 环境中对新方法进行了测试。在 VizDoom 中,我们的智能体学会成功导航至远距离目标,且速度是当前最优的好奇心方法 ICM 的两倍。在 DMLab 中,我们的智能体可很好地泛化至游戏的新级别——到达目标。

参考文献:
[1] Count-Based Exploration with Neural Density Models, Georg Ostrovski, Marc G. Bellemare, Aaron van den Oord, Remi Munos
[2] #Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning, Haoran Tang, Rein Houthooft, Davis Foote, Adam Stooke, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel
[3] Unsupervised Learning of Goal Spaces for Intrinsically Motivated Goal Exploration, Alexandre Péré, Sébastien Forestier, Olivier Sigaud, Pierre-Yves Oudeyer
[4] VIME: Variational Information Maximizing Exploration, Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel
原文链接:http://ai.googleblog.com/2018/10/curiosity-and-procrastination-in.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



