MachineLearning下一站,云原生既未来
最近看了很多关于云原生的文章,大体意思是机器学习服务这个行业将迎来一次巨大的变革。从13年我刚入行以来,机器学习在15年左右经历了模型深度的变革,从浅层学习逐步发展到了深度学习。到了20年这个节点,机器学习的整体服务架构会开始变革,逐渐会从Apache Yarn体系向Docker+Kubeflow这种云原生体系变革。
为什么会出现这种迁移?许多技术同学都在网上发表了他们的看法,我认为比较好的文章是:https://www.jiqizhixin.com/articles/2019-01-31-14
遗憾的是,发表这些文章的都是技术同学,更多地是从技术视角去看待这个问题,今天我尝试通过产品经理的视角,也就是用户具体应用的视角解释下云原生的好处。
可能有的同学不清楚什么是云原生,Docker+Kubeflow就是机器学习的云原生方案。首先给大家解释下Docker和VM(虚拟机)的区别。
VM是目前所有“云”业务的根源,VM的诞生使得传统的物理机可以向外提供标准化的计算服务。这种服务需要使用者把应用App、依赖Bins/Libs以及操作系统Guest OS打包成VM镜像,然后发到物理机上即可运行。

VM的一个问题就是因为VM镜像包含了Guest OS,所以VM是比较重的,可能每个VM镜像在10G左右,如果想同时拉起上千个任务,这个拉起时间成本非常高。
再来看看Docker,Docker的一个好处是不包含Guest OS。用户只需要把应用App和Libs打包成一个Docker Image就可以部署到服务器上,而且一样具备VM所具有的资源隔离、网络隔离等优势,这就灵活了许多。看下Docker的架构图:
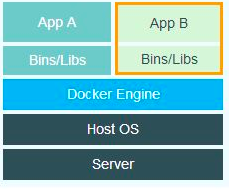
举个例子,比如做一个简单的模型服务,只需要把模型+Flask+python环境打包好即可,如果模型不大的话,这种Docker image只有几百兆,可以秒级拉起。所以云原生给到用户的是弹性的计算环境,只要用户把自己要计算的业务封装成Docker image,传上来就能跑。
云原生有资源调度更灵活,内存、网络隔离更完善等优点,这些都是技术优势,我今天重点介绍两个用户使用端的优势。分别是“更灵活的配置性”以及“业务模块的一致性”。
更灵活的配置性
传统的机器学习平台的架构是如下图这种模式:
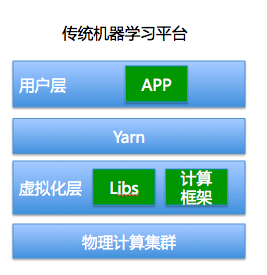
在用户层只给客户开放了APP的上传通道,而计算框架和依赖包需要平台层提前在集群配置好,而且不易更改。这会造成很大的麻烦,比如用户上传了一个python的代码包,这个包依赖于numpy这个python库,如果平台层没有内置numpy,用户是无法运行的,因为平台并没有给用户开放安装依赖包的口子。基于传统的Yarn调度的模式,在技术可行性方面也比较难实现用户自己在集群层面安装依赖。
反过来看云原生的平台,用户可以在用户层自己指定依赖的lib包,设置可以安装计算框架。从用户开发环境的角度比较,云原生的机器学习平台一定是更user friendly。
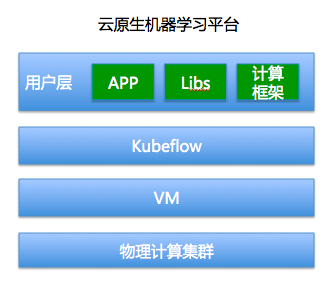
2.业务模块的一致性
我们知道,传统的Apache Yarn,设置整个Hadoop生态是基于大数据开发为业务背景去设计的。相比于机器学习建模,大数据开发场景相对会更单纯。因为大数据开发环境的输入和输出都是表。而机器学习场景输入的是数据,输出的是模型,模型还要部署成服务才可以使用。基于这样的体系,会产生以下这种机器学习架构,

大部分玩算法的人会把模型计算引擎和模型服务引擎解耦,甚至时间长了,觉得这两个部分就应该是不同的模块。基于这样很割裂的架构,会衍生出模型传递网络性能问题、引擎间模型格式不兼容等一系列问题。
有了云原生方式,会打破了Apache传统的以大数据方式建模的束缚。所有的建模相关的服务都可以做出Docker Image,部署到一个集群中,通过kubeflow的pipline去编排相互执行顺序。
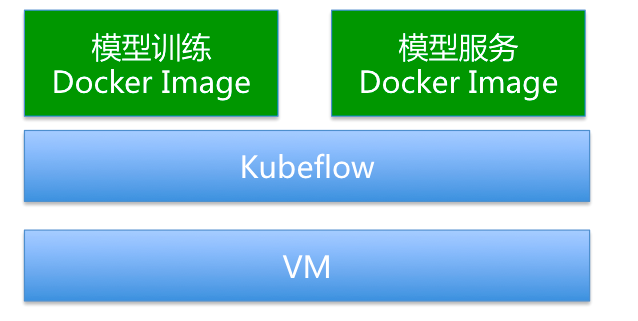
这样就解决了上述提到的问题,让整个业务都可以集中在一个集群,同时相互之间又有资源隔离机制,使得业务模块一致性更强。
经过这几天研究云原生机器学习业务的调研,我觉得kubeflow未来可期,需要所有从业的产品经理和开发人员重新更新自己的技术栈。
有一个问题需要时间验证,机器学习PaaS层产品是否是伪命题?
目前百度、阿里、腾讯都有PaaS层的机器学习产品,这些产品在云原生时代是否还有价值。因为云原生阶段会大大推动开源生态各种模型部署、算法框架的演进,用户完全可以利用这些开源的工具配合Docker在虚拟机上拉起来构建一个机器学习PaaS层服务,这样的话Yarn那一套有点落伍。
未来可能在机器学习领域,只存在SaaS业务层和IaaS计算资源层,PaaS的比重会下降。这是我的一个猜测,作为PaaS层机器学习产品经理,==!好担心自己会下岗。