新的State of the Art优化器RAdam , 就是这么好用!
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
导读
新的state of the art优化器:Rectified Adam(RAdam),相比adam,可以稳定提高准确率,关键是,真的有用。
Liu, Jian, He等人的一篇新论文介绍了RAdam,也叫作“Rectified Adam”。这是经典Adam优化器的一个新变种,在自动的、动态的调整自适应学习率的基础上,他们详细研究了训练期间的变化和动量的影响。与vanilla Adam相比,RAdam有希望即刻对每一个AI架构进行提升。
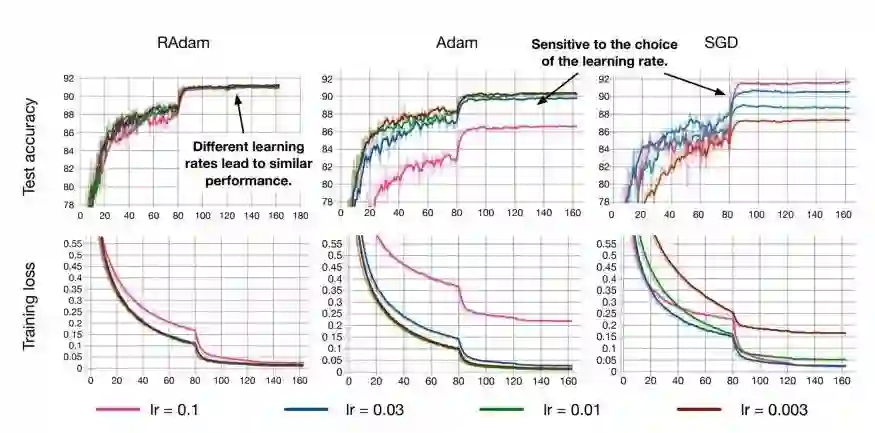
我已经在FastAI框架内测试了自己的RAdam,并很快获得了新的高精度记录,而在ImageNette上,只有两项难以击败FastAI排行榜得分。和我测试过的很多论文不一样,那些论文中的工作只适合他们特定的论文中使用的数据集,而并没有新数据集上做得很好,我试了一下RAdam,真的有提升。
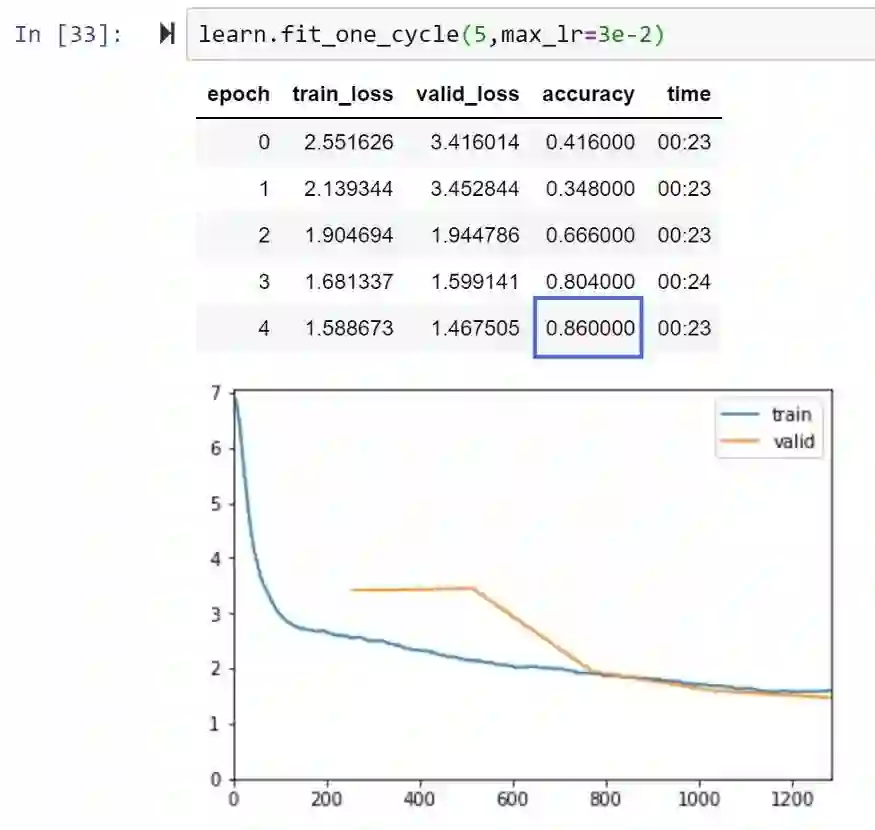

因此,我们需要深入研究下RAdam,了解它在内部做了什么,以及为什么它有希望为几乎所有AI应用提供了更好的收敛性、更好的训练稳定性(对选择的学习率不那么敏感)和更好的准确性和泛化能力。
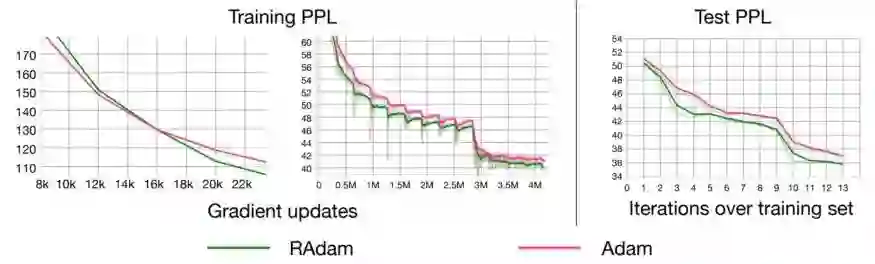
所有人工智能研究员的目标:一个快速和稳定的优化算法…
作者指出,尽管每个人都在朝着拥有快速稳定的优化算法的目标努力,但自适应学习率优化器(包括Adam、RMSProp等)都面临着陷入糟糕的局部优化(如果没有实现warmup方法的话)的风险。因此,几乎每个人都使用某种形式的warmup(FastAI在Fit_One_Cycle中内置了warmup功能)……但是为什么需要热身呢?
由于目前对人工智能社区中warmup启发式的潜在原因甚至最佳实践的理解有限,作者试图揭示这个问题的基础。他们发现,根本问题在于自适应学习率优化器的方差太大,特别是在训练的早期阶段,并且基于有限的训练数据进行过多的跳跃,从而会陷入较差的局部优化。
因此,当优化器只处理有限的训练数据时,warmup(初始训练阶段,学习速度要低得多)是自适应优化器抵消过多差异的必要条件。
下面是一个可视化的演示,展示了在没有warmup的情况下Adam最初的情况——在10次迭代中,梯度分布很快就被打乱了:
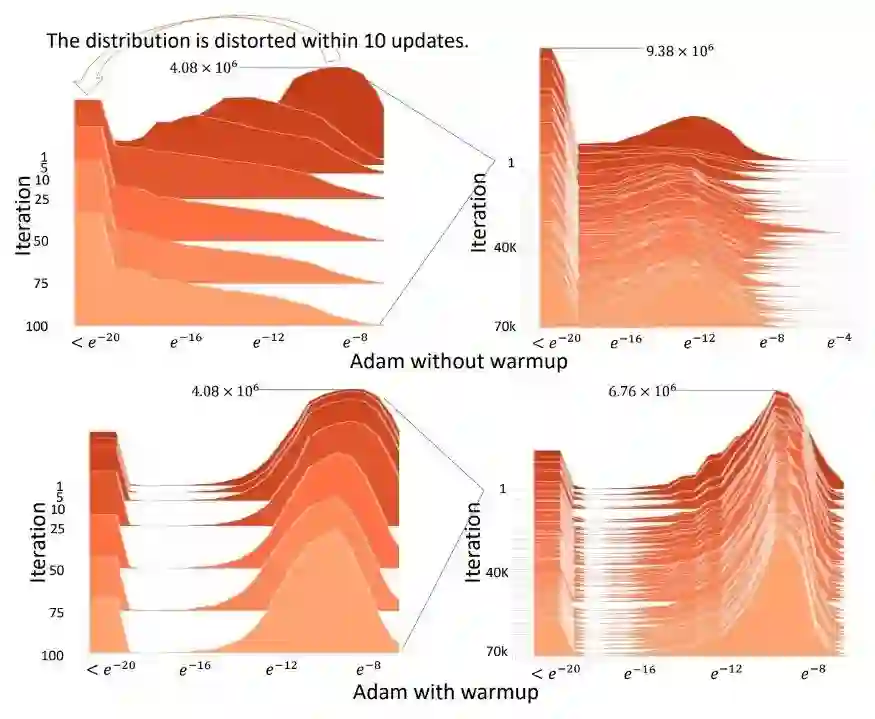
简而言之,vanilla Adam和其他自适应学习率优化器在早期的训练中,由于数据太少做出了错误的决策。因此,如果没有某种形式的warmup,他们很可能一开始就陷入糟糕的局部最优状态,因为糟糕的开始使得训练曲线更长、更困难。
然后,作者测试了在没有热身的情况下运行Adam,但是在前2000次迭代中避免使用任何动量(Adam-2k)。他们发现,取得了与Adam加热身类似的结果,从而验证了热身功能在最初的训练中是一种“减少方差”的功能,并避免了Adam在一开始没有足够的数据可用时陷入糟糕的优化状态。
RAdam中的“整流器”
考虑到热身是一种方差衰减器,但所需的热身程度是未知的,而且数据集之间是不同的,因此,作者决定用一种数学算法来作为一种动态方差衰减器。因此,他们构建了一个整流器项,这允许自适应动量作为一个潜在的方差的函数缓慢但稳定地得到充分表达。他们的完整模型是这样的:

RAdam at it’s core. The blue box highlights the final application of the rectifier r(t) to the step size.
作者指出,在某些情况下,由于衰减速率和潜在方差的驱动,RAdam可以退化为具有等效动量的SGD。
总结一下,RAdam根据方差的潜在散度动态地打开或关闭自适应学习率。实际上,它提供了不需要可调参数的动态warmup。
作者证实,RAdam的性能优于传统的手动warmup调优,需要猜测warmup步骤的数量:
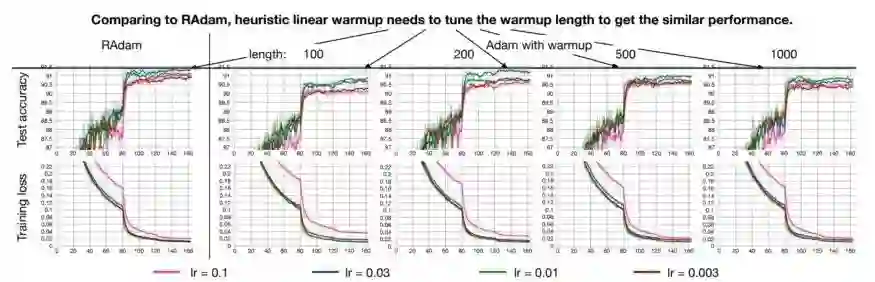
总结:RAdam可以说是AI最新state of the art优化器
正如你所看到的,RAdam提供了一个动态启发式方法来提供自动化的方差衰减,从而消除了在训练期间热身所涉及手动调优的需要。
此外,RAdam对学习速率变化(最重要的超参数)具有更强的鲁棒性,并在各种数据集和各种AI体系结构中提供更好的训练精度和泛化。
简而言之,我强烈建议您将RAdam放到你的AI架构中,看看你有没有立即获得好处。我愿意提供退款保证,但因为它的成本是0.00美元…
PyTorch的官方github提供了RAdam的实现:https://github.com/LiyuanLucasLiu/RAdam。
FastAI用户可以很容易地使用RAdam如下:

导入RAdam,声明为一个局部函数(根据需要添加参数)

通过前面声明的部分用RAdam覆盖默认的AdamW优化器。
更多的内容请阅读原始论文:https://arxiv.org/abs/1908.03265v1
英文原文:https://medium.com/@lessw/new-state-of-the-art-ai-optimizer-rectified-adam-radam-5d854730807b
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




