在看不见的地方,AI正在7×24为你在线服务

编者按:当你使用在线系统来搜索网页、编辑文档、存储图片、听音乐、看视频、玩游戏,并享受着行云流水般的顺畅服务时,正有几十万到上百万台服务器坚守在大后方,为你提供着7×24小时的可靠服务。超大的规模和超高的复杂度给服务的可靠性、可用性和性能都带来了极大的挑战。近年来,微软亚洲研究院软件分析组在与微软在线服务部门合作,利用人工智能前沿技术解决大规模在线系统服务的运维问题,成为微软诸多产品如Office 365、Azure等的坚强后盾。本文中,软件分析组的研究员将会展开介绍在线系统背后的相关研究工作和成果。
为了保证在线系统的服务质量和用户体验,公司运维部门需要实时监控系统运行状况,以便对异常及时进行分析和处理。众所周知,在运维发展的过程中,最早出现的是手工运维,但手工方式通常费事耗力,一直是运维人员的梦魇。后来,大量的自动化脚本实现了运维的自动化,大大提高了运维效率。不过随着系统规模的日益增长,自动化的运维也变得差强人意。所幸,数据和AI时代的到来让运维方式迈向智能化的历史阶段。运维智能化开始被越来越多的企业所重视,通过搭建集中监控平台,收集并记录系统的各项运行状态和执行逻辑信息,如网络流量,服务日志等,实现对系统的全面感知。而随着系统规模的增长,运维数据也在爆炸式增长,每天有上百亿条日志产生,给运维带来了更大的挑战。
我们长期深耕数据智能领域,利用大规模数据挖掘、机器学习和人工智能技术对纷繁复杂的运维大数据进行实时分析,从而可以为系统维护提供有效的决策方案。如今,我们的研究成果已经应用到了微软Skype、OneDrive、Office 365、Azure等诸多在线服务中。下面将主要从异常检测、智能诊断、自动修复、和故障预测四个方面对我们的研究成果进行深入解析。

异常检测
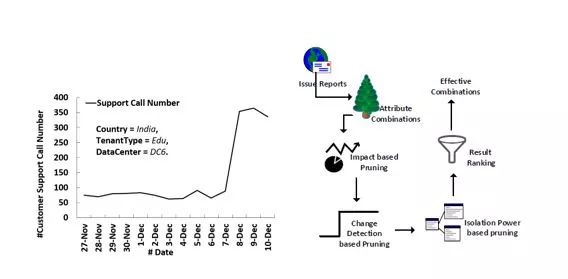
图:iDice
但是在大规模在线系统中,数量庞大的属性组合为检测有效组合带来了挑战。为此,我们提出了iDice[1]来高效找到有效组合,降低系统的维护成本。图iDice右侧展示了iDice的整体架构。首先,我们会从问题报告中整理出所有可能的属性组合,然后经过3次剪枝后再对剩下的属性组合排序,最终找到造成问题突发增长的有效组合。其中,3次剪枝分别为基于影响力的剪枝(Impact based pruning )、基于变化检测的剪枝(Change detection based pruning)以及基于区分能力(Isolation Power)的剪枝,通过剪枝可以有效缩减有效组合的查找范围。影响力(Impact)指对用户的影响程度,对更多用户造成影响的属性组合被认为有更大的影响力,而有效组合理应是影响力大的属性组合。此外,有效组合理应会造成报告数量的显著增长。接着,我们基于信息熵原理定义了区分能力,用来快速确定有效组合。
为了提供更稳定的服务,除了KPI异常预测,我们还会对系统日志进行异常事件识别,并支持对多维特征时序数据的异常分析。对于系统日志,通过日志解析将非结构化的日志信息转换成结构化的日志,再经过组合、不变因子挖掘,最终实现异常检测,详见文末参考文献[2]。
智能诊断
如果把异常检测比喻成一段高速公路上的堵车现象,那智能诊断的目标就是找到其背后的根本原因,是上下班高峰,还是交通事故,抑或是正在上演一场警匪角逐?
对异常的诊断基于对系统运行时产生的大量监测数据的深入分析。我们在实践中遇到了如下挑战:
1. 如何在海量指标数据中定位到异常原因?
2. 如何关联时序型的异常数据和文本类型的记录?
为了解决上述难题,我们先后提出了异构数据的关联分析方法[3],利用日志数据进行问题定位的日志诊断分析[4],以及在海量指标数据下的异常识别(Anomaly Detection)和自动诊断(Auto Diagnosis)系统AD2。
一、异构数据关联分析
时间序列(Time Series)数据和事件序列(Event Sequence)数据是两类常见的系统数据,包含丰富的系统状态信息。CPU使用率曲线就是一条典型的时间序列,而事件序列是用来记录系统正发生的事情,比如当系统存储不足时可能会记录下一系列“Out of Memory”事件。下图展示了CPU 使用率的时间序列和两个系统任务(CPU密集型程序和磁盘密集型程序)之间的关系。

图:时间序列数据与事件序列数据
监控数据和系统状态之间的相关性分析在异常诊断中发挥着重要的作用。为了定位异常原因,运维人员通常从在线服务的KPI指标(如宕机时间)和系统运行指标(如CPU使用率)的相关性切入。目前已经有很多工作研究时间序列数据和单一系统事件之间的相关性,但由于连续型的时间序列和时序型的事件序列是异构的,传统的相关分析模型(如Pearson correlation和Spearman correlation)效果差强人意。而且在大规模系统中,一件事件的发生可能与一整段时间序列相关,而传统的相关性分析只能处理点对点的相关性。
为此我们提出了创新性的方法来解决时间序列和事件序列的相关性问题[3],我们将问题建模为双样本(two-sample)问题,再用基于最近邻统计的方法来挖掘相关性。
二、日志分析
打日志是记录系统运行相关信息的关键方法,日志数据也成为问题诊断的重要资源[5]。一个微软的服务系统每天会产生1PB的日志数据,系统规模之大,复杂性之高的同时还带来了海量日志,一旦出现问题,手工检查日志需要耗费大量的时间。而且,与传统软件系统一劳永逸的漏洞修正方式不同,在大规模在线系统中,一个问题修正后还可能会反复出现,因此在问题诊断时可能会做大量重复性劳动。日志数据的类型也极具多样性,但不是所有的日志信息在问题诊断时都同等重要。
为了解决上述问题,我们提出了一种基于日志聚类的问题诊断方法[4]。如下图所示,日志分析分为两个阶段,构造阶段和产品阶段。在构造阶段,我们从测试环境(测试环境通常是一个小型的虚拟云平台)中收集日志数据,进行向量化(Log Vectorization)、分权重聚类后(Log Clustering),从每个集合中挑选一个代表性的日志,构造日志知识库(Knowledge Base)。在产品阶段,我们从大规模实际生产环境中收集日志,进行同样处理后与知识库中的日志进行核对。如果知识库中存储了这条日志,代表该问题之前已经过,只需采用以往的经验处理,如果没出现过,再进行手工检查。
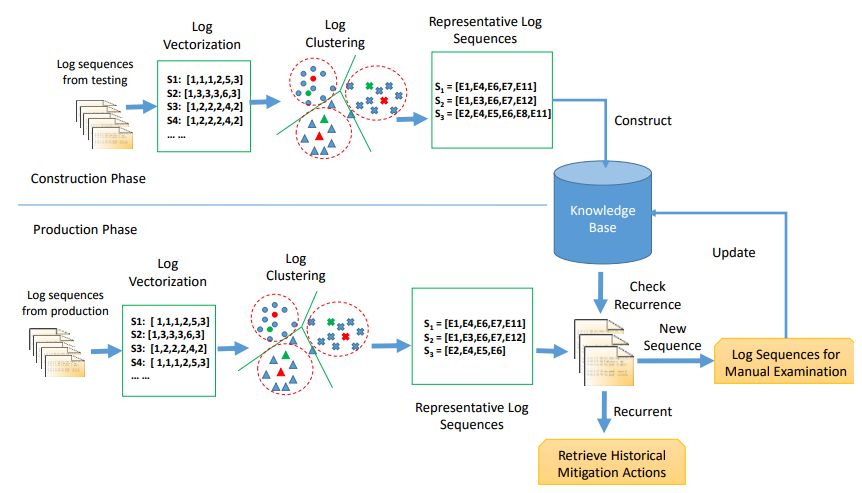
图:日志分析
三、AD2
AD2 的全称是异常检测和自动诊断(Anomaly Detection and Auto Diagnosis),AD2的自动诊断旨在解决海量指标数据下的异常诊断。
图AD2 表明在一段时间内出现两次服务异常,而在线系统从CPU、内存、网络、系统日志、应用日志、传感器等采集了上千种系统运行指标(Metric),而且这些指标之间存在复杂的关系,单独研究问题和指标之间的相关性已经无法得出诊断结论,需要理解指标之间的相关性。
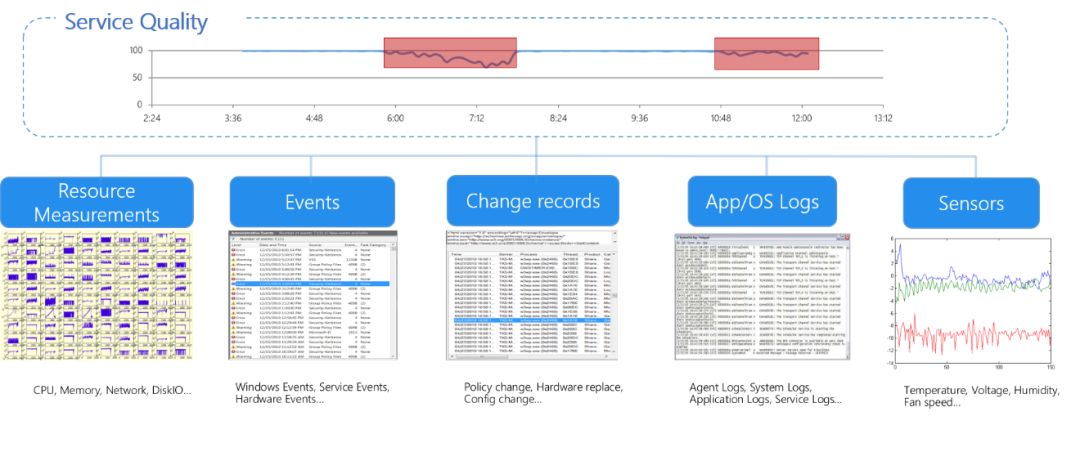
图:AD2
AD2基于这些指标数据构造出指标间的关系图,再根据贝叶斯网络估算条件概率,从而诊断出引起问题的主要指标。
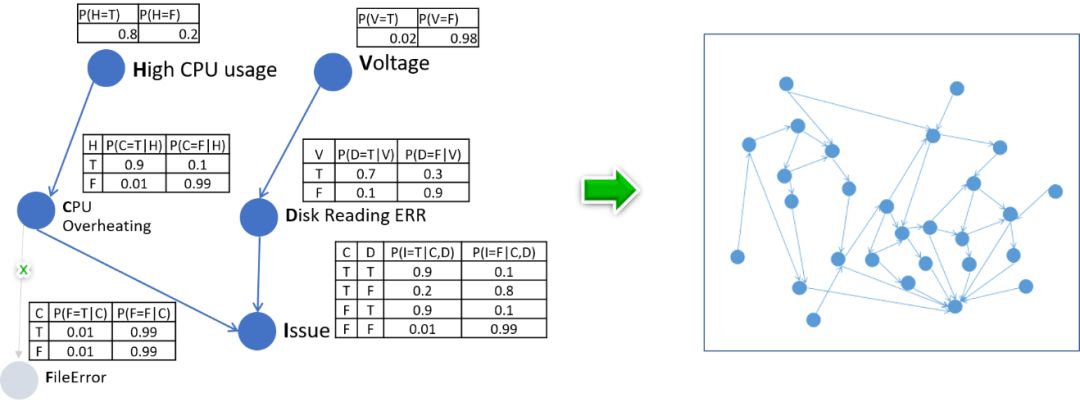
图:关系图
从2017年3月上线以来,AD2为Azure平台捕捉到数量可观的异常情况,并提供了有效的诊断信息。
自动修复
平均修复时间(Mean Time to Restore, MTTR)是衡量在线系统可靠性以及保证用户满意度的重要指标。为了减少MTTR,通常的修复做法是在问题出现时人工确定一个合适的(糙快猛)的方式(比如重启机器),等服务恢复正常后,再去挖掘并修复潜在的根本问题,因为“治本”比“治标”需要更多的时间。但是,人工确定修复方式一来耗时,大约占用到90% MTTR,二来容易出错,因为确定一个合适的修复方法需要很强的领域知识。由于大规模在线系统中的每台机器每天都会产生海量运行数据,人工修复的改革势在必行。
为了解决人工修复的“事倍功半”问题,我们提出了自动产生修复建议的方法[6],其主要思想是当一个新问题出现的时候,利用过去的诊断经验来为新问题提供合适的解决方案。下图展示了该策略的主要流程。首先,我们会根据问题(issue)的详细日志信息为其生成一个签名(Signature),还建了一个问题库记录过去已经解决过的问题,其中每个问题都有一些基本信息,比如发生时间、地点(某集群,网络,或数据中心)、修复方案。其中,修复方案由一个三元组描述<verb, target, location>,verb是采取的动作如重启,target是指组件或服务,如数据库,location是指问题影响到的机器及机器位置。当一个新问题出现的时候,我们会去问题库中寻找与其签名相似的问题,如果找到就可以根据相似问题的修复方案来修复,否则就单独人工处理。
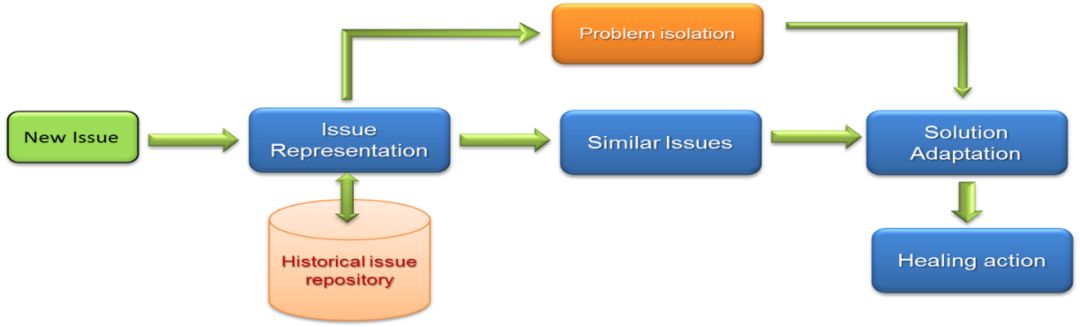
图:自动修复
在生成签名的过程中,我们首先采用了形式概念方法(Formal Concept Analysis )将高度相关的事件组合到一起,也就是一个Concept,并基于互信息衡量每个Concept与相应的日志记录之间的相关性,再根据相关数据生成问题签名。
在实践中,我们还遇到了其他挑战并提出了相应的解决方法。自动修复技术已经应用到微软的在线服务维护中,并有效地减少了MTTR,细节请参看文末论文[6].
Service Analysis Studio (SAS)
在系统实际运行中时而会发生某些系统故障,导致系统服务质量下降甚至服务中断,通常称为服务事故(Service Incident)。在过去的几年中,很多大公司运作的在线系统都曾经出现过多次服务事故。这样的服务事故往往会带来巨大的经济损失,并且严重损害公司的商业形象。因此,事故管理(Incident Management)对于保证在线服务系统的服务质量很重要。
一个典型的事故管理过程通常可以分为事故检测接收和记录、事故分类和升级分发、事故调查诊断、事故的解决和系统恢复等环节。事故管理的各个环节通常是通过分析从软件系统收集到的大量监测数据来进行的,这些检测数据包括系统运行过程中记录的详细日志(log和trace),CPU及其他系统部件的计数器,机器、进程和服务程序产生的各种事件等不同来源的数据。这些监测数据往往包含大量能够反映系统运行状态和执行逻辑的信息,因此在绝大多数情况下能够为事故的诊断、分析和解决提供足够的支持。
在过去的几年中,我们采用软件解析的方法来解决在线系统中事故管理问题,开发了一个系统Service Analysis Studio(SAS)来帮助软件维护人员和开发人员迅速处理、分析海量的系统监控数据,提高事故管理的效率和响应速度。具体来说,SAS包括如下分析方法(详见文末论文[7]):
1)可疑信息挖掘。从大量数据中自动找出可能与当前服务事故相关联的信息,进而帮助定位事故发生的源头和推测事故发生的机理;
2)缺陷组件定位。通过检测野点的方法,定位到个别运行状态“与众不同”的组件。
3)诊断信息重用。SAS中为每个事故案例创建指纹(signature),并且定义两个案例间的相似度。当事故发生后,会查找是否存在相似的历史案例,并在之前相似案例的解决方案的基础上给当前事故提供参考解决方案。
4)分析结果综合。为了使得SAS能够非常容易地被用户所理解和使用,我们将从不同分析算法中得到的结果进行综合,综合的结果以一个报表的形式呈现出来以方便用户使用。
SAS在2011年6月被微软某在线产品部门所采用,并安装在全球的数据中心,用于一个大规模在线服务产品的事故管理。我们从2012年开始收集SAS的用户使用记录。通过分析半年的使用记录发现,工程师在处理大约86%的服务事故处理中使用了SAS,并且SAS能够为解决其中的大约76%提供帮助。
故障预测
上文主要介绍了如何在故障出现之后进行高效的诊断和修复,更理想的情况是把问题扼杀在摇篮中。比如,如果可以提前预测出数据中心的节点(node)故障情况,就可以提前做数据迁移和资源分配,从而保障系统的高可靠性。
现有方法是把故障预测抽象为是与非的二分类问题,使用分类模型(如随机森林、SVM)做预测,并取得了相当好的效果。但面对实际生产环境,这些“实验室成果”则无能为力。首先,大规模复杂系统的故障原因多种多样,可能是由硬件或软件问题引起,分布在系统不同层级,也可能是多个组件共同作用产生的故障。数据特征也十分多样,包括数值型,类别型以及时间序列特征,简单模型已无法处理。其次,极度不平衡的正负样本为在线预测带来了极大的挑战。健康节点(磁盘)被标记为负样本,故障节点(磁盘)为正样本,在磁盘故障预测中,每天Azure的故障磁盘与健康磁盘的比例大约3:100000,预测结果会倾向于把所有磁盘都预测为健康,带来极低的召回率。而采样方法对在线预测也不适用,因为采样后的数据集无法代表真实情况,训练出的模型也会存在偏差。
为此,我们和Azure的专家们密切合作,分析故障原因,挖掘系统日志,提取重要特征,并采用KANG算法解决在线预测问题,得到预测样本的故障概率,把最可能出现故障的样本交给运维人员。
机会与挑战
大数据和人工智能的发展为在线系统的运维方式改革带来了“东风”,使得运维在由人工进化到自动之后,又迎来新的跨越。除了互联网,在金融、物联网、医疗、通信等领域,智能运维也将表现出强烈的需求。
虽然机器学习研究已经遍地开花,但基于机器学习的智能运维目前还面临着一些实际的挑战。首先,高质量的标注数据不足。由于运维的领域知识性较强,我们需要专业的运维工程师或专家参与标注才能取得高质量的标注数据,而这个过程需要花费大量时间,一个高效的数据标注方案令人期待。其次,在线系统的大规模和复杂性为运维问题带来了天然的挑战,即使总体样本量大,但异常种类少,类别不均衡。现有机器学习方法可以服务的场景与实际生产环境存在极大差距,这就要求运维人员既要有强大的知识装备,又有能够解决实际问题的技能,同时,这也值得更多研究者关注并投入实践。

微软亚洲研究院软件分析组
Reference
[1] Qingwei Lin, et al. iDice: Problem Identification for Emerging Issues. ICSE 2016
[2] Qiang Fu, et al. Contextual Analysis of Program Logs for Understanding System Behaviors. MSR 2013
[3] Chen Luo, et al. Correlatingevents with time series for Incident Diagnosis. KDD 2014
[4] Qingwei Lin, et al. Log Clustering based Problem Identification for Online Service Systems. ICSE 2016
[5] Qiang Fu et al. Where do developers log? An empiricalstudy on logging practices in industry. ICSE 2014
[6] Rui Ding et al. Mining Historical Issue Repositories to Heal Large-Scale Online Service Systems. DSN 2014
[7] Jian-Guang Lou, et al. Software Analytics for Incident Management of Online Services - An Experience Report. ASE 2013 Experience Track
你也许还想看:
● 成为数据专家,你只差一个Quick Insights的距离

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。






