MySQL挑战:10万连接数

在这篇文章中,我想探索一种与MySQL建立100,000个连接的方法。不限于空闲连接,还有执行查询功能的连接。
你可能会问,使用MySQL的时候真的有必要建立100,000个连接吗?虽然看起来有点过于追求极致,我还是在客户部署的时候看到很多不同的设计方案。有的部署了应用程序连接池,每一个连接池中有100个应用服务和1000个连接。有的应用程序使用了一种很糟糕的技术,“在查询慢时重连或重用”。这有可能会导致雪球效应,并在几秒钟内建立数千个MySQL连接。
所以现在我想设置一个超出预期的目标,看看能否实现。
配置
为此我将使用以下硬件配置:
由packet.net提供的裸机服务器,实例大小:c2.medium.x86
物理内核 @ 2.2 GHz (1 X AMD EPYC 7401P)
内存: 64 GB of ECC RAM
磁盘: INTEL® SSD DC S4500, 480GB
这是一个服务器级的 SATA SSD。
我们将使用到5台主机,下面作出解释,一个用于MySQL服务器的主机,以及四个用于客户端连接的主机。
在服务器上,我将使用带有线程池插件的Percona Server for MySQL 8.0.13-4。这个插件可以支持数千个数据库连接。
初始化服务器设置
网络设置(Ansible格式):
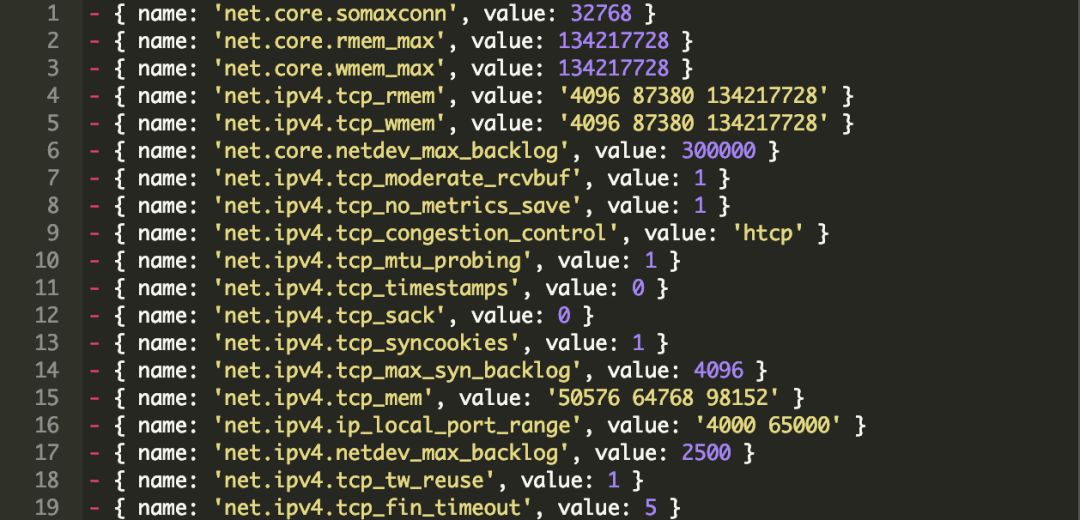
这些是推荐用于10Gb网络和高并发工作负载的典型设置。
systemd限制设置:

还有my.cnf文件中MySQL相关设置:

客户端使用sysbench 0.5版本而不是1.0.x版本,原因我们将在下面解释。
工作负载配置
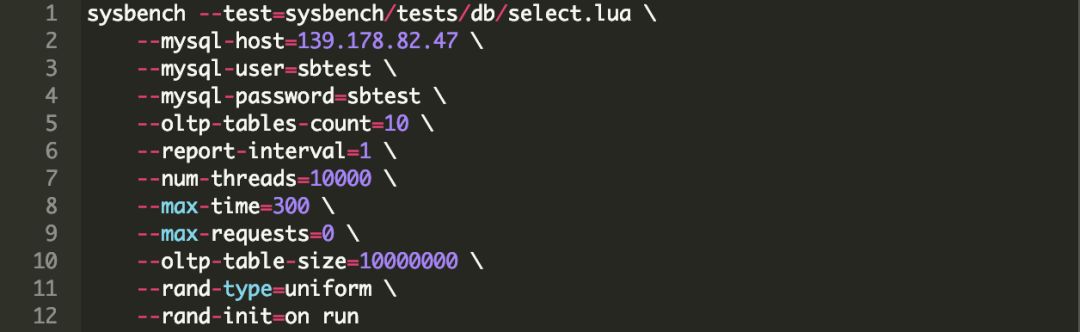
第一步 10,000连接数
这一步很简单,没有太多的事情需要处理。我们可以只用一个客户端实现,但是你有可能会遇到下面的错误:

这个是由于打开文件数限制引起的,也叫做TCP/IP套接字连接限制。可以在客户端设置 ulimit -n 100000 来解决。
我们能观察到的:

第二步 25,000连接数
使用25,000个连接的时候,在MySQL端会看到错误信息:

如果你查找这个错误的信息的话,你可能会看到这篇文章:
https://www.percona.com/blog/2013/02/04/cant_create_thread_errno_11/
但是这并不能解决我们的问题,因为我们已经把限制设置的足够高了:
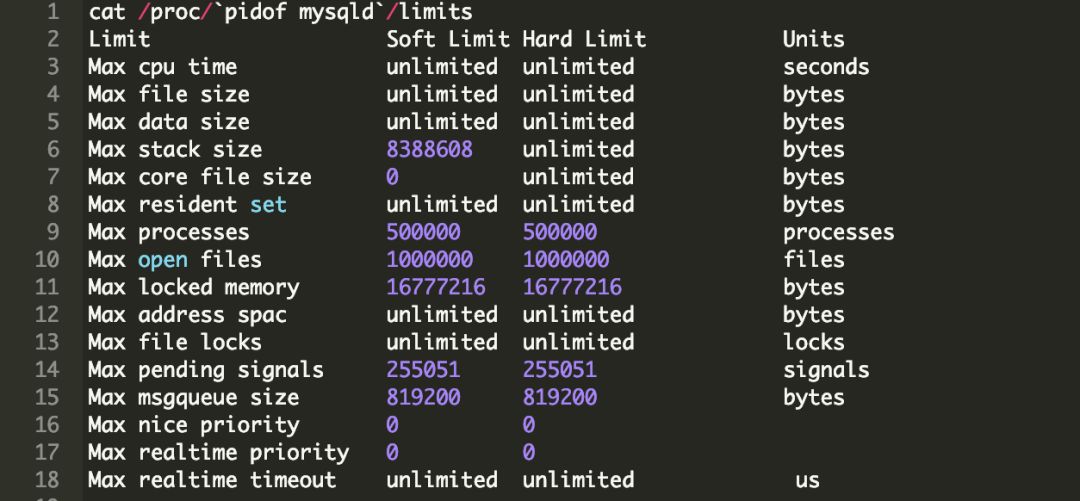
我们是从这里开始使用线程池功能的:https://www.percona.com/doc/percona-server/8.0/performance/threadpool.html
在my.cnf中增加:

并重启 Percona 服务器。
打印结果:

现在还是相同的吞吐量,但是实际上95%的响应时间已经从3690毫秒优化到979毫秒(由于使用了线程池)。
第三步 50,000连接数
这是目前我们遇到的最大的挑战。首先,在尝试从sysbench中获取50,000个连接的时候遇到了以下错误:

Error(99)是一个很隐蔽的错误,它表示:无法分配请求地址。
它是由应用程序可以打开的端口限制所触发,我的操作系统默认情况下是:

这表示有28231个端口可用(60999减32768),或者说是与给定IP地址所能建立的TCP连接的端口数限制。
你可以在客户端和服务端上使用一个更大的范围来扩展这些端口。

这给我们提拱了61000个连接,但是已经非常接近一个IP地址的连接限制了(最大端口号65535)。关键点在于,如果我们想要更多的连接数,那么则需要为MySQL服务器分配更多的IP地址。为了实现100,000连接数,我将在运行MySQL的服务器上使用两个IP地址。
在整理出端口范围后,sysbench又抛出了以下问题

这是sysbench的内存分配问题(即lua子系统)。Sysbench只能为32,351个连接分配内存,这个问题在sysbench 1.0.x版本中尤为严重。
Sysbench 1.0.x的局限
Sysbench 1.0.x使用了一套不同的Lua JIT(Just In Time,即时编译技术),甚至在连接数达到4000的时候就会产生内存问题,所以使用Sysbench 1.0.x想要超过4000连接数都是不可能的。
因此,与Percona Server相比,sysbench会更早达到连接数瓶颈。我们需要使用更多的sysbench客户端来实现更多的连接。如果sysbench的连接上限是32,351,那么至少要使用4个sysbench客户端才能达到100,000个连接。
我使用2台服务器(每个服务器运行单独的sysbench)实现50,000个连接,每个sysbench上运行25,000个线程。
每个sysbench上执行结果如下:

然而同样的吞吐量(总共 16794 * 2 = 33588 tps)的情况下,有95%的响应时间都翻了一倍。这是可以预见的,因为相比于25,000个基准测试连接,我们使用的连接数是原来的两倍。
第三步 75,000连接数
我们将使用3个sysbench服务器来实现75,000个连接,每个服务器上运行25,000个连接。
每个sysbench的运行结果:

第四步 100,000连接数
实现连接数从75k到100k并没有什么大的变化,我们只需要启动一个额外的服务器并启动sysbench就可以了。对于100,000个连接,我们需要四个sysbench服务器,每一个服务器显示:

所以相同吞吐量(总共 8065 * 4 = 32260 tps)时,有95%的相应时间为3405ms。
一个很重要的点是:建立100k个连接并使用线程池,95%的响应时间甚至比不带线程池的10k个连接更快。线程池使得Percona Server更有效的管理资源并提供更快的响应时间。
总结
MySQL实现10万连接数是完全可行的,而且我相信我们还可以更进一步。这里有三个组件可以帮助我们实现目标:
Percona Server的线程池
适当调整网络限制
服务器主机使用多个IP地址(一个IP地址支持大约60k个连接)
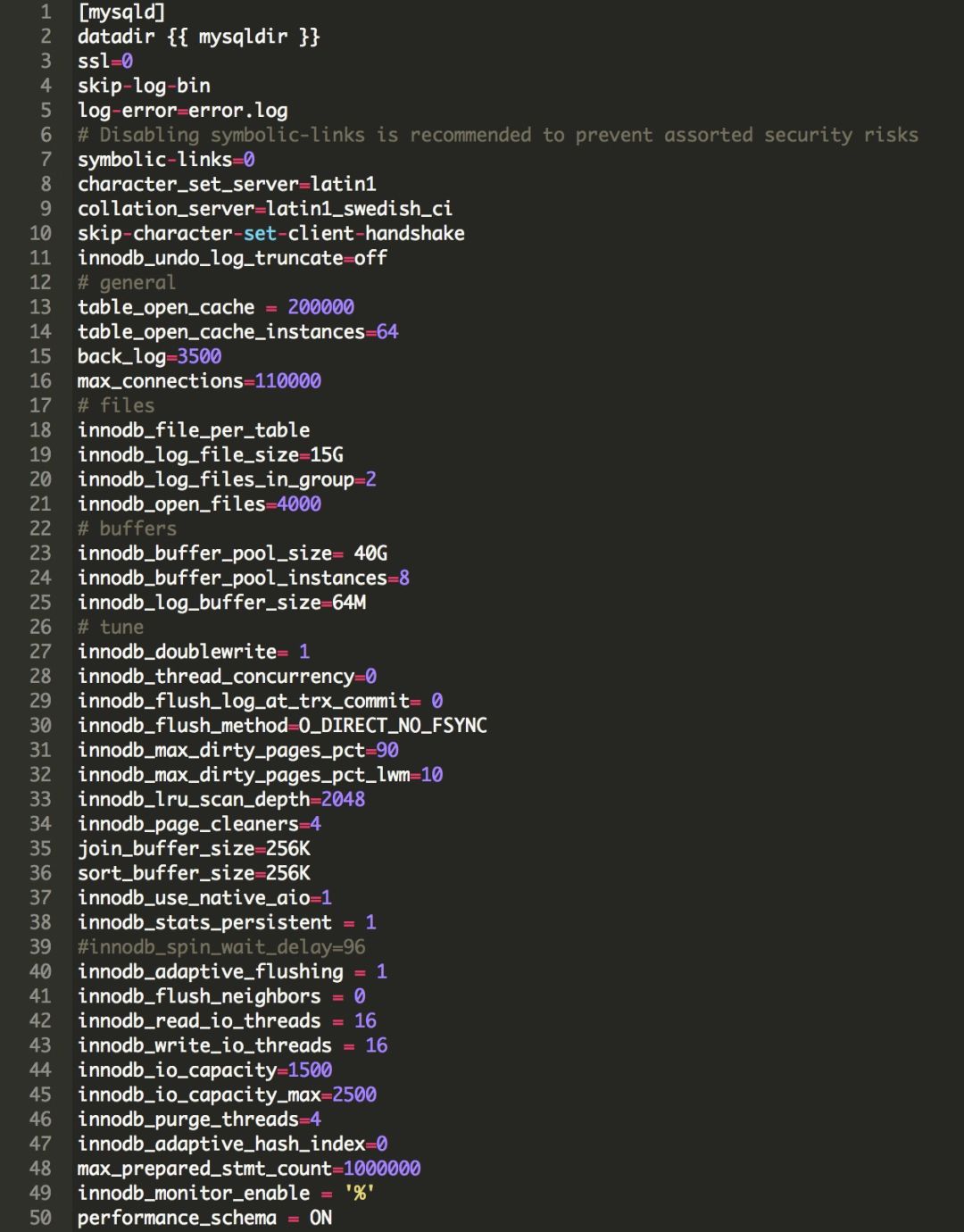
附录:my.cnf
英文原文:https://www.percona.com/blog/2019/02/25/mysql-challenge-100k-connections/
译者:敦伟




