数据分析很难学?60天就够了!
上世纪90年代,沃尔玛的管理人员分析销售数据时发现了一个令人费解的现象:在某些特定的情况下,”啤酒”与”尿布”两件看上去毫无关系的商品,经常出现在同一个购物篮中。于是沃尔玛将两种商品打包出售,啤酒和尿布的销量大幅增长。
“啤酒与尿布”的故事成为一段佳话,但其背后支撑的技术,只是简单的数据分析方法。
利用数据分析的方法,我们还可以得到很多有意思的结论,比如谷歌的数据分析可以预测一个地区即将爆发的流感,从而进行针对性的预防;淘宝可以根据你浏览和消费的数据进行分析,为你精准推荐商品;口碑极好的网易云音乐,通过其相似性算法,为不同的人量身定制每日歌单……
正如 Hal Varian 所说,数据正在变得越来越常见,小到我们每个人的社交网络、运动轨迹、消费信息……,大到企业的销售、运营数据,产品的生产数据、交通网络数据……
如何从海量数据中获得别人看不见的知识,如何利用数据来武装营销工作、优化产品、支撑决策,数据分析将成为重要的一环。
那么,普通人如何快速获得数据分析的能力呢?可能有很多大神给了你书单,学习方法,但你发现这样学习跟高效毫无关系。这里向你推荐一门课,通过最佳的学习路径,学习数据分析的核心技能,60天就够了。

你不需要看完大神给你推荐的100本书,不需要耗费精力去筛选、甄别学习资料。
这里为你提供了一条快速的学习路径,基于一线企业的真实分析案例,提供最完善最精选的学习资料。
自动批改的课后习题和即时排名的练习竞赛,足够让你去检测学习成果和技术水平。
如果你觉得自己应该具备一项未来必备的核心技能,并且正在寻找到一条很爽的学习路径。那么你可以直接跳到文尾,点击“阅读原文”开始数据分析之旅。如果对于数据分析的学习和入门你还想有更深入的了解,下面我们慢慢入坑。
我们从拉钩上找了一些最具有代表性的数据分析师职位信息,来看看薪资不菲的数据分析师需要哪些技能。



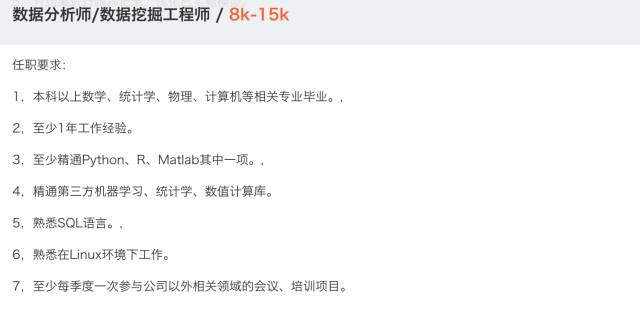

其实企业对技能需求差别不大,可总结如下:
SQL数据库的基本操作,会基本的数据管理
会用Excel/SQL做基本的数据分析和展示
会用脚本语言进行数据分析,Python or R
有获取外部数据的能力,如爬虫
会基本的数据可视化技能,能撰写数据报告
熟悉常用的数据挖掘算法:回归分析、决策树、随机森林、支持向量机等
一个数据分析师的工作流程是什么样的?
定义问题
确定你需要去分析的问题是什么?你想得出哪些结论?
比如某地区空气质量变化的趋势是什么?
影响公司销售额增长的关键因素是什么?
生产环节中影响产能和质量的核心指标是什么?
如何对分析用户画像并进行精准营销?
如何基于历史数据预测未来某个阶段用户行为?
问题的定义需要你去了解业务的核心知识,并从中获得一些可以帮助你进行分析的经验。
数据获取
有了具体的问题,你就需要获取相关的数据了。比如你要探究北京空气质量变化的趋势,你可能就需要收集北京最近几年的空气质量数据、天气数据,甚至工厂数据、气体排放数据、重要日程数据等等。如果你要分析影响公司销售的关键因素,你就需要调用公司的历史销售数据、用户画像数据、广告投放数据等。
数据的获取方式有多种。
一是公司的销售、用户数据。可以直接从企业数据库调取,所以你需要SQL技能去完成数据提取等的数据库管理工作。比如你可以根据你的需要提取2017年所有的销售数据、提取今年销量最大的50件商品的数据、提取上海、广东地区用户的消费数据……,SQL可以通过简单的命令帮你完成这些工作。
第二种是获取外部的公开数据集,一些科研机构、企业、政府会开放一些数据,你需要到特定的网站去下载这些公开数据。
第三种是编写网页爬虫,收集互联网上的数据。比如你可以通过爬虫获取招聘网站某一职位的招聘信息,爬取租房网站上某城市的租房信息,爬取豆瓣评分评分最高的电影列表,获取知乎点赞排行、网易云音乐评论排行列表。基于互联网爬取的数据,你可以对某个行业、某种人群进行分析,这算是非常靠谱的市场调研、竞品分析的方式了。
数据预处理
原始的数据可能会有很多问题,比如残缺的数据、重复的数据、无效的数据等等。把这些影响分析的数据处理好,才能获得更加精确地分析结果。
比如空气质量的数据,其中有很多天的数据由于设备的原因是没有监测到的,有一些数据是记录重复的,还有一些数据是设备故障时监测无效的。
那么我们需要用相应的方法去处理,比如残缺数据,我们是直接去掉这条数据,还是用临近的值去补全,这些都是需要考虑的问题。
当然在这里我们还可能会有数据的分组、基本描述统计量的计算、基本统计图形的绘制、数据取值的转换、数据的正态化处理等,能够帮助我们掌握数据的分布特征,是进一步深入分析和建模的基础。
数据分析与建模
在这个部分需要了解基本的数据分析方法、数据挖掘算法,了解不同方法适用的场景和适合的问题。分析时应切忌滥用和误用统计分析方法。滥用和误用统计分析方法主要是由于对方法能解决哪类问题、方法适用的前提、方法对数据的要求不清等原因造成的。
比如你发现在一定条件下,销量和价格是正比关系,那么你可以据此建立一个线性回归模型,你发现价格和广告是非线性关系,你可以先建立一个逻辑回归模型来进行分析。
当然你也可以了解一些数据挖掘的算法、特征提取的方法来优化自己的模型,获得更好的结果。
数据可视化及数据报告撰写
分析结果最直接的是统计量的描述和统计量的展示。
比如我们通过数据的分布发现数据分析师工资最高的5个城市,目前各种编程语言的流行度排行榜,近几年北京空气质量的变化趋势,商品消费者的地区分布……这些都是我们通过简单数据分析与可视化就可以展现出的结果。
另外一些则需要深入探究内部的关系,比如影响产品质量最关键的几个指标,你需要对不同指标与产品质量进行相关性分析之后才能得出正确结论。又比如你需要预测未来某个时间段的产品销量,则需要你对历史数据进行建模和分析,才能对未来的情况有更精准的预测。
数据分析报告不仅是分析结果的直接呈现,还是对相关情况的一个全面的认识。所以你需要一个讲故事的逻辑,如何从一个宏观的问题,深入、细化到问题内部的方方面面,得出令人信服的结果。
基于解决问题流程的学习路径:
你看,其实数据分析就这几个步骤,实现起来也感觉并不难。最好的学习路径是什么,就是按照解决问题的流程去学习。你了解这个流程,然后循序渐进深入每个部分,你会觉得这是一件特别容易上手的事情。而我们的课程设计正是源于这种思路,以下是课程的大纲:
《数据分析(入门)》课程大纲
60入门数据分析师
第一章:开启数据分析之旅 (1天)
1) 数据分析的一般流程及应用场景
2) Python 编程环境的搭建及数据分析包的安装
第二章:获取你想要的数据 (2周)
1) 获取互联网上的公开数据集
2) 用网站 API 爬取网页数据
3) 爬虫所需的 HTML 基础
4) 基于 HTML 的爬虫,Python(Beautifulsoup)实现
5) 网络爬虫高级技巧:使用代理和反爬虫机制
6) 应用案例:爬取豆瓣 TOP250 电影信息并存储
第三章:数据存储与预处理 (2周)
1) 数据库及 SQL 语言概述
2) 基于 HeidiSQL 的数据库操作
3) 数据库进阶操作:数据过滤与分组聚合
4) 用 Python 进行数据库连接与数据查询
5) 其他类型数据库:SQLite&MongoDB
6) 用 Pandas 进行数据预处理:数据清洗与可视化
第四章:统计学基础与 Python 数据分析 (3周)
1)探索型数据分析:绘制统计图形展示数据分布
2)探索型数据分析实践:通过统计图形探究数据分布的潜在规律
3)描述统计学:总体、样本和误差,基本统计量
4)推断统计学:概率分布和假设检验
5)验证型数据分析实践:在实际分析中应用不同的假设检验
6)预测型数据分析:回归、分类、聚类
7)预测型数据分析:用特征选择方法优化模型
8)预测型数据分析实践:用 scikit-learn 实现数据挖掘建模全过程
9)预测型数据分析实践:用 rapidminer 解决商业分析关键问题
10)高级数据分析工具:机器学习、深度学习初探
第五章 报告撰写及课程总结 (1周)
1) 养成数据分析的思维
2) 数据分析的全流程及报告撰写的技巧
3) 课程回顾以及一些拓展
按照计划,完成这些技能的学习,只需要60天,还包括你进行课外练习和补充知识的时间。
但更重要的是,每学习一部分知识,你知道是在哪个环节应用,去解决哪些问题。比如:
学完python爬虫,你可以自己去获取一些数据集;
学完SQL,你可以把获取的数据进行存储和提取;
利用pandas,可以进行数据的预处理;
学习统计学和python数据分析之后,你就可以实现完整的数据分析流程。
如果你有看过教学视频的经历,那么相信你一定遇到过这样一些问题:
课程需要一定的基础知识,但是老师并不会讲;
老师按照自己的理解水平来授课,很多地方听不懂;
老师的写的代码自己再写一遍,问题百出;
由于有深入的需求,寻找资料困难;
………………
考虑到各种各样的问题,课程中准备了非常丰富的学习资料,细分到每一节。主要包含四个部分:
课程中重要的知识点,资料中会进行详细阐述,帮助你理解;
默认你是个小白,补充所有基础知识,哪怕是软件的打开与关闭;
课程中老师的参考代码打包,让你有能力去复现案例;
提供超多延伸资料,让你可以去做更多的事情。

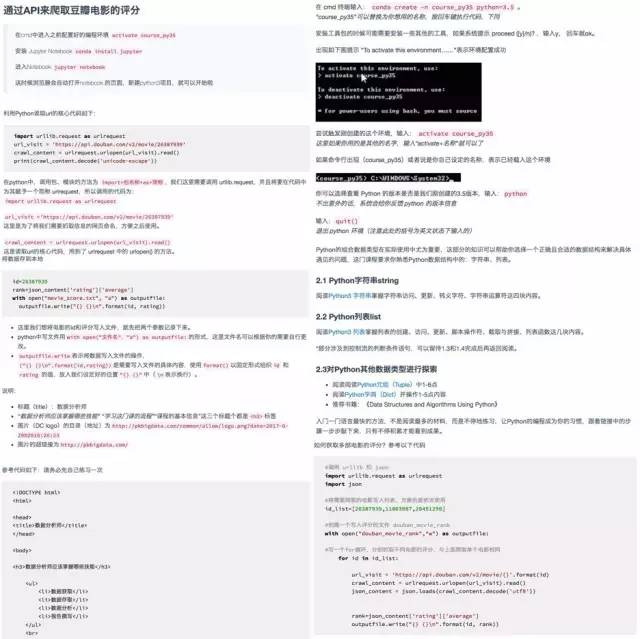
有很多爬过坑的同学反馈,学习编程等技术时,最大的BUG,往往在于感觉理解了知识点,却写不出自己的代码。甚至老师举的例子自己能够实现,却不能在其他的项目中应用。
这个问题并不是无解,而且办法很简单——刻意练习。
除了帮助你实现课程中老师的案例,我们还将提供很多的课外练习,全都是你最可能会用到的案例。比如老师会讲如何用python爬取豆瓣TOP200的电影,但是你不会爬取知乎的高票答案啊,招聘数据自己也爬不了,好气呀,怎么办?
别担心,课程中会提供同类问题下,不同例子的思路和参考的代码,你可以照着实现。相信从不同的案例练习、实现几次,没有什么是不能掌握的。
大部分的章节,都有习题,提交答案即可自动批改。更重要的是,我们设计了一些专门针对课程内容的练习竞赛。你可以通过数据分析的方法来获得答案,提交后系统会立即给你评分,并展示排名,你可以据此不断优化自己的方法。
以下为针对课程设计的练习竞赛



DC有成熟的评分和排名机制,为你提供精确的成绩和排名
课程采用录播的形式,你可以按照自己的节奏来规划学习节奏。为准备这个课程,我们吸取了无数数据分析师和竞赛选手爬坑的经验,我们研究了目前主流的数据分析书籍和课程,还有,邀请了两位能够为你提供学习方向的老师:

【课程主讲老师】

王乐业
香港科技大学博士后
王乐业,香港科技大学博士后,法国国立电信学院及巴黎六大计算机科学与技术专业博士。本科和硕士毕业于北京大学计算机科学与技 术专业。目前研究方向研究方向为城市时空数据挖掘。从事研究工作包括通过社交网络识别个人兴趣、通过移动通信网络推理人群移动模式、以及通过公共交通数据优化交通站点分布等。发表论文20余篇,其中SCI10余篇,引用300余次。乐业老师是一位乐于分享的学者,善于用简单的方法解答复杂的问题。在他看来,找到好的学习方法和路径,其实可以少走很多弯路。
【课程研发老师】

周涛
电子科技大学教授
周涛,电子科技大学教授、大数据研究中心主任。主要从事统计物理与复杂性,数据挖掘与数据分析方面的研究。在Physics Reports、PNAS、Nature Communications等国际 SCI期刊发表300余篇学术论文,引用超过17000次,H 指数为63。2015年入选全国十大科技创新人物,超级畅销书《大数据时代》译者,畅销书 《为数据而生:大数据创新实践》作者。周涛教授参与课程的研发和课程体系的设计,以多年的教学科研和企业数据团队管理经验为课程的顶层设计保驾护航。


种一棵树最好的时间是十年前,其次是现在
DC学院数据分析课程,60天入门数据分析师
8月8日-8月13日(公测期),半价(¥299)
限额200名!
快去抢!马上!就去!抢!
长按并识别下方二维码加入课程

如果你想过成为一名数据分析师
或者想学习一些未来有用的分析技能
这将是一个非常好的机会
60天,零基础掌握终身受用的技能
你将开始懂得数据分析的思维
用客观分析代替经验和猜测
能够用数据和别人撕逼
你将会养一条小蛇
它的名字叫python
它将为你处理所有重复性的工作
为你找到最有用的数据
它有一些非常棒的宝物
pandas、numpy、scikit-learn
帮你处理千万行数据
如果你愿意
他将带你体验更多好玩的东西
机器学习、深度学习
你将会找到一把钥匙
它将为你开启数据库的大门
然后你会发现
你想要的那部分数据
只是它一句话的事情
我们亲切地称它为:SQL
你将获得一把名为统计学的武器
足够劈开数据分析路上的阻碍
你将掌握一些黑魔法
回归分析、决策树、随机森林……
让你分析过去、预测未来
当然,还有很多,等你去探索
你会了解并实现一线企业的真实案例
你会知道如何通过代码实现自己的想法
你会了解什么是 machine learning
知道如何寻找解决问题的最佳算法
你还会知道如何用数据去讲一个完美的故事
去参加你曾望而止步的数据竞赛
你会将这些技能用于武装你的工作
甚至打开一些职业发展的新可能
点击下方“阅读原文”加入




