可复现性?稳健性?Joelle Pineau无情揭示强化学习的问题
机器之心原创
作者:Yufeng Xiong
编辑:李亚洲、Hao Wang
编译:路、张倩
当地时间 12 月 5 日,NeurIPS 2018 Posner Lecture 邀请到了 Facebook 蒙特利尔 FAIR 实验室负责人、麦吉尔大学副教授 Joelle Pineau。Joelle Pineau 在演讲中深刻揭露了强化学习中目前存在的一些问题(如可复现性等),并为参会者给出了系列建议。机器之心对她的演讲内容进行了整理。
演讲者简介:

Joelle Pineau,图源:https://research.fb.com/why-diversity-matters-in-ai-research/
加拿大麦吉尔大学副教授、William Dawson 学者,麦吉尔大学推理与学习实验室联合主任;
Facebook 蒙特利尔 FAIR 实验室负责人;
在滑铁卢大学获得学士学位,在卡内基梅隆大学获得机器人学硕士与博士学位;
致力于开发在复杂、局部可观察领域中规划和学习的新模型和算法,还将这些算法应用于机器人学、医疗、游戏及对话智能体中的复杂问题;
Journal of Artificial Intelligence Research、Journal of Machine Learning Research 杂志编委会成员,国际机器学习学会(International Machine Learning Society)主席;
加拿大自然科学与工程研究理事会(NSERC)的 E.W.R. Steacie Memorial Fellowship(2018)、AAAI Fellow 及 CIFAR 高级 Fellow,2016 年被加拿大皇家学会评选为「College of New Scholars, Artists and Scientists」成员。
可复现性、可重用性及稳健性
演讲一开始,Joelle Pineau 引用 Bollen 等人 2015 年向国家科学基金会提交的《Social, Behavioral, and Economic Sciences Perspectives on Robust and Reliable Science》解释了三个名词——可复现性、可重用性及稳健性(Reproducibility,Reusability,Robustness):
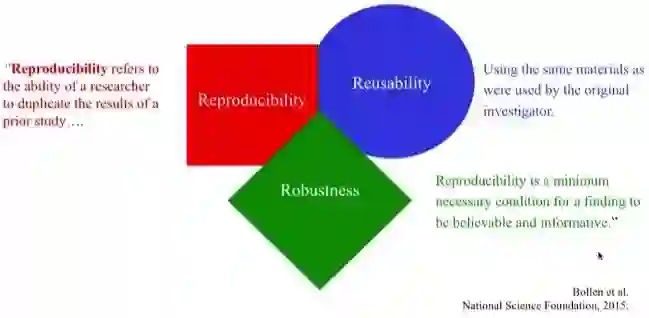
「可复现性指研究者重复过去某个研究的能力……」
「可重用性:使用与原研究者相同的材料。」
「可复现性是一项研究可信、信息充分的最低必要条件。」
实际上,Joelle 不是第一个提出可复现性问题的研究者。2016 年,《Nature》发起了一项名为《Is there a reproducibility crisis in science?》的调查。
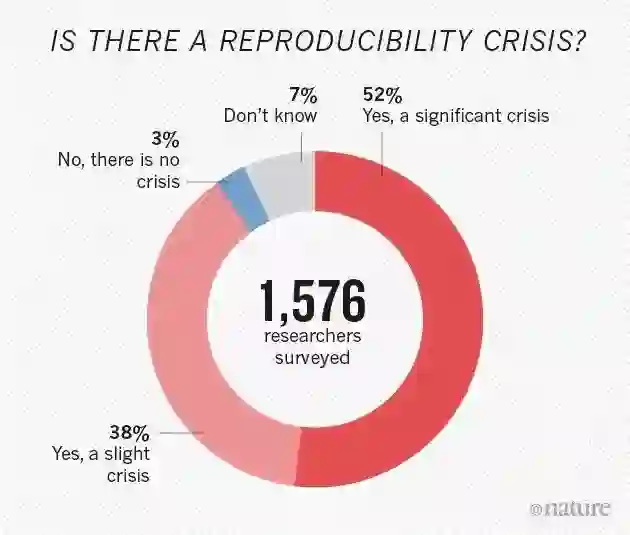
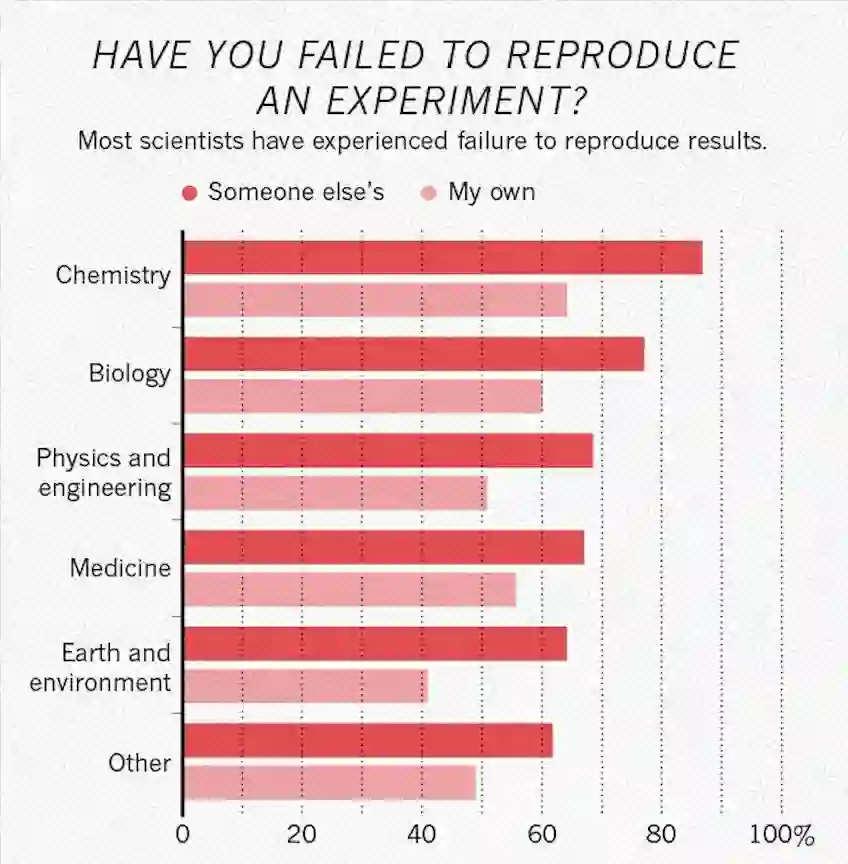
调查结果显示,52% 的科学家认为存在重大的可复现性危机。在化工领域,超过 85% 的科学家在复现他人的实验时遭遇过失败,甚至复现自己实验的失败率也超过 60%。
强化学习(RL)
之后,Jolle Pineau 简短地介绍了强化学习的一些背景。在强化学习中,智能体通过采取行动并获取奖励来学习策略。强化学习是用于序列决策的通用框架,智能体可以通过试错从稀疏反馈中学习。大量问题可以通过这一简洁框架得到更好的解决。
强化学习算法已经在围棋和 LIBRTUS 等游戏中取得了令人惊艳的结果。除了游戏以外,强化学习技术还广泛应用于机器人学、电子游戏、对话系统、医疗干预、算法改进、农作物管理、个性化辅导、能源交易、自动驾驶、假肢控制、森林火灾管理、金融交易等诸多领域。
Joelle Pineau 教授还提到她在自适应神经刺激(Adaptive Neurostimulation)方面的研究。她的团队利用 RL 框架,优化用于学习癫痫症的神经刺激设备的超参数。他们遇到的挑战是,这些在模拟环境中训练的 RL 智能体究竟有多可靠以及如何将训练好的模型从模拟环境迁移到现实世界场景。这也是她如此关注可复现性及稳健性问题的主要原因。
策略梯度方法
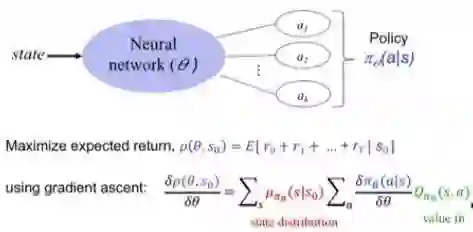
从过去 25 年的强化学习论文直方图可以看出,强化学习研究正处在一个快速增长的时期。2000 年大约有 2000 份论文发表,而到了 2018 年,这一数字超过了 20000。对于我们来说,想要追踪这一领域所有的新技术、新算法是非常困难的,此处我们重点讨论策略梯度方法。策略梯度方法的基本思路是学习某个策略并将其表示为函数,该函数可以通过神经网络或其他回归函数来表示。其目标是最大化采取一系列动作后获得的累积奖励。
Joelle 还列出了 NeurIPS 2018、ICLR 2018、ICML 2018、AAAI 2018、EWRL 2018、CoRL 2018 中关于策略梯度的多数论文,发现大部分论文都使用这几种策略梯度基线算法,即 Trust Region Policy Optimization(TRPO)、Proximal Policy Optimization(PPO)、Deep Deterministic Policy Gradients(DDPG)和 Actor-Critic Kronecker-Factored Trust Region(ACKTR)。
为了评估这四种策略梯度算法的稳健性,Joelle 的团队在 Mujoco 模拟器中的三种不同游戏环境中对其进行测试。他们发现,蓝色曲线在 Swimmer 环境中变化很大。实现有问题?他们带着疑问从在线源代码中选取了 7 个 TRPO 实现,得到了非常令人惊讶的不同结果,DDPG 实验中也是如此。
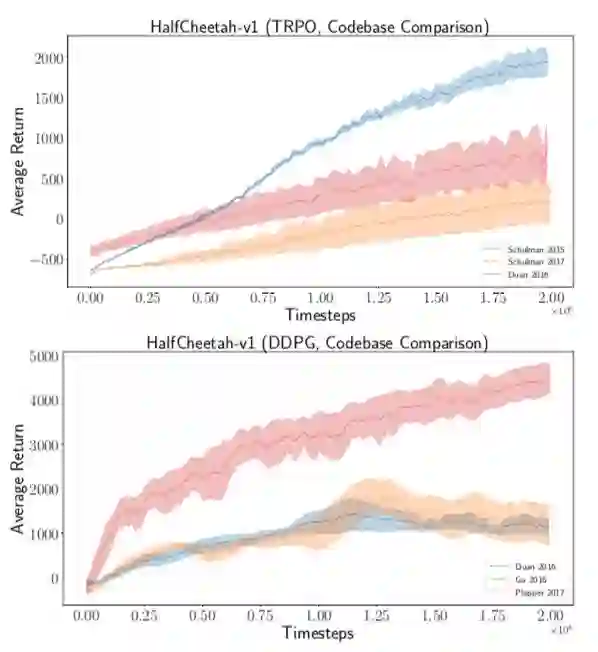
因此他们在不同的策略网络架构、单元激活函数和奖励缩放(reward scaling)、归一化技术等情况下,评估了超参数配置的效果,并再次得到大量的不同结果。Joelle 质疑:可能人们没有动力去寻找令基线模型得到最优性能的超参数配置,只是图方便使用默认的超参数配置。
为了确保对不同方法进行公平合理的对比,Joelle 的团队减少了一些归一化技术,尤其是一些超参数预算。该团队使用最优超参数配置重新运行同样的 TRPO 代码,结果有显著差异,而原因仅仅是 5 个不同的随机种子。或许 5 仍然不够?那么应该试验几次呢?从对近年来其他强化学习论文的研究来看,似乎 5 已经是上限并足够了。Joelle 用讽刺的口吻说道,一些人运行 n 次实验来得到好的结果(n 不是指定的),然后选择 top-5 结果。
这是否意味着强化学习并没有什么用,「深度」只有一点点效果?Jolle Pineau 强调,她并不是暗示人们应该放弃强化学习技术,而是有时候公平对比并不能反映全部情况。
a. 不同的方法有不同的超参数集合。
b. 不同的方法对超参数具备不同的敏感度。
c. 最优方法往往取决于数据/计算预算。
因此研究社区需要仔细思考自己的实验,审慎地报告自己的实验结果。Joelle 还研究了 2018 年的 50 篇强化学习论文(发表在 NeurIPS、ICML、ICLR 上),发现很少有论文进行了有意义的测试。

可复现性检查清单
Joelle 教授提出可复现性检查清单,并鼓励研究社区将该检查清单作为论文提交过程的一部分。
对于论文中的所有算法,检查是否包含:
1. 对算法的清晰描述。
2. 对算法复杂度(时间、空间、样本大小)的分析。
3. 下载源代码链接,包含所有依赖项。
对于论文中的所有理论论断,检查是否包含:
1. 结果陈述。
2. 对假设的清晰阐述。
3. 对理论论断的完整证明。
对于论文中展示实验结果的所有图表,检测是否包含:
1. 对数据收集过程的完整描述,包括样本大小。
2. 数据集或模拟环境可下载版本的链接。
3. 解释训练/验证/测试数据集中的样本分配情况。
4. 解释被排除在外的任何数据。
5. 考虑的超参数范围、选择最优超参数配置的方法,以及用于生成结果的超参数规格。
6. 评估运行次数的确切数字。
7. 对实验运行的具体描述。
8. 对用于报告结果的特定度量或统计数据的清晰定义。
9. 清晰定义的误差棒(error bar)。
10. 包括集中趋势(如平均值)和变化(如标准差)的结果描述。
11. 所用的计算基础设施。
Joelle 解释了基础设施在可复现性中的作用,称即使像分布式计算系统和 CUDA 运算这样的硬件仍然存在可变性空间,因此指明所用的计算基础设施是有帮助的。
Joelle 教授认为可复现性检查清单并不意味着安全保障,但可以作为对研究社区的提醒。例如,在 ICLR 2018 复现挑战赛中,80% 的作者在收到反馈后修改了自己的论文。
强化学习是机器学习中唯一可以在训练集上进行测试的案例吗?
在经典强化学习中,智能体是在同样的任务上进行训练和测试的。而对于通用人工智能(AGI)来说,智能体可在任意事物上进行测试,即整个世界都可以是测试集。
测试泛化性能的一个好方式是分割训练任务和测试任务。有大量研究是基于此的,比如多任务强化学习和元学习。Joelle 提出,我们不需要在那个方向上做进一步研究,但可以选择分离随机训练和测试种子,以带来可变性(variability)。

泛化误差是为训练 RL 智能体而定义的:
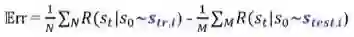
我们评估训练种子的实验回报(empirical return),也要考虑测试种子的实验回报。随着训练过程的进行,训练和测试之间的性能差距会减小。模拟实验证明,只要我们将种子提高到 5 或 10,泛化误差将显著下降。但是这存在一个问题:这么少的种子就可以使我们本质上记住现实世界的某个领域吗?毕竟自然世界非常复杂。
然而,很多强化学习基准非常简单,比如 Mujoco 中的低维状态空间、ALE 中的少量动作等。它们易于记忆,但也易受扰动的干扰。那么如何解决这个问题呢?Joelle 教授提出我们可以寻找一种机制,既保持模拟器的便利性,又囊括一些现实世界的复杂度。
第一个策略是在强化学习模拟训练过程中使用自然世界图像。因为这些图像来自自然世界,因此它们具备我们想要的自然噪声,引入了大量可变性(从观察的角度)。在 MNIST、CIFAR10、CIFAR100 数据集上的实验展示了不错的大型分割。

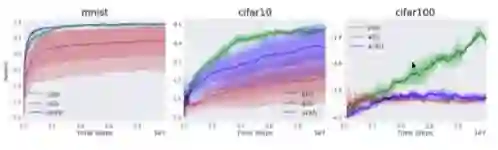
第二个策略是向强化学习模拟添加现实世界视频。例如 Atari 游戏,因为它的背景比较简单,我们可以在背景中添加一些随机的现实世界视频,从而得到来自现实世界的不同训练/测试视频,用来进行清晰的训练/测试分割。

按照这个方向,未来我们有很多事可以做。近期相关的一项研究是来自 Facebook 现实实验室(Facebook Reality Lab)的逼真图像模拟器中的多任务强化学习。
那么回到这个问题:强化学习是机器学习中唯一可以在训练集上进行测试的案例吗?

答案是未必!因为我们可以分别使用随机种子进行训练和测试,可以在强化学习模拟中添加其他图像或视频背景,还可以在逼真图像模拟器中训练多任务强化学习。
最后,Joelle 教授鼓励我们研究现实世界!但是你必须有耐心,因为现实世界需要大量探索。Joelle 教授认为,将科学当成一项竞技体育项目不适用于当下,科学是一项致力于理解和解释的共同努力。