DeepMind ICML 2017论文: 超越传统强化学习的价值分布方法
| 全文共2808字,建议阅读时长3分钟 |
内容来源:DeepMind
转载公众号:机器之心
微信号:almosthuman2014
编译:机器之心编辑部
设想一个每天乘坐列车来回跋涉的通勤者。大多数早上列车准时运行,她可以轻松愉快地参加第一个早会。但是她知道,一旦出乎意料的事情发生:机械故障,信号失灵,或者仅仅是碰到一个雨天,这些事情总会打乱她的模式,使她迟到以及慌张。
随机性是我们日常生活中经常遇到的现象,并且对我们的生活经验有十分深远的影响。但随机性同样在强化学习应用中极其重要,因为强化学习系统需要从试验和错误中学习,并且由奖励驱动。通常,强化学习算法从一个任务的多次尝试中预测它可能收到的奖励期望值,然后再利用这种预测决定下一步的行动。但是环境中的随机扰动会通过改变系统收到的具体奖励量而转变系统的行为。
在新论文中,我们展示了不仅对奖励期望值建模是可能的,同时对奖励所有的变化建模也是存在可能的,我们称之为价值分布(value distribution)。这就令新型强化学习系统要比以前的模型训练更快、更准确,但价值分布更重要的是它有可能启发我们重新思考整个强化学习。
如下图所示,在通勤者案例中假定我们有一段路程,它由三部分组成,每部分需要花 5 分钟。如果我们遇上了一周一次的火车故障,那么我们的路程需要多花 15 分钟。因此我们可以简单地计算平均通勤时间为:(3 x 5) + 15 / 5 = 18 分钟。
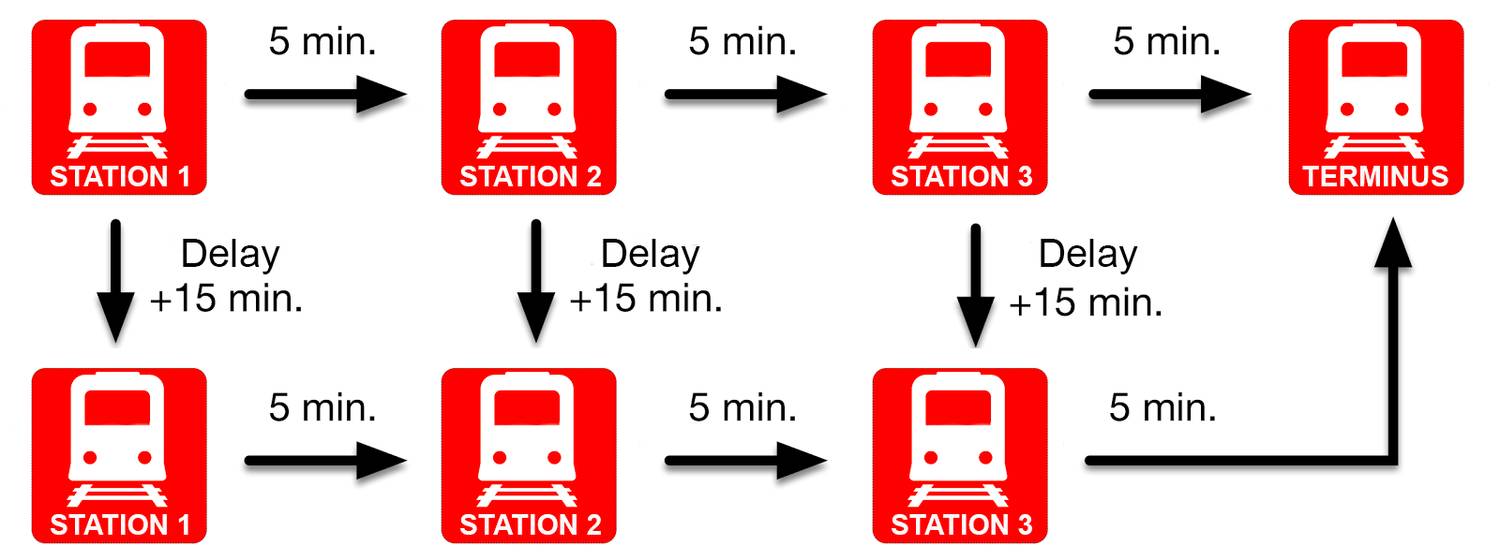
在强化学习中,我们使用贝尔曼方程(Bellman's equation)来预测平均通勤时间。具体来说,贝尔曼方程将我们当前的平均预测结果与未来的平均预测结果联系起来。在第一站,我们预测旅程将持续 18 分钟(总体时间平均数);从第二站开始,我们预测旅程将持续 13 分钟(总平均时间减去第一段路程的时间)。最后,假设火车没有停下来,那么在第三站,我们预测距离我们到达目的地还有 8 分钟(13 - 5)。贝尔曼方程使得每一次预测按顺序进行,并在新信息的基础上更新预测结果。
关于贝尔曼方程有一点反常之处在于我们事实上从未观察到这些预测的平均值:火车要么是开了 15 分钟(5 天里有 4 天皆是如此),要么是 30 分钟,从来不会出现 18 分钟!单纯从数学的角度来看,这不算问题,因为决策论(decision theory)告诉我们仅需要平均值即可做出最佳选择。因此,这个问题在实践中往往被忽略。但是,现在大量经验证明预测平均值是一件复杂的事。
从我们的经验数据来看,从分布视角(distributional perspective)更易构建更好、更稳定的强化学习模型。
在新论文中,我们表示事实上有一个贝尔曼方程的变体能预测所有可能性输出,且不是它们的平均值。在我们的示例中,主要主张两个在每个站台分布的预测:如果行程顺利,在每一站时间分别需要 15、10,然后是 5 分钟;如果火车坏掉,时间分别是 30、25 分钟,最后是 20 分钟。
从这种观点来看,所有的强化学习都可被重新解释,其应用也已经带来惊人的理论性成果。预测输出的分布也启发了各种类型算法的可能性,比如:
解开随机性的原因:一旦我们观察到通勤时间呈现双峰态势,即有两个可能的值,那么我们可以基于该信息采取行动,如在离家之前检查火车的状态更新;
分隔安全与危险的选择:如果两个选择的平均结果相同(如走路或乘坐火车),那么我们可能选择风险或变动最小的一项(如走路)。
自然辅助预测:实验证明,预测多个结果的分布(如通勤时间的分布)对更快速地训练深度网络很有益处。
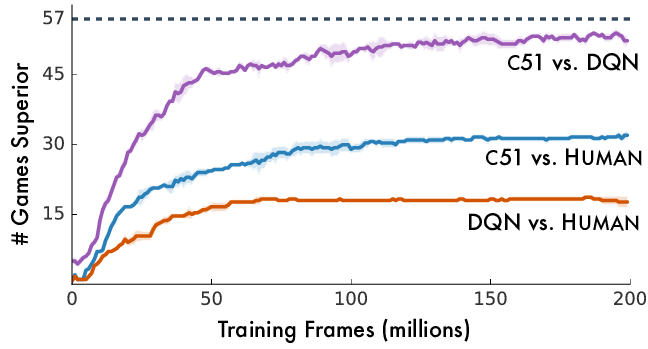
我们采用了新想法,并在深度 Q 网络智能体中实现了它们,将其单一奖励期望值输出替换为一个带有 51 个可能值的分布。另外的一个变化是新的学习规则,反映了从贝尔曼(平均)方程到其分布式对应物的转化。难以置信的是,结果证明这种转化是我们超越所有其他方法所需要的全部。下图展示了我们如何在 25% 的时间获得 75% 的已训练的深度 Q 网络的性能,且远超人类。
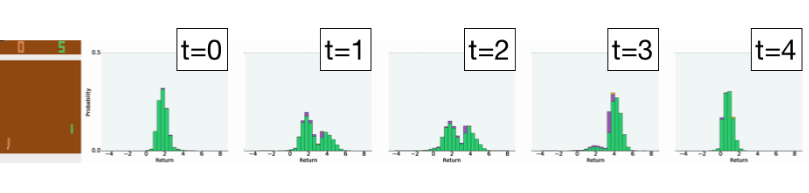
一个令人惊讶的结果是我们发现了 Atari 2600 游戏中的一些随机性,即使底层游戏模拟器 Stella 本身是完全可预测的。这种随机性的出现部分是由于我们所谓的局部可观察性(partial observability):由于模拟器的内在编程,玩乒乓球的智能体无法预测其得分增加的精确时间。通过可视化智能体对连续帧的预测(如下图),我们看到两个单独的输出,(低和高),反应了可能的时间。尽管这种内在的随机性并未直接影响性能,但结果指出了智能体在理解方面存在的局限性。
随机性也会发生由于智能体的自身行为是未确定的。在太空入侵者中,我们的智能体学习预测未来发生失误并输掉游戏的概率(零奖励)。
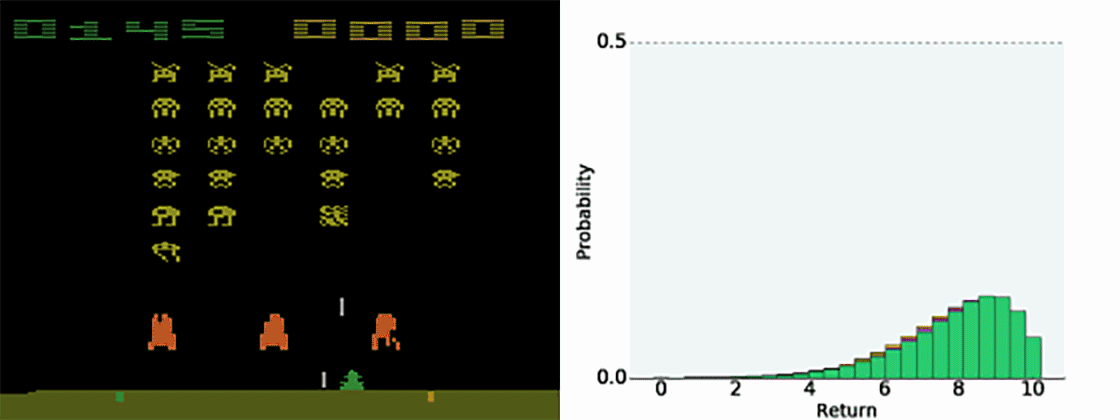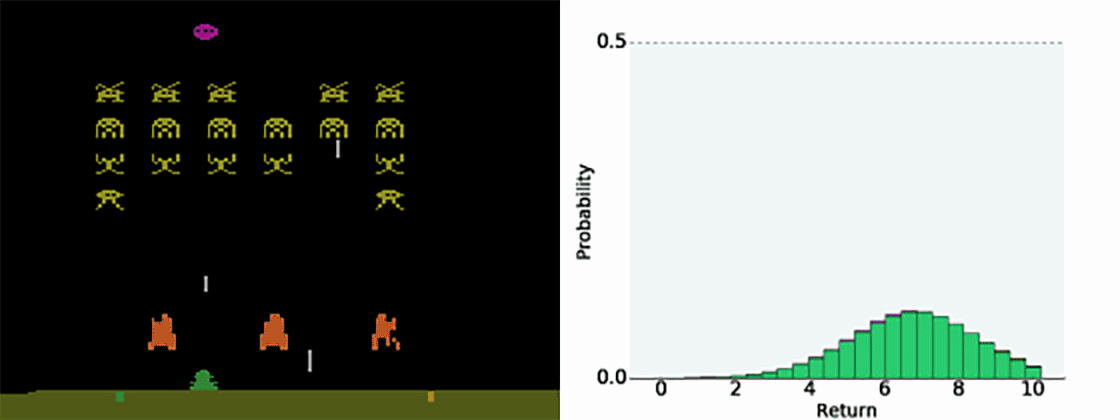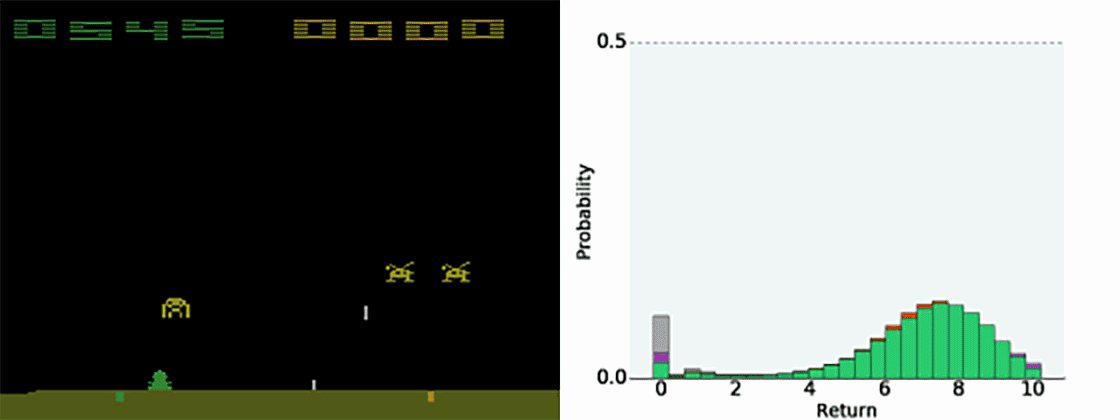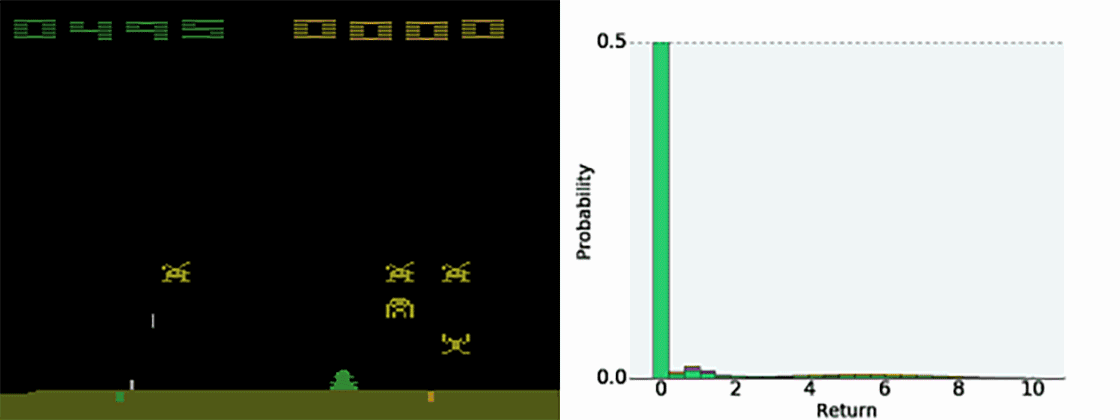
正如我们的训练过程实例,它为那些截然不同的结果保留各自的预测,而不是将其总计为一个不可平衡的平均数。事实上,我们认为我们获得提升的结果很多一部分来自智能体建模其自身随机性的能力。
从我们的结果可以看出,分布视角带来了更好、更稳定的强化学习。现在每一个强化学习概念都可能需要从分布视角下重新思考,也许它只是这一方法的开端。
论文:A Distributional Perspective on Reinforcement Learning

论文链接:https://arxiv.org/abs/1707.06887
摘要:本篇论文中,我们对价值分布的基本重要性——强化学习体接收到的随机返回值的分布,进行了讨论:这与强化学习的常见方法(对返回值的期望或值进行建模)形成了对比。尽管资料库的建立实现了对值分布的研究,它却也因此经常用于一种特定的用途,比如实施风险性意识行为(risk-aware behaviour)。我们以策略评估和控制环境的理论结果作为开端,对显著的分布不稳定性进行了揭露。随后使用分布的视角设计了一种新的算法——应用贝尔曼方程来学习近似值分布。我们使用了街机模式学习环境(Arcade Learning Environment)的游戏套件测试了我们的算法。我们得到了一流的结果以及能说明近似强化学习的值分布重要性的证据。最后,我们结合理论和实际的依据,强调了在近似环境中值分布影响学习的方式。

有缘的人终会相聚,慕客君想了想,要是不分享出来,怕我们会擦肩而过~
《【调查问卷】“屏幕时代,视觉面积与学习效率的关系“——你看对了吗?》
本文编辑:慕编组成员(小端午)



