业务不中断,PXC集群单机多实例拆分消除数据库隐患

作者介绍
刘书浩,中国移动DBA,负责“移动云”业务系统的数据库运维、标准化等工作;擅长MySQL技术领域,熟悉MySQL复制结构、Cluster架构及运维优化;具有自动化运维经验,负责“移动云”数据库管理平台的开发和部署。
过去两年,我主要从事“移动云”数据库的运维工作,有幸见证了“移动云”的快速发展,每当接维一个新的资源池,通常需要先进行标准化方面的工程改造,目的是以统一的标准体系开展后续的维护工作。通过大大小小的工程变更,积累了一些实践经验,下面我跟大家分享一个PXC集群单机多实例拆分的工程案例。
一、案例背景
通常情况下,根据业务垂直切分原则,不同业务数据库需要单独部署,一个MyQL实例不可存放多个业务库。但在某些特殊情况下,比如:物理机资源紧张、业务上线压力大等情况,部署阶段工程人员可能会将两个不同子系统数据库部署在同一物理机甚至同一实例,以节省资源、加快实施进度。这样造成的结果是业务耦合性过高,一旦出现问题会殃及池鱼,增加了故障定位的难度。
我们生产环境就曾经发生过因CLM系统问题引发数据库实例锁,导致移动云华中节点OP门户无法加载、客户无法订购云产品的故障。
为消除数据库存在的安全隐患,我们决定采用多实例的方法解决,在带业务的情况下对两个子系统(OP和CLM)数据库实例进行拆分,拆分完成后一个系统将对应一个业务库,互不干扰。在正式阐述变更方案之前,先简单介绍下 “移动云”生产环境使用的MySQL集群以及业务系统名称。
PXC,即Percona XtraDB Cluster,Percona的一个MySQL分支版本,是一个可以实时同步的MySQL集群,基于广播write set和事务验证来实现多节点同时commit、冲突事务回滚等功能,具有强数据一致性。
“移动云”管理域数据库是在PXC架构基础上进行封装,而PXC又是以开源Galera Cluster为基础,为表述方便,本文用PXC或Galera集群代替定制化产品名称。
OP:“移动云”门户系统,用户通过登录OP门户网站进行相关云产品的订购和使用 ,具有用户自服务能力。
CLM:资源池管理平台,目前用于性能数据采集、监控和告警传递。
二、PXC集群单机多实例拆分
最初考虑了两个方案:
方案一是在物理机上开启两台虚拟机分开部署OP和CLM数据库 ,因为需要安装虚拟机并重新部署PXC集群,业务中断的时间会比较长;
方案二是物理机上拆分不同实例,重新规划端口号、程序目录、PID、SOCKET文件路径。如果采用“先扩容再主动分裂集群的方式”基本可以保证在线情况下OP业务不受影响,但CLM系统性能数据会有少部分缺失,该方案中断业务时间短,正常情况下不超过15分钟。
从业务影响角度考虑,最终选择了方案二,下面介绍下实例拆分的实施过程。
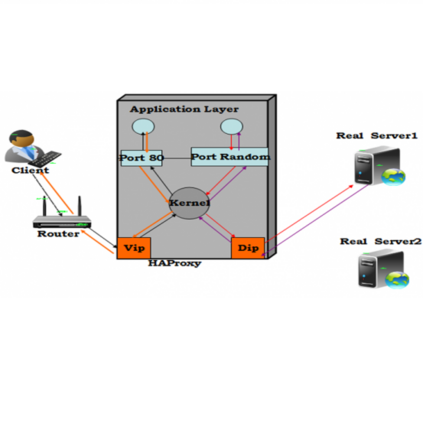
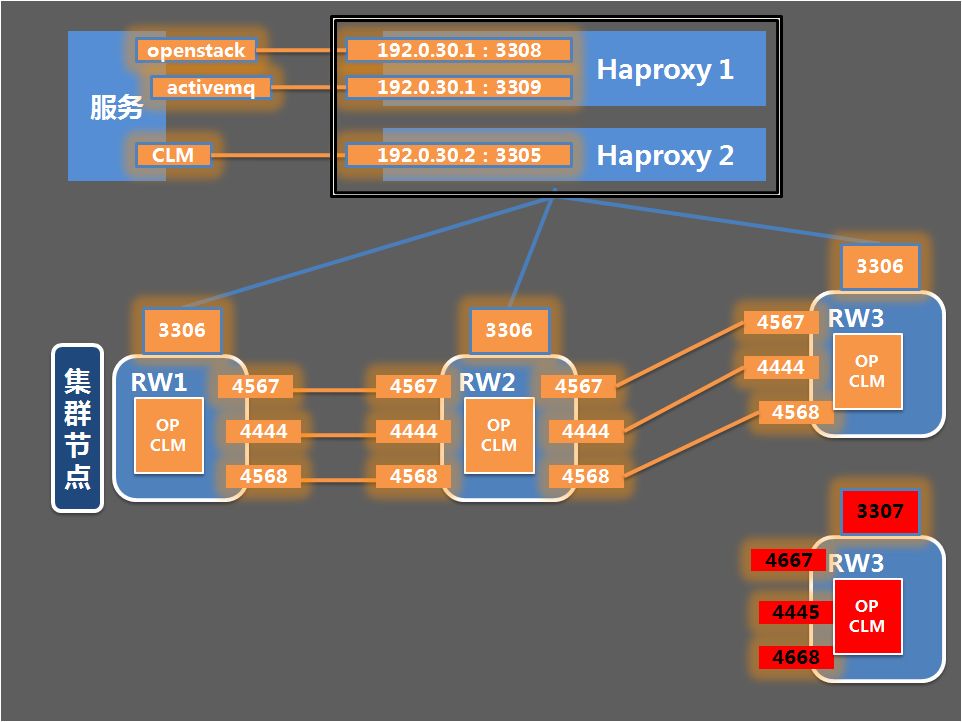
首先看一下变更实施前“移动云”华中节点OP、CLM数据库部署情况,从下图可以看到两个子系统数据库部署在同一实例,业务耦合度高:
“移动云”生产环境PXC集群默认配置为多主的方式,每个节点都可以提供读写服务,不支持程序内指定实际物理IP,应用程序通过HAproxy负载均衡组件指定VIP连接数据库,如上图中openstack和activemq为OP相关服务,与CLM服务通过不同的虚拟IP和服务端口号进行区分,结合上层HAproxy+Keepalived可以实现集群的高可用。数据库对外服务端口为3306,集群成员之间的通信端口为4567,集群节点SST和IST专用端口分别为4444和4568 ,各节点使用TCP/IP协议通信。
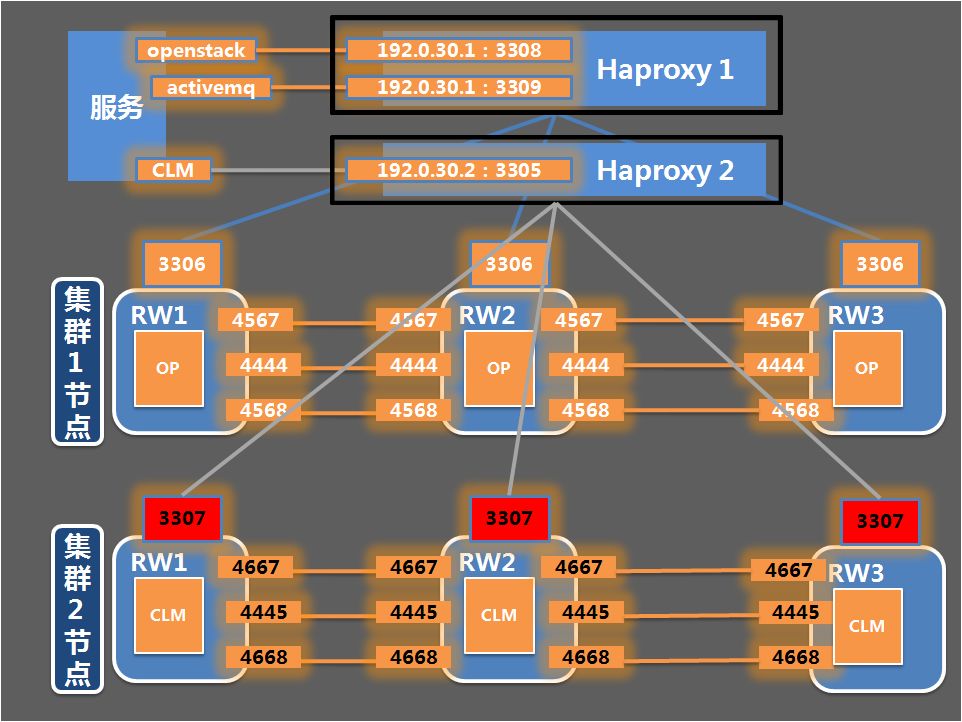
垂直切分,按业务分类进行拆分,OP系统后端数据库保留在原实例中,CLM系统数据库迁移到新实例中;
方案采用“先扩容再主动分裂集群的方式”,改造过程中尽量保证OP业务不受影响。
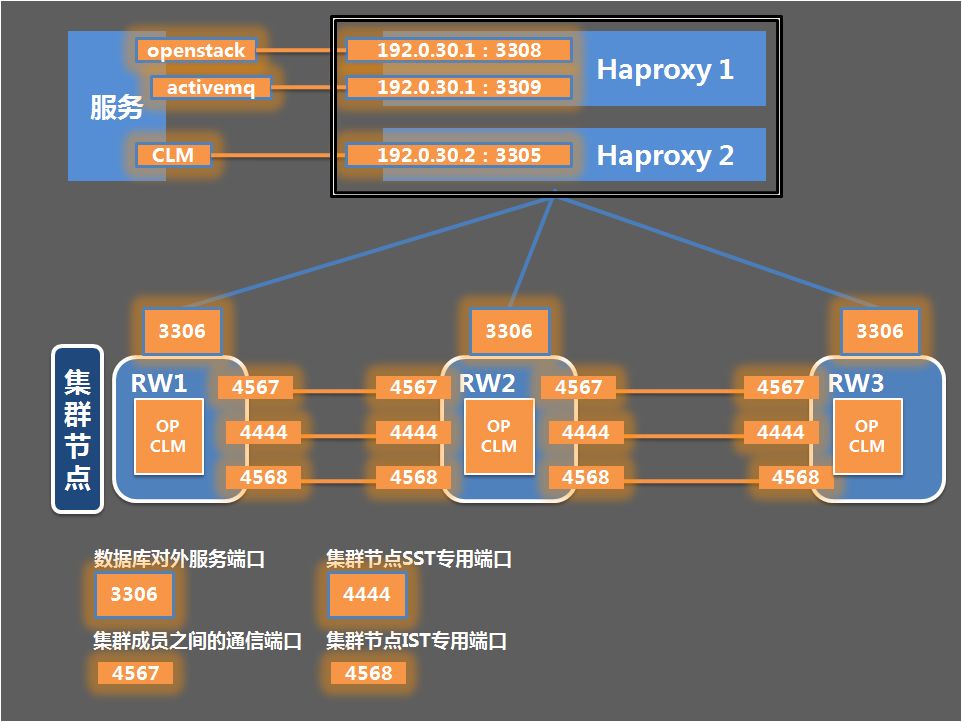
通过修改数据库配置文件,保留OP实例原来的端口设计,拆分出来的CLM实例采用新的内外端口,以此来区分同一物理机上两个不同的数据库实例,具体如下:
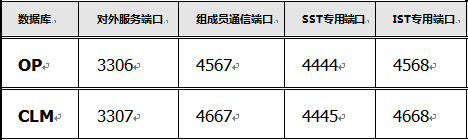
数据库对外服务的端口:OP实例的端口是3306,CLM实例的端口是3307;
集群组成员的沟通端口:OP实例的端口是4567,CLM实例的端口是4667;
SST专用端口:OP实例的端口是4444,CLM实例的端口是4445;
IST专用端口:OP实例A的端口是4568,CLM实例的端口是4668。
另外,还需要修改HAproxy配置文件中CLM数据库的访问端口,将CLM数据库实例的对外服务端口修改为3307:
OP实例沿用原有标准化目录,CLM实例相关的数据目录、日志目录、程序目录、软连接、pid、socket文件路径要重新指定,如下表所示:
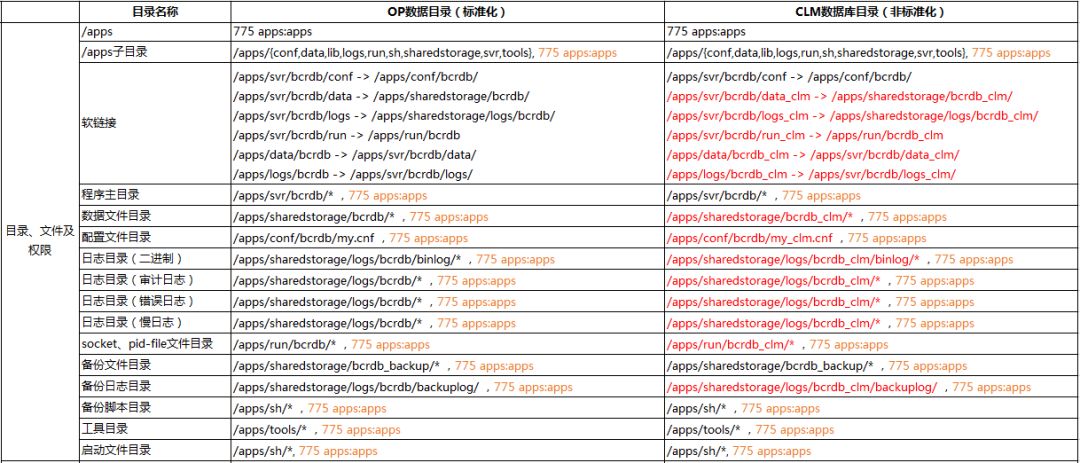
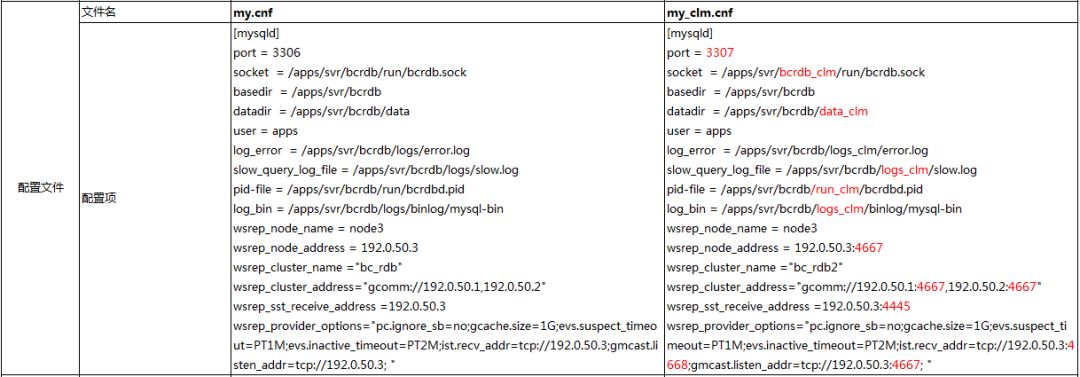
保留OP实例原my.cnf配置文件,为CLM实例创建新的配置文件my_clm.cnf,在配置文件中对mysql内外端口、数据目录、日志目录、pid、socket文件路径等参数进行重新配置,如下表所示:
要注意的是启动方式有所变化,因为需要维护两个配置文件,所以OP和CLM不能都采用原方式启动,启动CLM cluster的时候,需要指定新的配置文件,例如:
初始化集群首节点:
mysql_safe --defaults-file = /apps/conf/bcrdb/my_clm.cnf --wsrep-new-cluster &
集群次节点:
mysql_safe --defaults-file = /apps/conf/bcrdb/my_clm.cnf &
集群次节点:
mysql_safe --defaults-file = /apps/conf/bcrdb/my_clm.cnf &
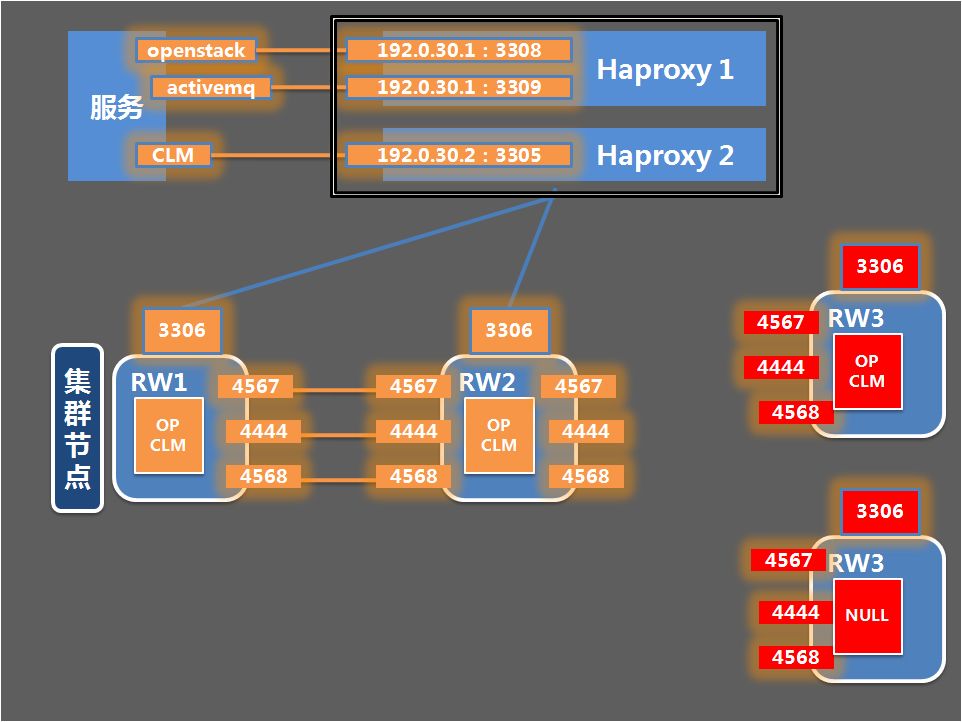
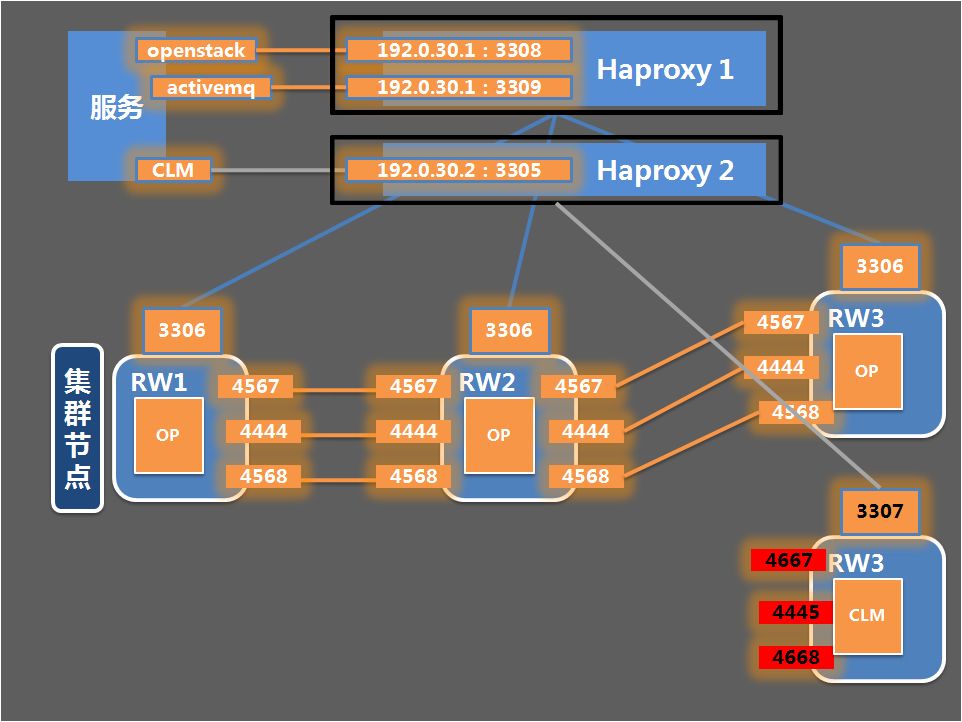
Step 1:登录RW3节点,为拆分出来的CLM数据库实例创建目录、软连接,并编写配置文件my_clm.cnf,重新规划内、外端口以及PID、SOCKET文件路径,完成后关闭RW3节点数据库进程,如下图所示:
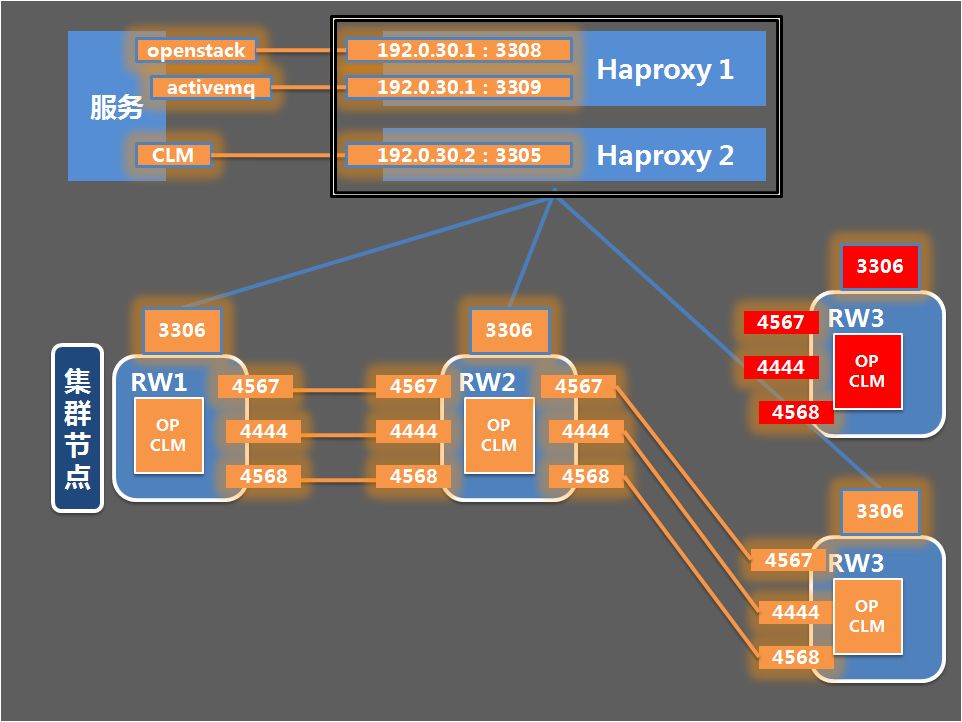
Step 2:同步数据,启动新的CLM数据库实例与原集群RW1、RW2节点进行数据同步(SST),这里需要注意的是,启动CLM实例时需指定原配置文件 mysql_safe --defaults-file = /apps/conf/bcrdb/my.cnf,从而保证拆分出来的CLM实例可以加入原有集群进行数据同步。
Step 3:恢复OP数据库集群状态,CLM实例完成数据同步后,使用命令:mysqladmin --defaults-file = /apps/conf/bcrdb/my.cnf -uroot -p shutdown关闭CLM实例进程,启动OP数据库RW3节点,恢复OP数据库集群状态。
Step 4:修改HAproxy配置文件,使CLM实例以3307端口对外提供服务,从而将CLM实例彻底从原集群拆分出来,启动CLM集群第一个节点RW3时需指定my_clm.cnf配置文件:
mysql_safe --defaults-file = /apps/conf/bcrdb/my_clm.cnf --wsrep-new-cluster &
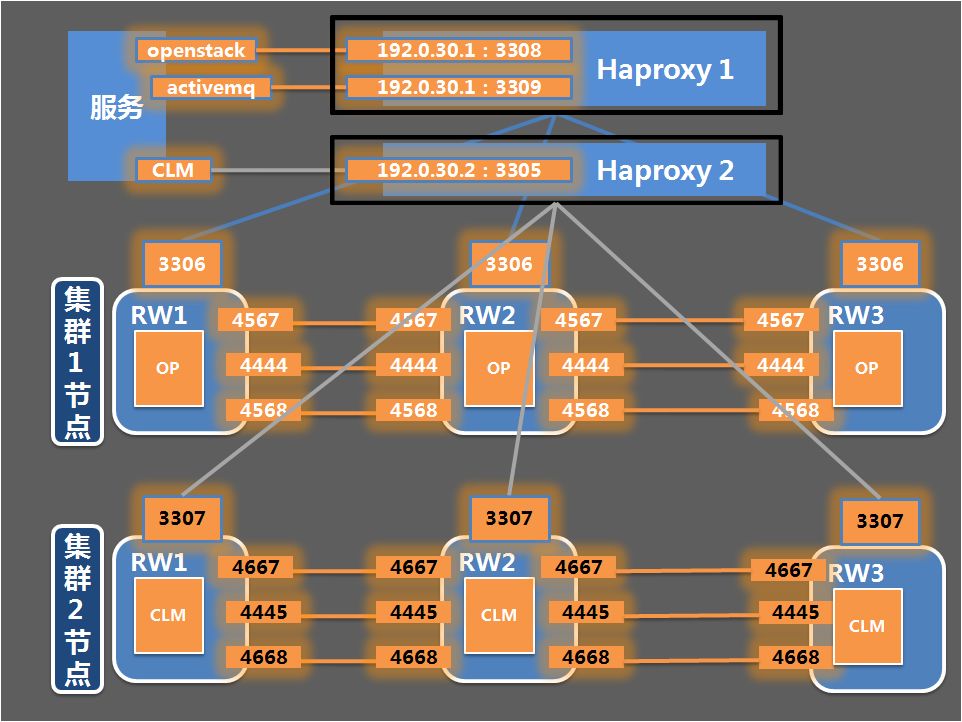
Step 5:重复步骤1到4,完成CLM cluster的启动,注意启动CLM实例RW1、RW2节点时启动命令有所不同:mysql_safe --defaults-file = /apps/conf/bcrdb/my_clm.cnf &,并且需要根据集群节点信息的不同先调整my_clm.cnf参数配置。
Step 6:修改自动化运维脚本,由于CLM实例拆分出来后,配置文件名称、数据目录有所不同,需要在备份、巡检和监控脚本中进行相应调整,比如备份脚本需进行如下修改:
full_backup()
{
echo "$(date +%F\ %T) start full backup..."
innobackupex --defaults-file=/apps/svr/bcrdb/conf/my_clm.cnf
--slave-info
--galera-info
--user=$bakuser
--password=$bakpwd
--no-timestamp
--kill-long-query-type=select
--kill-long-queries-timeout=20
--rsync --history=${bakname} ${bakdir}/${bakname}_full
[ $? -ne 0 ] && echo "$(date +%F\ %T) backup failed!" && exit 1
echo "$(date +%F\ %T) backup complete!"
}
incr_backup()
{
lastname=`$mysqlcmd "select name from xtrabackup_history where is_success='Y' and name like 'BCRDB_BC_CLM%' order by end_time desc limit 1"`
if [ "$lastname" != "NULL" ] && [ -n "$lastname" ] ;then
echo "$(date +%F\ %T) start incremental backup since $lastname..."
innobackupex --defaults-file=/apps/svr/bcrdb/conf/my_clm.cnf
--slave-info
--galera-info
--user=$bakuser
--password=$bakpwd
--no-timestamp
--kill-long-query-type=select
--kill-long-queries-timeout=20
--rsync --history=${bakname}
--incremental --incremental-history-name=$lastname ${bakdir}/${bakname}_incr
[ $? -ne 0 ] && echo "$(date +%F\ %T) backup failed!" && exit 1
echo "$(date +%F\ %T) backup complete!"
else
echo "$(date +%F\ %T) there is no backup history, cann't start incremental backup, start full backup instead..."
full_backup
fi
}
Step 7:创建crontab:
备份执行计划:30 2 * * * /apps/sh/backup_clm.sh -d 60 -n bcclm -t auto>/apps/sharedstorage/logs/bcrdb_clm/backuplog/backup_$(date '+\%Y\%m\%d_\%H\%M\%S').log 2>&1
Zabbix监控执行计划:*/1 * * * * /usr/zagt/zabbix_scripts/zbx_mysql_status.sh > /dev/null
通过以上步骤就完成了OP和CLM数据库的实例拆分,实现了PXC集群单机多实例部署,经测试OP业务未受影响,CLM因数据库中断丢失少量性能数据,端口的更改并没有导致网络问题。
三、结语
工程变更前期方案准备非常重要,特别是带业务进行操作,要预计到可能发生的问题点,并进行充分的测试,把每个操作细节都确定下来,整理为操作命令集合,并准备好回退方案。
本次变更大概用了一个月的时间进行准备,变更是在晚上10点后业务低谷期进行,各业务负责同事也参与其中,变更期间他们随时准备处理突发情况,从而保证变更操作的顺利完成。

更多数据库运维相关探索与实战,尽在2018 Gdevops全球敏捷运维峰会北京站!峰会议题覆盖AIOps演进、DevOps落地、数据库选型、SQL优化、技术管理等多方面实战,全方位为你充电!
↓↓↓ 扫描二维码了解更多详情 ↓↓↓