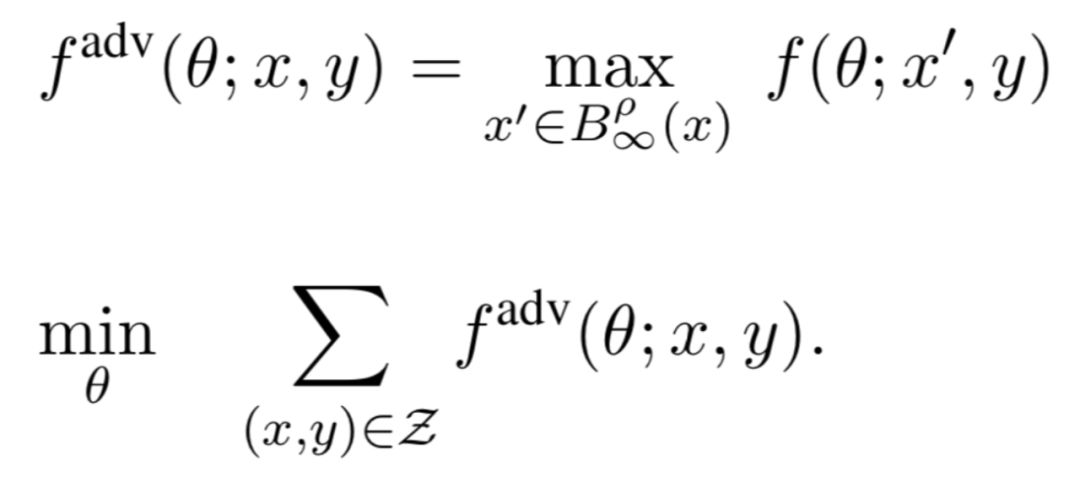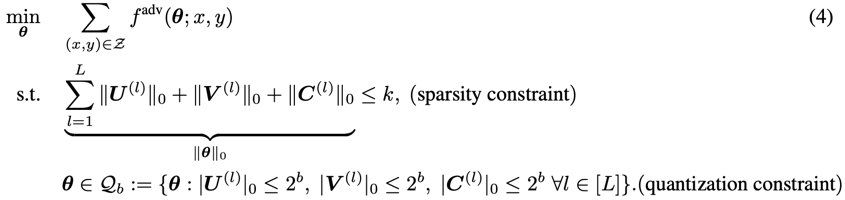四篇NeurIPS 2019论文,快手特效中的模型压缩了解一下
机器之心报道
作者:思
从改进最优化器到多智能体团队协力,这些最前沿的 NeurIPS 2019 研究,你都可以在快手上找到它们的身影。
快手在 NeurIPS 2019
在快手做研究
研究框架用什么?
论文代码要开源?
模型压缩在快手
模型压缩这条逻辑线
优化器:「有些参数生而冗余」
从数学看优化器
对抗训练:「我也能变压缩」
从数学看对抗与压缩
论文:Adversarially Trained Model Compression: When Robustness Meets Efficiency
地址:https://papers.nips.cc/paper/8410-model-compression-with-adversarial-robustness-a-unified-optimization-framework
论文:Global Sparse Momentum SGD for Pruning Very Deep Neural Networks
地址:https://papers.nips.cc/paper/8867-global-sparse-momentum-sgd-for-pruning-very-deep-neural-networks
论文:LIIR: Learning Individual Intrinsic Reward in Multi-Agent Reinforcement Learning
地址:https://papers.nips.cc/paper/8691-liir-learning-individual-intrinsic-reward-in-multi-agent-reinforcement-learning
论文:Efficient Smooth Non-Convex Stochastic Compositional Optimization via Stochastic Recursive Gradient Descent
地址:https://papers.nips.cc/paper/8916-efficient-smooth-non-convex-stochastic-compositional-optimization-via-stochastic-recursive-gradient-descent


-
自动发现每层合适的稀疏率 :如果 DNN 中的某一层对剪枝比较敏感,GSM 会对该层权重执行更「轻」的剪裁。也就是说,给定全局压缩率作为唯一目标,GSM 能够根据每层的敏感性自动选择合适的剪枝比率。 发现更好的 winning lottery tickets:ICLR 2019 最佳论文 The Lottery Ticket Hypothesis 表明,如果有些参数在训练后的网络中显得很「重要」,它们很可能在随机初始化后就是「重要」的。即在初始化的网络中存在某些稀疏子结构,单独训练这样的子结构可以得到与训练整个网络相媲美的性能,GSM 就能找到更好的稀疏子结构。
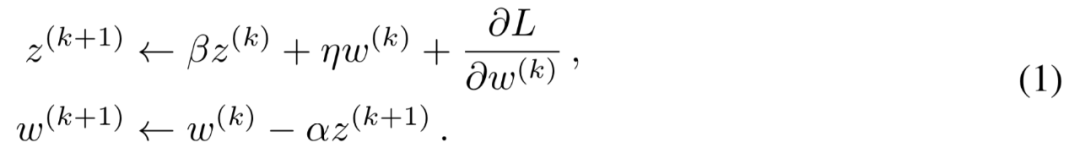
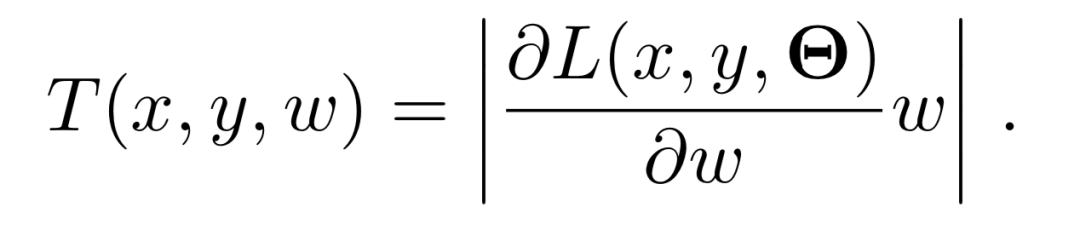
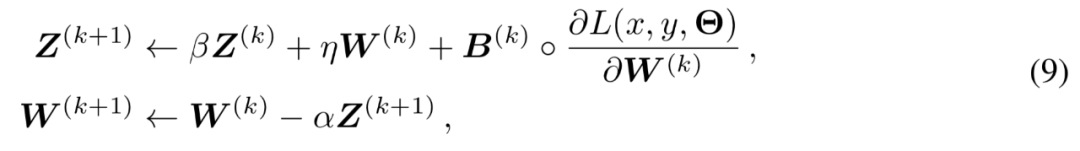

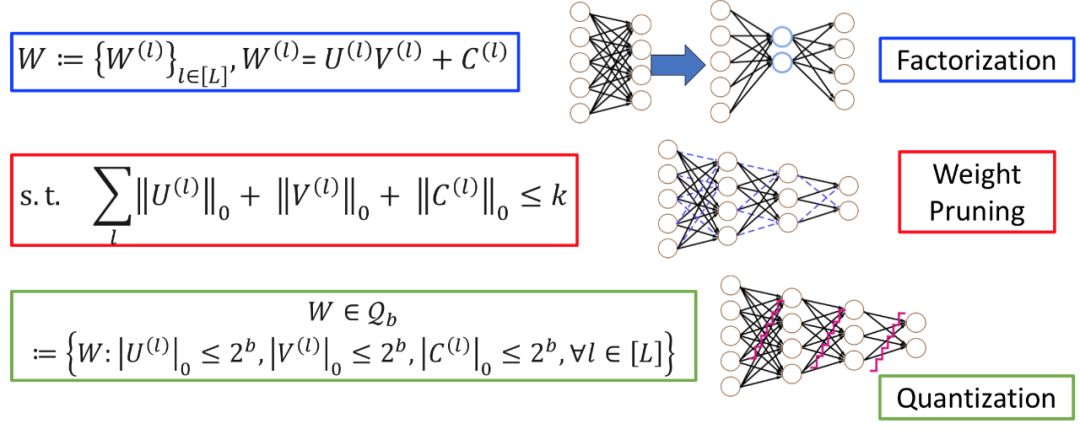
ATMC 以对抗性训练问题作为优化目标(极小化极大优化问题);
研究者将结构化的权重分解、元素级的稀疏化剪枝、以及模型权重量化作为整个优化问题的约束;
研究者证明 ADMM 算法可以有效解决带有约束的极小化极大优化问题,并得到具有紧凑性和鲁棒性的模型。