红楼梦、法律,BERT 已有如此多的神奇应用
机器之心原创
作者:曾祥极
编辑:Hao Wang
2019 年 5 月 ACM 图灵大会上,朱松纯教授(加州大学洛杉矶分校)与沈向洋博士(微软全球执行副总裁)在谈到「人工智能时代的道路选择」这个话题时,沈向洋博士认为人工智能发展在工业界将会迎来黄金十年,而朱松纯教授也表示人工智能的发展趋势将会走向大一统,从小任务走向大任务,从 AI 六大学科走向统一。
自然语言处理领域的 BERT 模型恰好印证了这一规律,BERT 尝试着用一个统一的模型处理自然语言处理领域的经典任务,如阅读理解、常识推理和机器翻译等任务。事实证明,自从谷歌于去年十月发布 BERT 之后,BERT 便开始了漫长的霸榜之路,在机器阅读理解顶级水平测试 SQuAD1.1 中 BERT 表现出了惊人的成绩,全部两个衡量指标上全面超越人类,并且还在 11 种不同 NLP 测试中创出最佳成绩,包括将 GLUE 基准推至 80.4%(绝对改进 7.6%),MultiNLI 准确度达到 86.7%(绝对改进率 5.6%)等。虽然近段时间不断有后起之秀在各种指标上超过了这一经典,但这只是架构上的小修小改。毫无疑问,BERT 开启了自然语言处理领域一个崭新的时代。
最近发布的 XLNet 在多个方面超越了 BERT,但是 BERT 语言模型与现有领域,如法律文书、科研论文,的交叉应用实例,对于 XLNet 的应用仍有非常大的意义。
本文作者是曾祥极,目前在浙江大学读硕士,方向是常识推理和AutoML,希望能和大家一起共同学习,探讨科研论文等。
1. 介绍
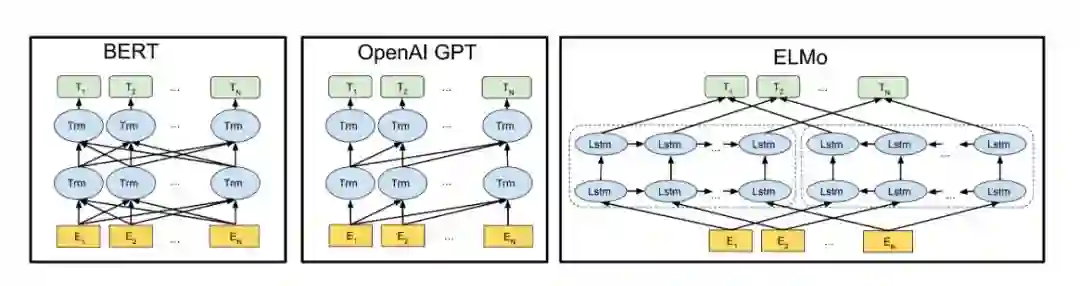
BERT、GPT 与 ELMo 模型架构图,来源 https://arxiv.org/abs/1810.04805
近十年,深度学习的复兴给自然语言处理领域带来了翻天覆地的变化,特别是 2013 年简化版词嵌入 word2vec 的提出为深度学习在自然语言处理领域的应用打下了铺垫。由于神经网络是基于张量空间的数值计算,因此神经网络不能良好地表示自然语言文本。自然语言文本与神经网络之间需要一个桥梁来完成这一转换,而词嵌入就是这个桥梁,词嵌入可以将自然语言文本转化成语义空间上低维的稠密数值向量。但是经过词向量转换后的句子表示在整个语义层面上仍然有着较大地缺陷,因为词嵌入无法有效地解决一词多义的问题。
语言预训练模型从另一个思路尝试着解决上下文环境语义表示的问题。互联网上拥有海量的文本数据,然而这些文本大多都是没有标注的数据,AllenNLP ELMo 模型的提出解决了从这些海量的无标记文本数据中获取上下文语义表示的问题。但是受限于 LSTM 的能力,ELMo 模型只是一个使用了三层 BiLSTM 的网络模型,按照传统观点,深度学习模型要想捕捉更精确的语义表示就需要将模型网络层数做得更深。
OpenAI GPT 模型解决了这个问题,GPT 采用 Transformer 的编码层作为网络的基本单元,Transformer 舍弃了 RNN 的循环式网络结构,完全基于注意力机制来对一段文本进行建模,从而可以将网络模型做得更深。除此之外,Transformer 还解决了 RNN 不能并行计算的缺点,这对减少模型训练的时间以及加大训练数据集带来了可能性。
BERT 则在此基础上更进一步,相比于 GPT 对句子从左到右的单向扫描,BERT 模型的每个词语可以感知两侧的语境,从而可以捕捉更多的信息。BERT 采用了两个超大的数据集:BooksCorpus(800M words) 和 English Wikipedia(2500M words) 进行预训练。因此,可以说 BERT 拥有了某种程度上的语言语义理解能力。BERT 可以作为其它任务网络模型的上游骨架,它可以很好的抽取任务数据的语义表示向量,我们只需要在上面进行微调即可获得很好的效果,这衍生出了许多神奇的下游应用。
2. 应用
2.1. 红楼梦知识提取
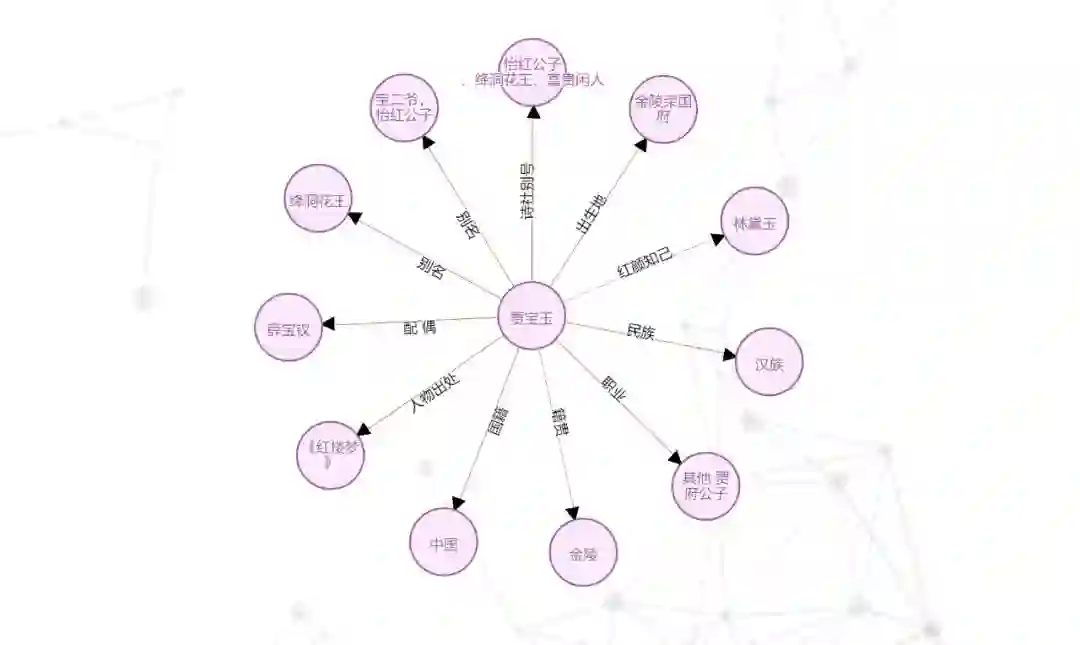
红楼梦人物知识图谱,来源 http://kw.fudan.edu.cn/
知识图谱是人工智能研究中的核心问题,它是人类对世界的近似表示与理解,能够赋予机器精准查询、理解与逻辑推理等能力。知识图谱相关的技术主要分为三个部分:知识提取、知识表示和知识应用。知识提取主要负责从各种结构化和非结构化的信息中抽取实体和关系即构建知识图谱,知识表示则是研究如何更好地表示知识,知识应用则是利用已经构建好的知识图谱为各种下游任务赋能,赋予机器理解世界的能力。
知识图谱也能够辅助我们快速了解小说的人物关系,对于没有仔细读过红楼梦或者是读得似懂非懂的同学们来说,我们可以利用 BERT 搭建起知识提取的机器学习模型提取红楼梦中的人物即实体,并分析人物与人物之间的关系,这对我们快速了解小说人物结构非常有帮助。有一位作者利用 BERT 对红楼梦进行了一个简单的人物知识图谱建模,接下来我们将会详细说明作者是如何从红楼梦中抽取人物和关系。
1)数据准备:作者首先利用正则表达式从红楼梦提取对话,如果假设说出这段话的人的名字出现在这段话的前面,那么可以用这段话前面的一段话作为包含说话人(speaker)的上下文(context)。如果说话人不存在这段上下文中,标签为空字符串。目前效果较好的实体抽取模型多为监督学习的模型,所以基于 BERT 的实体抽取模型也采用有监督的方法训练模型。因此,作者对之前抽取的对话进行实体标注。除此之外,由于实体之间 de 关系抽取技术还不太成熟,因此作者做了一个很简单的假设,把相邻的人看作是在对话,这在一定程度上是可以成立的。标注数据的部分结果如下:
{'uid': 1552, 'context': '黛玉又道:', 'speaker': '黛玉', 'istart': 0, 'iend': 2}
{'uid': 1553, 'context': '因念云:', 'speaker': None, 'istart': -1, 'iend': 0}
{'uid': 1554, 'context': '宝钗道:', 'speaker': '宝钗', 'istart': 0, 'iend': 2}
{'uid': 1555, 'context': '五祖便将衣钵传他.今儿这偈语,亦同此意了.只是方才这句机锋,尚未完全了结,这便丢开手不成?"黛玉笑道:', 'speaker': '黛玉', 'istart': 46, 'iend': 48}
{'uid': 1556, 'context': '宝玉自己以为觉悟,不想忽被黛玉一问,便不能答,宝钗又比出"语录"来,此皆素不见他们能者.自己想了一想:', 'speaker': '宝玉', 'istart': 0, 'iend': 2}
{'uid': 1557, 'context': '想毕,便笑道:', 'speaker': None, 'istart': -1, 'iend': 0}
{'uid': 1558, 'context': '说着,四人仍复如旧.忽然人报,娘娘差人送出一个灯谜儿,命你们大家去猜,猜着了每人也作一个进去.四人听说忙出去,至贾母上房.只见一个小太监,拿了一盏四角平头白纱灯,专为灯谜而制,上面已有一个,众人都争看乱猜.小太监又下谕道:', 'speaker': '小太监', 'istart': 103, 'iend': 106}
{'uid': 1559, 'context': '太监去了,至晚出来传谕:', 'speaker': '太监', 'istart': 0, 'iend': 2}
虽然作者花了两个小时标注了 1500 条左右的数据,然而这对于模型的训练仍然显得有些不足,所以作者又利用数据增强技术扩增到两百万条数据。
2)模型:作者构建实体抽取模型的思路是把实体抽取任务看成 QA 问题,即问题是对话语句而答案是抽取的实体,因此作者基于 BERT 并仿照阅读理解任务 SQuAD 上的模型做了实体抽取模型。
3)预测结果:由于 BERT 模型的强大,通过简单的问答训练,作者发现实体抽取的效果非常好,只有少部分出现问题,以下是部分预测结果:

4)人物关系:至于人物实体关系的抽取,作者则根据之前的假设,利用规则对人物关系进行了分析。其中,宝玉与袭人之间对话最多(178+175),宝玉与黛玉之间对话次之(177+174),宝玉与宝钗之间对话(65+61),仅从对话次数来看,袭人与黛玉在宝玉心目中的占地差不多,宝钗(65+61)占地只相当于黛玉的三分之一,略高于晴雯(46+41)。
最后,作者在 gitlab 上上传了自己的代码 https://gitlab.com/snowhitiger/speakerextraction。
2.2. 情报检测

飓风,来源:https://www.apnews.com/b4a51136559d44f589319ecfbf6f11a9
随着互联网用户的不断增加,互联网上的信息已经达到了不可能靠人力就能处理的地步,这其中情报信息的检测也变得十分重要。灾难信息是属于情报信息的一种,它是在灾害和其他紧急情况的准备,缓解,响应和恢复阶段使用信息和技术的研究,比如爆炸检测、情感分析和危害评估等。
诸如 Facebook、Twitter 等社交网站上的灾难信息如果得不到有效的检测,那么这将是一个极大的安全隐患。传统的灾难信息检测是基于关键词过滤的方法,但是这种方法具有很大的问题,一是灾难信息的组织形式在不断发生变化,二是仅靠社交公司有限的人力根本不可能有效地维护关键词语料库。
Guoqin Ma 提取了基于 BERT 的机器学习模型对灾难信息进行处理,他将推特上的灾难信息处理看作是文本分类问题。因此,在作者所用到的数据集中,作者将推特信息和灾难类型分别分为如下几类:
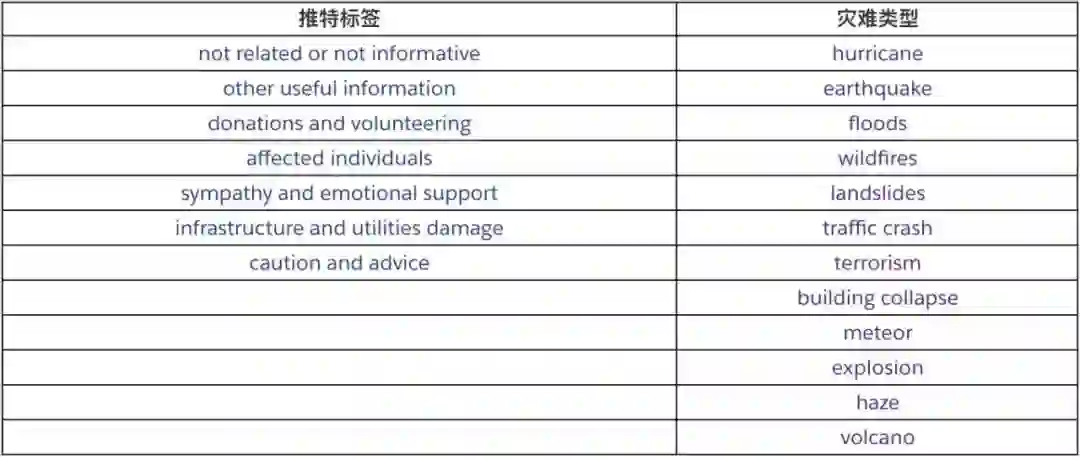
作者以一个单层双向 LSTM 作为基准,然后再在 BERT 之上衍生了四个模型变种 default BERT,BERT+NL,BERT+LSTM,BERT+CNN。
其中 default BERT 只在 BERT 的输出层加上单层全连接网络以及 softmax,而 BERT+NL 则是多层全连接网络以及 softmax,BERT+LSTM 顾名思义就是 BERT 输出层输入到一个 LSTM 网络,最终 LSTM 的输出再通过 softmax 输出,而 BERT+CNN 也是相同的原理,只不过 LSTM 换成了 CNN。
最终的实验结果如下图所示,我们可以看到基于 BERT 的模型在所有指标上均超过了只基于 LSTM 的基准模型。

最后,作者在 github 上上传了自己的代码 https://github.com/sebsk/CS224N-Project。
2.3. 文章写作
在自然语言处理的任务中,文本生成可采用经典的 sequence2sequence 模型来完成,即 Encoder 和 Decoder 模型结构,其中 Encoder 和 Decoder 一般都采用 RNN 来实现。而要想使用 BERT 来进行文本生成这个任务通常来说会是一个比较难的问题,原因在于 BERT 在预训练的时候采用的是 MASK 的方法,这是一种自编码(AE)的方法,训练的时候会利用上下文语境一起训练,并尝试着复现原输入。相比于 BERT,一般的 LSTM 采用的是上文预测下文的方法,这是一种自回归(AR)的方法,天然适合文本生成,因为文本生成就是从左到右一个单词一个单词生成的。
那么 BERT 是否就不能应用于文本生成呢?Alex Wang 在他的论文「BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model」中解释了这一问题,论文标题很直接地回答了这个问题,BERT 有张会说话的嘴。
这篇文章的作者先结合伪对数似然证明了 BERT 是一个马尔科夫随机场语言模型(MRF-LM),而马尔可夫随机场是一个可以由无向图表示的联合概率分布,即下一个时间点的状态只与当前的状态有关,属于生成式模型。同时也因为在某种程度上 BERT 学习到了句子的分布,所以这也就是说我们可以利用 BERT 来进行文本生成,比如新闻写作、小说写作等任务。
但是随后出人意外地是该论文的作者随后又在自己的博客中声明自己的推导有误,BERT 不是马尔科夫随机场,链接见段尾。虽然作者说明 BERT 不是马尔科夫随机场,但是仍然可作为一个生成模型。
博客链接:http://www.kyunghyuncho.me/home/blog/amistakeinwangchoberthasamouthanditmustspeakbertasamarkovrandomfieldlanguagemodel
我们可以看到生成的效果如下(左边是 BERT 生成的效果,右边是 GPT 生成的效果):

最后,作者上传了自己的代码到 Github 上 https://github.com/nyu-dl/bert-gen。
2.4. 法律文书 BERT

法律文档,来源 https://tutorcruncher.com/business-growth/legal-implications-when-starting-a-tutoring-business/
在自然语言处理领域,训练数据的文本质量至关重要,高质量的文本数据能够让模型学得更快学得更好。而法律行业则是少有的拥有高质量文本数据的行业,这是因为法律文书、合同等文本的质量高低与相关人员的切身利益密切相关,所以相关方都会反复审查文书内容确保文本质量。
清华大学人工智能研究院和幂律智能在最近这段时间发布了几个中文领域的预训练 BERT 模型,其中有民事文书 BERT 和刑事文书 BERT 是法律领域专用的预训练语言模型。
民事文书 BERT 基于 2654 篇民事文书进行训练,经过测试,它在相关法律任务上能够更快地学习到东西,并明显优于 Google 官方的中文 BERT。而刑事 BERT 则是基于 663 万篇刑事文书进行训练,在相关任务上的表现也比原版中文 BERT 要好。以下是测试结果:

该项目的预训练法律 BERT 模型与著名的开源项目 https://github.com/huggingface/pytorch-pretrained-BERT 完全兼容,只是模型参数发生了改变。此外由于 pytorch-pretrained-BERT 有着完善的文档,所以对于想要尝试该模型并熟悉 pytorch 的同学来说,这个模型可以很快的上手。
我们可以在 GitHub 上找到相关项目的资料以及模型链接:https://github.com/thunlp/OpenCLaP
2.5. 科学论文
近日,美国能源部劳伦斯伯克利国家实验室最近发表在《自然》杂志上的一篇论文引起了人们的广泛关注。研究人员表示它们的无监督预训练词嵌入在自动阅读 300 万篇材料学领域的论文之后发现了全新的科学知识。他们将这些论文的摘要用 word2vec 算法进行词嵌入训练,通过解释分析词与词之间的关系,可以提前数年给出新热电材料的预测,在目前未知的材料中找出有应用潜力的候选材料。
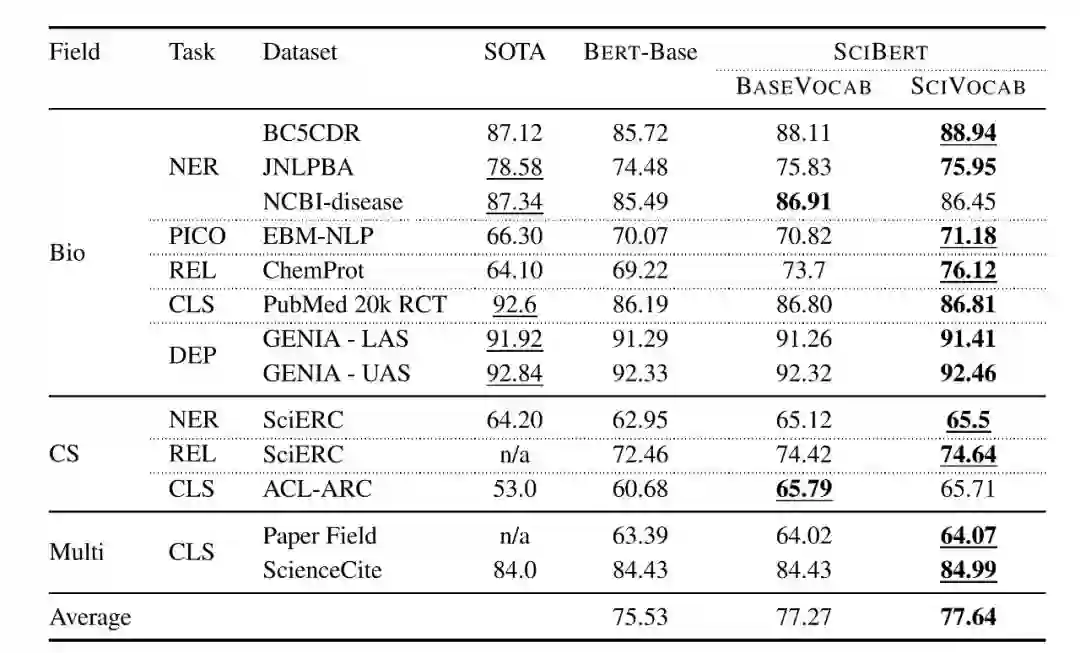
在论文文本预训练领域,也有这么一个基于 BERT 模型进行训练的。SciBERT 是 AllenNLP 提出的一个基于科学论文文本预训练的 BERT,根据 SciBERT 介绍,它具有以下特性:
完全基于 semanticscholar.org (https://semanticscholar.org/) 的论文全文进行训练,而不仅仅是摘要,整个论文数量达到了 1.14M,而文本符号也达到了 3.1B 的级别;
SciBERT 有自己的词库 scivocab,该词库完全匹配训练语料库;
在目前所有科学领域的自然语言处理任务中均达到了最先进的级别,我们可以看下图;
最后,我们可以在 Github 上找到源码和预训练模型进行下载 :https://github.com/allenai/scibert。
3. 结语
由于 BERT 通过威力巨大的特征抽取器 Transformer 在海量的文本上学习到了大量的语言特征先验知识,所以这对于大多数自然语言处理的任务都有非常好的效果。如果 BERT 比作一个人,那么它的阅读量则达到了我们一生所不能达到的量,从一定程度上可以说 BERT 是一位博学家。BERT 为我们开启了一个崭新的自然语言处理时代,相信站在这个巨人的肩膀上,未来一定会爆发更多有趣的工作!
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




