ECCV 2020 GigaVision挑战赛“行人和车辆检测”和“多目标追踪”冠军方案解读

极市导读
本文介绍了首届GigaVision挑战赛“行人和车辆检测”和“多目标追踪”两个赛道的难点以及冠军方案的工作细节。>>加入极市CV技术交流群,走在计算机视觉的最前沿


GigaVision赛题介绍
以人为中心的各项计算机视觉分析任务,例如行人检测,跟踪,动作识别,异常检测,属性识别等,在过去的十年中引起了人们的极大兴趣。
为了对大规模时空范围内具有高清细节的人群活动进行跨越长时间、长距离分析,清华大学智能成像实验室推出一个新的十亿像素视频数据集:PANDA。
该数据集是在多种自然场景中收集,旨在为社区贡献一个标准化的评测基准,以研究新的算法来理解大规模现实世界场景中复杂的人群活动及社交行为。围绕PANDA数据集,主办方组织了GigaVision 2020挑战赛。
任务介绍
挑战赛的任务是在由十亿像素相机收集的大范围自然场景视觉数据集PANDA上进行图像目标检测和视频多目标跟踪。
评测指标

DeepBlueAI团队荣获两项第一
任务一:

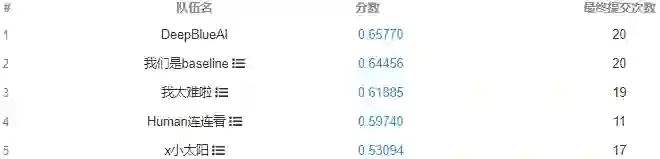
赛题特点
主要工作
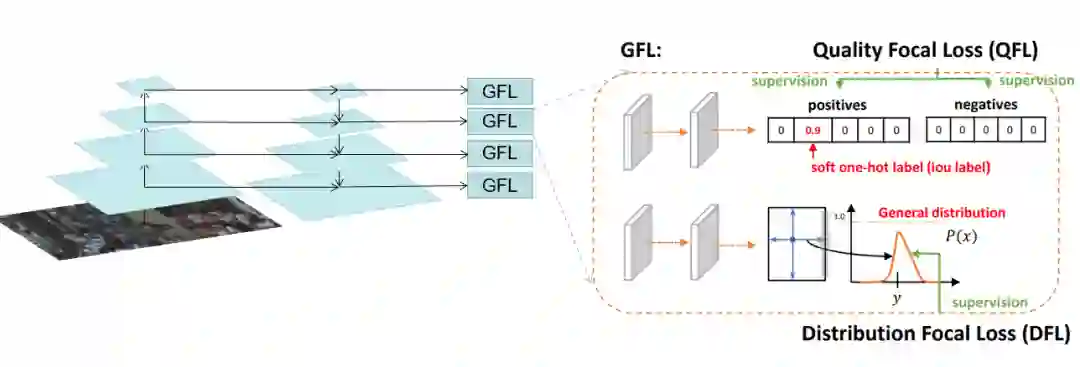
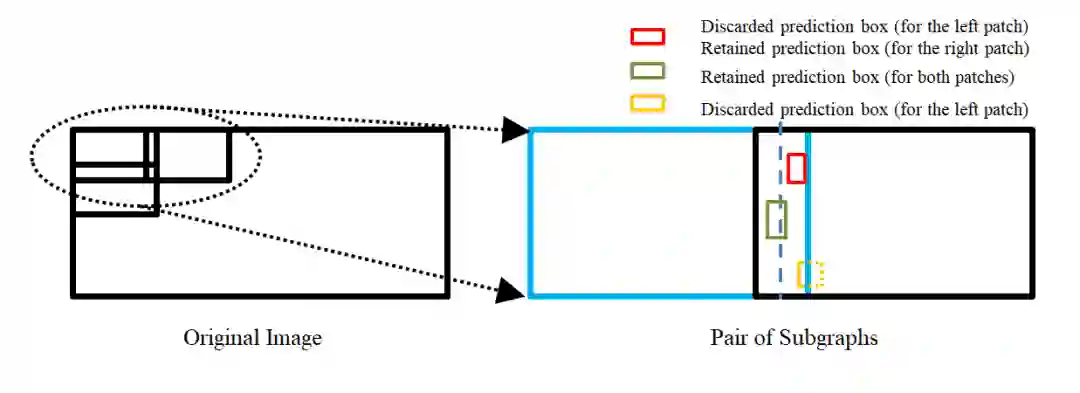
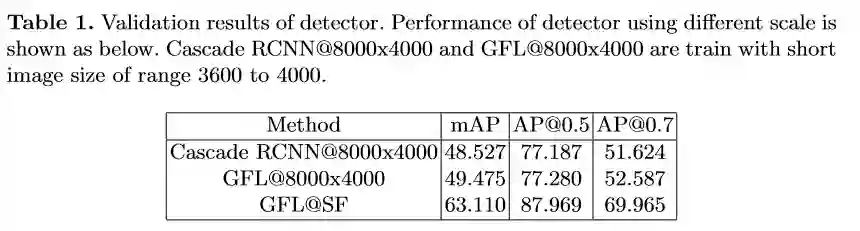
赛道一 Pedestrian & Vehicle Detection

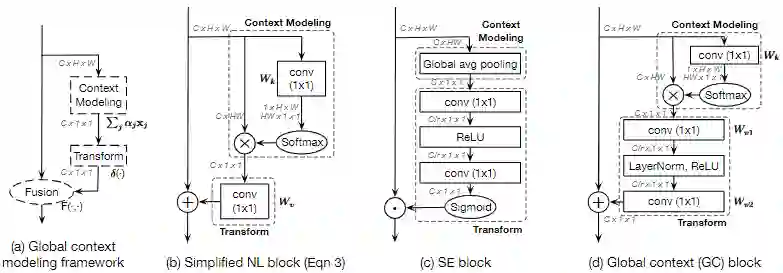
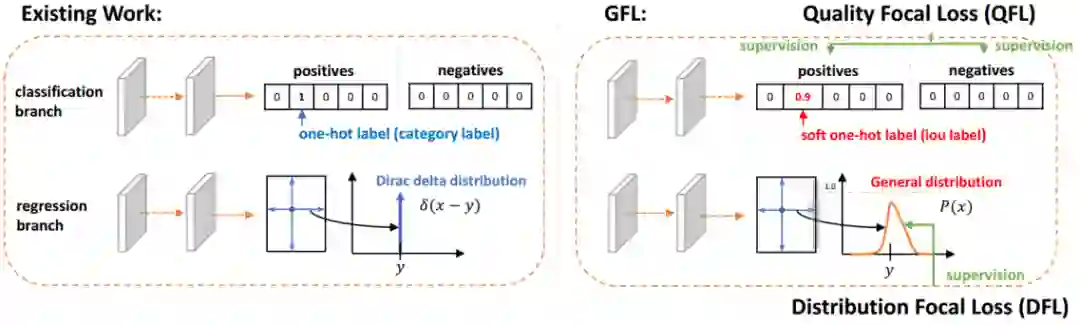
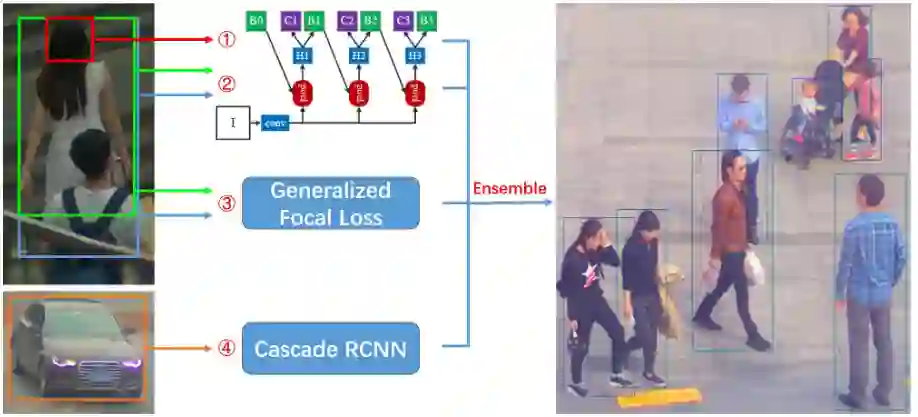
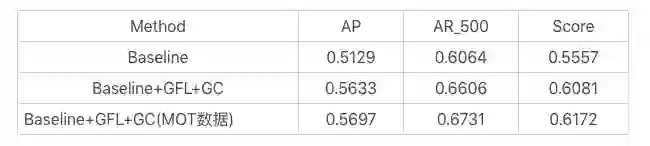
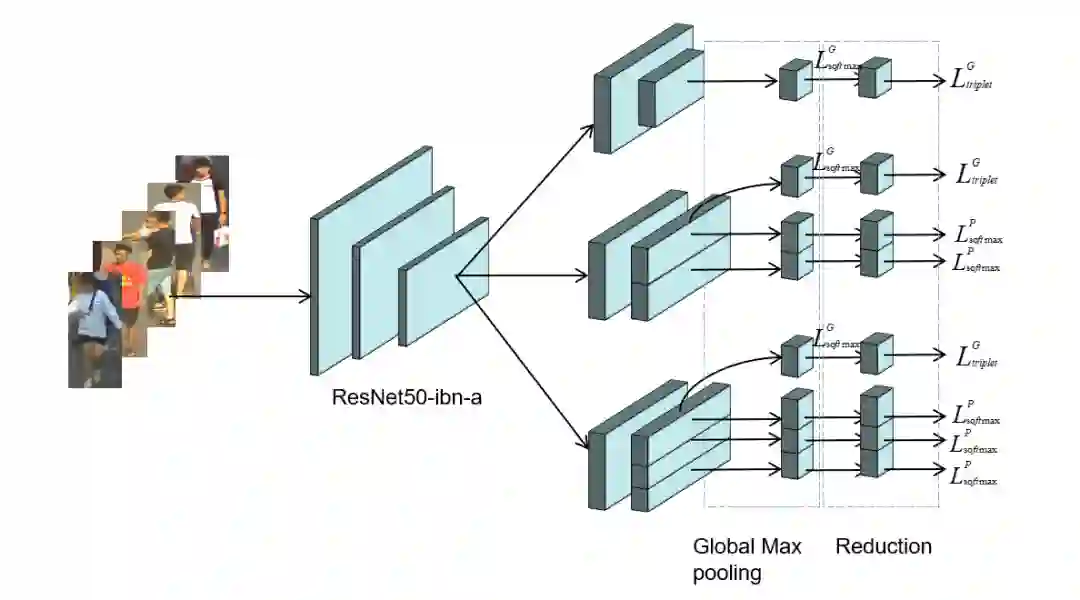
赛道二 Multi-Pedestrian Tracking
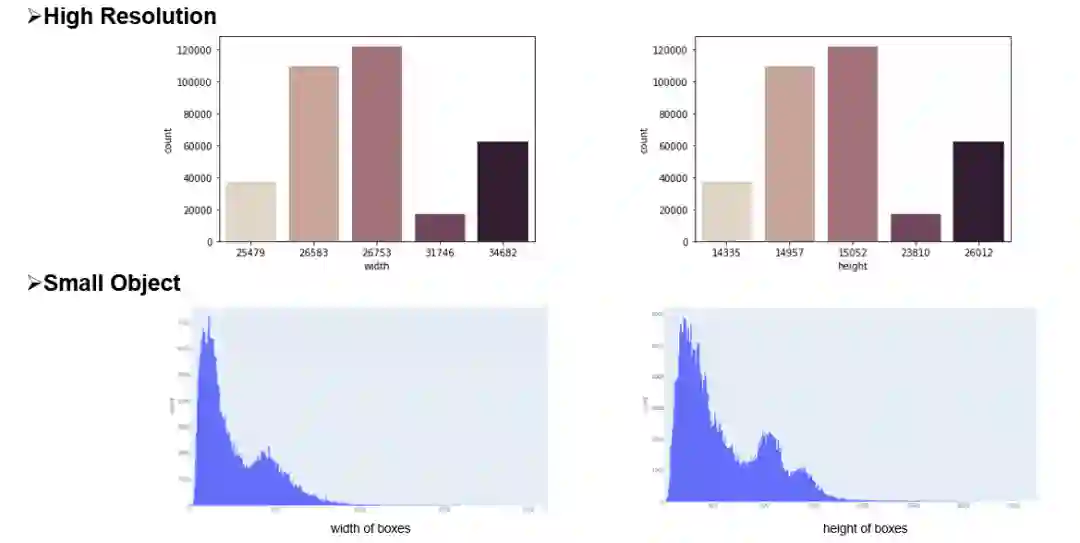
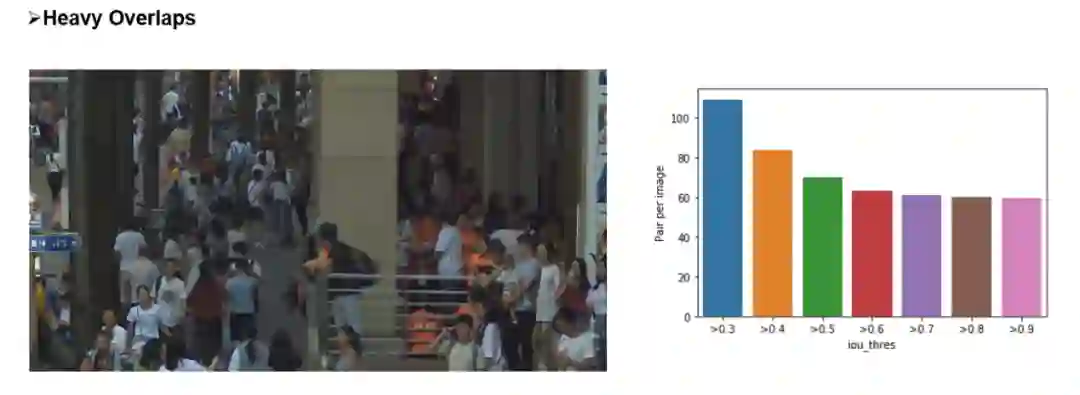
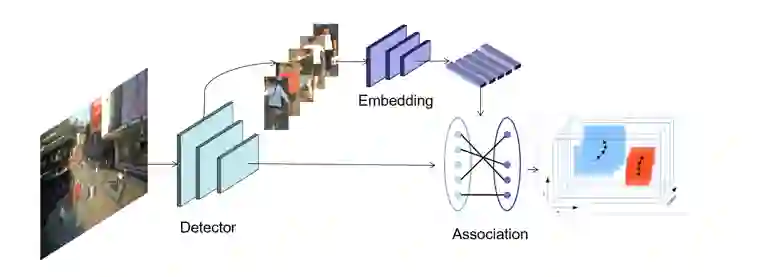
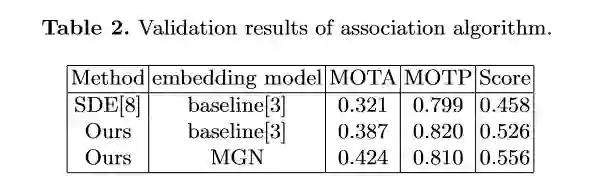
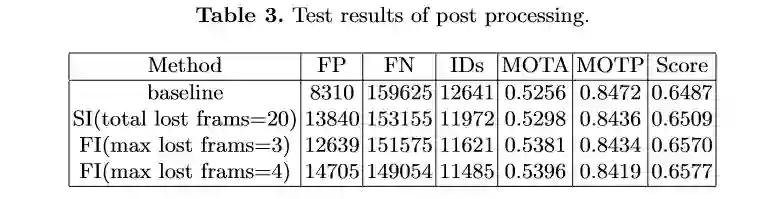
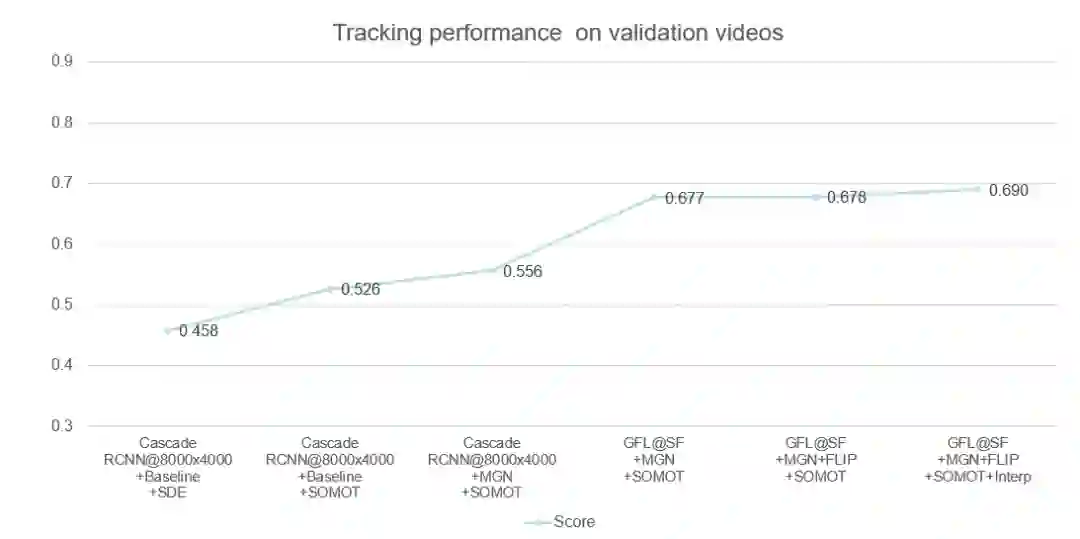
总结与思考
推荐阅读




登录查看更多
相关内容
专知会员服务
38+阅读 · 2020年3月23日
专知会员服务
56+阅读 · 2019年11月28日
Arxiv
0+阅读 · 2020年11月29日
Arxiv
7+阅读 · 2018年4月6日


相关VIP内容
专知会员服务
38+阅读 · 2020年3月23日
专知会员服务
56+阅读 · 2019年11月28日
相关资讯
相关论文
Arxiv
0+阅读 · 2020年11月29日
Arxiv
7+阅读 · 2018年4月6日