前沿 | DeepMind提出新型超参数最优化方法:性能超越手动调参和贝叶斯优化
选自DeepMind
作者:Max Jaderberg
机器之心编译
参与:蒋思源、刘晓坤
近日,DeepMind 发表论文提出一种新型的超参数调优方法,该方法从遗传算法获得启发大大提升了最优超参数搜索的效率。它的性能要比贝叶斯优化好很多,且在各种前沿模型的测试中很大程度上提升了当前最优的性能。
从围棋、Atari 游戏到图像识别与语言翻译,神经网络都取得了巨大的成功。但我们常常忽略的是,神经网络在特定应用上的成功通常取决于研究开始时所做的一系列选择,包括使用什么样的神经网络架构、数据与方法进行训练等。目前,这些选择或者说超参数都是通过实验经验、随机搜索或计算密集型的搜索过程实现。
在我们近日发布的论文 Population Based Training of Neural Networks 中,我们引进了一种训练神经网络的新方法,它允许实验者针对不同的任务快速选择最佳的参数集和模型。这种技术称为基于种群的训练(Population Based Training/PBT),它会同时训练并优化一系列网络,从而可以快速地搜索最佳的配置。更重要的是,这并不会增加计算开销,它可以像传统技术一样快速地完成,并可以轻易地集成到现有的机器学习流程中。
该技术是随机搜索和手动调整这两种最常见超参数最优化方法的混合体。在随机搜索中,算法会并行地训练一组独立的神经网络,并在训练结束时选择性能最好的模型。一般情况下,这意味着只有一小部分的网络会使用经过精调的超参数进行训练,而大多数仍然使用并不太优秀的超参数进行训练,因此这会造成计算资源的浪费。
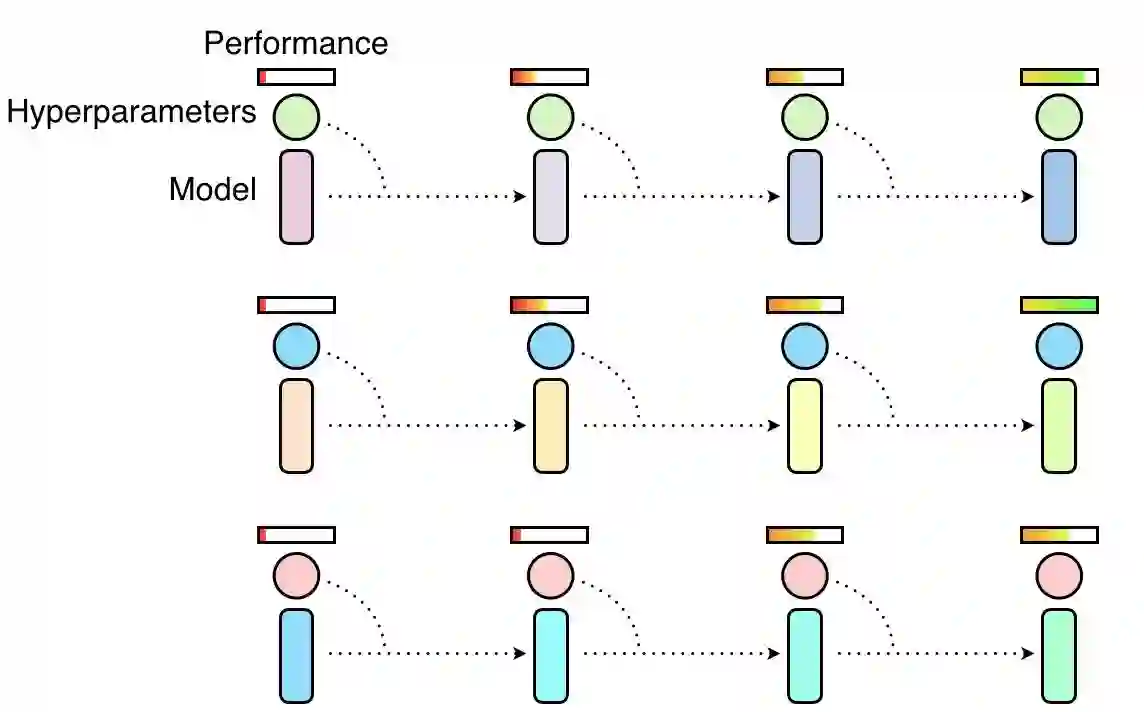
随机搜索超参数,其中很多超参数是通过并行选择的,它们之间是互相独立的。一些超参数会产生良好的性能,但另一些并不会。
对于手动调参而言,研究者必须根据经验选择可能的最好超参数,然后再训练和评估模型。这需要一遍又一遍地完成,直到研究者对网络的性能总体上感到满意。虽然这可能会产生较好的性能,但缺点是可能需要非常长的时间,有时甚至需要数周或数月才能找到完美的配置。虽然目前有一些如贝叶斯优化等方法自动完成这一过程,但仍然需要很长的时间和很多连续的训练任务才能找到最好的超参数。
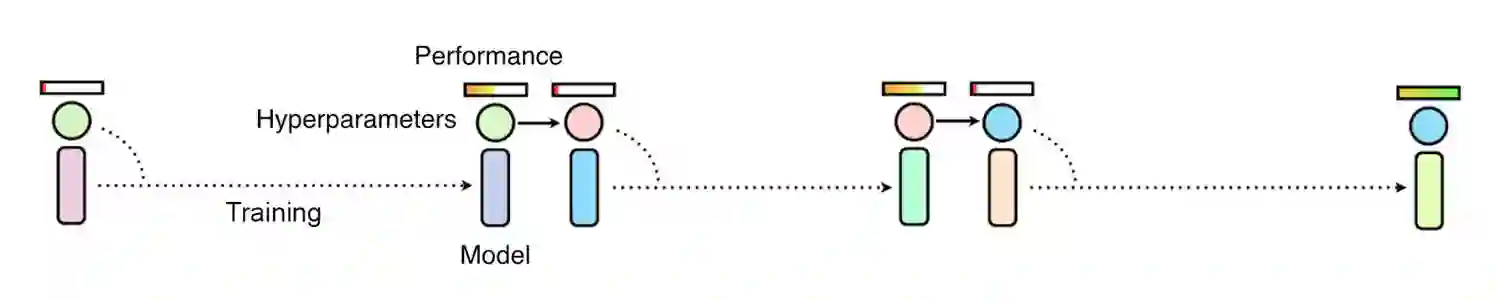
使用手动调参和贝叶斯优化的方法修正超参数需要依次观察许多网络的训练结果,这一过程令这些方法很慢。
PBT 就像随机搜索一样,首先需要以随机超参数的方式训练许多并行的网络。但是这些网络并不是独立训练的,它们会使用其它网络的训练信息来修正这些超参数,并将计算资源倾向那些有潜力的模型。这一过程是从遗传算法获得的灵感,其中一组网络(或称为种群/population)中的每个神经网络即一个个体(worker),它可以利用除自身外其余网络的信息。例如单个网络(或称为个体)可能会从表现较好的个体中复制模型参数,它还能通过随机修正当前的值而探索新的超参数组合。
随着不断地对神经网络群体进行训练,不断反复进行开发和探索的步骤(详见拟合目标函数后验分布的调参利器:贝叶斯优化),算法能确保所有的个体都有非常好的基础性能水平,且都能进行一定的超参数新探索。这意味着 PBT 可以快速利用优秀的超参数,并为有潜力的模型提供更多的训练时间。因此这个算法的关键点在于它可以在整个训练过程中调整超参数值,从而自动学习最优配置。
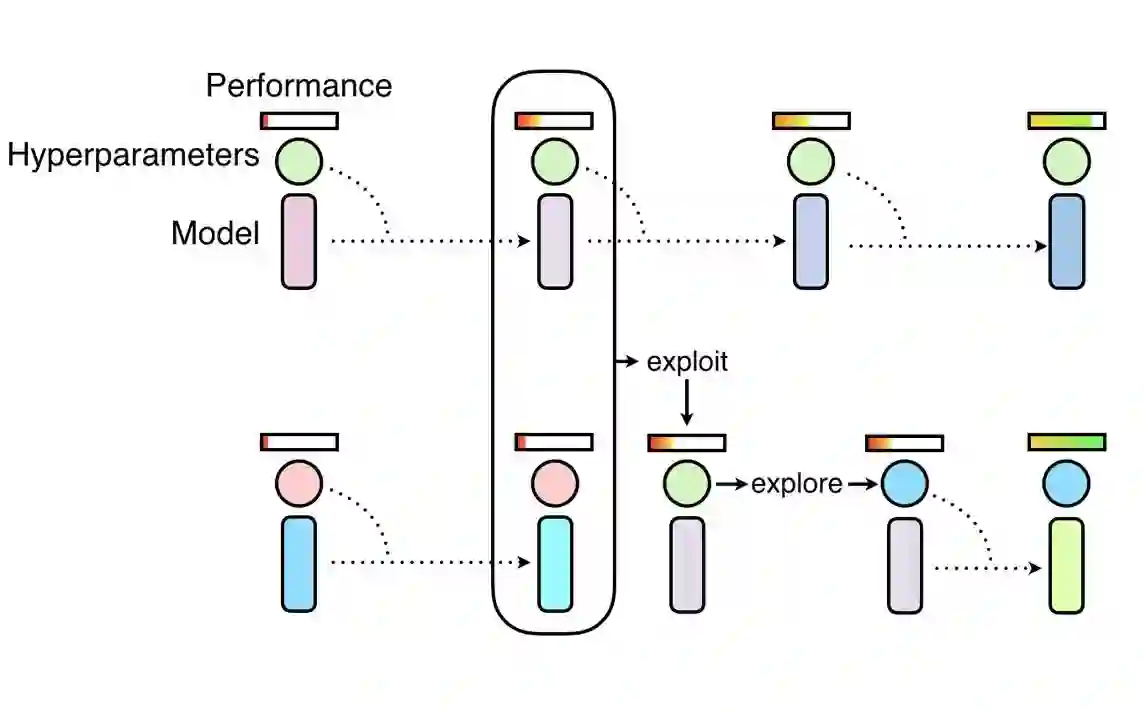
PBT 算法的起始阶段类似随机搜索,但允许一个个体利用其它个体的部分结果,并在训练过程中探索新的超参数。
我们的实验表明,PBT 在主要的任务和领域中都是非常有效的。例如,我们在 DeepMind Lab、Atari 和 StarCraft II 中的一系列有挑战性的强化学习问题上使用当前最佳的方法严密地测试了该算法。在所有的案例中,PBT 都能稳定训练过程,并快速找到好的超参数,得到超越当前最佳基线的结果。
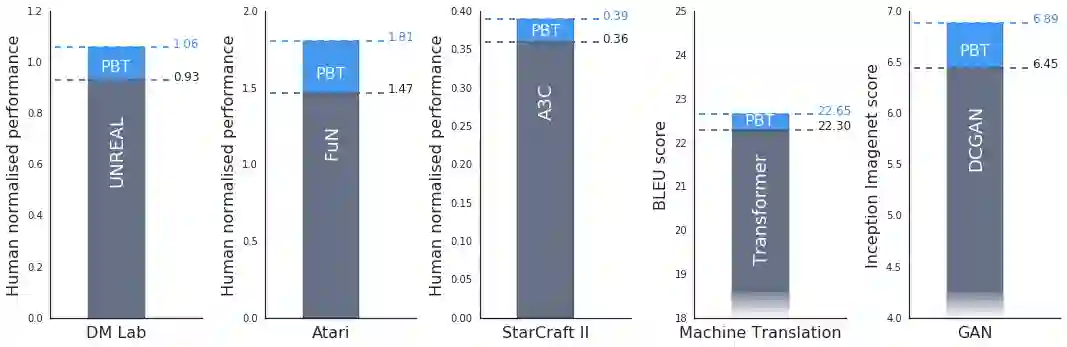
我们还发现 PBT 可以有效地训练生成对抗网络(GAN),众所周知,该网络是很难调整的。具体的说,我们是用 PBT 框架以最大化 Inception 分数(一种视觉保真度的度量),获得了显著的提升,即从 6.45 提高到 6.9。
我们还将 PBT 应用到谷歌的一种当前最佳的机器翻译神经网络(通常需要花费数月时间进行细致的手动调整超参数方案)上。通过 PBT 我们可以自动地获得超参数方案以得到甚至超越当前性能,在过程中不需要任何人为调整,并且它通常只需要运行单次训练。

GAN 在 CIFAR-10 上和 Feudal Networks(FuN)在 Ms Pacman 上的训练过程中的群体演化。粉色点表示初始智能体,蓝色点表示最终智能体。
我们相信这仅仅是这项技术的开端。在 DeepMind,我们还发现 PBT 能特别有效地用于训练新的算法和具有新的超参数的神经网络架构。随着我们对该算法的进一步打磨,PBT 将为寻找和开发更加复杂和强大的神经网络模型提供助力。
论文:Population Based Training of Neural Networks

论文地址:https://deepmind.com/documents/135/population_based_training.pdf
摘要:神经网络在机器学习领域占主导地位,但其训练过程和成功率仍然受到对超参数(如模型架构、损失函数和优化算法等)的经验选择的敏感度的限制。我们在这里提出基于种群的训练(Population Based Training,PBT),这是一种简单的异步优化算法,可以有效地利用固定的计算开销联合优化一群/多个模型和其超参数以最大化性能。重要的是,PBT 可以发现一个超参数配置的方案,而不是像通常那样使用子优化策略,即尝试寻找单个固定的超参数集用于整个训练过程。只需要对一种典型的分布式超参数训练框架做少量修改,我们的方法就能对模型进行鲁棒性的和可靠的训练。我们展示了 PBT 应用于深度强化学习问题的有效性,通过优化一系列超参数,表明可以达到小时级别的收敛速度并获得更高性能的智能体。此外,我们展示了该方法还可以应用于机器翻译的监督学习(其中 PBT 可以直接最大化 BLEU 分数),以及生成对抗网络的训练(最大化生成图像的 Inception 分数)。在所有的案例中,PBT 都能自动获得超参数的配置方案和模型的选择方案,从而使训练过程变得稳定,并获得更好的最终性能。

原文链接:https://deepmind.com/blog/population-based-training-neural-networks/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论。
