教你巧玩 [冲顶大会] 答题类游戏
这两天冲顶大会之类的直播答题 APP 突然火了起来,不得不佩服互联网公司的想象力,那么程序员怎么用不同的方式玩转答题游戏呢。之前微信的跳一跳小游戏刷爆朋友圈,已经有很多朋友写出了自动化的脚本辅助,一看到答题游戏就马上想到可以用类似的方式来写一个简单的脚本。我发现已经有朋友做了个调用百度 api 的,自己就再写个直接用识别库的吧,代码思路简单,可以用在各类答题游戏中。使用文字识别加搜索,只能起到辅助决策的作用,可以参考结果,增加准确率,也保证不了全对。
具体代码和环境及使用请戳:https://github.com/Skyexu/TopSup
随手 Star ^ ^
灵感来自:
具体做法
1.使用 ADB 获取手机截屏
adb shell screencap -p /sdcard/screenshot.png
adb pull /sdcard/screenshot.png .
2.OCR 识别题目与选项文字
分别通过代码截取题目区域与选项区域,再进行文字识别
文字识别两个方法:
3.搜索判断
结果判断方式
1.直接打开浏览器搜索问题

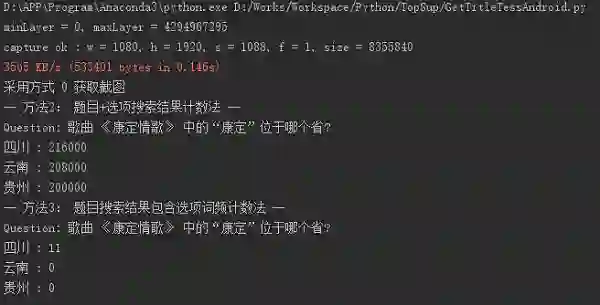
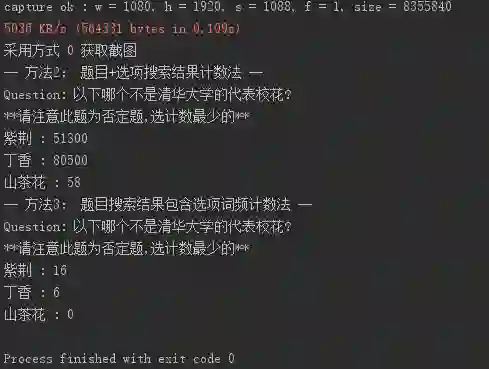
2.题目+每个选项都通过搜索引擎进行搜索,从网页代码中提取搜索结果的数目
3.只用题目进行搜索,统计结果页面代码中包含选项的词频
以下为两个示例结果,可以看出下面两道题,两个方法有不同的结果,可以根据问题类型进行不同的决策。
参考了 I Hacked HQ Trivia But Here’s How They Can Stop Me
主要代码
验证思路的主要代码是实现截图,识别,调用浏览器搜索。其实很简单,具体可以参考我的 github 库中简单版本代码
def pull_screenshot():
os.system('adb shell screencap -p /sdcard/screenshot.png')
os.system('adb pull /sdcard/screenshot.png .')
pull_screenshot()
img = Image.open("./screenshot.png")
# 切割题目位置,左上角坐标和右下角坐标,自行测试分辨率
question = img.crop((50, 350, 1000, 560)) # 坚果 pro1
choices = img.crop((75, 535, 990, 1150))
#region = img.crop((75, 315, 1167, 789)) # iPhone 7P
# tesseract 路径
pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files (x86)\\Tesseract-OCR\\tesseract'
# 语言包目录
tessdata_dir_config = '--tessdata-dir "C:\\Program Files (x86)\\Tesseract-OCR\\tessdata"'
# lang 指定中文简体
text = pytesseract.image_to_string(question, lang='chi_sim', config=tessdata_dir_config)
text = text.replace("\n", "")[2:]
print(text)
webbrowser.open('https://baidu.com/s?wd='+text)
总结
写完简单版本想一想,怕是还没有 Hi ,Siri来的方便,不过好在识别准确,查询快,后来又加了几个方法辅助决策。文字识别加搜索,在这类游戏中并不能完全做对,想要实现完全对,可能还是得抓包? 或者存储题库,不过这就太费时间了。有了 ADB 截图,怕是各种小辅助都可以玩了,大家可以发挥想象力。python 写小脚本真的很方便。接下来可以尝试文字识别后 nlp 处理一下关系,然后搜索不同选择结果,增加准确率等等。不玩了不玩了,得写 paper 去了。





