学界 | 好奇心驱动学习,让强化学习更简单

雷锋网 AI 科技评论按:强化学习在最近几年中都是最热门的研究领域之一,但是复杂环境中难以训练、训练后难以泛化的问题始终没有得到完全的解决。好奇心驱动的学习是一种非常有趣的解决方案,这篇文章就是一份详细的介绍。雷锋网 AI 科技评论全文编译如下。
* 本文是深度学习工程师 Thomas Simonini 个人编写的 Tensorflow 深度强化学习课程的一部分,戳这里查看教学大纲
(https://simoninithomas.github.io/Deep_reinforcement_learning_Course/)。
近年来,我们在深度强化学习领域看到了很多创新。从2014年的 DeepMind 的深度 Q 学习框架(https://deepmind.com/research/dqn/)到2018年 OpenAI 发布的玩 Dota2 的 OpenAI Five 游戏机器人,我们生活在一个激动人心且充满希望的时代。
今天我们将了解深度强化学习中最令人兴奋、最有前景的策略之一——好奇心驱动学习。
强化学习基于奖励机制,即每个目标可以被描述为获得最大化的奖励。然而,目前的问题就是外部奖励(也就是由环境给出的奖励)是由人为硬性编码的函数,并不可扩展。
好奇心驱动学习的思想是建立一个拥有内在的奖励函数的智能体(奖励函数由智能体自己生成)。这意味着智能体将成为自学者,因为他既是学生,也是反馈者。

- 嘿智能体,我写了一个反馈函数,它会给你反馈
- 免了吧,我有我自己的反馈。我现在是我自己的主人了
听起来很疯狂?是的,但这是一个天才的想法,在2017年的《Curiosity-driven Exploration by Self-supervised Prediction》(https://pathak22.github.io/noreward-rl/)一文中被再次提及,然后通过第二篇论文《Large-Scale Study of Curiosity-Driven Learning》(https://pathak22.github.io/large-scale-curiosity/)改进了结果。
他们发现好奇心驱动学习的学习体表现得和外部奖励机制的学习体一样好,并且能够在未开发的环境中更好地泛化。
在第一篇文章中,我们将讨论理论部分并从理论上解释好奇心驱动学习是怎么运作的。
然后,在第二篇文章中,我们将实现一个好奇心驱动学习下的 PPO 智能体玩超级马里奥。
听起来很有趣?让我们一起来看看!
强化学习中的两个主要问题
首先,稀疏奖励的问题,在于行动与其反馈(奖励)之间的时差。如果每个行动都有奖励,则智能体会快速学习,以便获得快速反馈。
例如,如果你玩太空侵略者,你射击并杀死一个敌人,你会获得奖励。因此,你会明白在那个场景下的这个行动是好的。

有了奖励学习体就知道在这个状态下行动是好的
但是,在实时策略游戏等复杂游戏中,您不会对每个行为都有直接的奖励。因此,糟糕的决策直到几小时后才会有反馈。
以帝国时代II为例来看,我们可以在第一张图片上看到智能体决定建造一个营房并专注于收集资源。因此,在第二张图片中(几小时后),敌人摧毁了我们的营房,因此我们拥有大量的资源,但我们无法建立一支军队,所以我们死了。

敌人摧毁我们的营房
第二个大问题是外部奖励不可扩展。由于在每个环境中,人类都实现了奖励机制。但是我们如何在大而复杂的环境中扩展它?
解决方案是开发智能体内在的奖励机制(由智能体本身生成),这种奖励机制将被称为好奇心。
新的奖励功能:好奇心
好奇心是一种内部奖励,它等于我们的智能体在其当前状态下预测其自身行为的后果的误差(也就是在给定当前状态和采取的行动的情况下预测下一个状态)。
为什么?因为好奇心的思想就是鼓励我们的智能体采取行动来降低学习体预测其自身行为后果的能力的不确定性(智能体花费较少时间的区域或动态复杂的区域的不确定性会更高)。
因此,测量误差需要建立一个环境动态模型,在给定当前状态和动作 a 的情况下预测下一个状态。
这里我们就要提出一个问题——我们怎么计算误差?
为了计算好奇心,我们将使用一个在第一篇论文中所提及的名为Intrinsic Curiosity module(内在好奇心模块)的模块。
介绍好奇心模块
需要一个良好的特征空间
在深入描述模型之前,我们先必须问自己,根据我们当前的状态和行动,智能体该如何预测下一个状态?
我们知道可以将好奇心定义为给定当前状态st和行动at的预测新状态(st + 1)与真实新状态之间的误差。
但是,请记住,大多数情况下,我们的状态是4帧(像素)的堆栈。这意味着我们需要找到一种方法来预测下一叠帧,这有两个难点:
首先,很难直接预测像素,想象你在Doom中向左移动,你需要预测248 * 248 = 61504像素!
其次,研究人员认为这是错误的做法,并且可以通过一个很好的例子来证明这一点。
想象一下,你需要在微风中研究树叶的运动。首先,很难对微风进行建模,因此在每个时间点预测每片叶子的像素位置就更困难了。
问题在于,因为你总是会有一个很大的像素预测误差,所以即使叶子的运动不是智能体动作的结果,智能体也会一直好奇,因此它的持续好奇心是不可取的。

因此,我们需要将原始感官输入(像素阵列)转换为仅包含相关信息的特征空间,而不是在原始感官空间(像素)中进行预测。
我们需要定义以下3点规则来构建一个好的特征空间:
要对可由智能体控制的物体进行建模。
还要对智能体无法控制但可能对其产生影响的事物进行建模。
不要对智能体无法控制且对其没有影响的事物建模(因此不受影响)。
让我们举个例子,你的学习体是一辆汽车,如果我们想创建一个好的特征表示,我们需要建模:
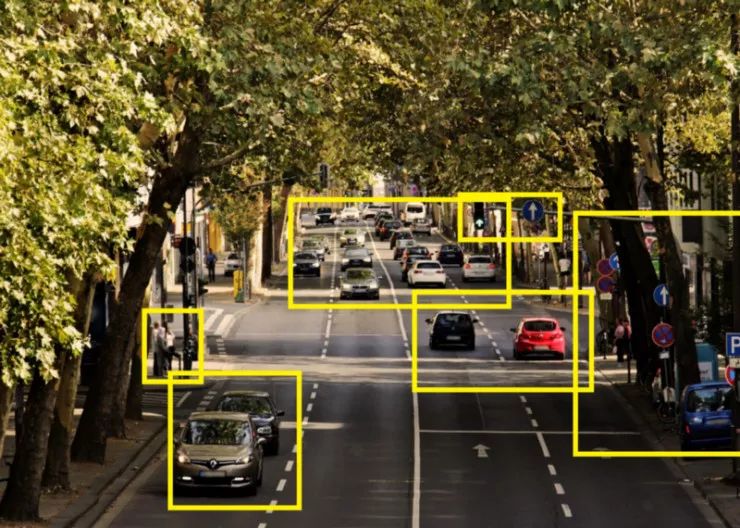
黄框是重要的成分
我们的汽车(由我们的智能体控制),其他汽车(我们无法控制但可能影响智能体),但我们不需要对叶子进行建模(不影响智能体,我们无法控制它)。这样我们就会有一个噪音更小的特征表示。
所需的嵌入空间应该:
空间紧凑(去除观察空间的不相关部分)。
保留有关观察的充分信息。
稳定:因为非固定奖励使强化学习体难以学习。
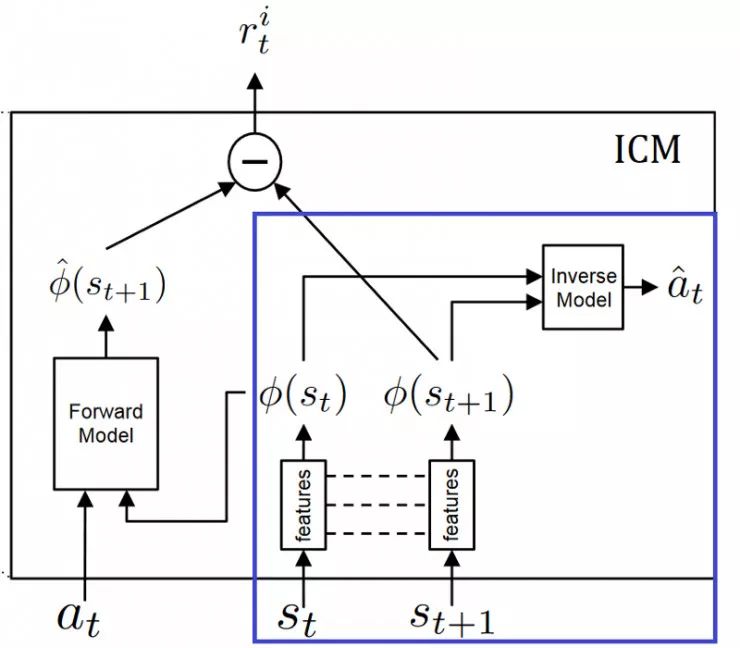
内在好奇心模块(ICM)
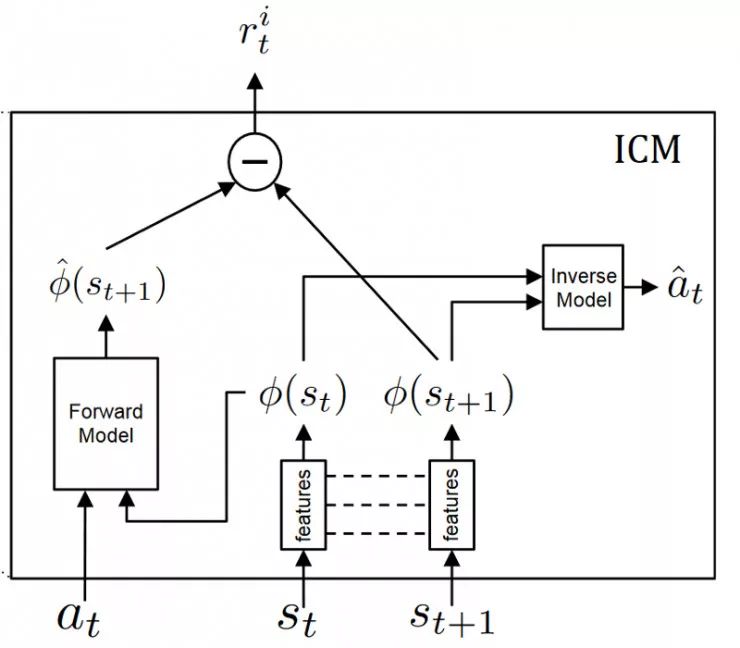
内在好奇心模块是帮助我们产生好奇心的系统。它由两个神经网络组成。
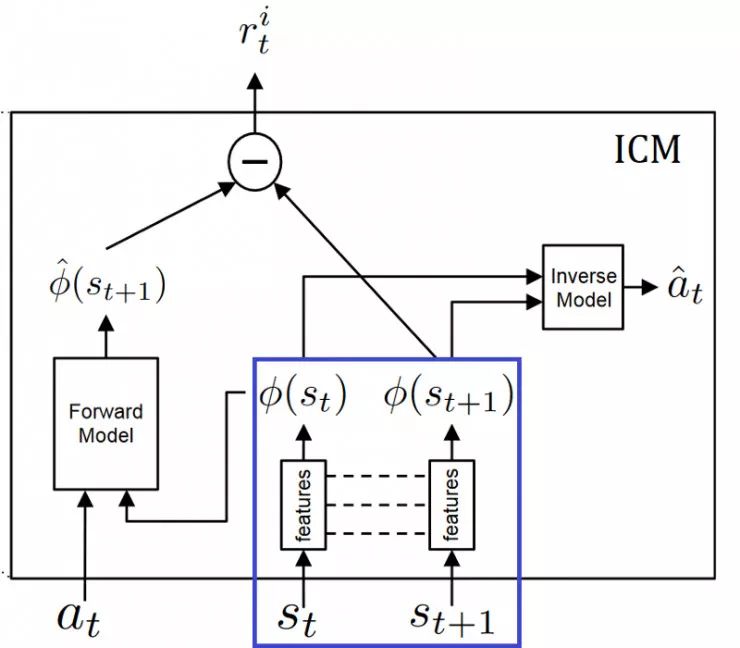
请记住,我们只希望预测环境中可能由于智能体的行为引起的改变或忽略其余内容对智能体产生影响的更改变。这意味着,我们需要的不是从原始感觉空间(像素)进行预测,而是将感官输入转换为特征向量,其中仅表示与智能体执行的动作相关的信息。
要学习这个特征空间:我们使用自我监督,在智能体逆向动态任务上训练神经网络,给定其当前状态和下一个状态(st和st + 1)预测学习体行为(ât)。
由于神经网络仅需要预测动作,因此没有动机在其特征向量空间内表示不影响智能体本身的环境变化因素。
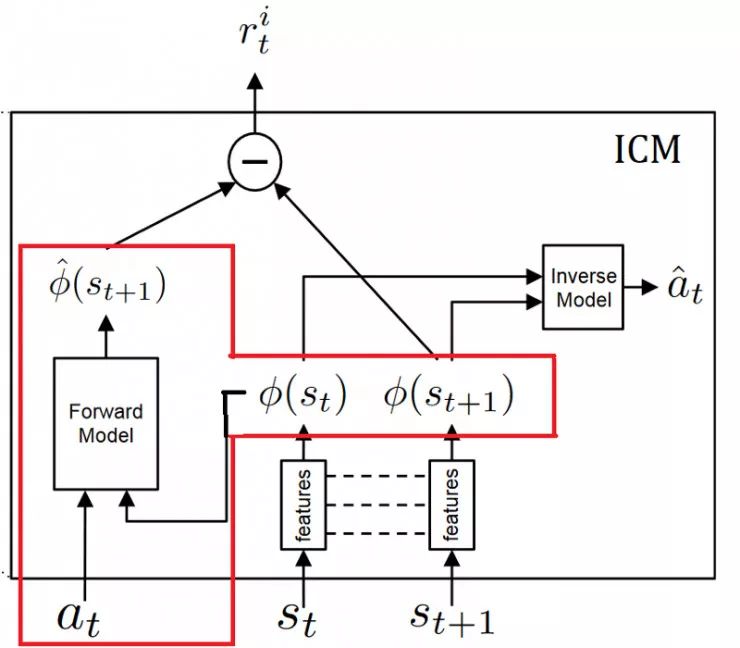
前向模型部分
然后我们使用此特征空间来训练前向态模型,给定当前状态phi(st)的特征表示和动作,用该模型预测下一个状态phi(st + 1)的未来表示。
并且我们向智能体提供前向动态模型的预测误差,作为鼓励其好奇心的内在奖励。
Curiosity= predict_phi(st + 1) - phi(st + 1)
那么,我们在ICM中有两个模型:
反向模型(蓝色):将状态st和st + 1编码到经过训练以预测动作的特征向量phi(st)和phi(st + 1)中。

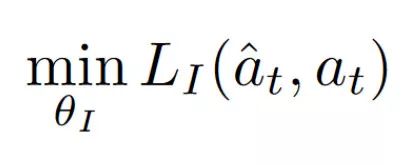
测量真实行为和预测行为差异的逆损失函数
正向模型(红色):将phi(st)和at作为输入,并且预测st + 1的特征表示phi(st + 1)。
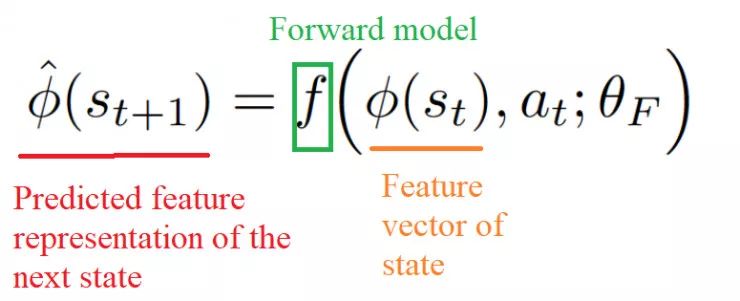
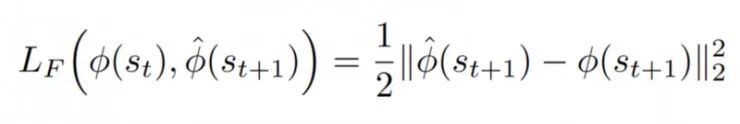
前向模型损失函数
然后从数学上讲,好奇心将是我们预测的下一个状态的特征向量与下一个状态的真实特征向量之间的差。

最后,该模块的整体优化问题是逆向损失,正向损失的结合。

这里有很多信息和数学知识!
回顾一下:
由于外部奖励实现和稀疏奖励的问题,我们希望创建智能体的内在奖励。
为此,我们创造了好奇心,这是智能体在预测其当前状态下的行动结果时的误差。
利用好奇心将推动我们的学习体支持具有高预测误差的转换(在智能体花费较少时间的区域或动态复杂的区域中会更高),从而更好地探索我们的环境。
但是因为我们无法通过预测下一帧(太复杂)来预测下一个状态,所以我们使用更好的特征表示,只保留可由智能体控制或影响智能体的元素。
为了产生好奇心,我们使用由两个模型组成的内在好奇心模块:用于学习状态和下一状态的特征表示的逆向模型和用于生成下一状态的预测特征表示的前向动态模型。
好奇心将等于predict_phi(st + 1)(前向动态模型)和phi(st + 1)(逆向动态模型)之间的差异。
这就是今天的一切!既然你理解了这个理论,那么你应该读读《Curiosity-driven Exploration by Self-supervised Prediction 》、《Large-Scale Study of Curiosity-Driven Learning》两篇论文的实验结果。
下一次,我们将使用好奇心作为内在奖励机制来实现玩超级马里奥的PPO学习体。
via towardsdatascience.com,雷锋网 AI 科技评论编译





