「视频片段检索」最新2022研究综述
最新视频片段检索综述

视频片段检索旨在利用用户给出的自然语言查询语句,在一个长视频中找到最符合语句描述的目标视频 片段.视频中包含丰富的视觉、文本、语音信息,如何理解视频中提供的信息,以及查询语句提供的文本信息,并进行 跨模态信息的对齐与交互,是视频片段检索任务的核心问题.本文系统梳理了当前视频片段检索领域中的相关工作,将它们分为两大类:基于排序的方法和基于定位的方法. 其中,基于排序的方法又可细分为预设候选片段的方法和有 指导地生成候选片段的方法;而基于定位的方法则可分为一次定位的方法和迭代定位的方法.本文还对本领域的数 据集和评价指标进行了介绍,并对一些模型在多个常用数据集上的性能进行了总结与整理.此外,本文介绍了本任务 的延伸工作,如大规模视频片段检索工作等.最后,本文对视频片段检索未来的发展方向进行了展望.
http://www.jos.org.cn/jos/article/abstract/6707
当下,社交网络与在线视频平台的兴起,致使各种各样的未剪辑视频呈爆炸式增长.对于视频的分析[1]与研 究[2]也逐渐成为热点问题.为满足人们对于搜寻长视频中具有特定语义含义片段的需求,视频片段检索任务应 运而生.视频片段检索任务,需要根据查询语句,从一个长视频中检索到最符合语句描述的视频片段.具体来说,数据集中,每个被标注的视频片段都与一组注释相关: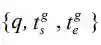
.本文中出现的符号及含义见表 1.在图 1 的示例中,给定一个完整的视频 v 和一条“a person is eating a sandwich (一个人正在吃三明治)”的查询语句 q,视频片段检索模型需要在视频 v 中找到与 q 最匹配的视频片段,并同时预测该片段的开始点和结束点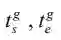


一些真实场景中的视频,如机器人导航[3]、自动驾驶[4]以及监控中的视频[5]等,包含太多无意义的片段,如在 监控视频中,异常视频片段出现的时间和频率远远少于正常片段.使用视频片段检索则可以从长时间的视频中 找出异常片段,从而达到提升效率的目的.这看起来是一项有挑战性的任务,因为我们不仅需要理解视频的内 容、查询语句的语义信息,还需要将不同模态的信息进行精确的匹配,从而达到我们的目的.
视频片段检索任务与动作时序定位任务一脉相承,区别在于动作时序定位没办法满足对于包含对象的具 体事件的查询.定位空间语句[6]也是视频片段检索任务的相关任务之一,其可以视为视频片段检索任务的前期 探索.定位空间语句将将视频类别限制为监控视频,查询语句限制为位置描述语句.Regneri 等人[7]在 MPIIComposites 数据集[8]的基础上,构建了 TACoS 数据集,这个数据集在视频片段检索领域得到了广泛的应用.2017年,Hendricks 等人[9]和 Gao 等人[10]不约而同地提出了视频片段检索的模型,他们均采取了将视频划分为候选片 段,然后从中挑选出最匹配片段的方式.他们不仅简化了问题的复杂度,而且各自贡献了用于视频片段检索任务 的数据集 DiDeMo 及 Charades-STA.特别地,Gao 等人[10]提出的模型框架更是成为基础框架之一,其思想被之后 的研究工作广泛借鉴,例如,通过引入注意力机制、更细致的跨模态交互等技术模块,使检索性能得到提升.2019年,Escorcia 等人[11]将本任务由单个视频的检索扩展到面向视频库的检索,使视频片段检索任务具有更加广泛的应用可能性,我们将其称为大规模视频片段检索任务,并在第五部分进行简要介绍.
本文的组织结构如下.首先,第一章简短地对视频片段检索任务进行介绍.根据解决问题角度的不同,我们 在本文中将现有的视频片段检索方法大致分为基于排序的方法和基于定位的方法两类,并分别在第二部分、第 三部分进行介绍.第四部分对当前视频片段检索任务的常用数据集进行了介绍,并对已有模型在一些数据集上 的实验结果进行分析与比较.第五部分中,我们对模型的类别、提出时间及优缺点进行总结.第六部分介绍了与 此任务有关的探索工作,并对该领域面临的挑战和发展趋势进行了展望.
基于排序的方法
本章首先介绍视频检索片段中的基于排序的方法,这类方法的核心在于对候选片段进行排序.这种解决方 案由于实施简单,易于解释和理解,成为了视频片段检索领域的主流方案之一.具体来说,根据产生候选片段的 过程不同,可进一步将基于排序的方法细分为预设候选片段的方法和有指导地生成候选片段的方法.前者是人 为地、穷举地切分视频为候选片段,然后按照与查询语句的相关程度对它们进行排序.后者则首先利用模型排 除掉大多数无关的候选片段,然后再对生成的候选片段排序.从模型的输入来看,预设候选片段的方法会直接将 预先切分好的视频片段送入模型,而有指导地生成候选片段的方法则以视频为模型的输入.图 2展示了两者在 思路上的区别.

预设候选片段的方法
.
预设候选片段的方法需要在无查询语句信息的情况下,对视频预先地进行划分,生成可能的候选片段集合.这种方法借鉴了多示例学习的思想,在训练阶段,每个候选片段可以被看作是一个带有标签的示例.划分预设的 候选视频片段的方法可以分为以 Gao 等人[10]提出的模型为代表的方法和以 Hendricks 等人[9]提出的模型为代 表的方法.第一类方法,以跨模态时序回归定位器(Cross-modal Temporal Regression Localizer, CTRL)[10]为代表,以有 80%重叠部分的不同尺度滑动窗口为基准,对视频进行划分;第二类方法,以时刻上下文网络(MomentContext Network, MCN)[9]为代表,对视频直接进行相同尺度的切分.这两类方法均采取了先提取多个候选片段 再多中选优的思路.具体来说,这两类方法最主要的区别是,相对于 MCN模型,CTRL模型构建的滑动窗口片段 是层级化的,且片段之间有大面积重叠,如图 2 所示.
有指导地生成候选片段的方法
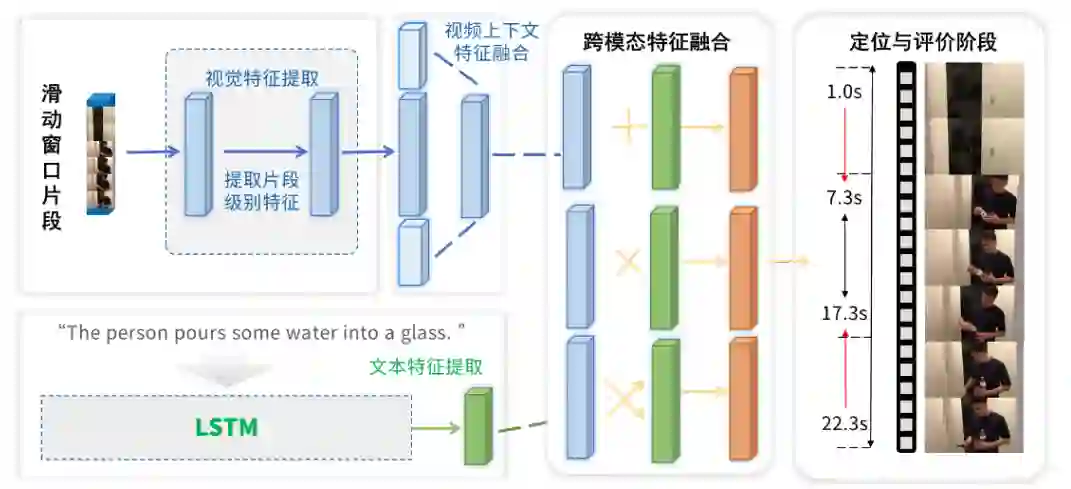
有指导地生成候选片段,即以查询语句或视频本身为指导,探索视频中的哪个片段更有可能与查询语句 相关,从而确定候选片段.此类论文大多是先对整个视频进行处理,得到视频级别的视觉特征,在与查询语句 进行模态间融合之后,根据结果产生候选片段,最后对每个候选片段计算分数.由于是提取视频级别的特征,这类方式能够避免对重复的帧进行多次处理和计算.根据生成候选片段的阶段不同,此类模型可以分为三类.第一类是在没有查询语句作为指导的情况下,直接利用视觉信息生成候选片段.第二类是在对查询语句进行。编码之后,利用文本信息给出的指导生成候选片段.第三类则是在对视觉信息和文本信息进行跨模态融合之 后,生成候选片段.一般来讲,候选片段的生成时间越晚,计算资源的浪费就越少,但也更易丢失有用信息.此外,在有指导地生成候选片段的方法中,弱监督学习和强化学习多次被使用.
基于定位的方法
不同于第二部分介绍的基于排序的一类方法,基于定位的这类方法不以候选视频片段为处理单位,而是以 整个视频为处理单位,直接以片段时间点作为预测目标.因此,相对于有指导地生成候选片段的排序方法而言,基于定位的方法能够较为明显地减少计算成本,几乎完全消除对于视频的重复处理和计算.考虑到定位的方式 又根据是否经过迭代,本章将要介绍的基于定位的方法可以进一步划分,分别是一次定位的方法和迭代定位的 方法.前者直接输出目标预测节点,后者则会在生成预测节点后对节点进行迭代地调整.两者在思路上的区别展 示在图 5 中.

4 数据集与实验
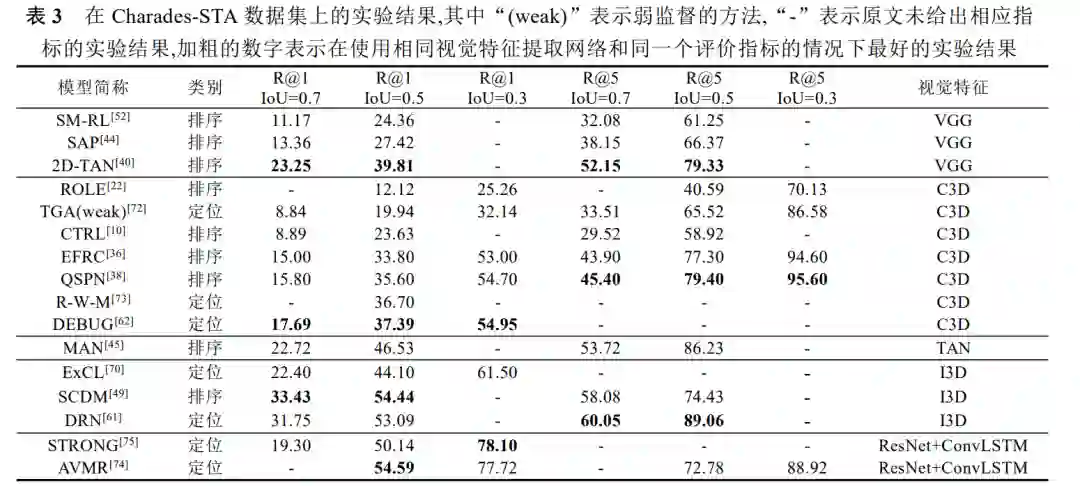
可以 用于视 频片段 检索领 域的数 据集 包括 Regneri 等人[7]提出 的 TACoS,Hendricks等人 [9]提出 的 DiDeMo,Gao 等人[10]在 Charades 数据集[78]的基础上提出的 Charades-STA,Krishna 等人[79]提出的 ActivityNetCaptions,Hendricks 等人[80]在 DiDeMo 数据集的基础上进行调整,得到的 TEMPO-TL及 TEMPO-HL两个数据 集,以及 Lei 等人[55]提出的 TVR 数据集.这些数据集的基本信息如表 2 所示:

评价度量
视频片段检索任务中一些常见的评价指标如下.通常来说,这些指标的数值越大,代表方法的性能越好.
(1) R(n,m),也可被写为“R@n,IoU=m”,表示的是在返回的前 n 个结果中,交并比指标(IoU)大于 m(∈(0,1])的结果(至少一个)占总体 n 个返回结果的比例.例如,在某次测试中,共有 1~8 号共 8个样本,其对应返回的 IoU值分别为 0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,若将 m 设置为 0.7,则满足条件的为 7~8共 2个样本,那么 R(n,m)即 R(8,0.7)的结果应为 2/8=0.25.因为大部分基于定位的方法对于每个测试样例仅会返回一个结果,所以只会出现 R(1,m)的情形.
(2) mIoU,也称为平均 IoU,表示的是所有测试样例的第一个返回结果对应 IoU的平均值.
(3) Rank@n,也写作 Rank-n accuracy,表示的是最匹配结果出现在前 n 个结果中的百分比,一般 n取 1或 5.等同于 R(n,1)指标.
(4) Acc@0.5,适用于定位任务,表示的是模型产生的返回结果(一个查询语句仅返回一个结果)与真实标签 间的 IoU 高于 0.5 的比例,等同于 R(1,0.5)指标.
模型总结
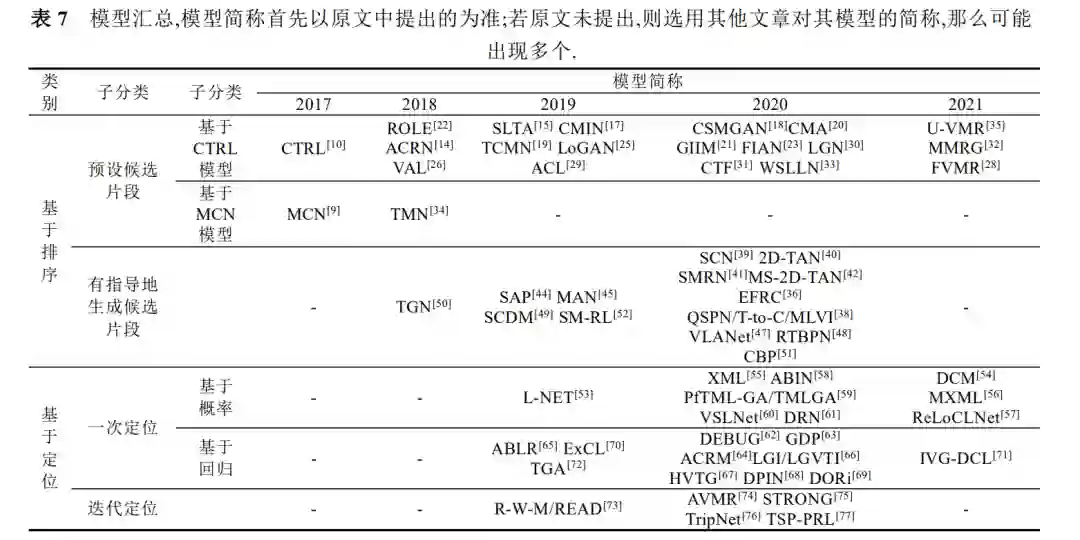
在这一部分,我们将对前述的模型进行简要总结,并提出当前方法可能的改进方向及发展趋势. 表 7 将前述模型的所属类别及提出时间进行了汇总.表 8 对各类方法的主要思想及特点进行了对比总结.

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“VMR” 就可以获取《「视频片段检索」最新2022研究综述》专知下载链接





