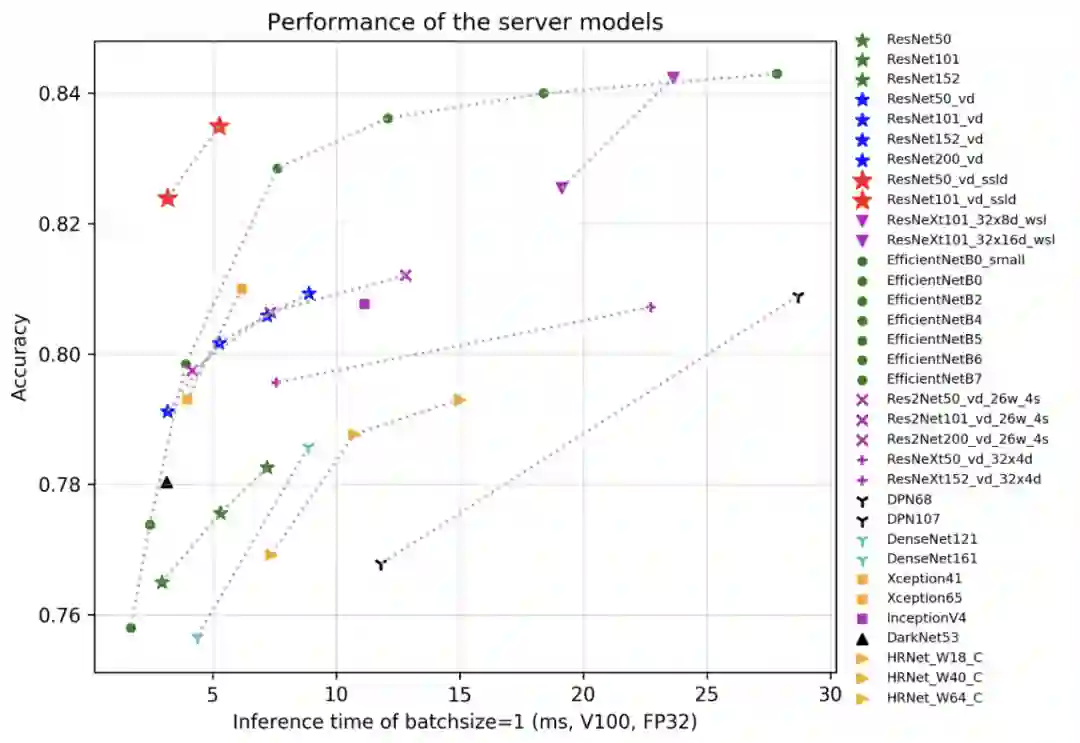
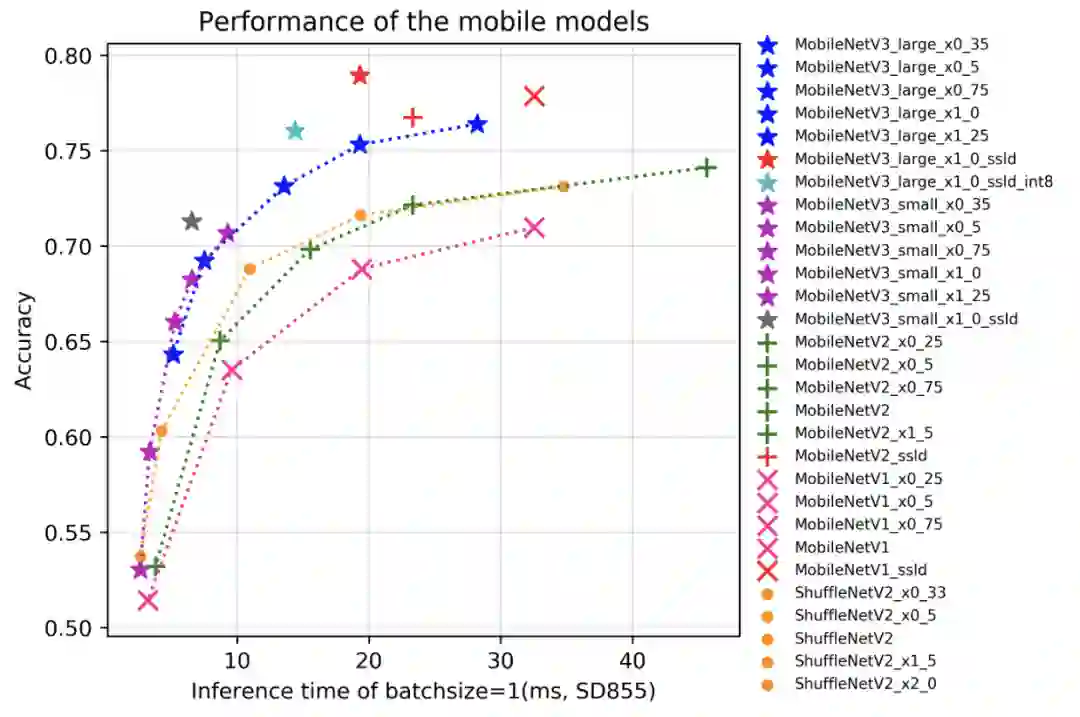
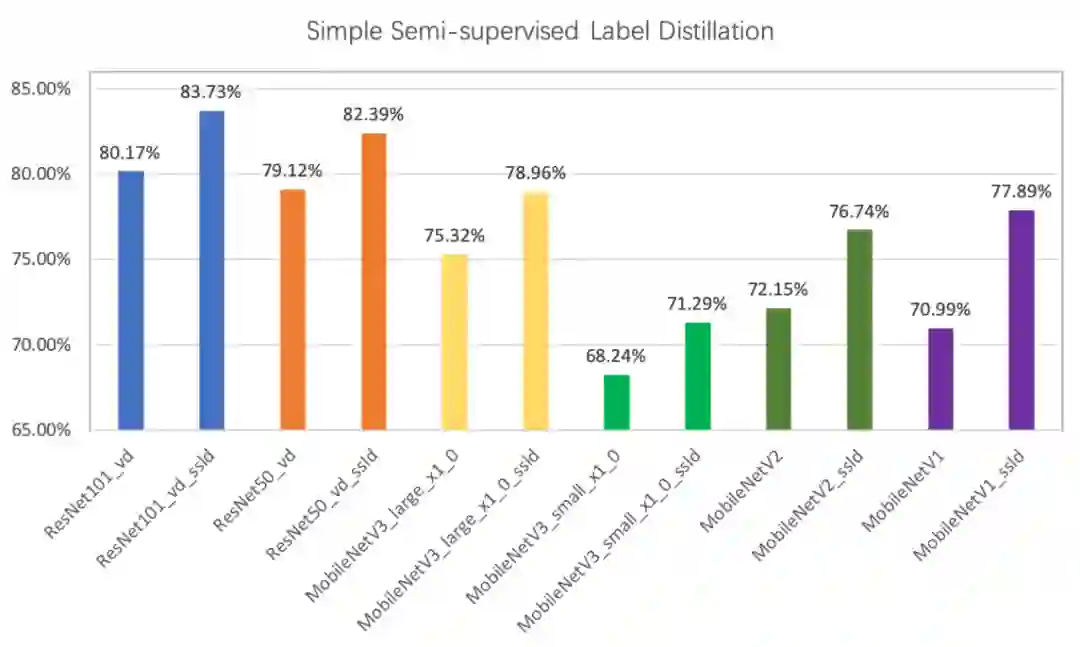
23个系列分类网络,10万分类预训练模型,这是飞桨PaddleClas百宝箱
机器之心发布
机器之心编辑部
如何训练出优秀的图像分类模型?飞桨图像分类套件 PaddleClas 来助力。



occlusion:识别目标被遮挡
scale:识别目标的尺度变化
deformation:识别目标变形
clutter:识别目标所处的背景嘈杂
illumination:识别目标所处环境的光照变化
viewpoint:拍摄识别目标的视角变化
object pose:识别目标的姿态变化


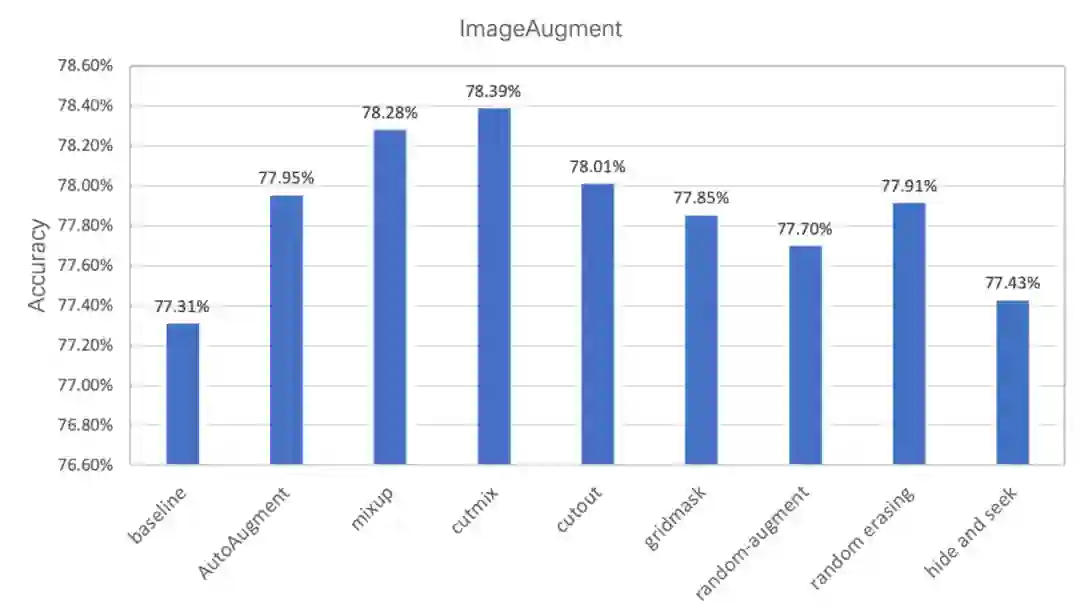
图像变换类是指对全图进行一些变换,包括 AutoAugment、RandAugment。
图像裁剪类是指对图像以一定的方式遮挡部分区域的变换,包括 CutOut、RandErasing、HideAndSeek、GridMask。
图像混叠类是指多张图进行混叠一张新图的变换,包括 Mixup、Cutmix。

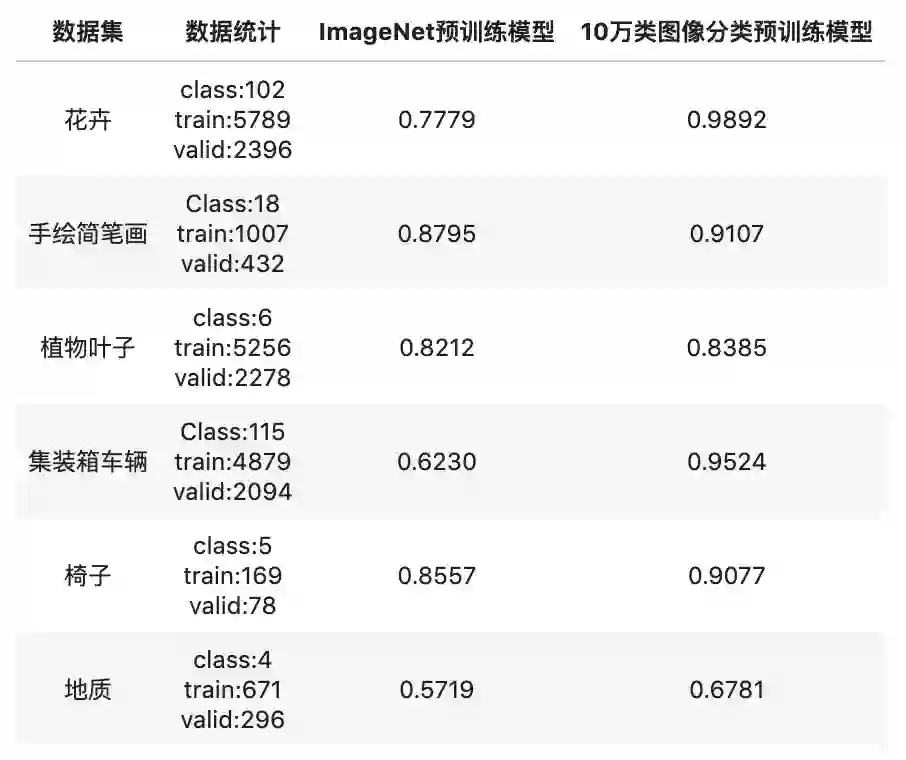
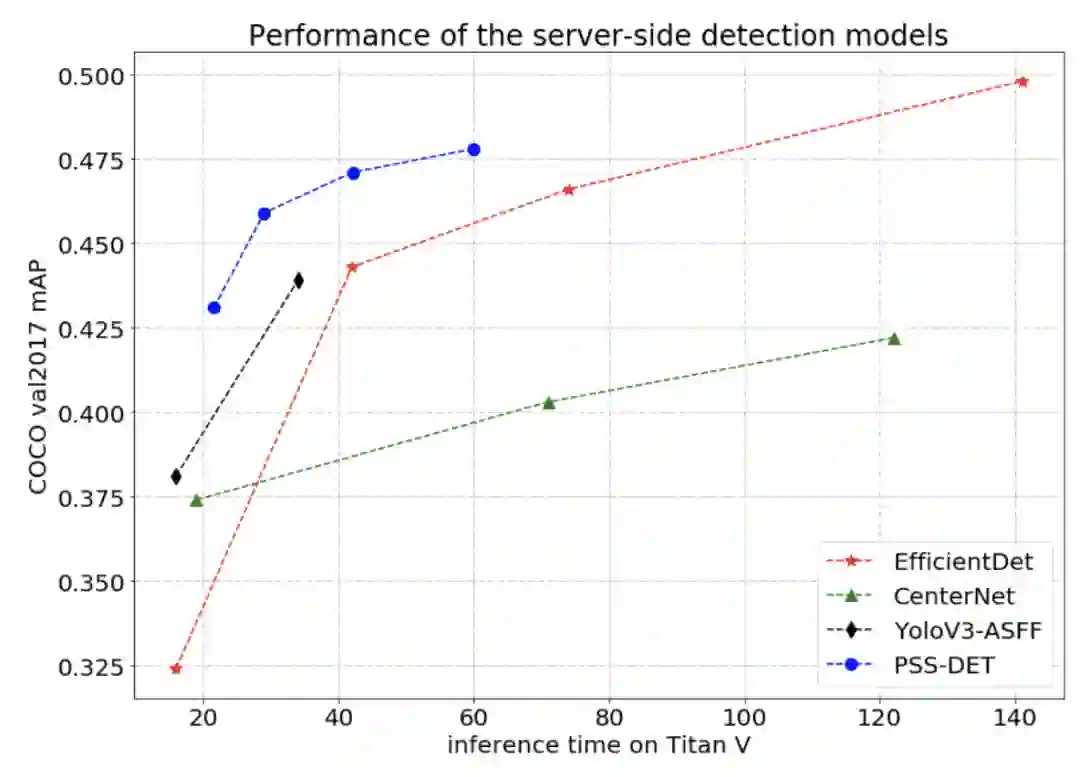
GitHub: https://github.com/PaddlePaddle/PaddleClas
Gitee: https://gitee.com/paddlepaddle/PaddleClas
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle
登录查看更多
相关内容

专知会员服务
30+阅读 · 2020年4月22日
Arxiv
3+阅读 · 2019年3月20日
Arxiv
15+阅读 · 2018年10月11日



相关VIP内容
专知会员服务
30+阅读 · 2020年4月22日
相关资讯
相关论文
Arxiv
3+阅读 · 2019年3月20日
Arxiv
15+阅读 · 2018年10月11日