深度学习在GPU和KNL上的扩展(下)
(点击上方公众号,快速关注,福利早知道)
今天我们继续聊<深度学习在GPU和KNL上的扩展>,,,
EXPERIMENTAL SETUP
(1) 实验数据集
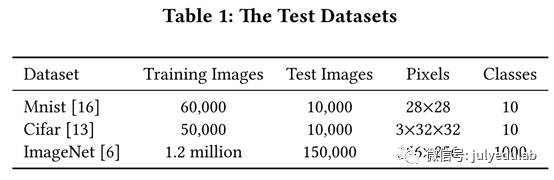
我们的测试数据集是Mnist、Cifar、和ImageNet,这些都是标准的深度学习测试集,具体见表1。Mnist数据集的应用都是手写数字的识别,Mnist的图片被划分为10类(0,1,2,……,9)。Cifar数据集的应用都是物体识别,Cifar数据集中的图片也可以划为10类:飞机、机动车、鸟、猫、鹿、狗、青蛙、马、船、卡车。Mnist和Cifar的随机猜测精确度预测是0.1.
ImageNet是一个超过一千五百万张图片的计算机视觉数据集,这些图片可以被划分到超过20000种类别中。这些图片图片都是从网站上搜集来的,然后由使用亚马逊的Mechanical Turk crowd-sourcing 工具的人类贴标签机进行标签。一个起源于2010年的年度竞赛ImageNet Large-Scale Visual Recognition
Challenge(ILSVRC)使用的测试集就是imageNet的子集,该子集从1000个类别的每个类别中分别选取1200张图片。共计有大约一百二十万张训练图片,五万张验证图片和十五万测试图片。本文中的ImageNet数据集是2012年ILSVRC的数据集。预计ImageNet图片的随机猜测精确度为0.001.
(2) 神经网络模型
本文我们使用最先进的DNN模型来进行数据集的运行。我们使用LetNet来执行Mnist数据集,该模型如图3所示。使用AlexNet模型来执行Cifar数据集的运行,该模型有五个卷积层和三个全连接层。ImageNet数据集则在22层的GoogleNet模型和19层的VGG模型上运行。
(3) 基线(the baseline)
下一章的原生EASGD即是我们的基线。原生EASGD(算法1)方法使用轮询方式来进行master和workers的通信调度,master在任何时候都只能与一个worker进行交互。,且不同的workers的交互是有序的(第i+1个worker不能在第i个worker之前与master交互,按机器等级ID排序)。
DISTRIBUTED ALGORITHM DESIGN
(1) 并行SGD方法的重新设计
本章节我们基于现有方法(即,原生EASGD、异步SGD、异步MSGD和Hogwild SGD)来设计一些有效的并行SGD方法。我们将我们的方法与现有方法进行对比(即,我们在相同的数据集和计算资源下进行时间和精确度的对比)。因为现有SGD方法最初是部署在GPUs上的,所以我们也将我们的新方案运行在GPUs上。这些方法我们也会在KNL芯片上运行,因为大家更关心这些方法在芯片间的运行而不是芯片内。(这个很好理解,毕竟这是分布式系统嘛)
异步EASGD:原生EASGD方法(Algorithm 1)使用轮询方式来进行调度,该方法对HPC来说是非常低效的,因为不同GPUs间的计算和更新必须是有序的,第i个worker更新之前不允许第i+1及之后的workers更新。不可否认该方法有很好容错性和收敛性,但它的低效也是难以忽略的。因此,我们的第一个改进就是使用参数-服务器更新方式来取代轮询更新方式。我们的异步EASGD与原生EASGD的不同之处在于,我们使用先到先服务(FCFS)的机制来处理多个workers而它们使用顺序规则来处理多个workers。
我们将全局权重W放在master机器上,第i个worker有它自己的本地权重Wi,在第t次迭代过程中,有以下三个步骤:
l 第i个worker首先将它的本地权重Wit传递给master,然后master返回Wt给第i个worker(i∈{1,2,……,p})。
l 第i个worker计算梯度ΔWit并且接收Wt。
l Master使用公式(2)进行更新,worker使用公式(1)进行更新
从图6.1我们可以看出,我们的异步EASGD要快于异步SGD。
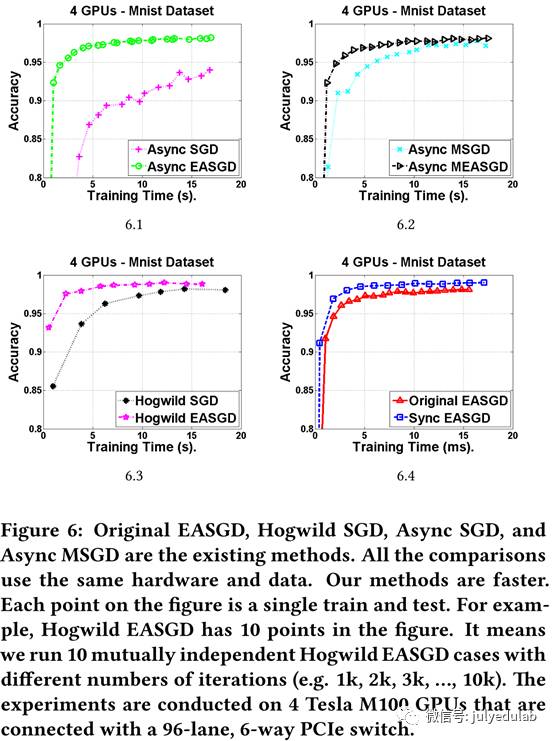
异步MEASGD:动量是一个提速SGD的重要方法。动量(Momentum)SGD的更新规则如公式(3)和(4)所示,V是动量参数,它与权重和梯度有相同的维度,μ是动量率,按经验来说,μ=0.9或者是近似值。在我们的设计中,MEASGD的master的更新规则与前面公式(2)相似,而第i个worker的更新方式变为公式(5)和(6)。从图6.2中我们可以看出,我们的异步MEASGD要比异步MSGD更快更稳定。
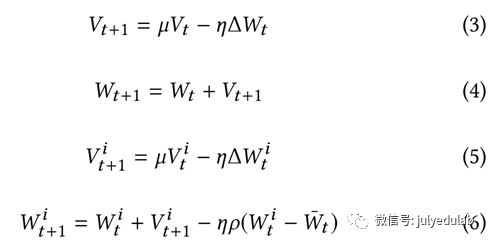
Hogwild EASGD:Hogwild SGD为了获得更快的收敛而去除了更新W时的锁机制。对常规EASGD来说,在进行Wt+1 = Wt +ηρ(Wit − Wt )和Wt+1 = Wt +ηρ(Wjt − Wt )(i,j∈{1,2[中华1] ,…,P})时要加锁,以防止两个同时到达时的并发问题。在Hogwild EASGD中我们同样地去除锁机制来加快收敛(我们像Hogwild SGD一样,将常规EASGD中的锁机制去除得到Hogwild EASGD)。从图6.3中我们清楚看到,Hogwild EASGD比Hogwild SGD运行更快,同时Hogwild EASGD的收敛性证明在https://www.cs.berkeley.edu/∼youyang/HogwildEasgdProof.pdf中。
同步EASGD:同步EASGD的更新规则是公式(1)和(2),同步EASGD在第t次迭代是包含以下五步:
l 第i个worker基于它的数据和权重Wit(i∈{1,2,…,P})计算它的子梯度ΔWit
l Master将Wt广播给所有workers
l 系统通过一个归约操作(reduce operation)来得到∑Pi=1Wti并将它发送给master
l 第i个worker基于公式(1)更新它的本地权重Wit
l Master基于公式(2)更新Wt
在上述步骤中,步骤(1)和(2)可以重叠,步骤(4)和(5)可以重叠。从图6.4我们看出,同步EASGD比原生EASGD要快。
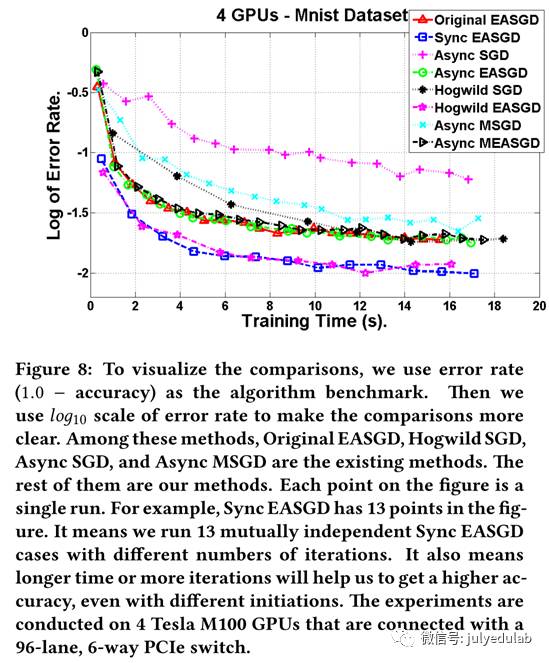
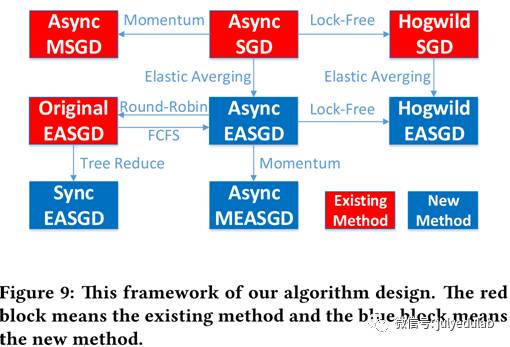
我们制作了一个全体对比图,图8。在图8中,原生SGD、Hogwild SGD、异步SGD和异步MSGD是已存在的方法。我们已经从图6中看到,我们的方法总是比现有算法的相应版本要快。我们也可以看出,同步EASGD和Hogwild EASGD比起的方法比起来是最快的,两个基本上是并列最快。同步EASGD。我们的算法设计框架如图9所示,展示了这些算法间的区别。
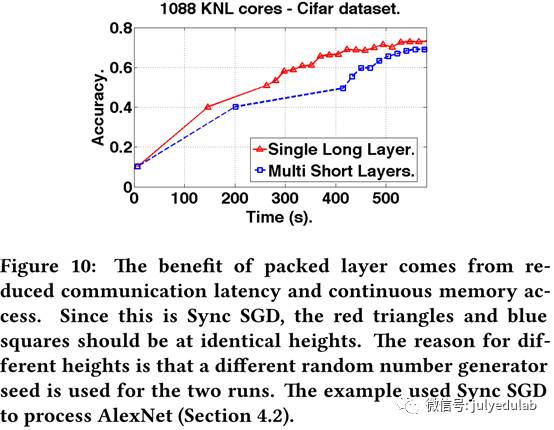
(2) 单层通信
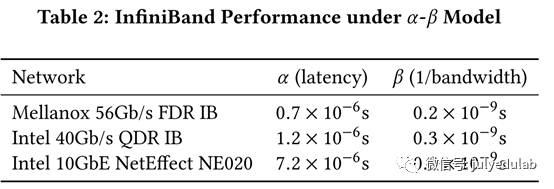
当前深度学习系统为不同的神经网络层分配不相邻的内存,也会为不同层进行多轮通信。我们以连续的方式分配神经网络,并将所有的层包在一起,每次进行一次通信,这种方式明显减小了延迟。从图10我们可以看出这种技术的优势。改善的原因有两个:1)发送一个n-word的信息的消耗可以被公式化为α-β模式:(α + β × n)秒,α是网络延迟,β是网络带宽的倒数,β通常远小于α(表2)。因此,传输相同数据量时,发送一个大信息(big message)就比许多个小信息(small messages)要好得多;2)连续内存访问要比非连续内存访问缓存命中率更高。
ALGORITHM-ARCHITECTURE CODESIGN
(1) 多GPU优化
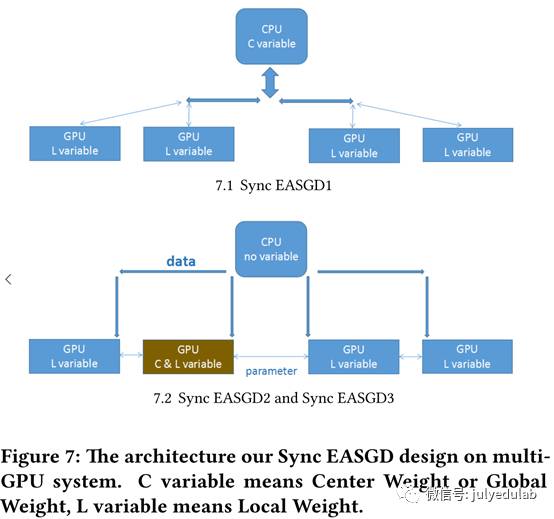
本小结我们展示如何在一个多GPU系统中一步一步优化EASGD。我们使用同步EASGD1,同步EASGD2和同步EASGD3来示意我们的优化三部曲。
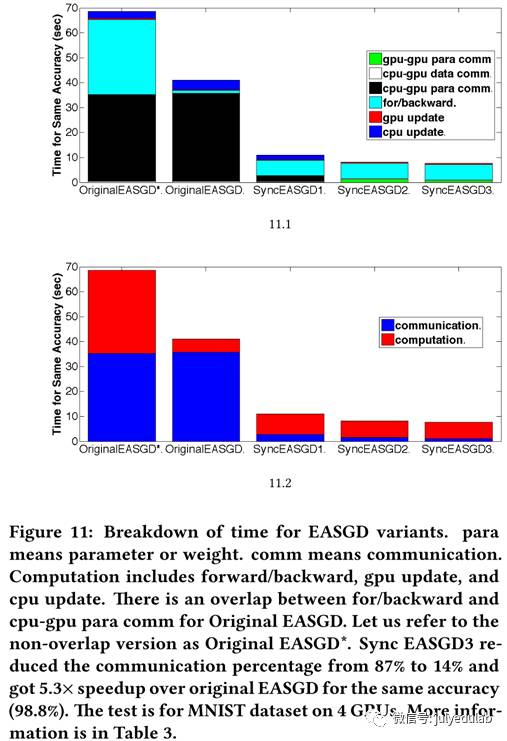
同步EASGD1:算法1是原生的EASGD算法,多GPU系统的实施包含8个潜在耗时部分。对算法1来说,它们是:1)数据I/O;2)数据和权重初始化(第1-2行);3)GPU-GPU的参数通信(none);4)CPU-GPU数据通信(第9行);5)CPU-GPU参数通信(第10行和第12行);6)向前向后传播(第11行);7)GPU权重更新(第13行);8)CPU权重更新(第14行)。我们忽视1)和2),因为他们的时间消耗量百分比很小。GPU-GPU参数通信即不同GPUs的权重交换,CPU-GPU数据通信即GPU每次迭代时复制的一批图片,CPU-GPU的参数通信即CPU发送全局权重给GPU并接收GPU的本地权重。3)4)和5)是通信,6)7)和8)则是计算。在基准测试后,我们发现EASGD的主要消耗都集中在通信上(图11),占到了8GPU系统的训练总时长的87%。如果我们再继续深入看通信,我们会发现CPU-GPU参数通信要比CPU-GPU数据通信耗时的多(86% vs 1%),这主要是因为权重大小(W的元素个数)要远大于一批训练数据的大小。例如,AlexNet的权重是249MB而一批64张Cifar图片只有64 × 32 × 32 × 3 × 4B = 768 KB。为了解决这个问题,我们设计了同步EASGD1(algorithm 2)。在同步EASGD1中,P个块传送/接收操作可以通过tree-reduction操作(例如,标准MPI操作)来有效执行,tree-reduction操作可以将通信负担从P(α + |W|β) 降至 logP(α + |W|β)。我们实验表明,同步EASGD1相比原生EASGD提速3.7倍(表3和图11)。
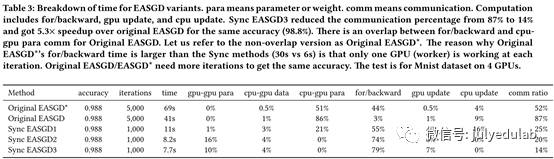

同步EASGD2:从表3我们可以看出,CPU-GPU通信仍然是通信的主要负担,因此我们想要将数据或者权重之一从CPU移动到GPU来减小通信消耗。我们不能将所有数据都放到GPU,因为相比CPU而言,GPU的片上内存有限。例如ImageNet的训练数据是240GB,而K80的片上内存只有12GB,所以此算法需要随机从数据集中挑选出样品,但是我们却不能预测哪部分数据被那个GPU使用。因此我们将所有训练和测试数据都放在CPU上,仅在每次迭代的运行时间将需要的数据复制到GPU。另一方面,权重通常是小于1GB的,我们可以将其存在GPU上。这样也可以方便每次迭代时的权重重利用(algorithm 3)。我们将所有权重放在GPU上来减少通信消耗,我们称该方法为同步EASGD2,该方案比同步EASGD1相比要提速1.3倍。同步EASGD2的框架如Algorithm 3描述。

同步EASGD3:我们通过将计算和通信重叠来进一步提升算法。我们在算法3的步骤7-14中最大化了重叠优势。因为向前/向后传播使用来自CPU的数据,7-10步是关键路径。GPU-GPU通信(步骤11-12)不依赖于步骤7-10,因此我们将算法3中步骤7-10和步骤11-12重叠,得到同步EASGD3。同步EASGD3相比同步EASGD2而言提速了1.1倍。总的来说,同步EASGD3相比原生EASGD,在不损失精度的前提下,通信率从87%降至14%并获得了5.3倍的提速(表3和图11)。因此我们认为同步EASGD3是通行高效的EASGD。我们也为KNL设计了相似的算法,如算法4示。

(2) Knights Landing 优化
我们的KNL芯片有68或72个核,远远多于常规CPU芯片,为了充分利用计算功率,数据位置非常重要。而且我们也要在算法级别好好利用KNL的集群模式(BACKGROUND)。我们将KNL芯片分成类似Quad或SNC-4的四部分模式,KNL就会像四个NUMA节点一样工作。用这种方法,我们也将数据复制成4份然后每个NUMA拥有一份。我们也将权重复制四份,每个NUMA一份。所有NUMA节点计算梯度后,我们利用tree-reduction操作来总和这些梯度。每个NUMA节点可以得到一份梯度和的副本并利用这些副本去更新他们自己的权重。这样不同的NUMA节点间不需要通信,除非它们共享梯度。这就是分而治之的方法,“分”的步骤包括复制数据和复制权重,“治”的步骤则是所有部分的梯度求和。通过快速梯度传播,算法速度也能加快。
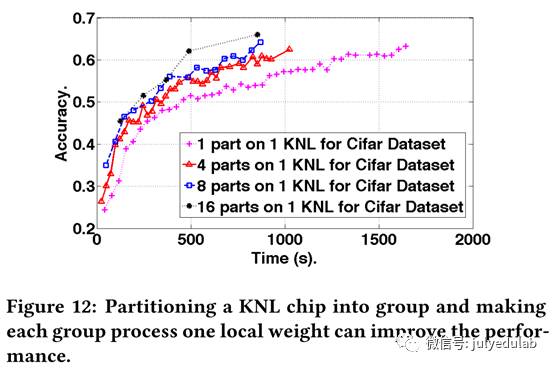
用同样的方法,我们还能将芯片分为8份、16份等等。现在我们将芯片分为P份,这个方法的限制就是快速内存(cache和MCDRAM)应该能够处理P个权重备份和P个数据副本。图12展示了当P<=16情况下,我们用AlexNet上运行Cifar数据集时该方案的表现。因为AlexNet是249MB的权重和687MB的数据,所以MCDRAM可以容纳16份权重和数据副本。具体地,为了实现相似的精确度(.625),1份时,耗时1605秒;4份时,耗时1025秒;8份时,耗时823秒;16份时,耗时490秒。我们通过复制权重和数据来充分利用快速内存、减少通信,最终实现了3.3倍的提速。
文章后面还有些额外的结果和讨论以及附件,主要讨论了和intel caffe的对比还有batch size的影响之类,附件则是源码、数据集和依赖库等有兴趣可以看原文。
原文:Scaling Deep Learning on GPU and Knights Landing clusters --- Yang You,Aydın Buluc¸ James Demmel(UC Berkeley)
注:文中翻译感觉不是特别准的粘贴英文原文