想在手机上用自己的 ML 模型?谷歌模型压缩包你满意

AI 研习社按: Google I/O 2018 上,谷歌发布了可供开发者定制移动端机器学习模型的 ML Kit 开发套件,关于该套件中的核心技术:Learn2Compress 模型压缩技术,谷歌也火速在 Google AI 上撰文对其进行了详细介绍和实战测试,AI 研习社将其内容编译如下。
大家都知道,要成功地训练和运行深度学习模型,通常要求海量的计算资源,超大内存以及足够的能源来支撑,这也就为想要在移动端(mobile)和 IoT 设备上同样成功地运行模型带来了相应的障碍。移动端机器学习(On-device machine learning)允许你直接在该设备上运行推理,且具有保证数据隐私性和随时使用的优势,不管网络连接状况如何。此前的移动端机器学习系统,如轻量神经网络 MobileNets 和 ProjectionNets 均通过对模型效率的优化来处理资源瓶颈问题。但如果你想要在手机上的移动应用中运行自己设计和训练的模型呢?
现在谷歌帮你解决了这个难题,在 Google I/O 2018 上,谷歌面向所有移动端开发者发布了移动端机器机器学习开发套件 ML Kit。该 ML Kit 开发套件中的一项即将可用的核心功能,是由谷歌 research 团队开发的 Learn2Compress 技术所驱动的一项自动模型压缩服务。Learn2Compress 技术能够在 TensorFlow Lite 内定制移动端深度学习模型,定制后的模型可高效的运行在移动端设备上,无需担心内存不足和运行速度过慢。谷歌也很高兴不久后在 ML Ki 中实现 Learn2Compress 技术驱动的图像识别功能。Learn2Compress 技术将率先开放给一小部分开发者,并将在接下来的几个月内提供给更多的开发者们使用。对该技术特性感兴趣并有意设计自己模型的开发者可以访问此网址(https://g.co/firebase/signup)进行注册。
Learn2Compress 技术的工作原理
Learn2Compress 技术融合了此前研究中介绍的 ProjectionNet 等学习框架,并结合了神经网络模型压缩的几项前沿技术。Learn2Compress 技术的工作原理是这样的:先输入一个用户提供的预先训练好的 TensorFlow 模型,随后 Learn2Compress 技术开始训练和优化该模型,并自动生成一个随时可用的移动端模型,该模型尺寸较小,内存占用和能源利用效率更高,且能在保证最小限度丢失准确率的情况下达到更快的推理速度。

可自动生成移动端机器学习模型的 Learn2Compress 技术
为了达成模型压缩的目的,Learn2Compress 技术使用了多重神经网络优化和下面三项模型压缩技术:
通过移除那些对预测没有太大作用的的权重或者运算(比如低分权重)来修剪,降低模型尺寸。该操作尤其能使包含稀疏输入或输出的移动端模型的效率得到相当大的提升,虽然模型在尺寸上被压缩小 2 倍,但仍保留着原来模型 97% 的预测质量。
在训练模型的过程中应用的量子化技术格外有效,该技术可以通过减少用于模型权重和激活数值的位数来提升模型推理速度。例如,使用 8-bit 固定点表示而非浮点数值可以加速模型推理,降低能源消耗以及有望进一步将模型尺寸缩小 4 倍。
遵循老师-学生学习策略的联合训练(Joint training)和蒸馏(distillation)方法—保证最小限度丢失准确率的前提下,谷歌在使用一个大的老师网络(在该案例中,使用的是用户提供的 TensorFlow 模型)来训练一个压缩学生网络(即移动端模型 on-device model)。
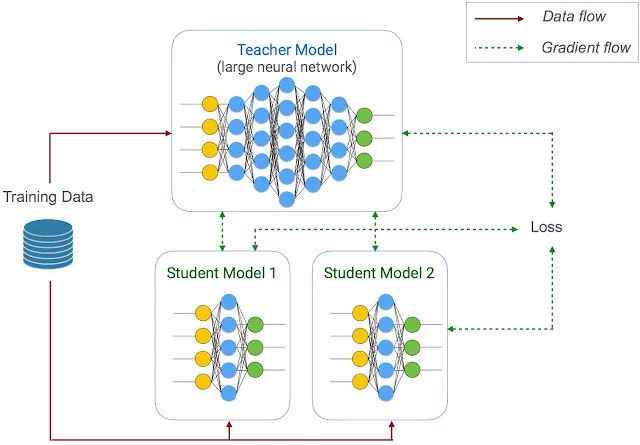
使用联合训练和蒸馏方法来学习压缩学生模型
老师网络可以是固定的(就像在蒸馏方法中那样)或者是被共同优化的,老师网络甚至还可以同时训练不同尺寸的多种学生模型。因而,Learn2Compress 技术只需一次操作就可以生成具有不同尺寸和不同推理速度的多种移动端模型,而非单一模型,同时还支持开发者从中选取最符合自己应用需求的那个模型。
以上这些再加上其他类似迁移学习这样的技术也可以使模型压缩进程更加具有效率和可扩展至大规模数据集。
Learn2Compress 技术的实战表现如何?
为了证明 Learn2Compress 技术的有效性,谷歌基于几个在图像和自然语言任务中使用的最先进的深度神经网络(如 MobileNets,NASNet,Inception,ProjectionNet 等),并使用该技术将它们压缩成移动端模型。给定一个任务和数据集,谷歌就可以使用该技术生成具有不同的推理速度和模型尺寸的多种移动端模型。
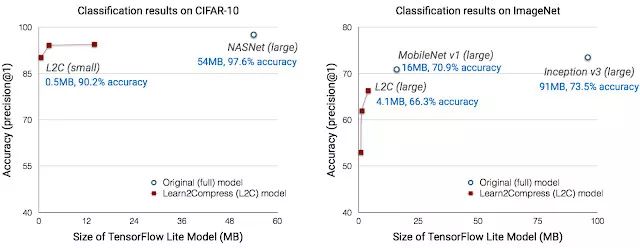
Learn2Compress 模型在多种尺寸下的准确度,在 CIFAR-10(左图)上的全尺寸基线网络,以及 ImageNet(右图)图像识别任务。生成了多种 CIFAR-10 和 ImageNet 分类器变体的学生网络的架构的灵感来自 NASNet 和 MobileNet。
在图像识别方面,Learn2Compress 技术可生成适合手机应用的,且具有良好预测精度的既小又快的模型。举个例子,在 ImageNet 任务上,Learn2Compress 技术可实现一个比 Inception v3 baseline 小 22 倍,比 MobileNet v1 baseline 小 4 倍的模型,而准确率仅下降了 4.6-7%。在 CIFAR-10 上,使用共享参数来共同的训练多种 Learn2Compress 模型所花费的时间,只比训练单独的一个 Learn2Compress 大模型多耗时 10%,例如 yields 3 压缩模型在尺寸上要小 94 倍,而速度上快 27 倍,成本降低 36 倍,且能达到很好的预测质量(90-95% 的 top-1 级别准确度)。
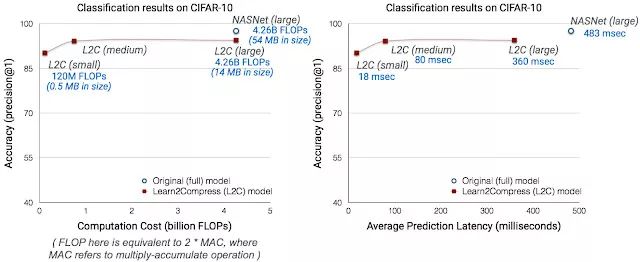
在 CIFAR-10 图像识别任务下,使用 Pixel phone 测试 baseline 和 Learn2Compress 模型得到的计算成本和平均预测延迟。Learn2Compress-优化模型使用 NASNet 样式的网络构架。
谷歌也很开心地看到开发者已经使用这种技术做出了一些成果。例如,一个名为 Fishbrain 的垂钓爱好者社交平台使用了谷歌的 Learn2Compress 技术,将平台目前的图像识别云模型(尺寸大小 80MB+,达到了 91.8% 的 top-3 级别准确度)压缩成了一个十分小的移动端模型(尺寸少于 5MB,但仍保持与原来大模型相似的准确度)。在另外一些案例中,谷歌发现得益于正则化效应(regularization effect),压缩后的模型在准确度上甚至有稍微胜于原来的大模型的可能。
谷歌表示,随着机器学习和深度学习技术的不断发展,他们将会继续改进 Learn2Compress 技术并将其扩展至更多的用户案例(不仅局限于图像识别这类模型)。谷歌还很期待上线 ML Kit 的模型压缩云服务。谷歌希望 Learn2Compress 技术可以帮助开发者自动构建和优化他们自己的移动端机器学习模型,这样开发者们就可以专注于开发包含计算机视觉、自然语言以及其他机器学习应用在内的优秀的应用程序和酷炫的用户体验了。
via Google AI Blog,AI 研习社编译。

从Python入门-如何成为AI工程师
BAT资深算法工程师独家研发课程
最贴近生活与工作的好玩实操项目
班级管理助学搭配专业的助教答疑
学以致用拿offer,学完即推荐就业

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
一场深度学习引发的图像压缩革命
▼▼▼



