曾奇:谈谈我所认识的分布式锁
导读:随着计算机技术和工程架构的发展,微服务变得越来越热。如今,绝大多数服务都处于分布式环境中,其中,数据一致性是我们一直关注的重点。分布式锁到底是什么?经过了哪些发展演进?工程上有哪些实现方案?各种方案的利弊权衡又有哪些?希望这篇文章能够对你有一些帮助。
▍阅读索引
0. 名词定义
1. 问题引入
2. 分布式环境的特点
3. 锁
4. 分布式锁
5. 分布式锁实现方案
5.1. 朴素Redis实现方案、朴素Redis方案小结
5.2. ZooKeeper实现方案、ZooKeeper方案小结
5.3. Redisson实现方案、Redisson方案小结
6. 总结
7. 结束语
8. Reference

▍0. 名词定义
分布式锁:顾名思义,是指在分布式环境下的锁,重点在锁。所以我们先从锁开始讲起。
▍1. 问题引入
举个例子:
某服务记录数据X,当前值为100。A请求需要将X增加200;同时,B请求需要将X减100。在理想的情况下,A先读取到X=100,然后X增加200,最后写入X=300。B请求接着读取到X=300,减少100,最后写入X=200。然而在真实情况下,如果不做任何处理,则可能会出现:A和B同时读取到X=100;A写入之前B读取到X;B比A先写入等等情况。
上面这个例子相信大家都非常熟悉。出现不符合预期的结果本质上是对临界资源没有做好互斥操作。互斥性问题通俗来讲,就是对共享资源的抢占问题。对于共享资源争抢的正确性,锁是最常用的方式,其他的如CAS(compare and swap)等,这里不展开。
▍2. 分布式环境的特点
我们的绝大部分服务都处于分布式环境中。那么,分布式系统有哪些特点呢?大致如下:
* 可扩展性:可通过横向水平扩展提高系统的性能和吞吐量。
* 高可靠性:高容错,即使系统中一台或几台故障,系统仍可提供服务。
* 高并发性:各机器并行独立处理和计算。
* 廉价高效:多台小型机而非单台高性能机。
▍3.锁
我们先来看下非分布式情况下的锁方案(多线程和多进程的情况),然后再演进到分布式锁。
▍多线程下的锁机制:
各种语言有不同的实现方式,比较成熟。比如,go语言中的sync.RWMutex(读写锁)、sync.Mutex(互斥锁);JAVA中的ReentrantLock、synchronized;在php中没有找到原生的支持锁的方式,只能通过外部来间接实现,比如文件锁,借助外部存储的锁等。
▍多进程下的锁机制:
对于临界资源的访问已经超出了单个进程的控制范围。在多进程的情况下,主要是利用操作系统层面的进程间通信原理来解决临界资源的抢占问题。比较常见的一种方法便是使用信号量(Semaphores)。
▍对信号量的操作,主要是P操作(wait)和V操作(signal):
* P操作 ( wait ) :
先检查信号量的大小,若值大于零,则将信号量减1,同时进程获得共享资源的访问权限,继续执行;若小于或者等于零,则该进程被阻塞后,进入等待队列。
* V操作 ( signal ) :
该操作将信号量的值加1,如果有进程阻塞着等待该信号量,那么其中一个进程将被唤醒。
可看出,多进程锁方案跟多线程的锁方案实现思路大同小异。
我们将互斥的级别拉高,分布式环境下不同节点不同进程或线程之间的互斥,就是分布式锁的挑战之一。后面再细讲。
另外,在传统的基于数据库的架构中,对于数据的抢占问题也可以通过数据库事务(ACID)来保证。在分布式环境中,出于对性能以及一致性敏感度的要求,使得分布式锁成为了一种比较常见而高效的解决方案。
▍从上面对于多线程和多进程锁的概括,可以总结出锁的抽象条件:
1)“需要有存储锁的空间,并且锁的空间是可以访问到的”:
对于多线程就是内存(进程中不同的线程都可以读写),多进程中通过共享内存的方式,也是提供一块地方,供不同进程读写。主要目的是保证不同的进线程改动对于其他进线程可见,进而满足互斥性需求。
2)“锁需要被唯一标识”:
不同的共享资源,必然需要用不同的锁进行保护,因此相应的锁必须有唯一的标识。在多线程环境中,锁可以是一个对象,那么对这个对象的引用便是这个唯一标识。多进程下,比如有名信号量,便是用硬盘中的文件名作为唯一标识。
3)“锁要有至少两种状态”:
有锁,没锁。存在,不存在等等。很好理解。
满足上述三个条件就可以实现基础的分布式锁了。但是随着技术的演进,
▍相应地,对锁也提出了更高级的条件:
1)可重入:
外层函数获得锁之后,内层函数还可以获得锁。原因是随着软件复杂性增加,方法嵌套获取锁已经很难避免。但是从代码层面很难分析出这个问题,因此我们要使用可重入锁。导致锁需要支持可重入的场景。对于可重入的思考,每种语言有自己的哲学和取舍,如go就舍弃了支持重入:Recursive locking in Go [ https://stackoverflow.com/questions/14670979/recursive-locking-in-go ]以后go又会不会认为“可重入真香”呢?哈哈,我们拭目以待。
2)避免产生惊群效应(Herd Effect):
惊群效应指,在有多个请求等待获取锁的时候,一旦占有锁的线程释放之后,所有等待方都同时被唤醒,尝试抢占锁。但是绝大多数的抢占都是不必要的。这种情况在多线程和多进程中开销同样很大。要尽量避免这种情况出现。
3)公平锁和非公平锁:
公平锁:优先把锁给等待时间最长的一方;非公平锁:不保证等待线程拿锁的顺序。公平锁的实现成本较高。
4)阻塞锁和自旋锁:
主要是效率的考虑。自旋锁适用于临界区操作耗时短的场景;阻塞锁适用于临界区操作耗时长的场景。
5)锁超时:
防止释放锁失败,出现死锁的情况。
6)高效,高可用:
加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
还有很多其他更高要求的条件,不一一列举了。有兴趣的小伙伴可以看看编程史上锁的演进过程。
▍4. 分布式锁
▍使用分布式锁的必要性:
1)服务要求:部署的服务本身就处于分布式环境中
2)效率:使用分布式锁可以避免不同节点重复相同的工作,这些工作会浪费资源。比如用户付了钱之后有可能不同节点会发出多封短信
3)正确性:跟2)类似。如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失
包括但不限于这些必要性,在强烈地呼唤我们今天的主角---“分布式锁”闪亮登场。
▍5. 分布式锁实现方案
有了非分布式锁的实现思路,和分布式环境的挑战,我们来看看分布式锁的实现策略。
分布式锁本质上还是要实现一个简单的目标---占一个“坑”,当别的节点机器也要来占时,发现已经有人占了,就只好放弃或者稍后再试。
▍大体分为4种
1)使用数据库实现
2)使用朴素Redis等缓存系统实现
3)使用ZooKeeper等分布式协调系统实现
4)使用Redisson来实现(本质上基于Redis)
因为利用mysql实现分布式锁的性能低以及改造大,我们这里重点讲一下下面3种实现分布式锁的方案。
▍5.1 朴素Redis实现方案
我们循序渐进,对比几种实现方式,找出优雅的方式:
方案1:setnx+delete
1setnx lock_key lock_value
2// do sth
3delete lock_key
缺点:一旦服务挂掉,锁无法被删除释放,会导致死锁。硬伤,pass!2
方案2:setnx + setex
1setnx lock_key lock_value
2setex lock_key N lock_value // N s超时
3// do sth
4delete lock_key
在方案1的基础上设置了超时时间。但是还是会出现跟1一样的问题。如果setnx之后、setex之前服务挂掉,一样会陷入死锁。本质原因是,setnx/setex分为了两个步骤,非原子操作。硬伤,pass!
方案3:set ex nx
1SET lock_key lock_value EX N NX //N s超时
2// do sth
3delete lock_key
将加锁、设置超时两个步骤合并为一个原子操作,从而解决方案1、2的问题。(Redis原生命令支持,Redis version需要>=2.6.12,滴滴生产环境Redis version一般为3.2,所以日常能够使用)。
优点:此方案目前大多数sdk、Redis部署方案都支持,实现简单
缺点:会存在锁被错误的释放,被错误的抢占的情况。如下图:
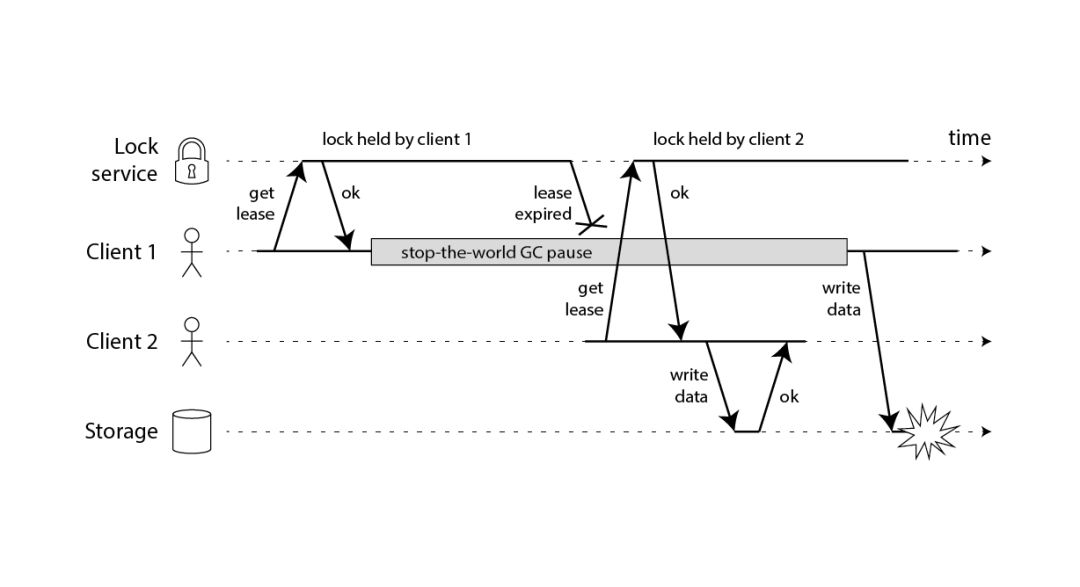
这块有2个问题:
1)GC期间,client1超时时间已到,导致将client2错误地放进来
2)client1执行完逻辑后会显式调用del,将所有的锁都释放了(正确的情况应该只释放自己的锁,错误地释放了client2的锁)
方案4:
在3的基础上,对于问题1,将client的超时时间设置长一些,保证只能通过显式del来释放锁,而超时时间只是作为一种最终兜底的方案。针对问题2,增加对 value 的检查,只解除自己加的锁,为保证原子性,只能需要通过lua脚本实现。
lua脚本:https://redis.io/commands/eval
1if redis.call("get",KEYS[1]) == ARGV[1] then
2 return redis.call("del",KEYS[1])
3else
4 return 0
5end
如果超时时间设置长,只能通过显式的del来释放锁,就不会出现问题2(错误释放掉其他client的锁)。跟滴滴KV store的王斌同学讨论过,目前没有找到方案4优于方案3(只要超时时间设置的长一些)的场景。所以,在我的认知中,方案4跟方案3的优势一样,但是方案3的实现成本明显要低很多。
朴素Redis方案小结
方案3用的最多,实现成本小,对于大部分场景,将超时时间设置的长一些,极少出现问题。同时本方案对不同语言的友好度极高。
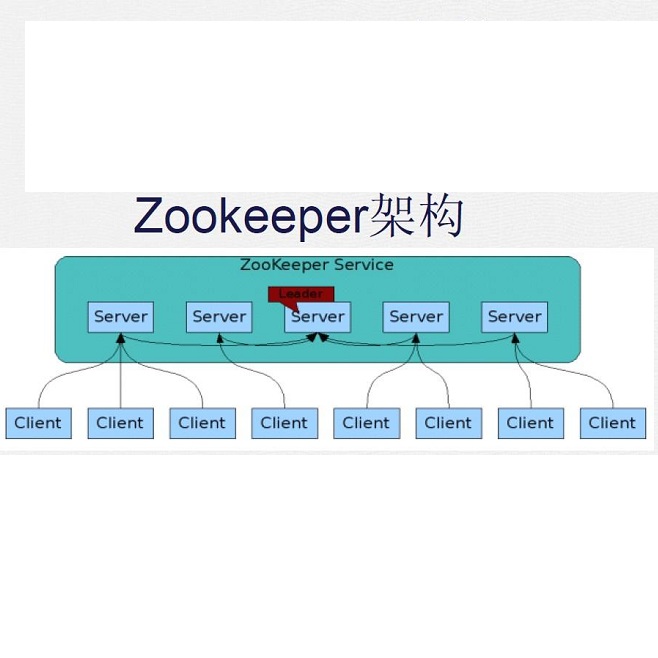
▍5.2 ZooKeeper实现方案
我们先简要介绍一些ZooKeeper(以下简称ZK):
ZooKeeper是一种“分布式协调服务”。所谓分布式协调服务,可以在分布式系统中共享配置,协调锁资源,提供命名服务等。为读多写少的场景所设计,ZK中的节点(以下简称ZNode)非常适合用于存储少量的状态和配置信息。
对ZK常见的操作:
create:创建节点
delete:删除节点
exists:判断一个节点的数据
setdata:设置一个节点的数据
getchildren:获取节点下的所有子节点
这其中,exists,getData,getChildren属于读操作。Zookeeper客户端在请求读操作的时候,可以选择是否设置Watch(监听机制)。
什么是Watch?
Watch机制是zk中非常有用的功能。我们可以理解成是注册在特定Znode上的触发器。当这个Znode发生改变,也就是调用了create,delete,setData方法的时候,将会触发Znode上注册的对应事件,请求Watch的客户端会接收到异步通知。
我们在实现分布式锁的时候,正是通过Watch机制,来通知正在等待的session相关锁释放的信息。
什么是ZNode?
ZNode就是ZK中的节点。ZooKeeper节点是有生命周期的,这取决于节点的类型。在 ZooKeeper 中,节点类型可以分为临时节点(EPHEMERAL),时序节点(SEQUENTIAL ),持久节点(PERSISTENT )。
临时节点(EPHEMERAL):
节点的生命周期跟session绑定,session创建的节点,一旦该session失效,该节点就会被删除。
临时顺序节点(EPHEMERAL_SEQUENTIAL):
在临时节点的基础上增加了顺序。每个父结点会为自己的第一级子节点维护一份时序。在创建子节点的时候,会自动加上数字后缀,越后创建的节点,顺序越大,后缀越大。
持久节点(PERSISTENT ):
节点创建之后就一直存在,不会因为session失效而消失。
持久顺序节点(PERSISTENT_SEQUENTIAL):
与临时顺序节点同理。
ZNode中的数据结构:
data(znode存储的数据信息),acl(记录znode的访问权限,即哪些人或哪些ip可以访问本节点),stat(包含znode的各种元数据,比如事务id,版本号,时间戳,大小等等),child(当前节点的子节点引用)。
利用ZK实现分布式锁,主要得益于ZK保证了数据的强一致性。
下面说说通过zk简单实现一个保持独占的锁(利用临时节点的特性):
我们可以将ZK上的ZNode看成一把锁(类似于Redis方案中的key)。多个session都去创建同一个distribute_lock节点,只会有一个创建成功的session。相当于只有该session获取到锁,其他session没有获取到锁。在该成功获锁的session失效前,锁将会一直阻塞住。session失效时,节点会自动被删除,锁被解除。(类似于Redis方案中的expire)。
上述实现方案跟Redis方案3的实现效果一样。
但是,这样的锁有没有改进的地方?当然!
1)我们可能会有可重入的需求,因此希望能有可重入的锁机制。
2)有些场景下,在争抢锁的时候,我们既不想一次争抢不到就pass,也不想一直阻塞住直到获取到锁。一个朴素的需求是,我们希望有超时时间来控制是否去上锁。更进一步,我们不想主动的去查到底是否能够加锁,我们希望能够有事件机制来通知是否能够上锁。(这里,你是不是想到了ZK的Watch机制呢?)
要满足这样的需求就需要控制时序。利用顺序临时节点和Watch机制的特性,来实现:
我们事先创建/distribute_lock节点,多个session在它下面创建临时有序节点。由于zk的特性,/distribute_lock该节点会维护一份sequence,来保证子节点创建的时序性。
具体实现如下:
1)客户端调用create()方法在/distribute_lock节点下创建EPHEMERAL_SEQUENTIAL节点。
2)客户端调用getChildren(“/distribute_lock”)方法来获取所有已经创建的子节点。
3)客户端获取到所有子节点path之后,如果发现自己在步骤1中创建的节点序号最小,那么就认为这个客户端获得了锁。
4)如果在步骤3中发现自己并非所有子节点中最小的,说明自己还没有获取到锁。此时客户端需要找到比自己小的那个节点,然后对其调用exist()方法,同时注册事件监听。需要注意是,只在比自己小一号的节点上注册Watch事件。如果在比自己都小的节点上注册Watch事件,将会出现惊群效应,要避免。
5)之后当这个被关注的节点被移除了,客户端会收到相应的通知。这个时候客户端需要再次调用getChildren(“/distribute_lock”)方法来获取所有已经创建的子节点,确保自己确实是最小的节点了,然后进入步骤3)。
Curator框架封装了对ZK的api操作。以Java为例来进行演示:
引入依赖:
1<dependency>
2 <groupId>org.apache.curator</groupId>
3 <artifactId>curator-recipes</artifactId>
4 <version>2.11.1</version>
5</dependency>
使用的时候需要注意Curator框架和ZK的版本兼容问题。
以排他锁为例,看看怎么使用:
1public class TestLock {
2
3 public static void main(String[] args) throws Exception {
4 //创建zookeeper的客户端
5 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
6 CuratorFramework client = CuratorFrameworkFactory.newClient(“ip:port", retryPolicy);
7 client.start();
8
9 //创建分布式锁, 锁空间的根节点路径为/sunnyzengqi/curator/lock
10 InterProcessMutex mutex = new InterProcessMutex(client, "/sunnyzengqi/curator/lock");
11 mutex.acquire();
12 //获得了锁, 进行业务流程
13 System.out.println("Enter mutex");
14 Thread.sleep(10000);
15 //完成业务流程, 释放锁
16 mutex.release();
17 //关闭客户端
18 client.close();
19 }
20}
21
△左滑浏览全貌
上面代码在业务执行的过程中,在ZK的/sunnyzengqi/curator/lock路径下,会创建一个临时节点来占位。相同的代码,在两个机器节点上运行,可以看到该路径下创建了两个临时节点:

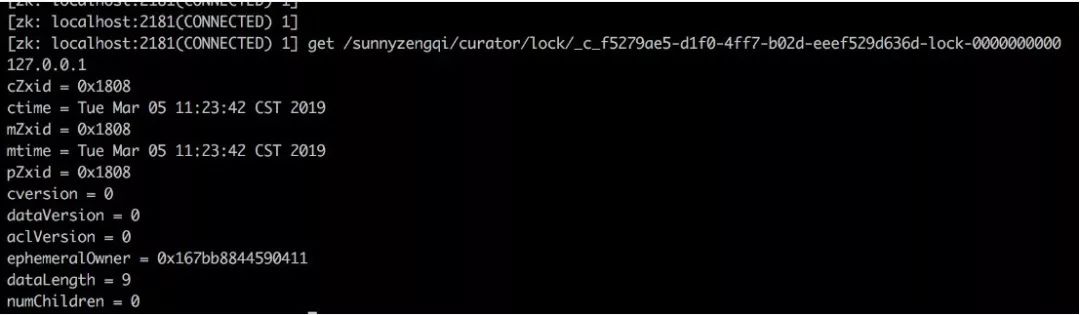
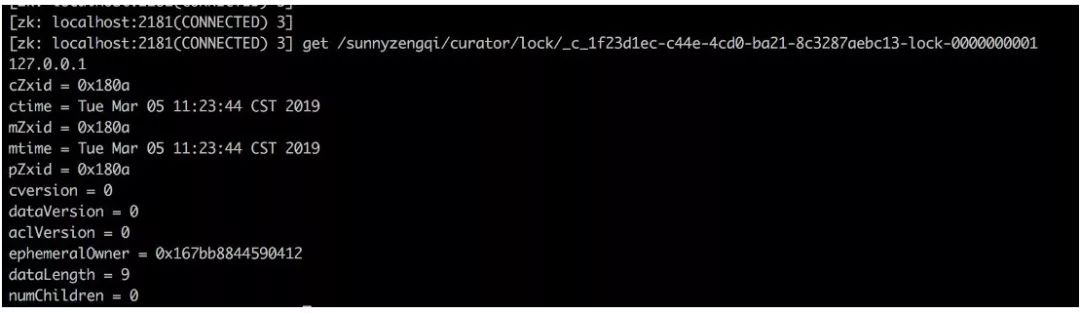
运行命令echo wchc | nc localhost 2181查看watch信息:

可以看到lock1节点的session在监听节点lock0的变动。此时是lock0获取到锁。等到lock0执行完,session会失效,触发Watch机制,通知lock1的session说锁已经被释放了。这时,lock1可以来抢占锁,进而执行自己的操作。
除了简单的排它锁的实现,还可以利用ZK的特性来实现更高级的锁(比如信号量,读写锁,联锁)等,这里面有很多的玩法。
ZooKeeper方案小结
能够实现很多具有更高条件的锁机制,并且由于ZK优越的session和watch机制,适用于复杂的场景。因为有久经检验的Curator框架,集成了很多基于ZK的分布式锁的api,对于Java语言非常友好。对于其他语言,虽然也有一些开源项目封装了它的api,但是稳定性和效率需要自己去实际检验。
▍5.3 Redisson实现方案
我们先简要介绍一下Redisson:
Redisson是Java语言编写的基于Redis的client端。功能也非常强大,功能包括:分布式对象,分布式集合,分布式锁和同步器,分布式服务等。被大家熟知的场景还是在分布式锁的场景。
为了解决加锁线程在没有解锁之前崩溃进而出现死锁的问题,不同于朴素Redis中通过设置超时时间来处理。Redisson采用了新的处理方式:Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。
跟Zookeeper类似,Redisson也提供了这几种分布式锁:可重入锁,公平锁,联锁,红锁,读写锁等。具体怎么用这里不展开,感兴趣的朋友可以自己去实验。
Redisson方案小结
跟ZK一样,都能够实现很多具有更高条件的锁机制,适用于复杂的场景。但对语言非常挑剔,目前只能支持Java语言。
▍6. 总结
上一节,我们讨论了三种实现的方案:朴素Redis实现方案,ZooKeeper实现方案,Redisson实现方案。由于第1种与第3种都是基于Redis,所以主要是ZK和基于Redis两种。我们不禁想问,在实现分布式锁上,基于ZK与基于Redis的方案,有什么不同呢?
1)锁的时长设置上:
得益于ZK的session机制,客户端可以持有锁任意长的时间,这可以确保它做完所有需要的资源访问操作之后再释放锁。避免了基于Redis的锁对于有效时间到底设置多长的两难问题。实际上,基于ZooKeeper的锁是依靠Session(心跳)来维持锁的持有状态的,而Redis不支持Sesion。
优势:ZK>Redisson>朴素Redis。
2)监听机制上:
得益于ZK的watch机制,在获取锁失败之后可以等待锁重新释放的事件。这让客户端对锁的使用更加灵活。避免了Redis方案主要去轮询的方式。
优势:ZK>Redisson=朴素Redis。
3)使用便利性上:
由于生产环境都有稳定的Redis和ZooKeeper集群,有专业的同学维护,这两者差别不大。在语言局限性上,朴素Redis从不挑食。ZK和Redisson都偏向于Java语言。在开发难度上,Redis最简单,几乎不用写什么代码;ZK和Redisson次之,依赖于使用的语言是否有集成的api以及集成稳定性等。
优势:朴素Redis>ZK>Redisson。
4)支持锁形式的多样性上:
上面有提及,ZK和Redisson都支持了各种花样的分布锁。朴素Redis就比较捉急了,在实现更高要求的锁方面,如果自己造轮子,往往费时费力,力不从心。
优势:ZK=Redisson>Redis。
▍7. 结束语
分布式锁在日常Coding中已经很常用。但是分布式锁这方面的知识依然非常深奥。2016年,Martin Kleppmann与Antirez两位分布式领域非常有造诣的前辈还针对“Redlock算法”在分布式锁上面的应用炒得沸沸扬扬。
最后借助这场历史闹剧中Martin的话来结束我们今天的分享。与诸君共勉!将学习当成一生的主题!
对我来说最重要的一点在于:我并不在乎在这场辩论中谁对谁错 —— 我只关心从其他人的工作中学到的东西,以便我们能够避免重蹈覆辙,并让未来更加美好。前人已经为我们创造出了许多伟大的成果:站在巨人的肩膀上,我们得以构建更棒的软件。
……
对于任何想法,务必要详加检验,通过论证以及检查它们是否经得住别人的详细审查。那是学习过程的一部分。但目标应该是为了获得知识,而不应该是为了说服别人相信你自己是对的。有时候,那只不过意味着停下来,好好地想一想。
由于时间仓促,自己水平有限,文中必定存在诸多疏漏与理解不当的地方。非常希望得到各位指正,畅谈技术。
▍Reference
0.Apache ZooKeeper(https://zookeeper.apache.org/)
1.Redisson(https://github.com/redisson/redisson)
2.Redis(https://redis.io/)
3.Redis分布式锁进化史(http://tech.dianwoda.com/2018/04/11/redisfen-bu-shi-suo-jin-hua-shi/)
4.分布式系统互斥性与幂等性问题的分析与解决(https://tech.meituan.com/2016/09/29/distributed-system-mutually-exclusive-idempotence-cerberus-gtis.html)
5.浅谈可重入性及其他(http://t.cn/EXd2CWE)
6.Distributed locks with Redis(https://redis.io/topics/distlock)
7.How to do distributed locking(https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html)
8.Is Redlock safe?(http://antirez.com/news/101)
9.Note on fencing and distributed locks(https://fpj.me/2016/02/10/note-on-fencing-and-distributed-locks/)
本文来自公众号滴滴技术(didi_tech)

架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文