Streamlio的端到端实时处理解决方案
10 月 16 号,本文作者翟佳和 Streamlio 创始人郭斯杰将在 QCon 全球软件开发大会会前培训中详细介绍流计算相关内容及典型应用,包括 10 小时的授课和 2 小时的提问交流。
如果你想学习如何搭建一套高性能、切实可用的实时处理系统,了解分布式系统和实时处理系统设计中常见问题、难点和处理策略,可以点击 「 阅读原文 」报名参与。
更多精彩文章请添加微信“AI 前线”(ID:ai-front)
作为一家初创公司,Streamlio 团队正在全力打造世界上第一个企业级的端到端实时数据处理平台。从前段时间发布的 Streamlio Sandbox 预览版中,我们可以初步了解 Streamlio 平台提供的服务内容。
Streamlio 实时处理平台由三个核心系统(Heron、Pulsar 和 BookKeeper)组成,其中 Heron 提供实时计算(compute),Pulsar 提供持久化的消息系统(messaging),BookKeeper 提供流存储(stream storage)。Streamlio 团队提供了一系列的技术文章来详细阐述平台的各个组成部分的特性:Heron(https://www.streaml.io/blog/why-heron),Pulsar(https://www.streaml.io/blog/why-apache-pulsar)和 BookKeeper(https://www.streaml.io/blog/intro-to-bookkeeper)。
在这篇文章里我们将会讨论一下我们希望的实时处理平台是怎样的,应该提供怎样的服务;并讨论实时计算,持久化的消息系统和流存储服务三个方面是怎样相辅相成,共同组成一个高效的实时处理平台。
持久化的消息系统
(Pulsar-Durable messaging)
消息系统就像是一个实时处理平台的神经系统,它将平台上的各个组件连接在一起。消息系统作为基础的数据管道,不仅在平台内为各个系统组件提供通信服务;而且还是平台与外部 application 之间的交互通道。
如果没有记忆功能,神经系统的价值就会大打折扣。一个 Messaging 系统可以实现得很简单,但是如果一个进入系统的消息不能持久的保存,可以很容易地被丢失,那么这个简单的系统是有缺陷的。一个可靠的消息系统,应该能够保证在系统故障(硬件故障、网络分区等)发生时,未处理的消息也不丢失,这对实时处理平台十分重要。因为实时处理平台的任务是为进入系统的每个消息和请求执行指定的操作,任意一个消息丢失,都可能会带来无法预计的计算结果。特别是有状态计算(stateful computation),在消息的持久化方面有更明显的需求。
例如在一个实时竞拍的系统中。当有人对某个标的出价时,每一个所出的价格,都会直接影响竞拍系统中标的下一个竞拍价。如果丢失掉一个用户的竞拍价格,会影响后面整个竞拍过程,对整个竞拍带来不可预料的结果。
Streamlio 平台选择了使用 Pulsar 来作为消息系统,因为我们需要一个可以信赖的消息传输通道,来避免上面竞价系统所出现的类似的错误场景。Pulsar 是可靠的,因为它的底层使用了比较成熟的企业级的实时数据存储系统 BookKeeper 来作为持久消息的存储,即使在大量数据产生时,它也能够保证零数据丢失。实时处理平台中的消息系统需要提供这样的可靠性和持久化。持久化的消息系统也是实时处理平台的基本需求。
实时处理平台不仅仅需要一个让数据从一个地方流向另一个地方的通道,它还需要、也必须做一些实际的计算工作。从某种意义上说,计算层(Compute)在实时处理平台中扮演的角色非常简单和直接:为数据提供计算。这种计算包括异常模式的检测、应用相关的复杂算法、不同数据源的聚合、对数据的过滤清洗等等。为达到对实时输入得到实时计算结果(每次计算能在几个毫秒内得到结果)的目的,计算系统必须强大而高效。
从易用性方面,计算层需要为开发人员提供便捷的接口。它需要提供易于理解的抽象、稳定可靠的开发环境和较高的开发效率。现在的开发人员已经习惯了在像 PaaS(如 Heroku)和容器平台(如 Kubernetes)上进行应用程序的部署。实时平台计算层的部署过程可以简单的分成两步,首先很容易地将作业处理(对于 Streamlio 平台的 Heron topology)打包成 artifact,然后运行一条简单的命令。换句话说,实时计算平台计算层的使用,应该像使用 PaaS 的感觉。
实时计算平台计算层需要能很容易地解决大型组织和企业的需求,能够满足组织内众多的团队和部门同时使用,来开发、建立、测试、调优和运行数百甚至数千个具有不同复杂性的计算任务;同时应该提供 application 级别的资源精细管理,来提高资源使用效率、控制成本。
Streamlio 平台选择了使用 Heron 来作为实时计算层。因为我们知道 Heron 能够支持上面讨论的计算层的所有需求。Heron 已经在 Twitter 内部非常苛刻的实时计算环境下服务多年,支持了数亿用户级别的服务(如 timeline service)。在数年的不断开发积累和进化完善中,Heron 已经能满足实时计算的几乎所有需求。
尽管我们已经比较熟悉各种各样的存储方案和系统,例如基本的 web 应用后端存储,HDFS、Ceph、SQL 驱动的 report 系统等等,但是实时计算中的存储需求还是比较特别,传统的存储方案包括各种各样的数据库很难满足。适应实时计算需求的存储系统需要做好这三方面的工作:
首先,存储层需要为 Messaging 系统提供持久化的存储。上面我们已经讨论过,丢失消息会给整个实时处理过程带来不可预料的后果。
接着,存储层需要为平台内部和外部 application 提供便捷的接口,也能让开发人员轻松理解和掌控。
第三,存储层需要很容易地支持计算层作业(artifacts)的版本控制(versioning)和分发(distribution)。
Streamlio 平台选择了使用 BookKeeper 来作为存储系统,因为它非常适合实时计算的需求。BookKeeper 在 Streamlio 平台中提供三个方面的支持。
BookKeeper 在后台巧妙地支撑 Streamlio 的 effectively-once 语义,保证零数据丢失,为 Pulsar 系统提供无损的持久化的消息存储。
BookKeeper 为 compute applications(Heron topologies)提供便捷易用的后端存储,来支持计算层的有状态处理(Stateful processing)。
BookKeeper 为计算任务和平台外部的应用程序提供可靠的存储。
BookKeeper 能够很好地满足企业级实时计算完整需求,它能够使用较少的资源来快速响应各种有状态的处理(Stateful processing)。当然,在 Streamlio 平台中,开发者也可以使用熟悉的其他数据库来存储计算的结果,比如存储在 PostgreSQL 或 MongoDB 中。Streamlio 也正在为各种各样的后端存储提供 connector。但是使用这些外部存储需要额外的部署,而且只能用在计算层的计算结果存储上。使用集成在 Streamlio 平台中的 BookKeeper 则不需要任何额外的部署和管理。
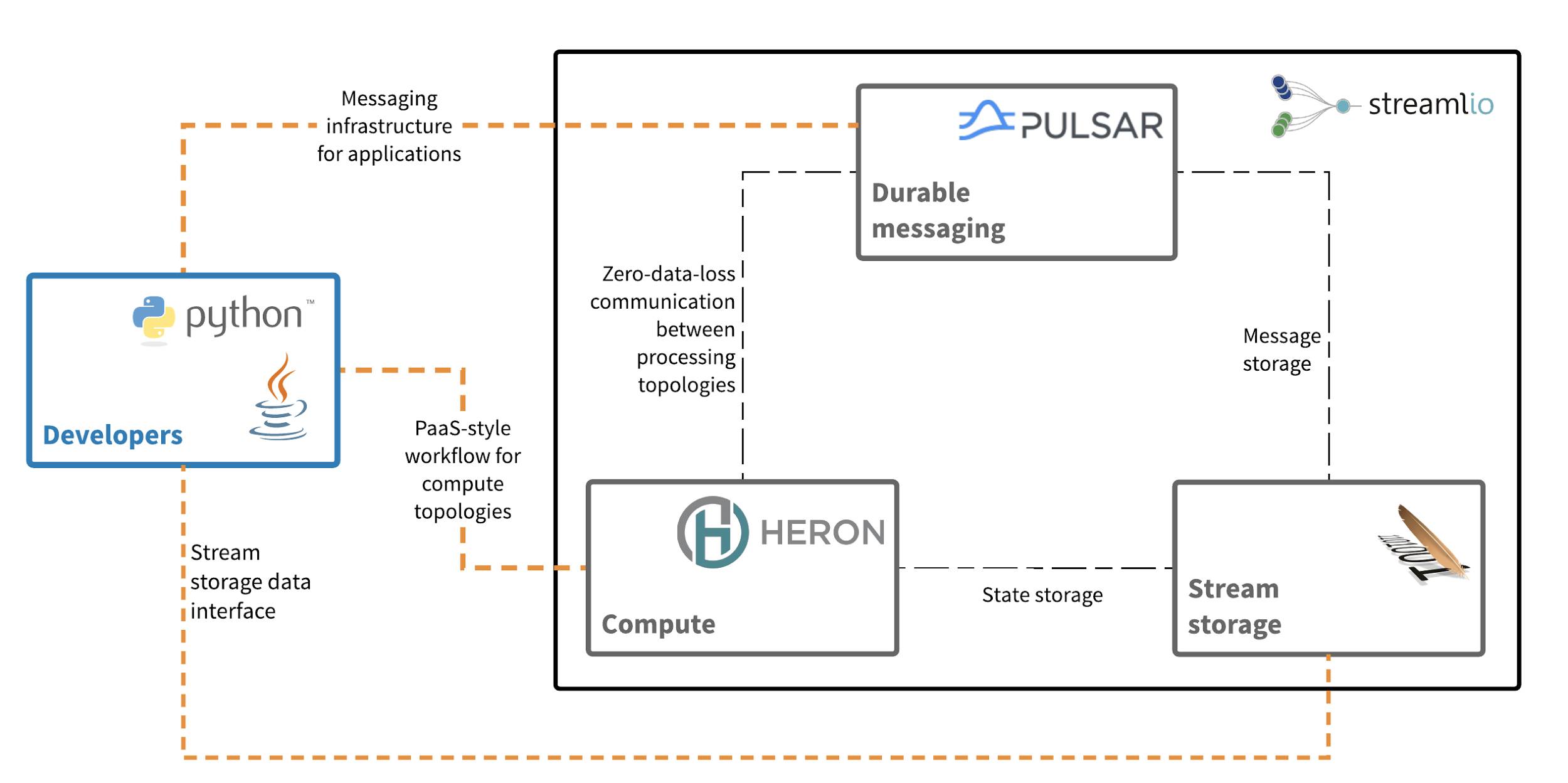
从上面的图中,我们可以看到 Streamlio 的各个组成部分和相互的关联。在这三个部分中,持久化的消息系统、计算系统和流存储系统三者之间是紧密联系不可分割的。
缺了消息系统,计算系统不能获取有效数据;缺了计算系统,整个平台只进行数据传递,失去了处理平台的意义;失去存储系统,消息系统将不再可靠,会丢失数据,有状态的计算任务也不能得到支撑。
Streamlio 将最佳的技术整合在了一起,是一个完整的实时处理平台,即使面对最复杂的组织和应用场景,它也能够满足严格的需求,确保了大型组织和公司能够很容易地接受和使用 Streamlio 平台,使用 Streamlio 平台来支撑成千上万的实时应用程序。
我将在 10 月 16 号和 Streamlio 创始人郭斯杰共同在 QCon 全球软件开发大会会前培训中详细介绍流计算相关内容及典型应用,包括 10 小时的授课和 2 小时的提问交流。
如果你想学习如何搭建一套高性能、切实可用的实时处理系统,了解分布式系统和实时处理系统设计中常见问题、难点和处理策略,可以点击「 阅读原文 」报名参与,开启机器学习工程师之路。报名过程中有任何问题欢迎联系购票经理 Hanna,电话:15110019061,微信:qcon-0410。






