谷歌发布 AVA 数据库:5 万个精细标注视频片段,助力识别人类动作

在计算机视觉研究中,识别视频中人的动作是一个基础研究问题。个人视频搜索和发现、运动分析和手势交流等应用中,都会用到这项至关重要的技术。
尽管过去的几年里在图像中分类和识别物体的技术上,我们已经取得了令人振奋的突破,但识别人类的动作仍然是一个巨大的挑战。从本质上来说,视频中人的行为更难被明确定义,而物体的定义更为明确。所以构建精细动作标记的视频数据集非常困难。目前虽然有许多基准数据集,比如 UCF101、ActivityNet 和 DeepMind Kinetics,采用基于图像分类的标签方案,为数据集中的每个视频或视频片段分配一个标签,但不存在面向复杂场景的视数据集,比如同一时刻多人不同动作的场景。
为了进一步研究识别人类动作的技术,AI研习社了解到,谷歌发布了 AVA (Atomic Visual Actions) 数据库,意思是 “原子视觉动作”,这一新数据集为扩展视频序列中的每个人打上了多个动作标签。 AVA 数据集由 YouTube 公开视频的 URL 组成,这些视频被 80 个原子动作标注,例如走路,踢东西,握手等,所有动作都具有时空定位,产生 5.76 万个的视频片段,9.6 万个人类动作,以及 21 万个的动作标签。
您可以访问 AVA 网站(http://t.cn/RWvunf8),来探索数据集和下载标注,您也可以阅读谷歌发表于 arXiv 上的论文(https://arxiv.org/abs/1705.08421),了解该数据集的设计和开发。
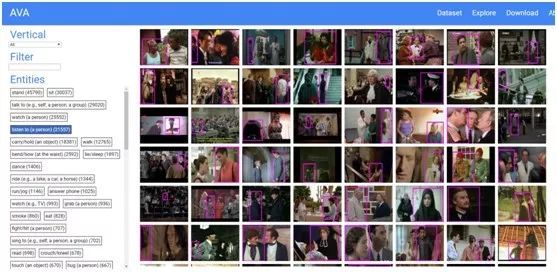
图 1. AVA 网站截图
与其他动作标签数据集相比,AVA 具有以下主要特点:
基于人的标签:每个动作标签都与人相关联,而不是与整段视频或剪辑关联。常见的场景是同一场景中有多个人在执行不同动作,为这些动作分配不同的标签。
基于原子视觉动作:谷歌将动作标签限制在精细的时间尺度(3 秒),在这个尺度上动作都是物理动作,并具有清晰的视觉特征。
基于真实视频资料:谷歌把电影作为 AVA 的数据来源,包括不同国家、不同流派的电影。因此,数据源覆盖了大部分人类行为。

图 2. 3 秒视频片段中间帧中的红色边框标注 (为清晰起见,每个示例仅显示一个边界框)
为了创建 AVA,谷歌首先从 YouTube 收集了大量多样化的视频内容,内容集中在是电影和电视这两个类别,视频里有不同国籍的专业演员。每个视频分析其中 15 分钟的剪辑片段,并这个片段均匀分割成 300 个不重叠小片段,每一段 3 秒钟,这种采样策略保留了动作序列的时间顺序。
接下来,在每个 3 秒片段的中间帧,手动标记边框里的人。打标者从预定义的 80 个原子动作词汇中,选择适当数量的标签来描述人物的行为动作。这些行为分为三组:姿态 / 移动动作、人和物体的交互、人与人的交互。因为对所有人的动作都进行了全面打标,因此 AVA 的标签频率是呈现长尾分布的,如下图所示。
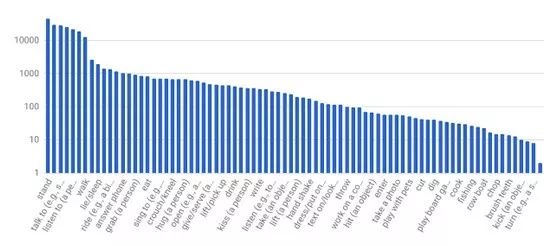
图 3. AVA 的原子动作标签频次分布图(x 轴所示标签只是词汇表的一部分)
由于 AVA 的独特设计,我们可以从中能够得出一些有趣的统计信息,而这些信息从其他现有数据集中是统计不出来的。例如,数据集中多数人具有两个以上的动作标签,那么我们可以找出不同行为标签共现模式(co-occurrence pattern)。下图展示了 AVA 中最有可能并发的动作对及其同时出现的频率分值,例如人们经常在唱歌时玩乐器,和小孩玩耍的时抱起他,亲吻时拥抱。
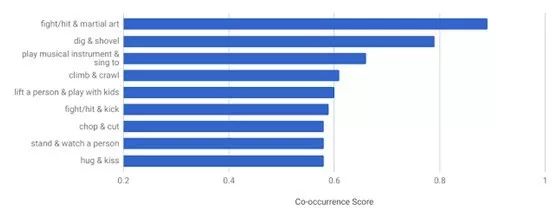
图 4. AVA 中统计得出共现频率分值最高的动作对
为了评估 AVA 数据集在人类行为识别系统中的有效性,谷歌设计了一个现有的基线深度学习模型,该模型在较小的 JHMDB 数据集上获得了很好的绩效。由于视频变焦、背景杂乱、摄影角度和外貌变化等问题,该模型实现了较为不错的表现,正确识别 AVA 中动作的平均准确率达到 18.4%,这表明 AVA 数据集可用于开发和评估新的动作识别架构和算法。
谷歌希望 AVA 的发布能加速人类动作识别系统的发展。基于具有精细时空粒度的标签,对个人复杂活动进行建模将变为现实。谷歌将继续扩充和改进 AVA,并渴望听取来自社区的反馈,帮助校正 AVA 数据集未来的发展方向。请加入 AVA Mail List(http://t.cn/RWlhXt5),即可获得数据集更新,并向谷歌发送电子邮件反馈建议。
via Announcing AVA: A Finely Labeled Video Dataset for Human Action Understanding,AI研习社编译


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
我们应当如何理解视频中的人类行为?
▼▼▼





