独家 | 教你使用Keras on Google Colab(免费GPU)微调深度神经网络

作者:LONG ANG
翻译:闫晓雨
校对:丁楠雅
本文约2300字,建议阅读7分钟。
本文将指导您如何使用Google上的Keras微调VGG-16网络。
简介
在CPU上训练深度神经网络很困难。本教程将指导您如何使用Google Colaboratory上的Keras微调VGG-16网络,这是一个免费的GPU云平台。如果您是Google Colab的新手,这是适合您的地方,您将了解到:
如何在Colab上创建您的第一个Jupyter笔记本并使用免费的GPU。
如何在Colab上上传和使用自定义数据集。
如何在前景分割域中微调Keras预训练模型(VGG-16)。
现在,让我们开始!
1. 创建您的第一个Jupyter笔记本
假定您已登录自己的Google帐户。请按以下步骤操作:
步骤a. 导航到http://drive.google.com。
步骤b. 您将在左侧窗格中看到“我的驱动器”选项卡。现在,在其中创建一个文件夹,比如Colab Notebooks。
步骤c. 右键单击创建的文件夹内右窗格中的其他位置,选择More > Colaboratory。弹出另一个窗口,您可以将笔记本命名为其他窗口,例如myNotebook.ipynb。
恭喜!!!您已经在Colab上创建了您的第一个笔记本😄
2. 为笔记本设置GPU加速器
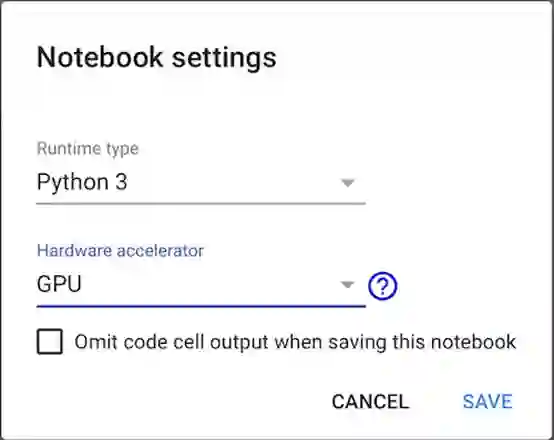
在笔记本中,选择Runtime > Change runtime type。将弹出一个窗口。然后选择您的运行时间类型,从硬件加速器下拉菜单中选择GPU并保存您的设置,如下图所示:
3. 将您的自定义数据集上传到Colab
您已将笔记本设置为在GPU上运行。现在,让我们将您的数据集上传到Colab。在本教程中,我们处理前景分割,其中前景对象是从背景中提取的,如下图所示:

图像来自changedetection.net
将数据集上传到Colab有几种选择,但是,我们在本教程中考虑两个选项;首先,我们上传到GitHub并从中克隆到Colab,其次,我们上传到Google云端硬盘并直接在我们的笔记本中使用它。您可以选择任一选项 a 或选项 b 如下:
步骤a. 从GitHub克隆
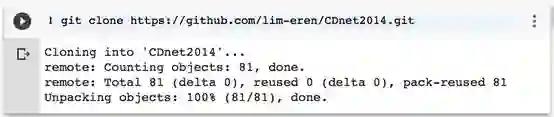
让我们将数据集克隆到创建的笔记本上。在您的笔记本中运行:
!git clone https://github.com/lim-eren/CDnet2014.git.
您会看到这样的东西:
完成!让我们列出训练集,看它是否有效:
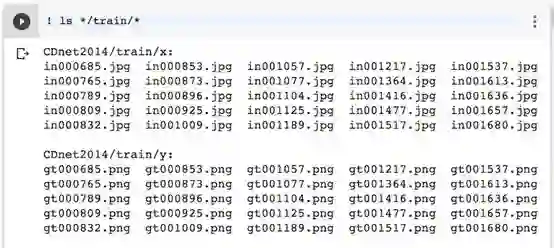
开始了!训练集包含25个输入帧和25个地面真实帧。如果您已完成此步骤,可略过步骤 b并跳转到第4节。
步骤b. 从Google云盘下载
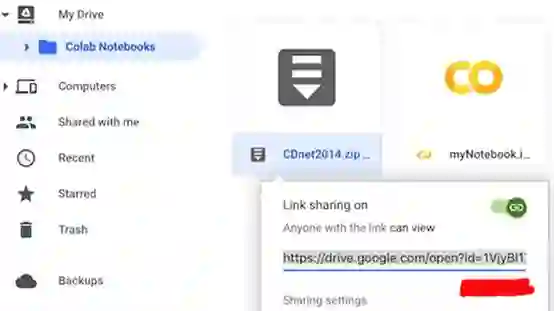
另一种方法是将数据集上传到Google云端硬盘并从中进行克隆。假设您已经压缩了上面的培训集,比如说CDnet2014.zip,并上传到Google Drive中与myNotebook.ipynb相同的目录。现在,右键单击CDnet2014net.zip > 获取可共享链接。复制文件的ID并将其存储在某个地方(稍后我们将使用它)。
然后,通过运行以下代码验证Colab以访问Google云端硬盘。点击链接获取验证码并将其粘贴到文本框下方,然后按Enter键。

然后,让我们将CDnet2014net.zip文件内容下载到我们的Jupyter笔记本中(替换 YOUR_FILE_ID 为上面步骤中获得的id)并通过运行以下代码解压缩它:

完成!您已将数据集从Google云端硬盘下载到Colab。让我们继续第4节,使用这个数据集构建一个简单的神经网络。
4. 微调您的神经网络
将数据集下载到Colab后,现在让我们在前景分割域中对Keras预训练模型进行微调。请按照以下步骤操作:
步骤a. 首先,在笔记本上添加此代码段,以获得跨机器的可重现结果(请在笔记本的单元格中运行代码段):
# Run it to obtain reproducible results across machines (from keras.io)
from__future__import print_function
import numpy as np
import tensorflow as tf
import random as rn
import os
os.environ['PYTHONHASHSEED'] ='0'
np.random.seed(42)
rn.seed(12345)
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
from keras import backend as K
tf.set_random_seed(1234)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
步骤b. 创建一个从Colab加载数据的函数。此函数返回具有相应基础事实(Y)的输入图像(X):
# load data func
import glob
from keras.preprocessing import image as kImage
defgetData(dataset_dir):
X_list=sorted(glob.glob(os.path.join(dataset_dir, 'x','*.jpg')))
Y_list =sorted(glob.glob(os.path.join(dataset_dir, 'y' ,'*.png')))
X= []
Y= []
for i inrange(len(X_list)):
# Load input image
x = kImage.load_img(X_list[i])
x = kImage.img_to_array(x)
X.append(x)
# Load ground-truth label and encode it to label 0 and 1
x = kImage.load_img(Y_list[i], grayscale=True)
x = kImage.img_to_array(x)
x /=255.0
x = np.floor(x)
Y.append(x)
X = np.asarray(X)
Y = np.asarray(Y)
# Shuffle the training data
idx =list(range(X.shape[0]))
np.random.shuffle(idx)
X = X[idx]
Y = Y[idx]
return X, Y
步骤c. 最初是一个vanilla编码器——解码器模型。我们将VGG-16预训练模型作为编码器进行调整,其中所有完全连接的层都被移除,只有最后一个卷积层(block5_conv3)被微调,其余层被冻结。我们使用转置卷积层来恢复解码器部分中的特征分辨率。
由于它是二分类问题,binary_crossentropy因此使用并且来自网络的输出将是0和1之间的概率值。这些概率值需要被阈值化以获得二进制标签0或1,其中标签0表示背景和标签1代表前景。
import keras
from keras.models import Model
from keras.layers import Deconv2D, Input
definitModel():
### Encoder
net_input = Input(shape=(240,320,3))
vgg16 = keras.applications.vgg16.VGG16(include_top=False, weights='imagenet', input_tensor=net_input)
for layer in vgg16.layers[:17]:
layer.trainable =False
x = vgg16.layers[-2].output # 2nd layer from the last, block5_conv3
### Decoder
x = Deconv2D(256, (3,3), strides=(2,2), activation='relu', padding='same')(x)
x = Deconv2D(128, (3,3), strides=(2,2), activation='relu', padding='same')(x)
x = Deconv2D(64, (3,3), strides=(2,2), activation='relu', padding='same')(x)
x = Deconv2D(32, (3,3), strides=(2,2), activation='relu', padding='same')(x)
x = Deconv2D(1, (1,1), activation='sigmoid', padding='same')(x)
model = Model(inputs=vgg16.input, outputs=x)
model.compile(loss=keras.losses.binary_crossentropy, optimizer=keras.optimizers.RMSprop(lr=5e-4), metrics=['accuracy'])
return model
步骤d. 我们将学习率设置为5e-4,batch_size为1,validation_split为0.2,max-epochs为100,当验证损失连续5次迭代没有改善时将学习率降低10倍,并在验证损失连续10次迭代没有改善时提前停止训练。现在,让我们训练模型吧。
# load data
dataset_path = os.path.join('CDnet2014', 'train')
X, Y = getData(dataset_path)
# init the model
model = initModel()
early = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=1e-4, patience=10)
reduce= keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=5)
model.fit(X, Y, batch_size=1, epochs=100, verbose=2, validation_split=0.2, callbacks=[reduce, early], shuffle=True)
model.save('my_model.h5')

使用GPU进行训练
一次迭代大约需要1秒钟,贼快!验证集的最大精度高于98%。还不错,对吧?现在,让我们暂停一下。让我们比较使用和不使用GPU的训练速度(如果需要,可以跳过此比较并跳转到测试部分)。要在没有GPU的情况下进行训练,请将硬件加速器设置为无(参见上面的第2节)。这是培训日志。没有GPU,一次迭代需要大约30秒,而使用GPU训练只需要1秒(大约快30倍👏)。

不使用GPU进行训练
现在,让我们使用ColabGPU在测试集上测试模型(您可以运行!ls */test/*以查看具有相应基础事实的测试帧)。
好棒!!!只需使用25个vanilla网络的例子,我们就可以在测试集+验证集上达到98.94%的精度。请注意,由于训练示例的随机性,您可能会得到与我相似的结果(不完全相同但只有很小的精度差异)。
注意一个问题:我们的模型过度拟合了训练数据,您接下来的工作是解决这个问题。提示:使用正规化技术,如Dropout,L2,BatchNormalization。
步骤e. 让我们通过运行以下代码绘制分段掩码:
import matplotlib.pyplot as plt
idx =1#image index that you want to display
img =np.empty(3, dtype=object)
img[0] = X[idx]
img[1] =Y[idx].reshape(Y[idx].shape[0],Y[idx].shape[1])
img[2] =pred[idx].reshape(pred[idx].shape[0],pred[idx].shape[1])
title = ['input','ground-truth', 'result']
for iinrange(3):
plt.subplot(1, 3, i+1)
if i==0:
plt.imshow(img[i].astype('uint8'))
else:
plt.imshow(img[i], cmap='gray')
plt.axis('off')
plt.title(title[i])
plt.show()
好了!细分结果一点都不差!大多数对象边界被错误分类了,该问题主要是由于训练期间在损失计算中考虑空标签(对象边界周围的模糊像素)引起的。我们可以通过在损失中省略这些void标签来更好地提高性能。您访问以下两个链接参考如何执行此操作:
https://github.com/lim-anggun/FgSegNet
https://github.com/lim-anggun/FgSegNet_v2

CDnet2014数据集上的测试结果(changedetection.net)
GitHub中提供了本教程的完整源代码:
https://github.com/lim-anggun/tutorials/blob/master/myNotebook.ipynb
总结
在本教程中,您学习了如何使用Google Colab GPU并快速训练网络。您还学习了如何在前景分割域中微调Keras预训练模型,您可能会发现它在您未来的研究中很有趣。
如果您喜欢这篇文章,请随时分享或鼓掌。祝愉快!🎊😁
原文标题:
A comprehensive guide on how tofine-tune deep neural networks using Keras on Google Colab (Free GPU)
原文链接:
https://towardsdatascience.com/a-comprehensive-guide-on-how-to-fine-tune-deep-neural-networks-using-keras-on-google-colab-free-daaaa0aced8f
译者简介

闫晓雨,本科毕业于北京林业大学,即将就读于南加州大学应用生物统计与流行病硕士项目。继续在生统道路上摸爬滚打,热爱数据,期待未来。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织


