![]()
虽然当前的基准强化学习(RL)任务对于推动这一领域的进展大有裨益,但在许多方面还不能很好地替代真实数据的学习。在低复杂度的仿真环境中测试日益复杂的RL算法,获得的RL策略难以推广。
![]()
论文地址:https://arxiv.org/pdf/1811.06032.pdf
为解决此问题,本文提出了3个新的基准RL域体系,包含自然世界复杂性的同时仍然支持快速广泛的数据采集,还允许通过公平的训练/测试分离来描述泛化性能,并且容易比较和复制结果。作者通过这项工作向RL研究界提出挑战:要达到高标准的评估,就必须开发出更具鲁棒性的算法。
基准域的广泛应用,如Atari学习环境和MuJoCo,一直是RL领域进步的主要驱动力。但研究表明当前的RL基准有严重的脆弱性,由于算法不鲁棒,或者模拟器缺乏多样性,无法诱导有趣的学习行为。
本文的目的是探索一种新的RL模拟器,将从自然(真实)世界获取的信号作为状态空间的一部分。首先,与只向模拟器中注入随机噪声相比,将状态链接到真实信号可以确保任务特性更有意义。第二,通过从现实世界中获取状态空间构成可以实现公平的训练/测试分离,这对RL来说是一个长期的挑战,但本文提出的任务仍然快速和简单易用。
作者考虑了三类任务,前两类是基于视觉推理的任务,第三类是现有RL基准的变体。
第一组任务由覆盖在自然图像上的网格世界环境组成,这些环境展示了利用需要视觉理解的自然信号将传统的有监督学习任务转换为基本的RL导航任务的过程。每个数据集都有一个预定义的训练/测试分割,在训练集图像上训练RL智能体,在测试集图像上评估,以此分割来提取公平的泛化度量。这些新域包含几个具有自然复杂性的真实世界图像,易于下载并且便于复制。
作者提出了一个图像分类任务,智能体从一个“蒙面”图像上的随机位置开始,它可以通过在{上、下、左、右}四个方向中的某个方向移动来取消图像窗口的遮罩。在每个时间步长,它还输出一个可能类别的概率分布C。当智能体正确分类图像或达到最多20个时,此幕结束。智能体若分类图像错误,则在每个时间步长的回报为-0.1。在每个时间步长接收到的状态是隐藏了未观察部分的完整图像。
给定图像中某个目标的分割掩码,智能体必须移动到该目标的顶部。每一个时间步长有4个可选择的动作,时间限制为200步,可利用多目标和对象类的附加输入进一步复杂化任务。
使用Cityscapes数据集进行目标检测,Cityscapes数据集由50k 256*256张图像组成,包含30个类别。窗口w控制任务的难度,令w=10,窗口大小决定了智能体的行动轨迹,如果轨迹与图像中目标重叠,此幕结束。将智能体放置在图像中心,并赋予其查找和导航目标对象的类标签。当智能体位于目标顶部时(环境对此给予的回报值为1),或者如果达到最大200步,则此幕结束。
从OpenAI gym中选取任务,并添加自然视频作为观察帧的背景。利用动力学数据集中的汽车驾驶视频,通过过滤黑色像素(0,0,0)遮挡Atari帧,用视频帧替换黑色背景。为保持光流,使用随机选择的视频中的连续帧作为背景,并从同一组840个视频中随机采样用于训练和测试。
在OpenAI gym中对MuJoCo任务执行相同操作。MuJoCo默认使用由每个关节的位置和速度组成的低维状态空间。相反,考虑PixelMuJoCo,其观察空间包括跟踪智能体的摄像机。在新基准中,用与Atari域中相同的视频帧替换PixelMuJoCo任务的地板平面。因发现MuJoCo任务中智能体学习的策略开环,并且完全忽略了观察输入,因此没有将PixelMuJoCo的结果包含在提出的基准集中。作出上述改动后,环境状态空间急剧增加,为关注与游戏相对应的目标而对场景进行视觉理解,并且忽略视频中目标。
本节将在新提出的域上测试现有流行的RL算法的基准性能。
对于提出的视觉推理任务,在MNIST、CIFAR 10和Cityscapes上应用CNN和ResNet-18。CNN由3个卷积层和一个全连接层组成,其具有不同的步长和卷积核大小,处理来自不同数据集的不同尺寸的图像,选择ReLU作为激活函数。
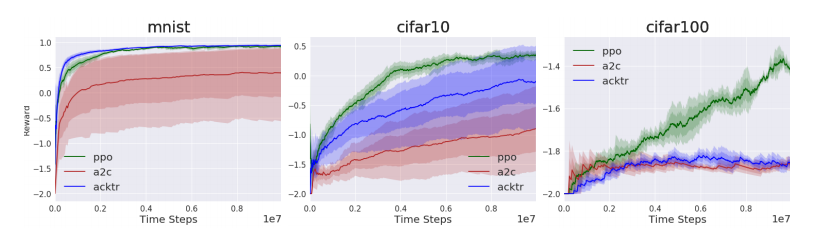
MNIST、CIFAR10和CIFAR100数据集上图像分类任务的结果如图1和2所示。发现PPO和ACKTR能够在MNIST上获得接近1的平均回报,这意味着智能体能够在较少时间步长内准确地对数字进行分类。因为CIFAR10和CIFAR100数据集包含更难理解的可视化概念,智能体的性能更差。在监督学习中,应用这些数据集,智能体的性能也会下降。A2C始终在所有数据集和主干模型中表现最差。
![]()
![]()
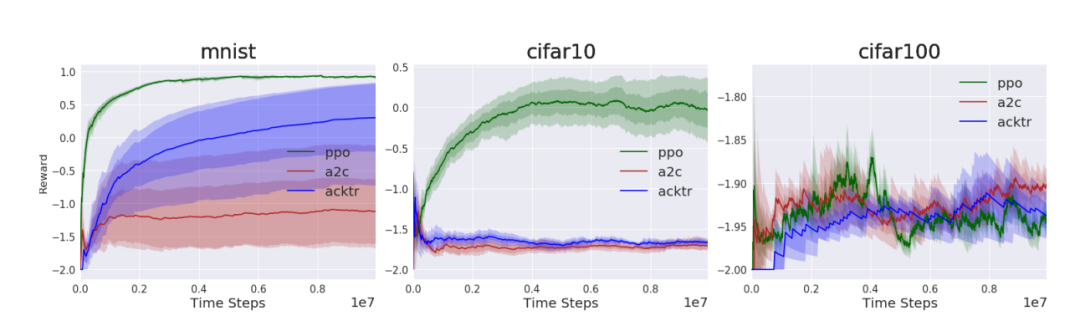
图 2 使用ResNet-18主干进行图像分类结果
更耐人寻味是,当在3个数据集上从3层CNN到ResNet-18测试时,都可看到性能下降。PPO仍然能够在MNIST和CIFAR10上获得相同的性能,这两个数据集都是10分类任务,但是ACKTR和A2C受到了巨大的影响。没有一个算法在ResNet-18和100分类任务中表现突出。这融合了两个更困难的问题:现在行动空间是10倍大;还要学习10倍多的概念。
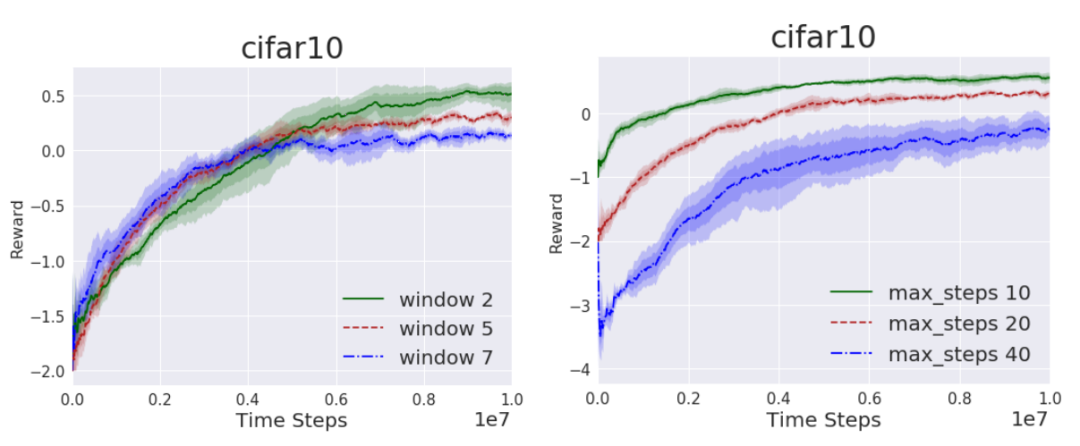
可以在两个维度上改变这个任务的难度,改变智能体的窗口大小w,或者每幕的最大步数M。在实验中,尝试w∈[2,5,7]和M∈[10,20,40]的值。结果如图3所示,对应于更直接的奖励,随着步数的减少性能提高,这更利于执行RL任务。最初,w越大性能越好,但随着训练的继续,w趋向于2。
![]()
图3 CIFAR10结合PPO算法,(左)固定最大步数M=20,窗口大小变化曲线图;
(右)固定窗口大小w=5,每幕最大步数变化曲线图。
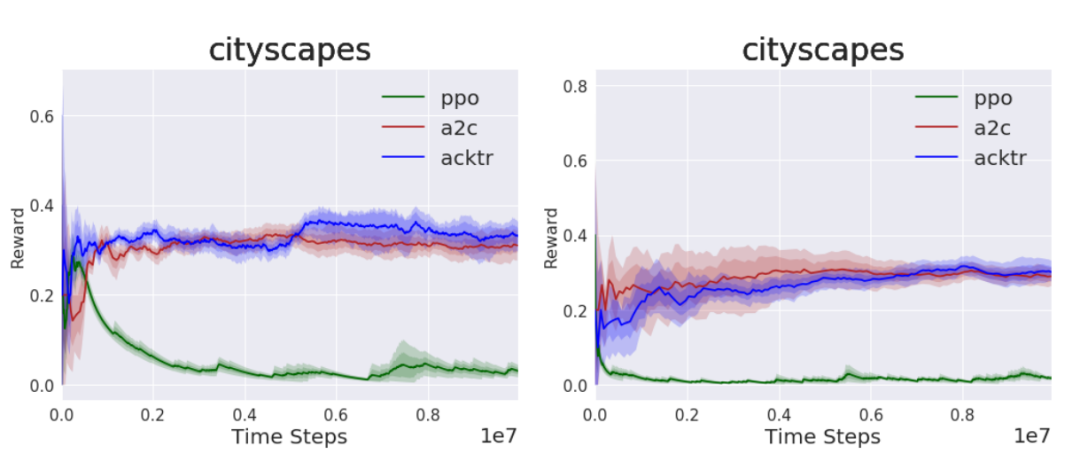
Cityscapes目标检测任务的结果如图4所示,当从3层CNN主干转为ResNet-18时,任务难度加大的同时性能也略有下降。虽然PPO在分类任务中击败了A2C和ACKTR,这里看到PPO已完全丧失学习能力。但是A2C和ACKTR在超过40%的时间内都无法导航到图像中的期望目标。说明深度模型在RL框架和SL框架中的表现确实不同。
![]()
对于Atari和PixelMuJoCo,将帧大小调整为84*84,转换为灰度,并连续执行4步的跳帧和粘滞操作,为每个观测叠加4个连续帧,以静态黑色背景下的原始任务为基线进行比较。
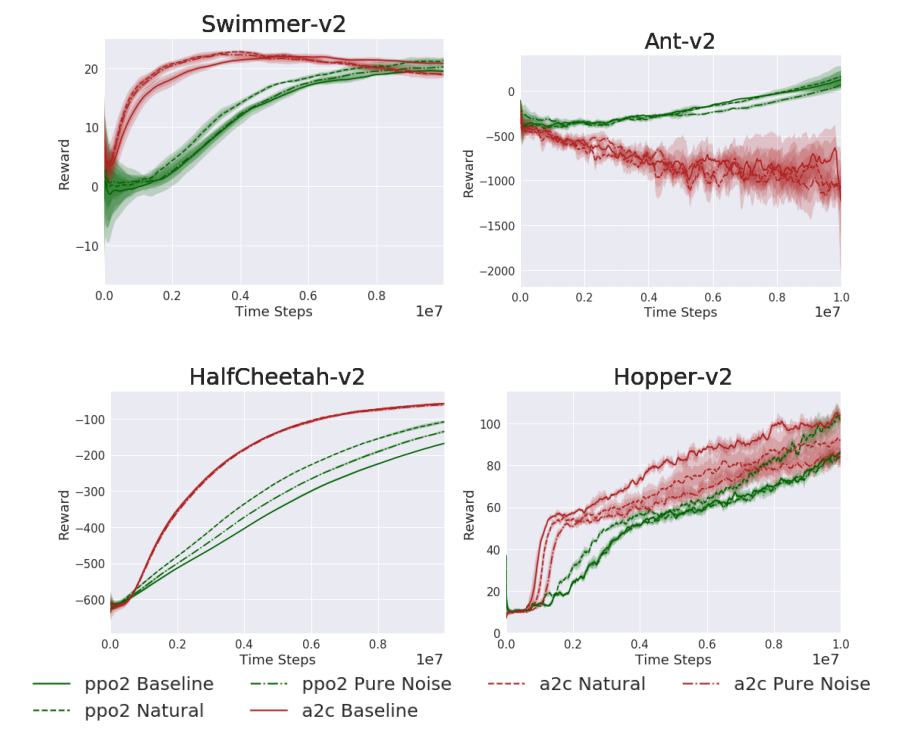
PixelMuJoCo的结果如图5所示。在基线和自然条件下看到了性能类似,特别是对于HalfCheetah和Hopper任务差距很小。这可能是由于策略陷入局部最优,完全忽略了观察到的状态。为验证此假设,用高斯噪声代替观测值。
![]()
即使在观察中没有返回任何信息的情况下,PPO和A2C能够像观察中提供实际状态信息时一样学习良好的策略。结果表明,当前的RL算法是将MuJoCo任务作为一个开环控制系统来求解的,在决定下一步动作时完全忽略了输出,说明MuJoCo可能不是RL算法的一个强大基准。
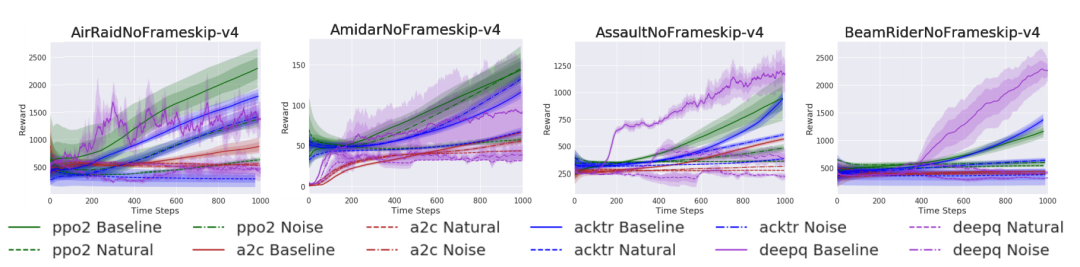
选择Atari的16个环境(主要是具有黑色背景以便于过滤的环境),并在默认环境和注入视频帧上评估了PPO、ACKTR、A2C和DQN算法。看到许多游戏在性能上有更大的差距,这表明视觉理解在这些环境中更为重要。在视觉流中添加自然噪声会导致策略在某些游戏中完全失败,而在其他游戏中只会导致性能略降。在这些情形中,策略可能再次将任务视为开环控制问题。
为弄清楚由于自然信号的加入而导致的性能差异有多大,而不是仅仅将环境改变为非确定性,还评估了一些Atari环境,其背景被帧间变化的随机独立同分布高斯噪声所替代(图6)。四款游戏中,智能体在原始静态黑色背景(基线)下的性能最好,类似于高斯噪声下的性能降低,在视频(自然)下的性能最差。但是性能差异有所不同。在中段,ACKTR和PPO在随机噪声下的性能非常接近基线,但在自然信号下性能会大幅下降。在Beamrider中,任何随机噪声或自然信号的加入都令该算法无法获得良好的策略。
![]()
图6 以基线、高斯噪声和自然视频为背景的Atari帧下评估结果图
Atari任务非常复杂,在不同的状态下需要多样化的行为。策略不能忽略观察状态,而是要通过学习解析观察获得一个好的策略。在大多数游戏中,它能够在静态背景下完成这项工作,在随机噪声背景下,在自然信号背景下完全失败。
作者提出了3个新的基准任务体系剖析RL算法的性能。前两个领域通过将传统的监督学习任务引入RL框架来测试视觉理解。在这个过程中,作者已经证明了成功的视觉模型的简单即插即用在RL设置中是失败的。这表明,目前支持RL的端到端框架在隐式学习视觉理解方面并不成功。
第三类任务要求通过融合来自自然世界的信号,将自然视频中的帧注入到当前的RL基准中来评估RL算法。在这种设置下,几个最先进的RL优化算法和主干模型的性能急剧下降。从一种状态到另一种状态的转换引入来自不完善的执行器和传感器的噪声,如何将自然动力学信号注入到模拟环境中仍是一个悬而未决的问题。
![]() ACL 2020原定于2020年7月5日至10日在美国华盛顿西雅图举行,因新冠肺炎疫情改为线上会议。为促进学术交流,方便国内师生提早了解自然语言处理(NLP)前沿研究,AI 科技评论将推出「ACL 实验室系列论文解读」内容,同时欢迎更多实验室参与分享,敬请期待!
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。
ACL 2020原定于2020年7月5日至10日在美国华盛顿西雅图举行,因新冠肺炎疫情改为线上会议。为促进学术交流,方便国内师生提早了解自然语言处理(NLP)前沿研究,AI 科技评论将推出「ACL 实验室系列论文解读」内容,同时欢迎更多实验室参与分享,敬请期待!
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。