策略解读丨统计风险模型初探

本文由优矿金融工程团队撰写,未经允许私自转载者必究。
投稿合作邮箱:yifan.hua@datayes.com
我们知道,在估计资产之间的协方差矩阵时,基于历史收益数据估计股票的协方差矩阵,经常出现两个问题:
估计的参数太多,导致模型不够稳健;
当资产的个数高于观测的期数之后,计算得到的协方差矩阵不可逆。
如何解决这个问题,前有东方证券的压缩矩估计的方法,现有优矿的基本面风险模型。今天再介绍一个新的思路——统计风险模型。
1统计风险模型简介
1.1 基本面风险模型

(清晰版请点击“阅读原文”获取)
1.2 因子分析模型回顾

(清晰版请点击“阅读原文”获取)
1.3 因子载荷的估计——主成分分析法

(清晰版请点击“阅读原文”获取)
2Bias Statistics

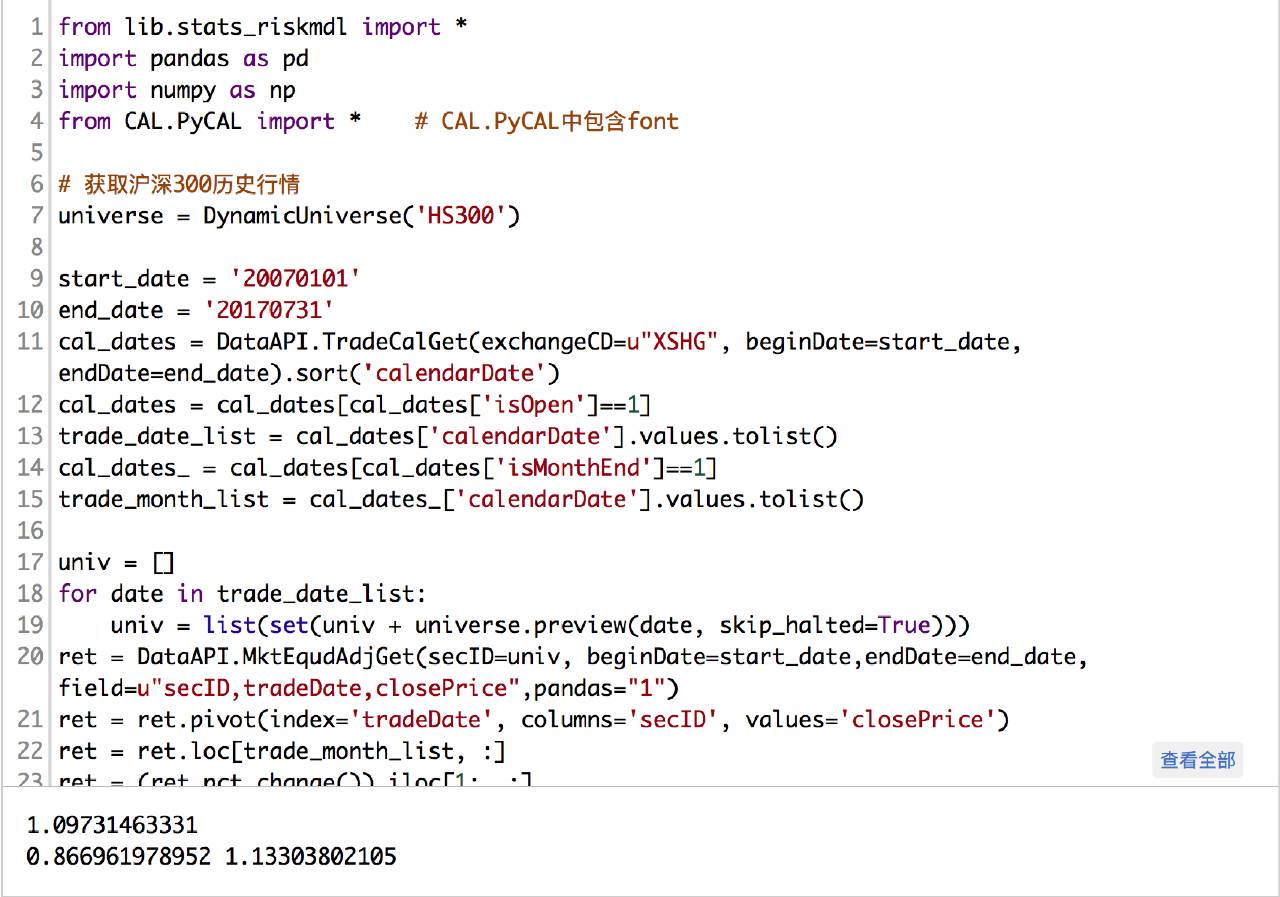
(完整源码请点击文末“阅读原文”获取)
这里只是简单的测试,可以看到我们的统计量是在置信区间之内的,所以从这个角度来说,通过主成分方法来估计样本协方差矩阵是可行的。
3统计风险模型的一些思考与不足
先说不足,看起来,我们有了一个计算股票之间协方差矩阵的新方法,但是,别得意,还有些不足。基本面风险模型的功能远不只算协方差矩阵这一点,像业绩归因,如果统计风险模型是不能做到的(想想看为什么),对市场风格的预测统计风险模型也不能做到,这两点也很重要。再来谈谈一些思考:
我们舍弃了后面p-m个主成分,那么这个m又该如何确定,主成分取多少比较合适?
当股票数量很大是,计算主成分的会比较耗时间,又该如何解决?
对协方差矩阵进行分解,是不是可以考虑对相关系数矩阵进行分解?
-
是不是很多情况下,第一个主成分的功贡献率太高,导致我们的模型会把其他主成分舍去(这个问题和第一个问题一起考虑)? 当然了,其中还有其他很多细节,这里也只是提供了一个思路,至于是否合理,值得商榷,感兴趣的可以在帖子或公众号下方留言交流。
--- the end ---
Read More:
优矿是由通联数据出品,覆盖研究、回测、模拟、实盘交易全流程的量化平台。优矿不仅拥有通联海量的金融数据、动态丰富的策略框架,同时还通过知识库信号库提供持续的知识输出,满足用户在研究过程中高效获取、迅速验证、多维度挖掘、多策略并行的迫切需求,为投资决策提供重要支持。

扫二维码,立即试用优矿专业版
↓↓↓ 点击"阅读原文" 【查看源码】




