TPAMI 2021 | 时间走向二维,基于文本的视频时间定位新方法兼顾速度与精度
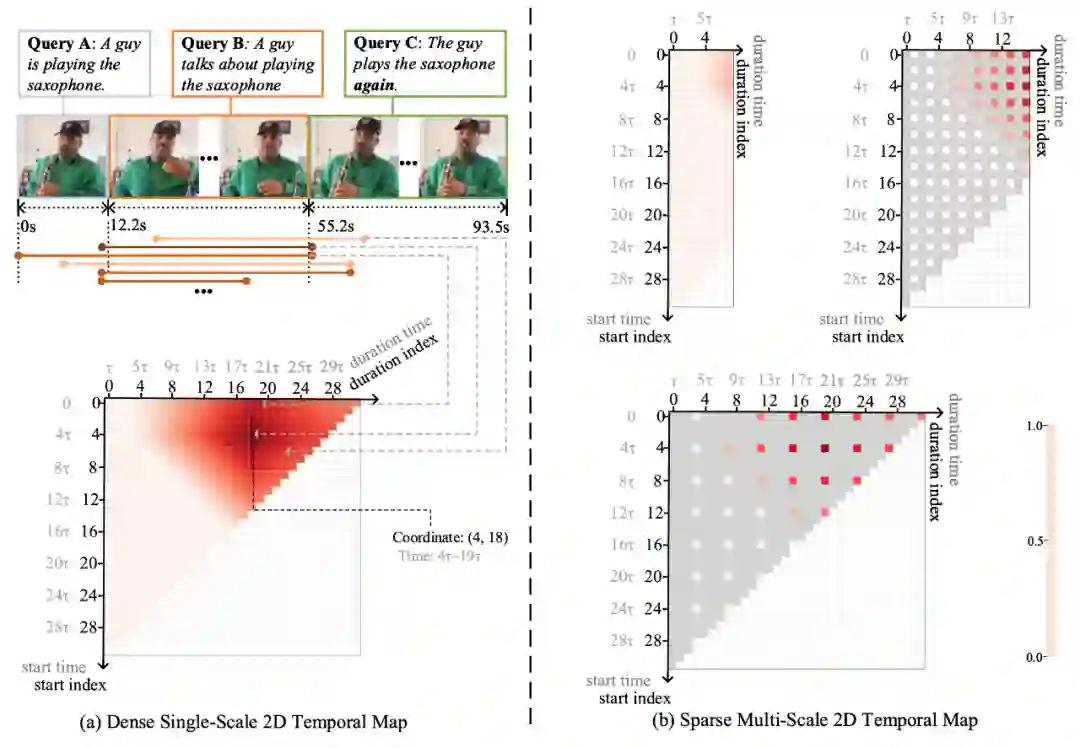
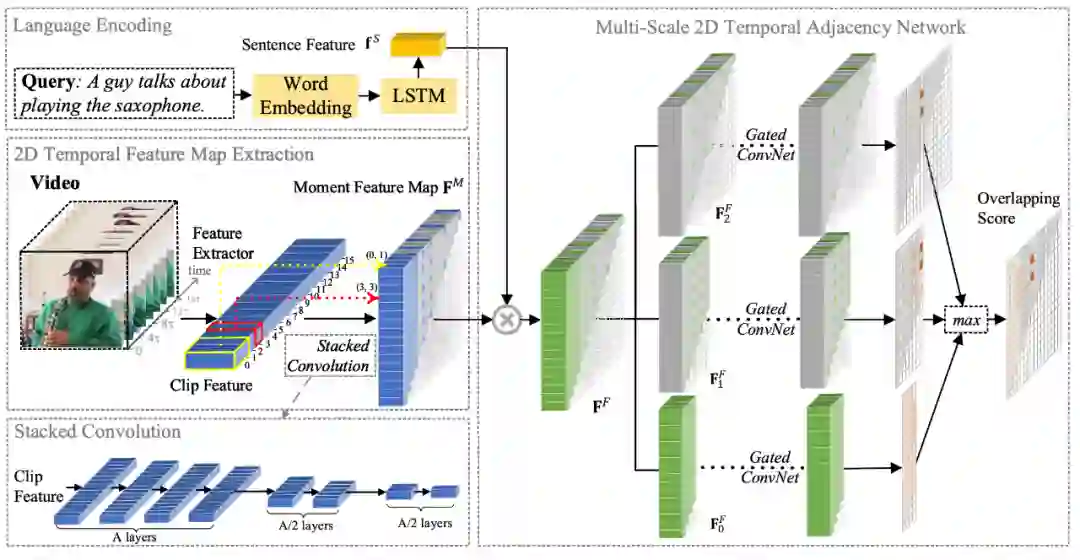
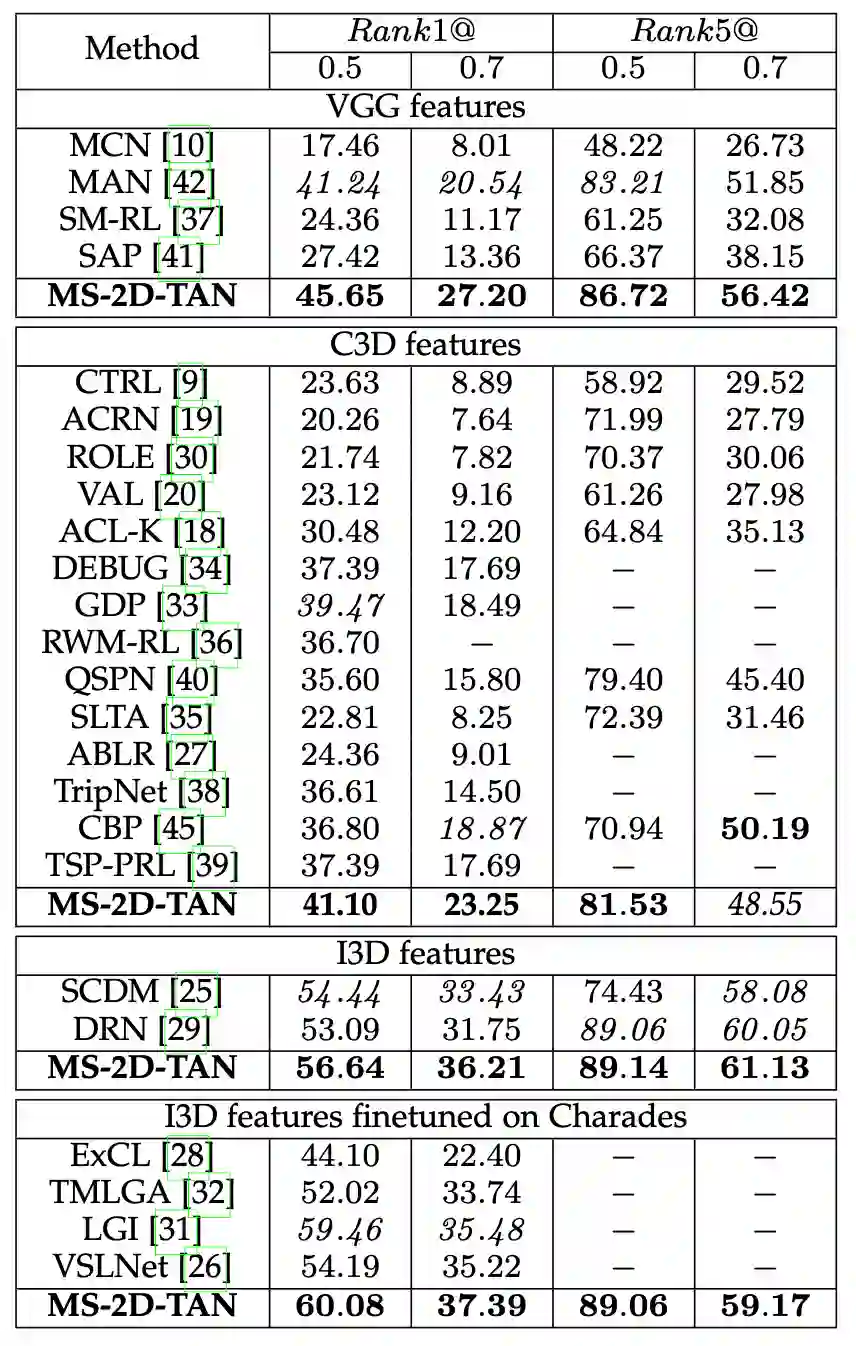
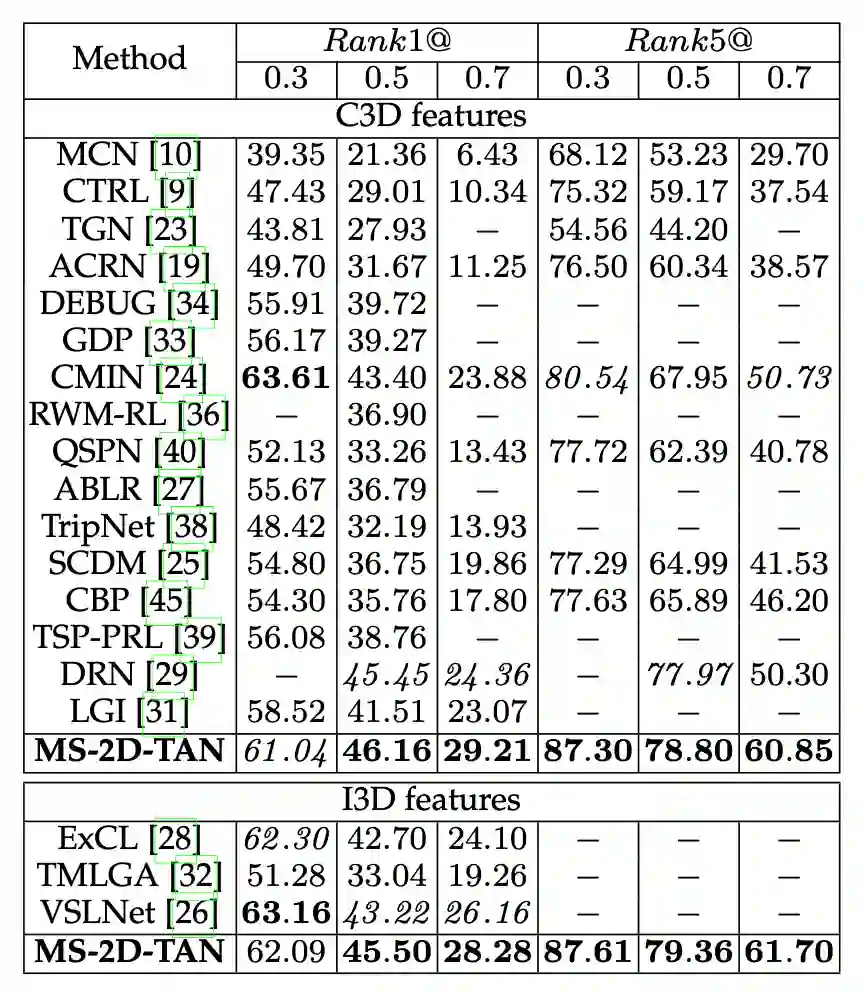
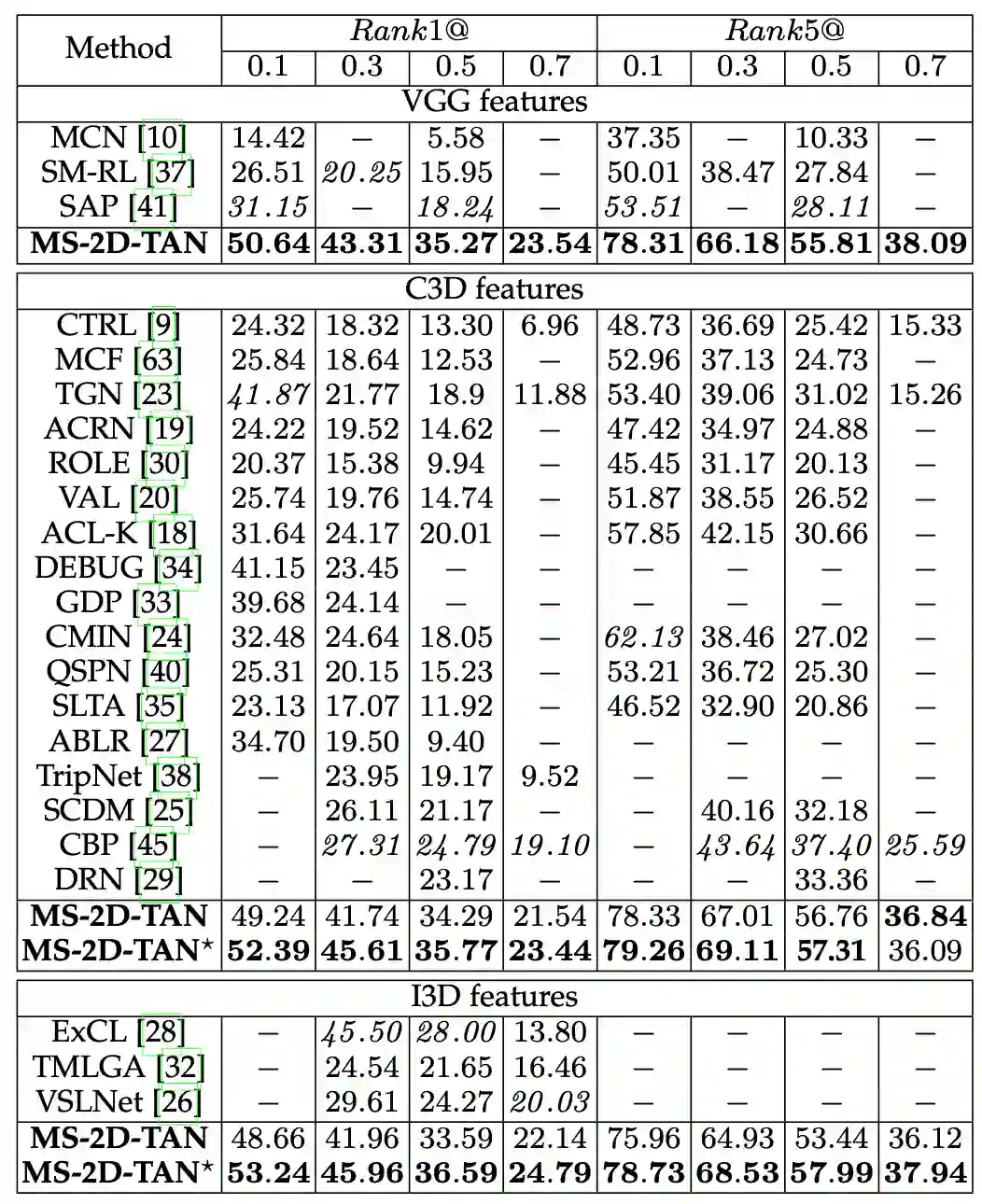
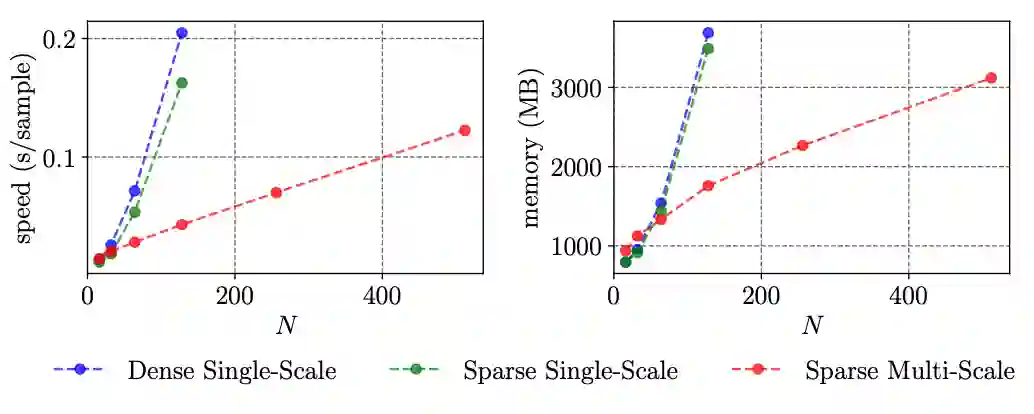
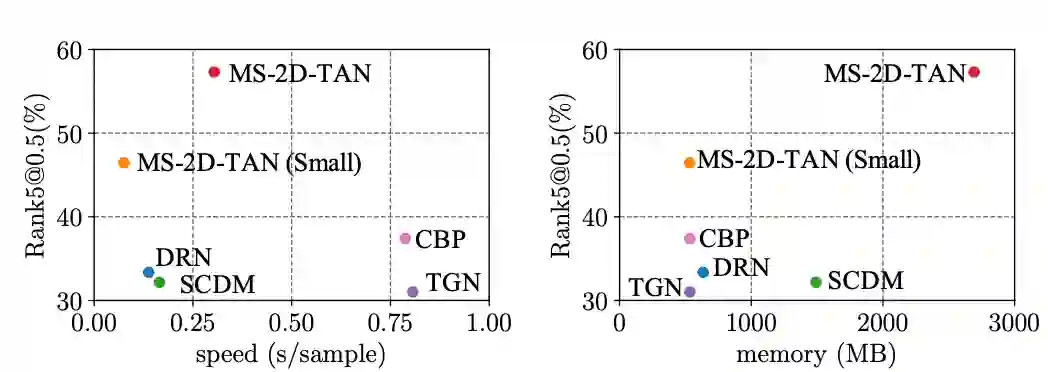
当时间的维度从一维走向二维,时序上的建模方式也需要相应的改变。本文提出了多尺度二维时间图的概念和多尺度二维时域邻近网络(MS-2D-TAN)用于解决视频时间定位的问题。本文拓展自 AAAI 2020 [1],并将单尺度的二维时间建模拓展成了一个多尺度的版本。新模型考虑了多种不同时间尺度下视频片段之间的关系,速度更快的同时精度也更高。本文在基于文本的视频时间定位任务中验证了其有效性。相关内容将发表在 TPAMI上。

论文地址:https://arxiv.org/abs/2012.02646 https://www.zhuanzhi.ai/paper/d2d11fce9437434aa6236a25e2f8efcc
代码地址:https://github.com/microsoft/2D-TAN/tree/ms-2d-tan
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“2DTAN” 就可以获取《TPAMI 2021 | 时间走向二维,基于文本的视频时间定位新方法兼顾速度与精度》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月15日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月15日