Airflow任务调度延时问题分析和优化



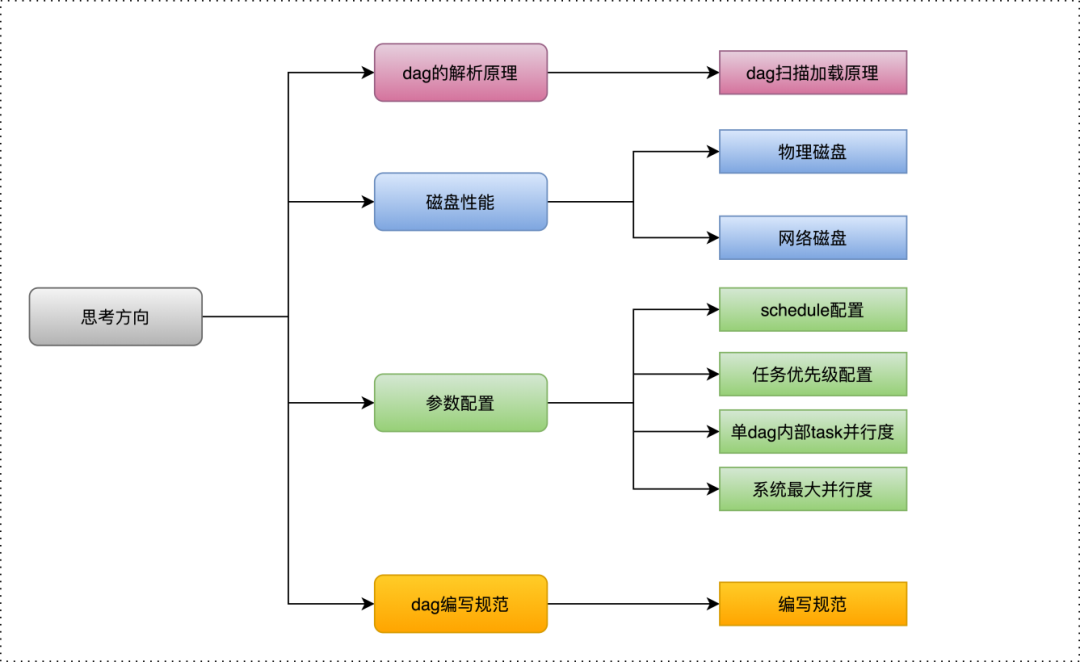


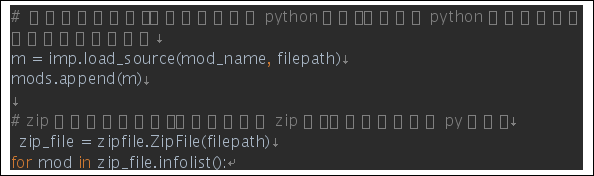




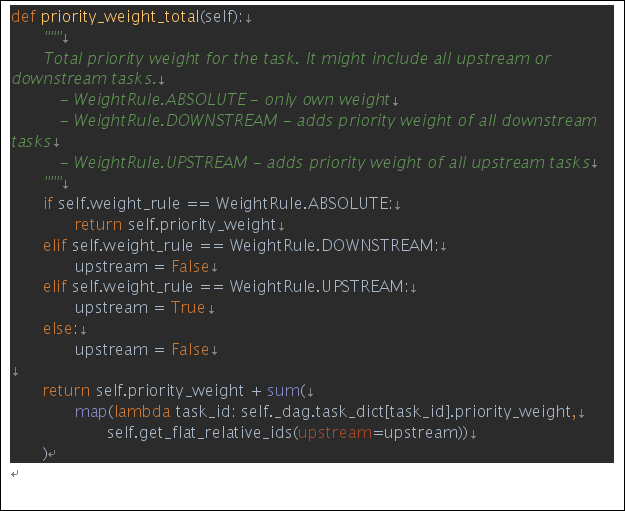
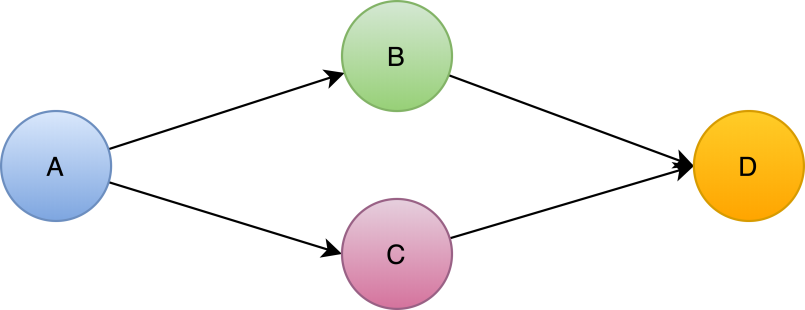

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|


更多精彩推荐
☞ 与 Brian Kernighan 一起回忆 Unix 的诞生! ☞ 挑战 Linux 之父认为的“不可能”:向 M1 Mac 移植 Linux
☞ TIOBE 12 月编程语言:Python 有望第四次成为年度语言!
☞ 升级版APDrawing,人脸照秒变线条肖像画,细节呈现惊人
☞ 中科大“九章”历史性突破,但实现真正的量子霸权还有多远?
☞ 云原生应用Go语言:你还在考虑的时候,别人已经应用实践
![]()
点分享
![]()
点点赞
![]()
点在看



登录查看更多
相关内容

Processing 是一门开源编程语言和与之配套的集成开发环境(IDE)的名称。Processing 在电子艺术和视觉设计社区被用来教授编程基础,并运用于大量的新媒体和互动艺术作品中。



相关VIP内容
相关资讯
相关论文