王者荣耀开源环境上榜!九月AI研究GitHub排行来了,「star多」才叫好论文
![]()
新智元报道

新智元报道
【新智元导读】GitHub上榜项目靠谱,拿来就能用!
九月份总共发表了11768篇AI相关论文,比八月份10642篇多了近一千篇。
其中附带代码的论文只有约9.1%,有0.7%的论文包含多个复现。
有网友根据论文在GitHub仓库获得的stars,对论文进行了一次排行,其中包括王者荣耀竞技场、大规模中文科学文献库等。
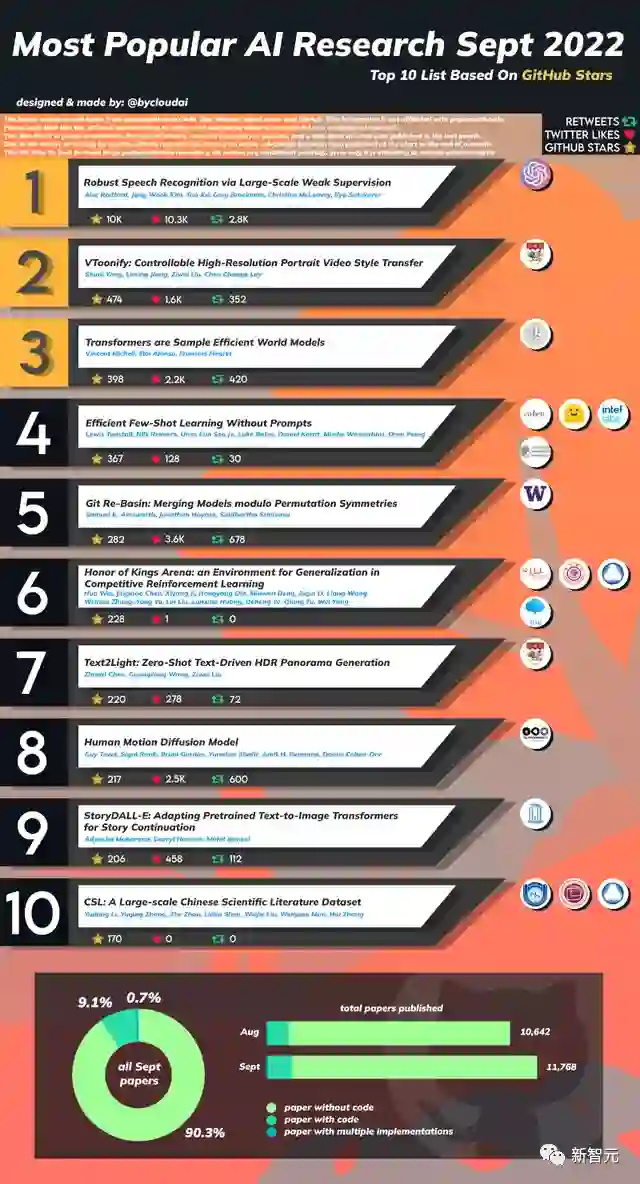
看看过去一个月有没有你错过的高质量、可复现的研究?
1. 基于大规模弱监督的鲁邦语音识别
1. 基于大规模弱监督的鲁邦语音识别
来自OpenAI的研究人员研究了简单训练的语音处理系统在预测互联网上大量的音频转录的能力。

论文链接:https://cdn.openai.com/papers/whisper.pdf
代码链接:https://github.com/openai/whisper
当扩展到680,000小时的多语言和多任务监督时,所产生的模型对标准基准有很好的泛化性,在一个无需任何微调的zero-shot迁移任务设置中,已经与先前的完全监督模型的性能相差无几。当与人类比较时,这些模型已经接近了人类的准确性和稳定性。
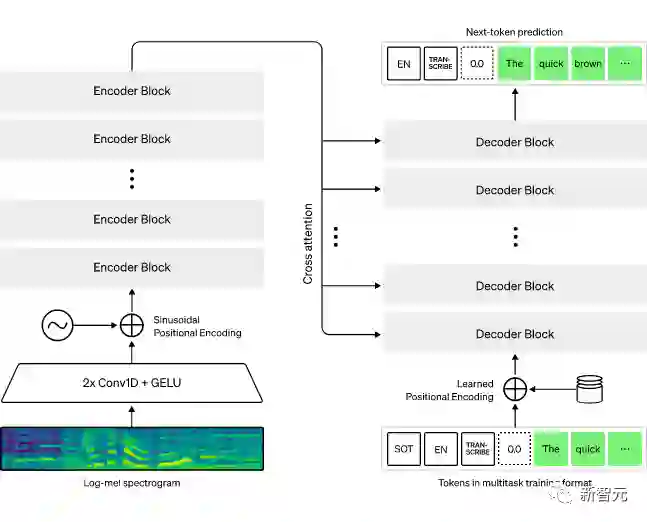
相关的模型和推理代码已经开源,作为鲁棒性语音处理的进一步工作的基础。
2. VToonify: 可控的高分辨率肖像视频风格迁移
2. VToonify: 可控的高分辨率肖像视频风格迁移
生成高质量的艺术人像视频(artistic portrait videos)是计算机图形学和视觉领域的一项重要的任务。
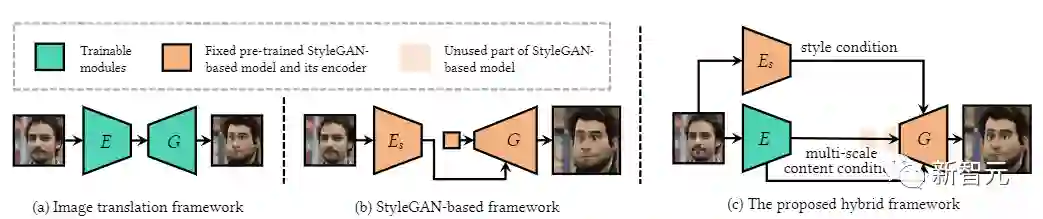
尽管目前已经提出了一系列建立在强大的StyleGAN基础上的成功的人像图像化模型,但这些面向图像的方法在应用于视频时有明显的局限性,如固定的帧大小、脸部对齐的要求、非脸部细节的缺失和时间上的不一致。
来自南洋理工大学的研究人员提出一个新颖的VToonify框架来研究具有挑战性的可控高分辨率人像视频风格转移。
论文链接:https://arxiv.org/abs/2209.11224v2
代码链接:https://github.com/williamyang1991/vtoonify
具体来说,VToonify利用StyleGAN的中分辨率和高分辨率层,根据编码器提取的多尺度内容特征渲染高质量的艺术肖像,以更好地保留帧的细节。
由此产生的全卷积架构接受可变大小的视频中的非对齐人脸作为输入,有助于在输出中形成具有自然运动的完整人脸区域。

该框架与现有的基于StyleGAN的图像卡通化模型兼容,将其扩展到视频卡通化,并继承了这些模型的优秀特点,对颜色和强度进行灵活的风格控制。
这项工作提出了建立在Toonify和DualStyleGAN基础上的VToonify的两个实例,分别用于基于集合和基于示范的肖像视频风格转移。
实验结果表明,文中提出的VToonify框架在生成具有灵活风格控制的高质量和时间连贯的艺术肖像视频方面比现有的方法更有效。
3. Transformer是高效的世界模型
3. Transformer是高效的世界模型
深度强化学习智能体是出了名的样本效率低下,这大大限制了它们在现实世界问题上的应用。

论文链接:https://arxiv.org/abs/2209.00588v1
代码链接:https://github.com/eloialonso/iris
许多基于模型的方法被设计来解决这个问题,其中在世界模型的想象中学习是最突出的方法之一。
虽然与模拟环境的几乎无限的互动听起来很吸引人,但世界模型必须在相当长的一段时间内维持准确的互动。
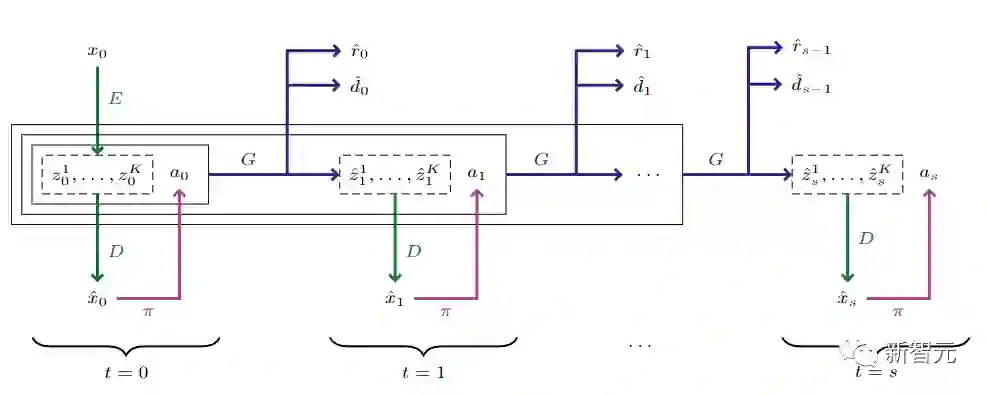
基于Transformer在序列建模任务中取得的成功,来自日内瓦大学的研究人员提出了IRIS模型,一个在由离散自动编码器和自回归变形器组成的世界模型中学习的数据高效的智能体。
在Atari 100k基准测试中,IRIS只用了相当于两个小时的游戏时间,就取得了1.046的人类归一化平均分,并在26个游戏中的10个游戏中优于人类。
该方法为没有前瞻搜索的方法设定了一个新的技术状态,甚至超过了MuZero
4. 无提示的高效Few-Shot学习
4. 无提示的高效Few-Shot学习
最近发表的Few-Shot方法,如parameter-efficient fine-tuning(PEFT)和Pattern-Exploiting Training(PET),在标签稀缺的情况下取得了非常好的效果。
但这两种方法通常很难用,因为它们受制于手工制作的提示语的高变异性,并且通常需要数十亿个参数的语言模型来实现高准确性。
为了解决这些缺点,来自HuggingFace等机构的提出了SETFIT(句子Transformer微调),这是一个高效且无提示的框架,用于对句子Transformer(ST)进行少量微调。

论文链接:https://arxiv.org/abs/2209.11055v1
代码链接:https://github.com/huggingface/setfit
SETFIT的工作原理是,首先以对比连带的方式,在少量的文本对上对预训练的ST进行微调。
然后,所产生的模型被用来生成丰富的文本嵌入,这些嵌入被用来训练分类头。
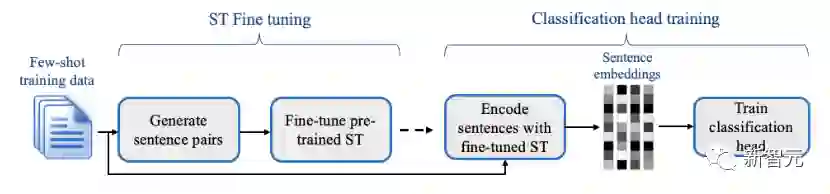
这个简单的框架不需要任何提示或口头语,并且以比现有技术少几个数量级的参数实现了高精确度。
实验表明,SETFIT获得了与PEFT和PET技术相当的结果,同时训练速度快了一个数量级。结果还表明,SETFIT可以通过简单地切换ST主体而应用于多语言环境。
5. Git Re-Basin: Merging Models modulo Permutation Symmetries
5. Git Re-Basin: Merging Models modulo Permutation Symmetries
深度学习的成功得益于我们能够相对轻松地解决某些大规模的非凸优化问题。
尽管非凸优化是NP-hard,但简单的算法——通常是随机梯度下降的变种——在实践中对大型神经网络的拟合表现出惊人的有效性。
来自华盛顿大学的研究人员认为,在考虑了隐藏单元的所有可能的排列对称性之后,神经网络损失包含(几乎)一个单一的basin。

论文链接:https://arxiv.org/abs/2209.04836v1
代码链接:https://github.com/samuela/git-re-basin
文中介绍了三种算法,用于对一个模型的单元进行替换,使其与参考模型的单元保持一致。
这种转换产生了一组功能等同的权重,这些权重位于参考模型附近的一个近似凸形的basin中。

通过实验,在各种模型结构和数据集上证明了单一basin现象,包括在CIFAR-10和CIFAR-100上独立训练的ResNet模型之间首次(据我们所知)证明了zero-barrier的线性模式连接。
此外,研究人员还发现了有趣的现象,即在各种模型和数据集上,模型的宽度和训练时间与模式连接有关。
最后,文中讨论了单一basin理论的缺点,包括对线性模式连接假设的反例。
6. 王者荣耀竞技场:竞技强化学习泛化的环境
6. 王者荣耀竞技场:竞技强化学习泛化的环境
这篇论文介绍了王者荣耀竞技场,一个基于《王者荣耀》的强化学习(RL)环境,也是目前世界上最流行的游戏之一。

论文链接:https://arxiv.org/abs/2209.08483v1
代码链接:https://github.com/tencent-ailab/hok_env
与以前大多数工作中研究的其他环境相比,该环境为竞争性强化学习提出了新的泛化性挑战。
它是一个多智能体问题,一个智能体与它的对手竞争;它需要泛化能力,因为它有不同的目标要控制,有不同的对手要竞争。
文中描述了《王者荣耀》数据域的观察、行动和奖励规范,并提供了一个开源的基于Python的接口,用于与游戏引擎进行通信。
代码中在《王者荣耀》竞技场中提供了20个目标英雄的各种任务,并介绍了在可行的计算资源下基于RL的方法的初步基线结果。
最后,研究人员还介绍了王者荣耀竞技场所带来的泛化挑战以及对挑战的可能补救措施。
8. Text2Light: 文本驱动的Zero-shot HDR 全景图生成
8. Text2Light: 文本驱动的Zero-shot HDR 全景图生成
高质量的HDRI(高动态范围图像),通常是HDR全景图,是在图形中创建逼真的照明和360度反射的3D场景的最流行的方法之一。
鉴于捕捉HDRIs的难度,人们非常需要一个通用的、可控的生成模型,让普通用户能够直观地控制生成过程。
然而,现有的最先进的方法仍然难以合成复杂场景的高质量全景图。
在这项工作中,来自南洋理工大学的研究人员提出了一个Zero-Shot文本驱动的框架,即Text2Light,能够以生成4K+分辨率的HDRIs,而不需要配对的训练数据。

论文链接:https://arxiv.org/abs/2209.09898v1
代码链接:https://github.com/frozenburning/text2light
给定一个自由格式的文本作为场景的描述,通过两个步骤合成相应的HDRI:1)文本驱动的低动态范围(LDR)和低分辨率的全景图生成,以及2)超分辨率反色调映射,在分辨率和动态范围上扩大LDR全景图。

具体来说,为了实现Zero-Shot文本驱动的全景图生成,首先建立双编码簿作为不同环境纹理的离散表示。然后,在预先训练好的CLIP模型的驱动下,一个文本条件下的全局采样器学会根据输入文本从全局编码簿中采样整体语义。
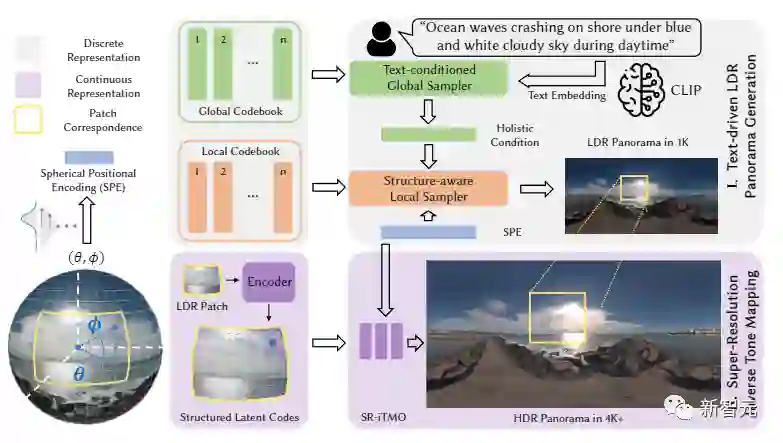
此外,一个结构感知的局部采样器在整体语义的指导下,学习逐片合成LDR全景图。为了实现超分辨率反色调映射,需要从LDR全景图中导出了360度成像的连续表示,作为锚定在球体上的一组结构化潜伏代码。这种连续表示使一个多功能模块可以同时提高分辨率和动态范围。
大量的实验证明了Text2Light在生成高质量HDR全景图方面的卓越能力。此外,文中还展示了该工作在现实渲染和沉浸式VR中的可行性。
8. StoryDALL-E: 为故事延续改编预训练的文本到图像转换器
8. StoryDALL-E: 为故事延续改编预训练的文本到图像转换器
最近在文本到图像合成方面的进展导致了大型的预训练Transformer,具有从给定文本生成可视化的出色能力。
然而这些模型并不适合像故事可视化这样的专门任务,因为故事要求智能体生成一连串的图像,给定相应的标题序列,形成一个叙述。
此外还可以发现,故事可视化任务不能适应对新的叙述中未见过的情节和人物的概括。
因此,北卡罗来纳大学教堂山分校的研究人员首次提出了故事延续的任务,即生成的视觉故事以源图像为条件,允许对有新人物的叙述进行更好的概括。

论文链接:https://arxiv.org/abs/2209.06192v1
代码链接:https://github.com/adymaharana/storydalle
增强或改装预训练的文本-图像合成模型,使其具有特定的任务模块,用于(a)连续的图像生成和(b)从初始帧复制相关元素。
然后研究人员探索了对预训练模型的全模型微调,以及基于提示的参数有效适应的调整。
在两个现有的数据集PororoSV和FlintstonesSV上评估了新方法StoryDALL-E,并引入了一个新的数据集DiDeMoSV,该数据集收集自一个视频字幕数据集。
研究人员还开发了一个基于生成对抗网络(GAN)的故事延续模型StoryGANc,并与StoryDALL-E模型进行比较,以证明该方法的优势。
实验结果表明,文中提出的逆向拟合方法在故事延续方面优于基于GAN的模型,并且有利于复制源图像中的视觉元素,从而提高了生成的视觉故事的连续性。
最后,实验分析表明,预训练的Transformer在理解包含多个角色的叙事时很困难。总的来说,这项工作表明,预训练的文本-图像合成模型可以适应复杂的、低资源的任务,如故事的延续。
9. CSL:一个大规模的中文科学文献库
9. CSL:一个大规模的中文科学文献库
科学文献是一个高质量的语料库,一直支撑着大量的自然语言处理(NLP)研究。
然而,现有的数据集通常是以英语为中心的,这限制了中文科学NLP的发展。

论文链接:https://arxiv.org/abs/2209.05034v1
代码链接:https://github.com/ydli-ai/csl
在这项工作中,来自中国地质大学(北京)、深圳大学、腾讯AI Lab和国家科技基础条件平台中心的研究人员发布了CSL,一个大规模的中文科学文献数据集,它包含了396k篇论文的标题、摘要、关键词和学术领域。
据我们所知,CSL是第一个中文科学文献数据集。
CSL可以作为一个中文语料库,同时,这种半结构化的数据是一种自然的标注,可以构成许多有监督的NLP任务。
基于CSL,研究人员提出了一个基准来评估模型在科学领域任务中的表现,即总结、关键词生成和文本分类。
文中分析了现有文本到文本模型在评估任务上的行为,并揭示了中文科学NLP任务所面临的挑战,这为未来的研究提供了宝贵的参考。
10. 人体运动扩散模型
10. 人体运动扩散模型
自然和富有表现力的人类运动生成是计算机动画的圣杯。
因为可能的运动的多样性,人类对运动的感知敏感性,以及准确描述运动的难度,所以这是一项具有挑战性的任务。
目前的生成解决方案要么质量不高,要么表现力有限,扩散模型由于其多对多的性质,已经在其他领域显示出了显著的生成能力,是人类运动的有希望的候选者,但它们往往是资源匮乏的,而且难以控制。
在这篇论文中,来自特拉维夫大学的研究人员提出了运动扩散模型(MDM),这是一个经过精心调整的用于人类运动领域的无分类扩散的生成模型。

论文链接:https://arxiv.org/abs/2209.14916v1
代码链接:https://github.com/guytevet/motion-diffusion-model
MDM是基于Transformer的,结合了运动生成文献的见解,一个值得注意的设计选择是在每个扩散步骤中对样本的预测,而不是对噪声的预测,这有利于使用既定的关于运动位置和速度的几何损失,如脚部接触损失。

正如模型所证明的,MDM是一种通用的方法,可以实现不同的调节模式和不同的生成任务。
实验结果表明,我们的模型是用轻型资源训练的,但在文本到运动和动作到运动的主要基准上取得了最先进的结果。





