靓仔落泪,性能问题定位难倒我了

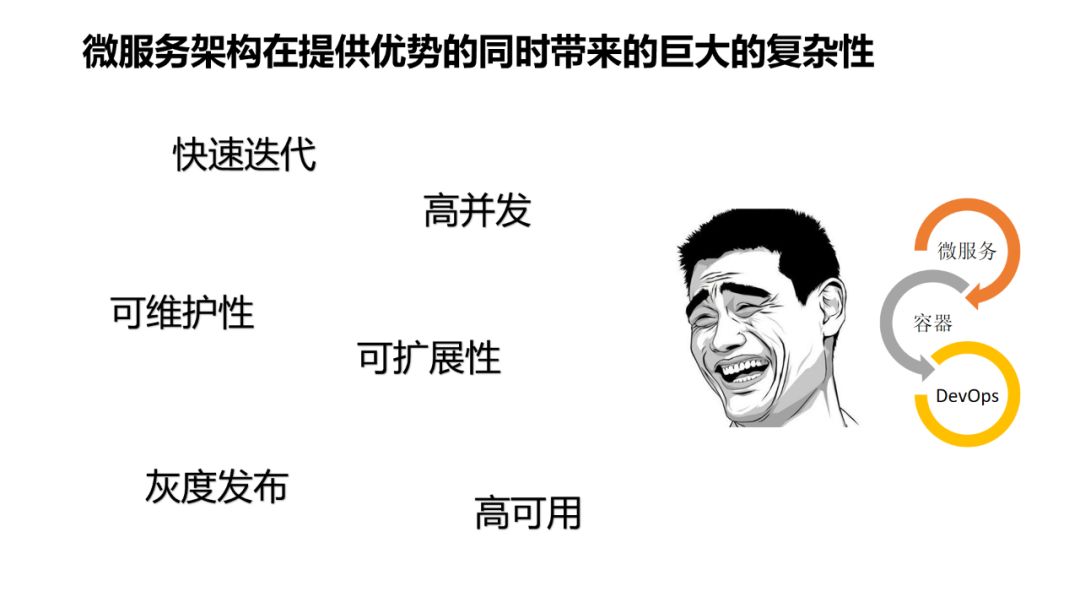

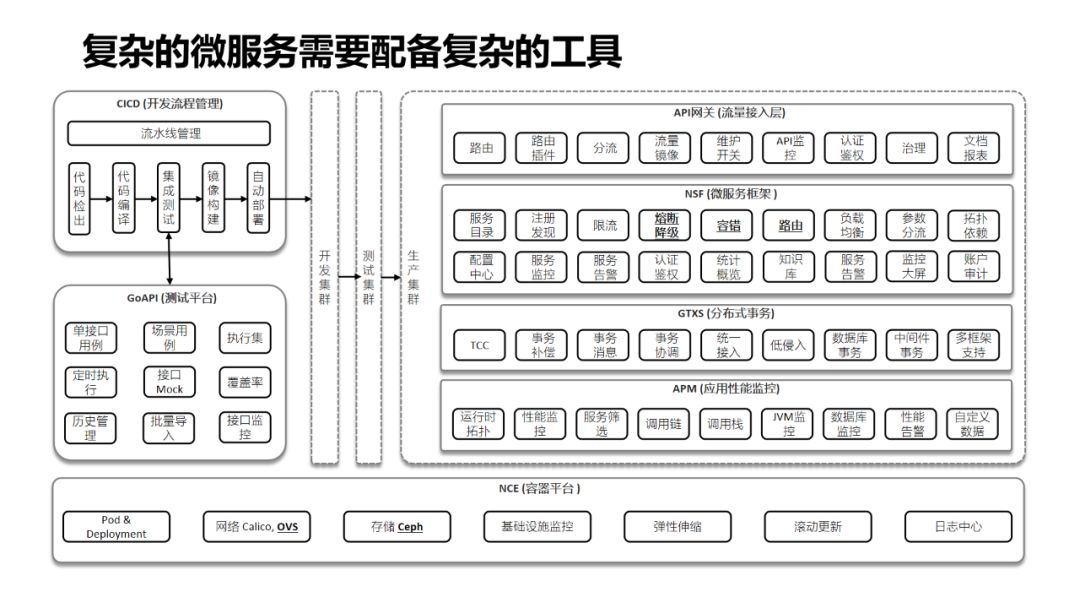
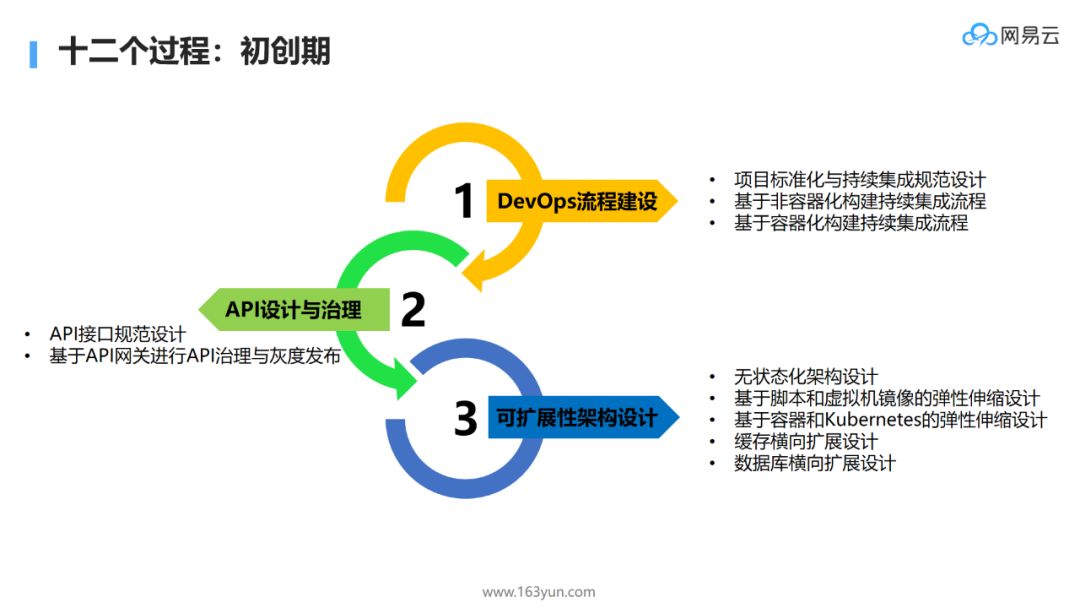
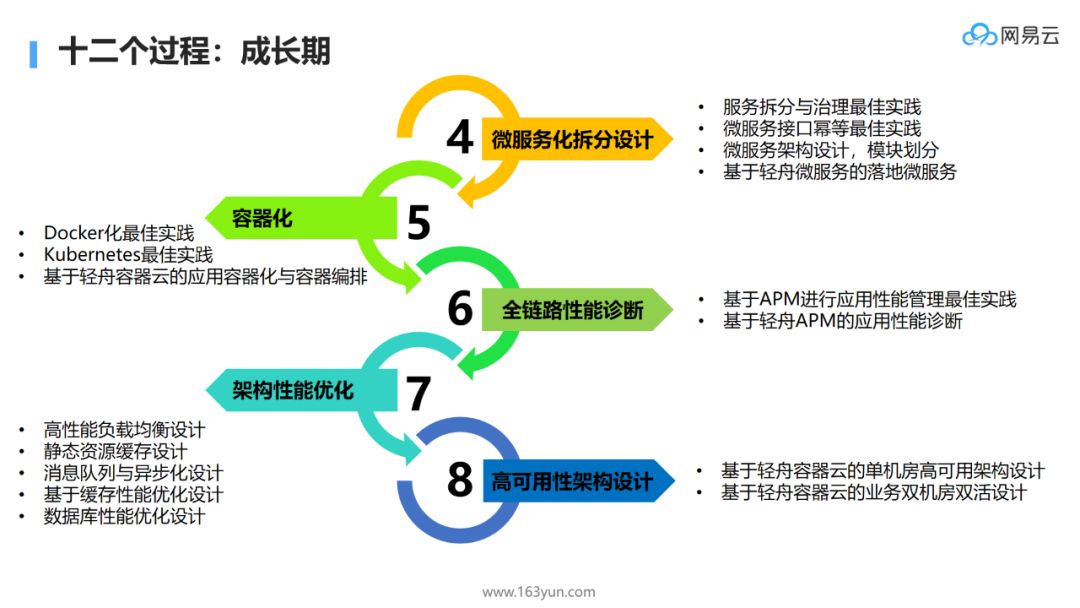
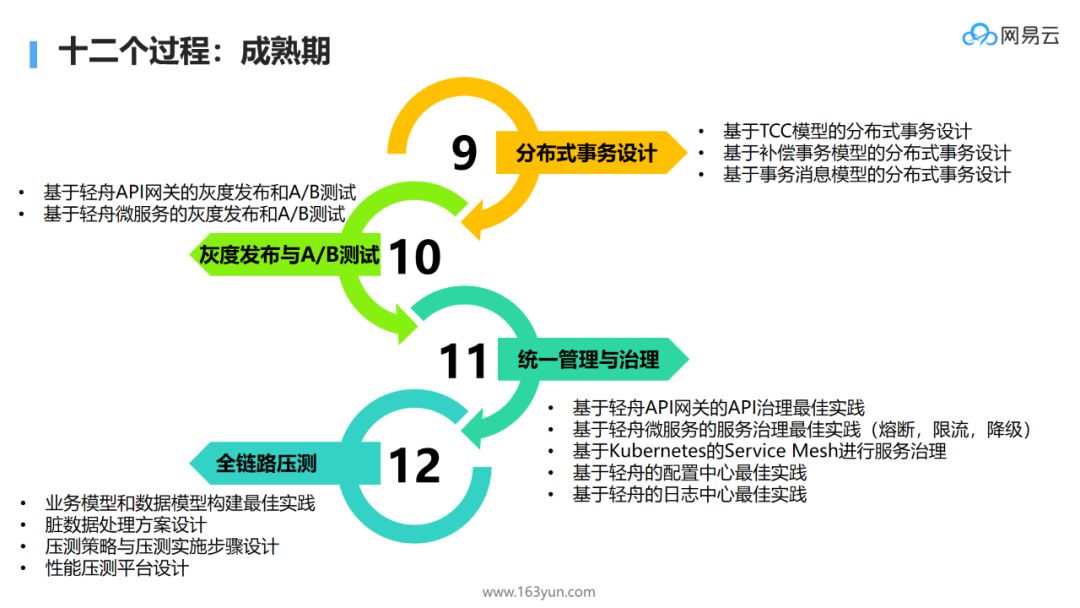
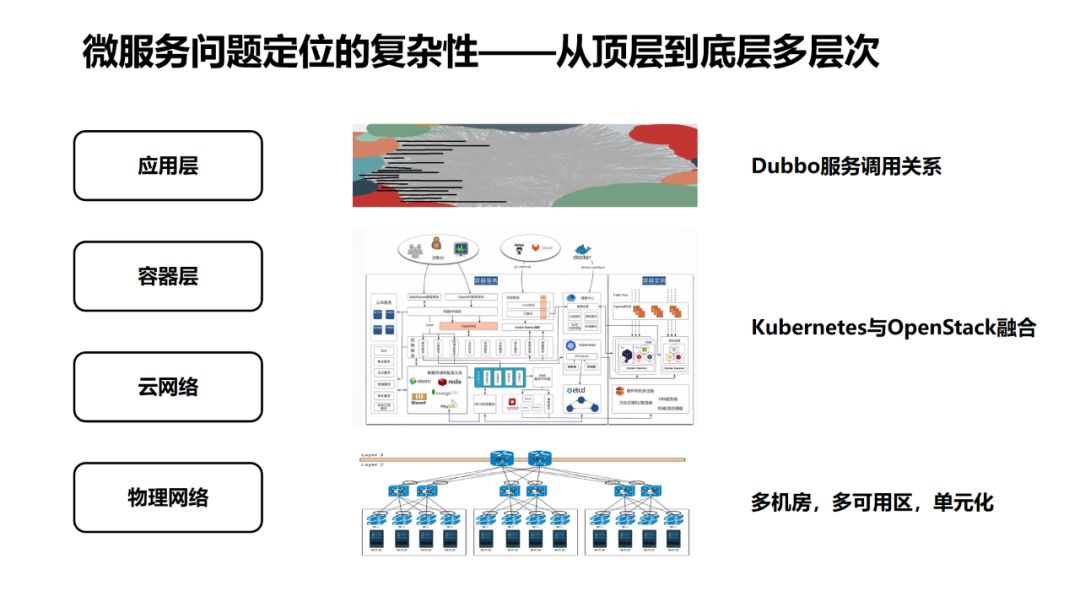
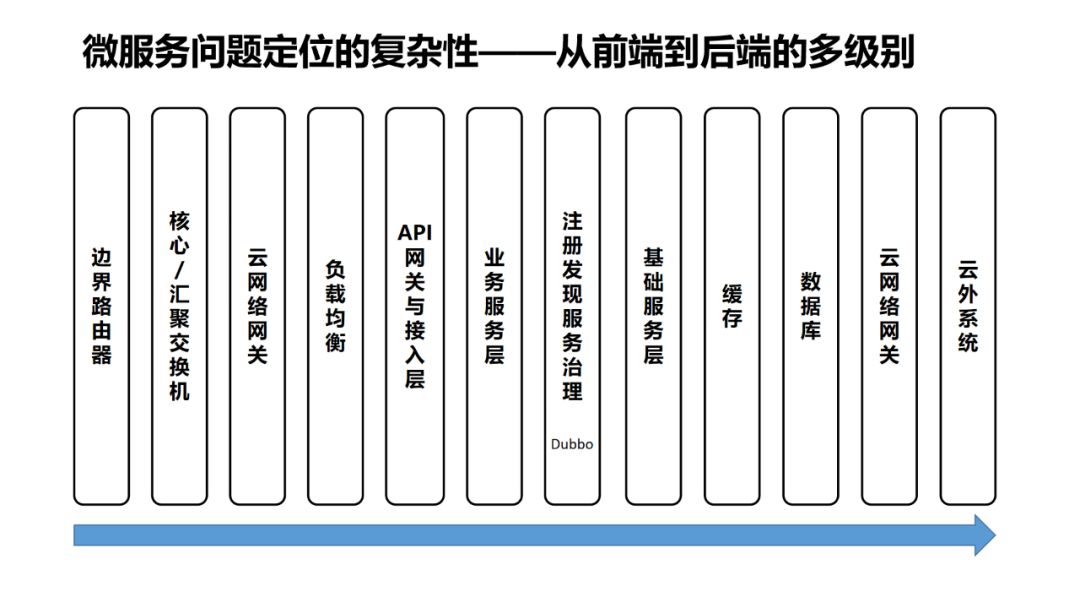
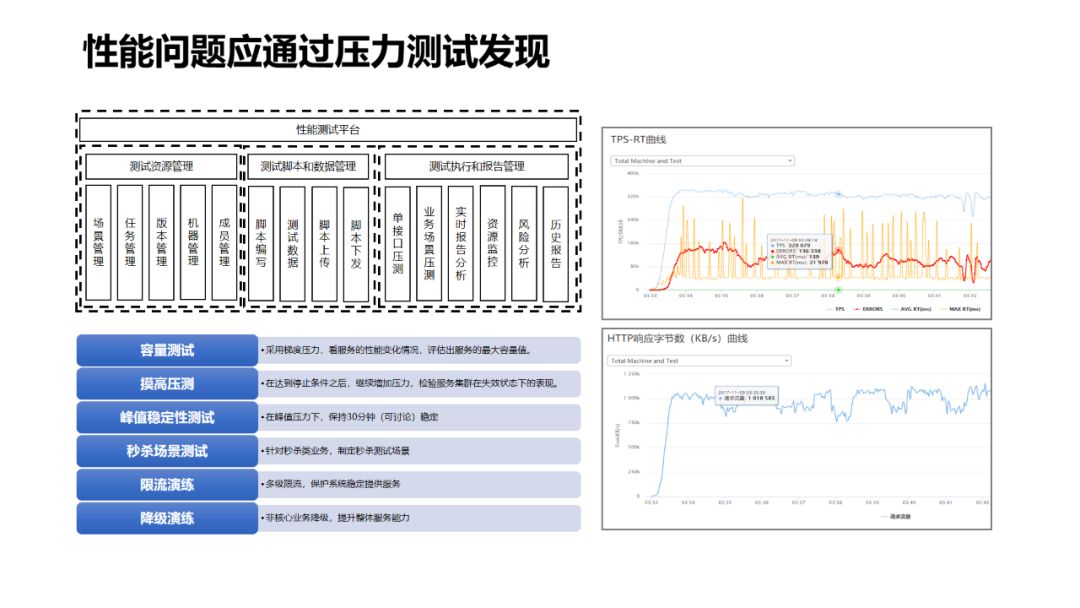
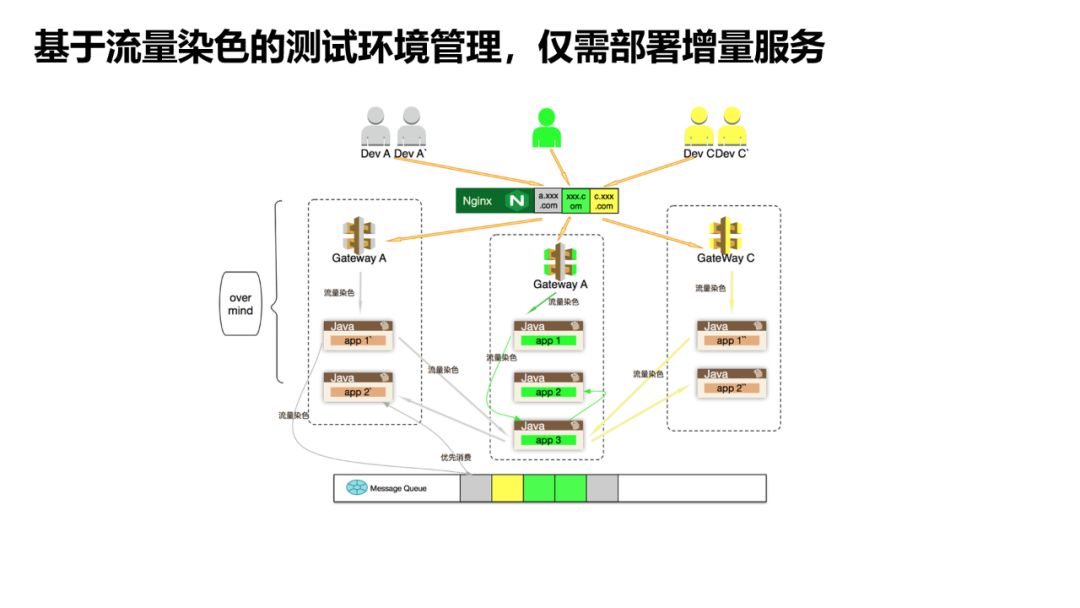
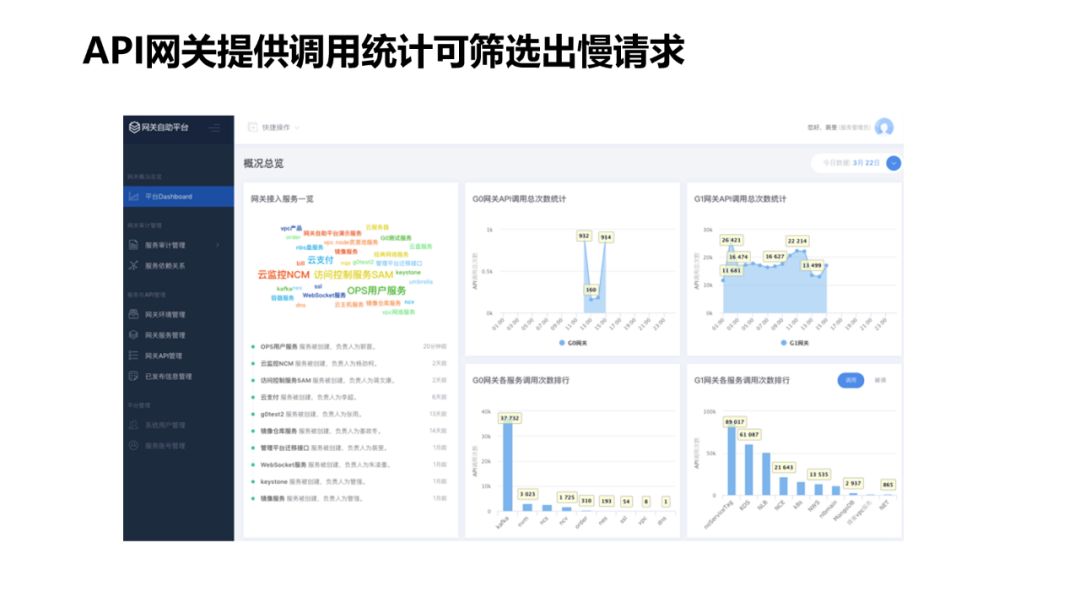

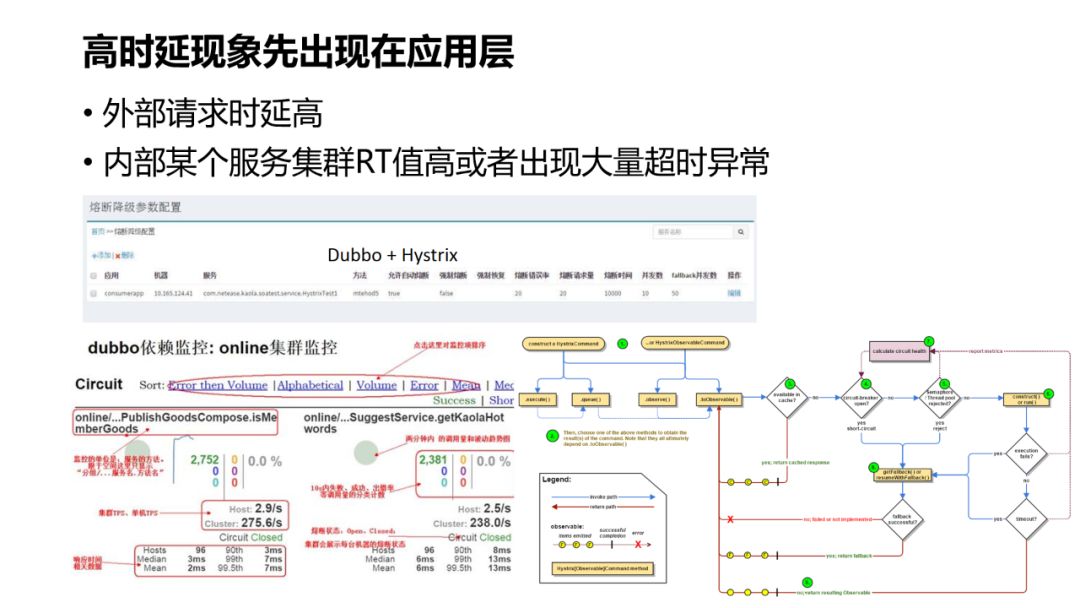
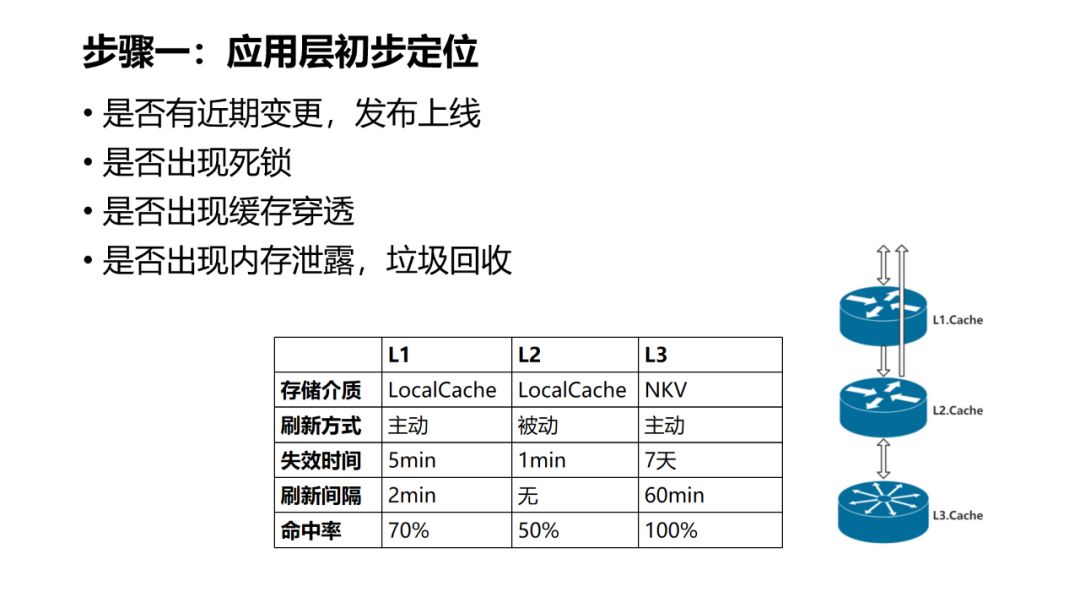

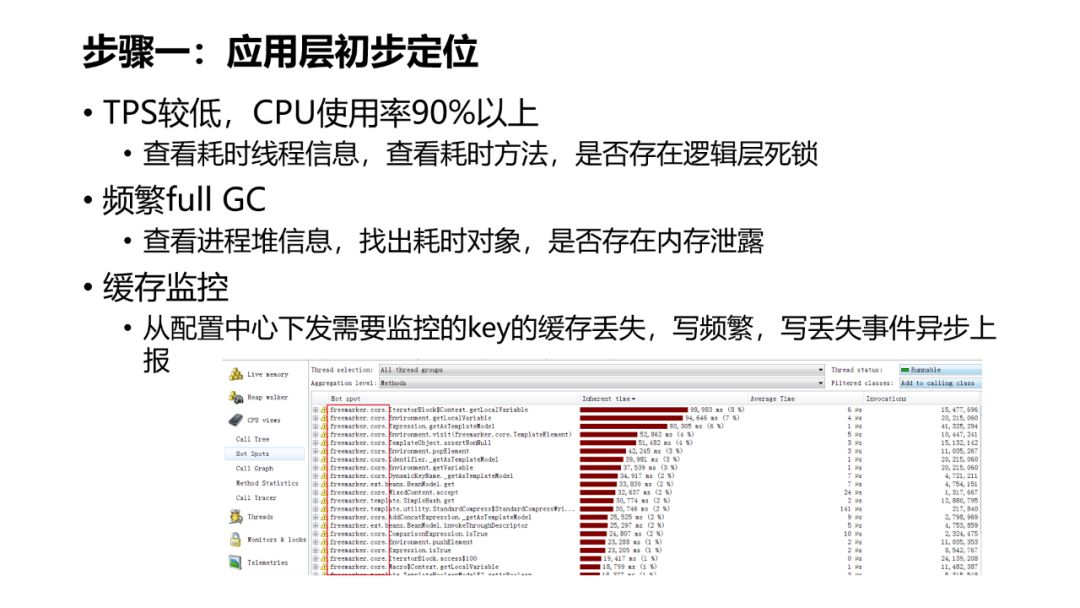


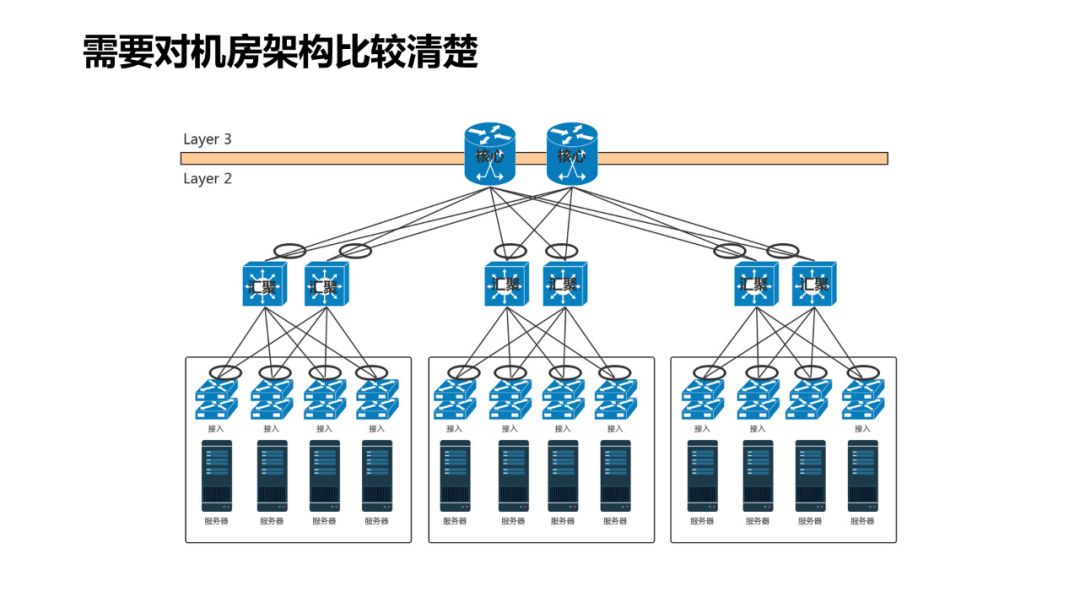
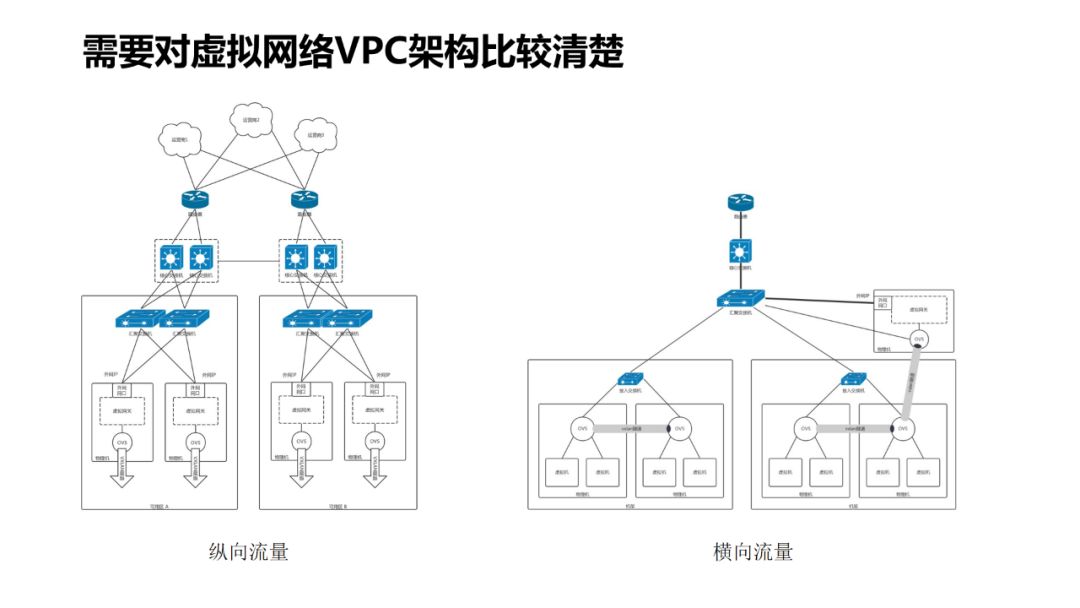
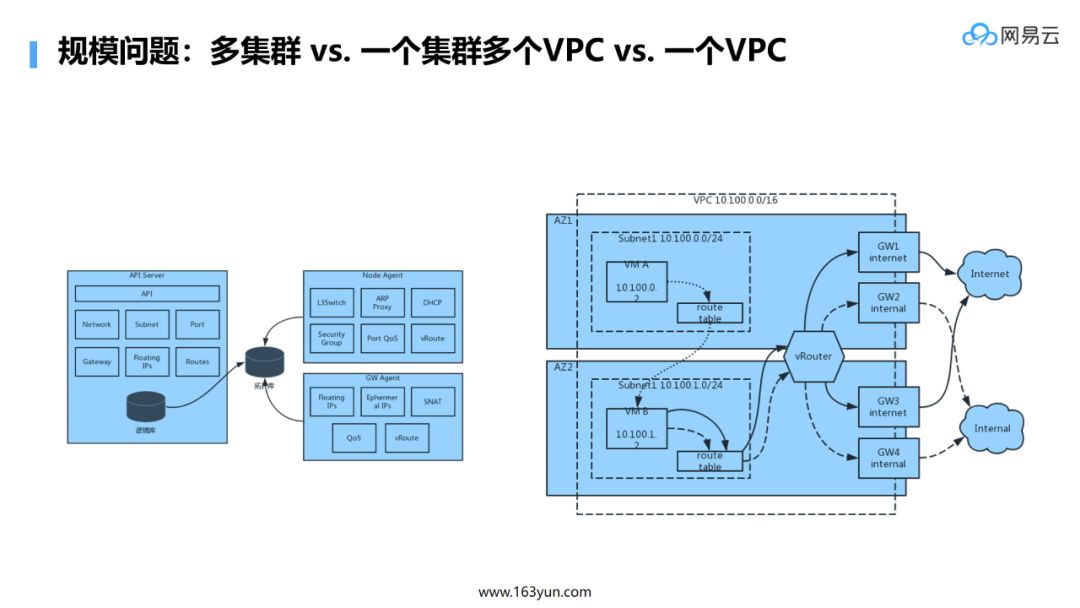
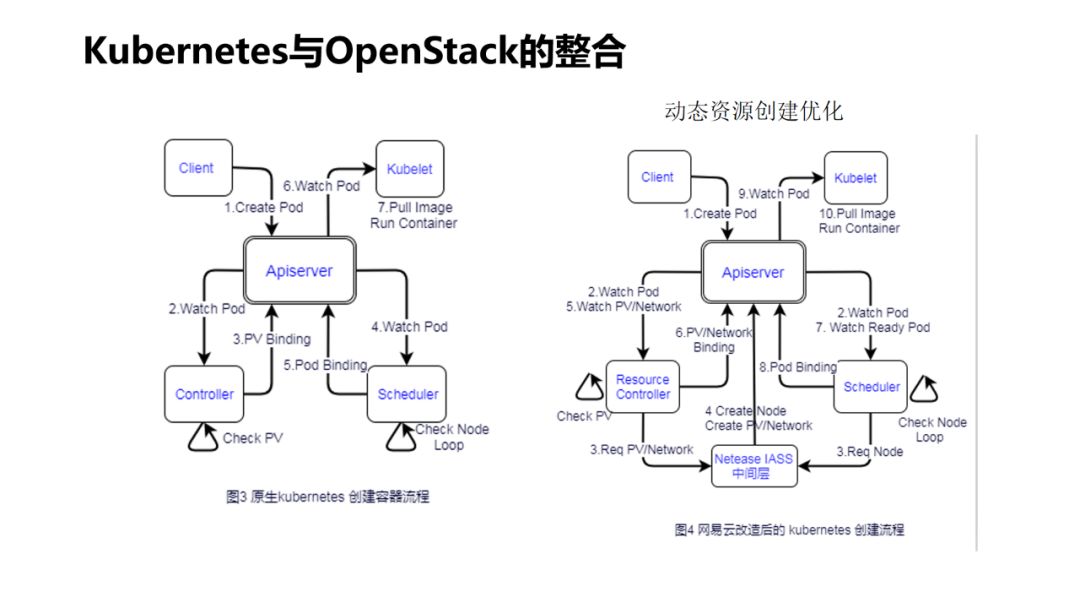
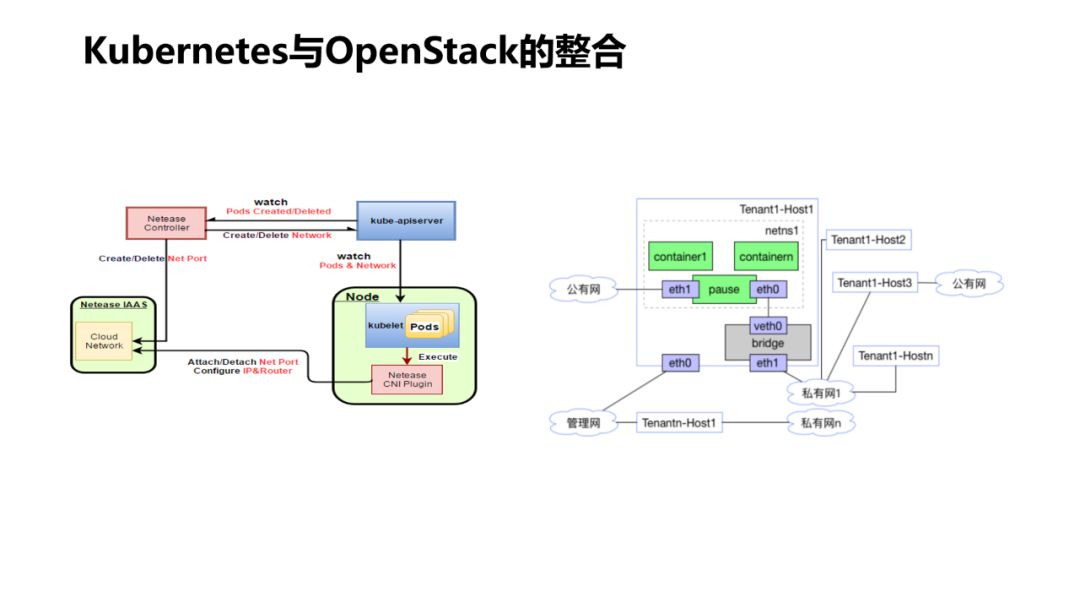
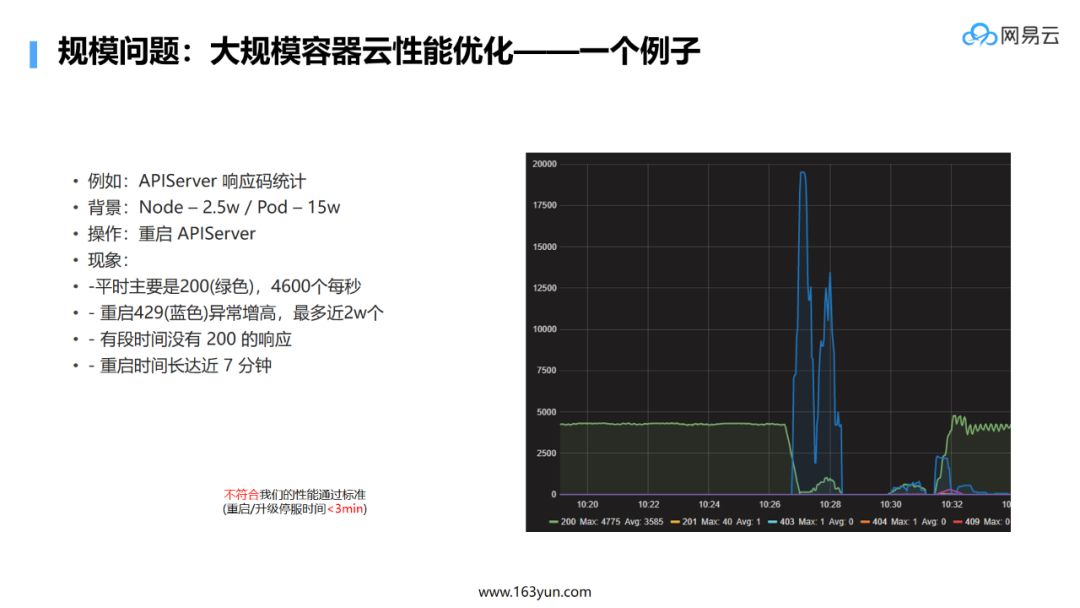
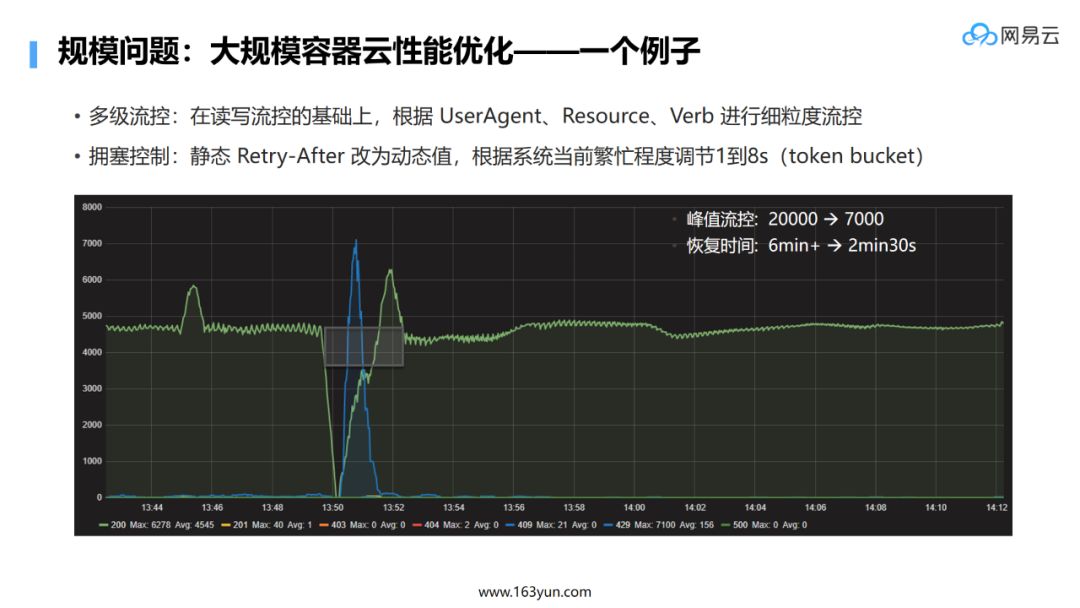
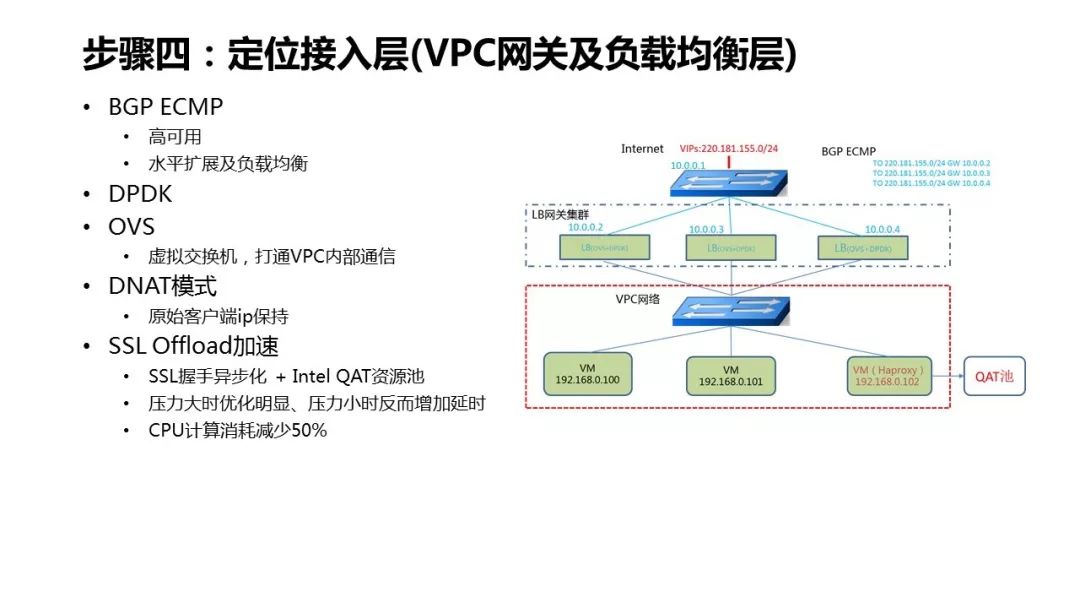
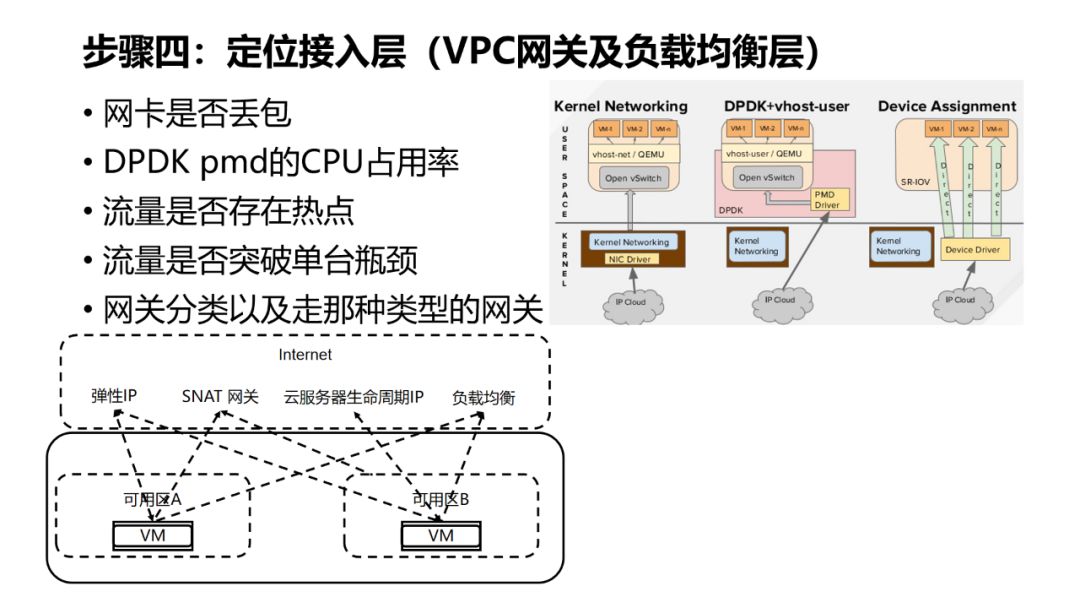
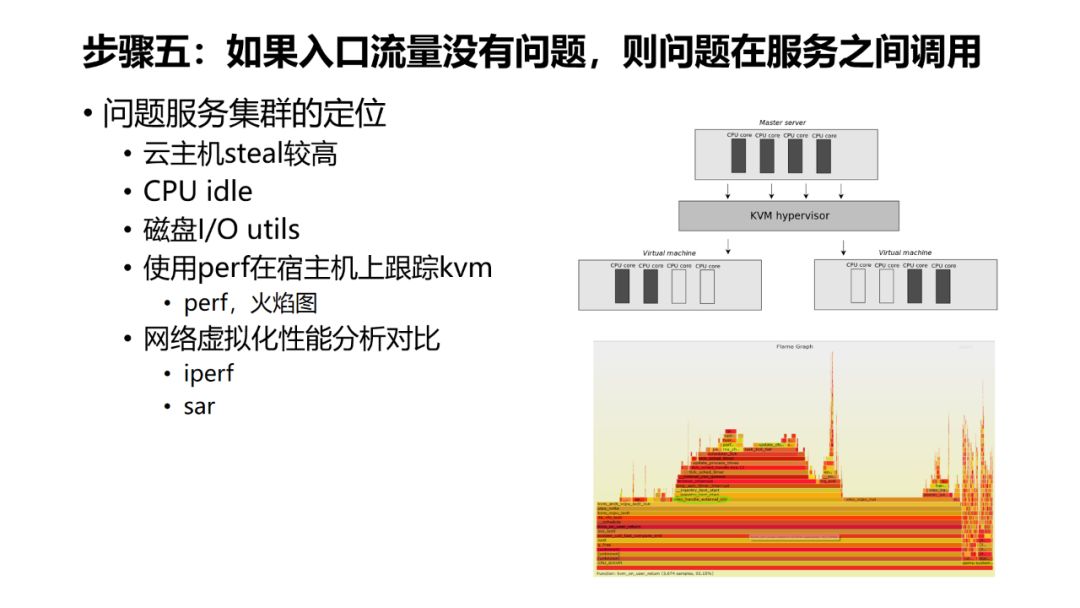
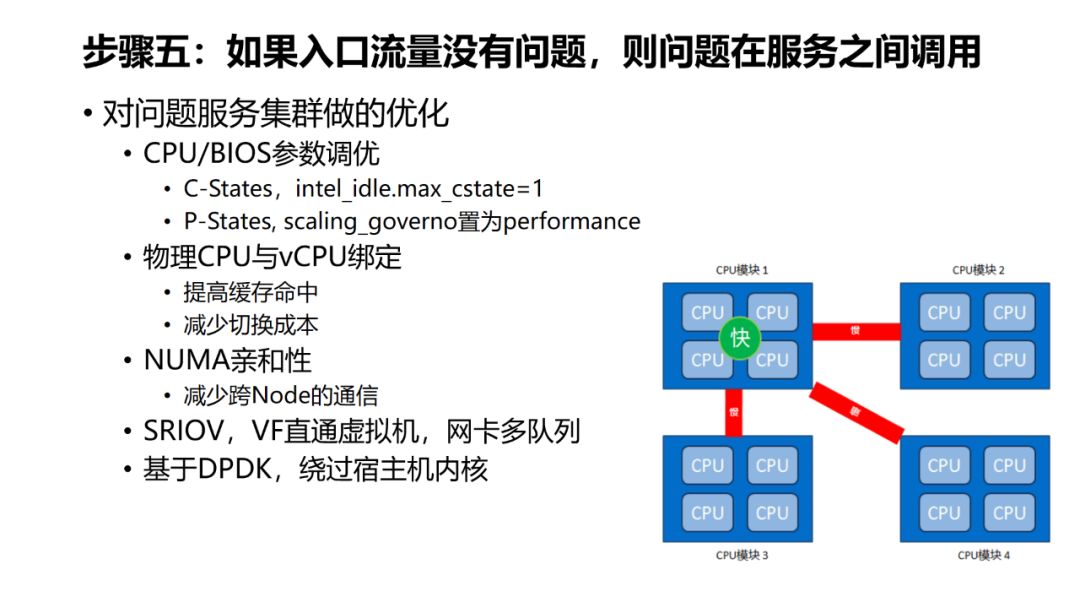





-
漫画:什么是希尔排序?
-
一次失败的面试,复习一次一致性哈希算法
Pandas中第二好用的函数 | 优雅的Apply
-
程序员因接外包坐牢 456 天!两万字揭露心酸经历
限时早鸟票 | 2019 中国大数据技术大会(BDTC)超豪华盛宴抢先看
阿里开源物联网操作系统 AliOS Things 3.0 发布,集成平头哥 AI 芯片架构!
-
雷声大雨点小:Bakkt「见光死」了吗?
登录查看更多
相关内容
Arxiv
3+阅读 · 2019年3月20日




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年3月20日