AlphaStar 称霸星际争霸2!AI史诗级胜利,DeepMind再度碾压人类
点击上方“公众号”可以订阅哦!

新智元报道
新智元报道
编辑:金磊、闻菲、张乾、索夫
【导读】DeepMind潜心两年打造的AlphaStar,以5比0的比分,决定性地击败了世界上最强大的职业星际争霸玩家之一,攻破了人类难度最高的游戏,又一个里程碑!
AlphaStar横空出世!
刚刚,DeepMind在推出AlphaGo之后,又把打造两年的AlphaStar推上历史的舞台,创造出第一个打败星际争霸2顶级职业选手的AI。
DeepMind昨晚放出在12月19日举行的一系列测试比赛录像,AlphaStar在与队友达里奥·温施(Dario " TLO " Wunsch)进行了一场成功的基准测试后,以5比0的比分,决定性地击败了世界上最强大的职业星际争霸玩家之一。
虽然在像雅达利、马里奥、雷神争霸3竞技场和Dota 2这样的电子游戏中,AI已经取得了巨大的成功,但直到现在,AI仍在努力应对星际争霸的复杂性。
《星际争霸2》由暴雪娱乐公司出品,故事背景设定在一个虚构的科幻世界中,具有丰富的多层次游戏玩法,旨在挑战人类的智力。因为高度复杂性和策略性,这款游戏成为史上规模最大、最成功的游戏之一,玩家在电子竞技比赛中竞争了20多年。
这次AI击败顶级选手,真正攻破了人类智力的最后阵地!
赛前,DeepMind召集了两位人类职业玩家选手,每位选手分别与AlphaStar对战五回合。而后在现场,人类与AI进行了最终的博弈,挽回了颜面,我们一起来看下。
这次终极1V1人机大战采用的地图是Catalyst LE,游戏版本为4.6.2。
与AlphaStar对战的人类选手,分别是TLO和MaNa。
TLO是现役职业选手德国人Dario Wünsch,所属荷兰战队 “Team Liquid”。他在2018年WSC Circuit中排名44。由于经常全力在Twitch直播,TLO在玩家中很出名。
另一位对战选手,是今年25岁的现役职业玩家“MaNa”,有波兰王牌之称。MaNa惯用神族,在刚刚结束的IEM科隆站比赛中,MaNa在小组赛中以2:1战胜了韩国选手Jaedong。
MaNa目前在2018 WSC Circuit上排名第13,他在去年WCS Austin中获得亚军,在2015年WCS第三季中也获得亚军。更早一些,MaNa得过Dreamhack2012夏季赛的冠军。

接下来是10场比赛录像中的精彩片段,以及现场的精彩打斗。
Round 1:7分钟,AlphaStar终结人类顶级玩家
开局,人类玩家率先派出农民一位,在AI家里来回探路。

2分50秒,人类玩家派出2名高阶圣堂开始了第一波骚扰,AlphaStar派出部分壮丁对其进行狙击剿灭。
随后人类玩家骚扰不断,与此同时AI也开始了反击,派出了一名追踪者攻击主基地。
而不知不觉中,AI已经攒出了6个追踪者,并大步迈向人类玩家分基地。
双方开始了第一波GANK,但LTO派出家里老少还算抵御住了这次攻击。然而,AI的补给兵已经到达战场。LTO已是无力回天。

Round2:人类玩家侵略性强,AI步步为营,精准计算
依旧,双方前期小打小闹不断,6分钟左右,AlphaStar率先派出10名追踪者对LTO进行攻击,人类玩家防御成功。
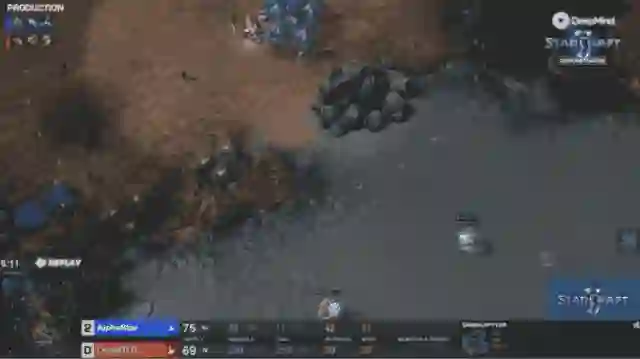
在此期间,AlphaStar做出了减少气体采集的策略。
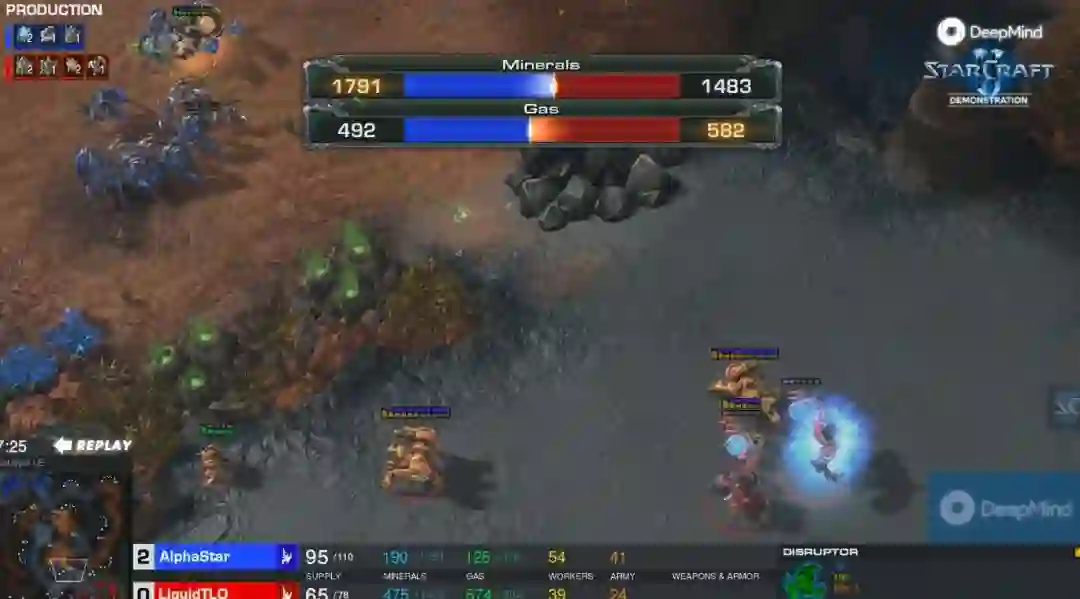
而后,人类玩家和AI都各自发展经济、制造兵种,在全场小范围迂回作战。
在14分时,致胜点出现了,看似人类玩家追打AI,却突然被其它两路而来的兵源切割,惨遭毒手。

人类玩家无力回天,AlphaStar再次取胜。
Round3-5:AlphaStar兵临城下,各路围剿,简直虐待
接下来播放的视频是另一位顶级人类玩家MaNa的战况。
来看下录播视频中的三段完虐场景吧。
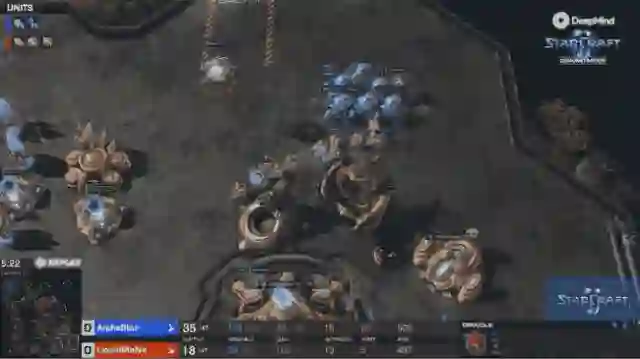
遛着农民绞杀。
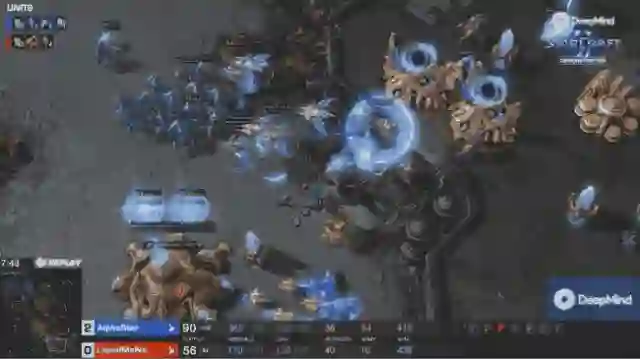
快推一波流。
三路围剿,兵败峡谷。
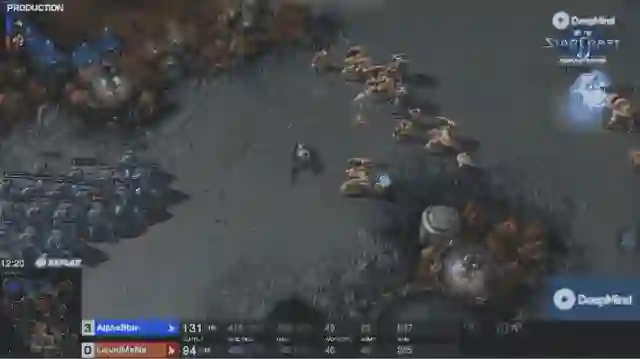
现场较量:人类玩家绝地大反击,将AI赶尽杀绝
可能是因为AI太厉害,人类需要证明自己的实力。最后,职业玩家MaNa在现场与AlphaStar实时较量了一场。
与录像相比,此次人类选手采取了较为保守的策略,选择发展经济、“招兵买马”;而AlphaStar则率先发起挑衅。
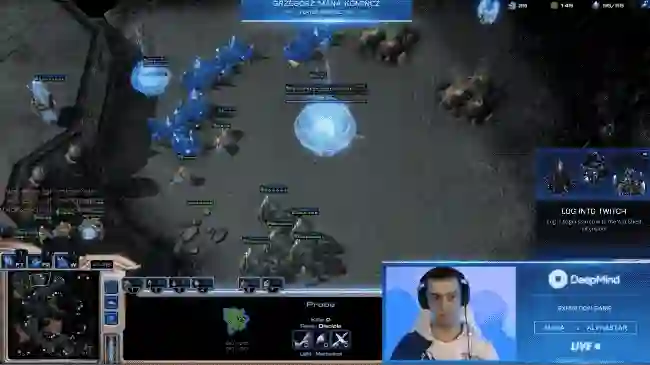
而且迂迂回回不断进行骚扰,基地周边以及探路的农民也遭到射杀。
在保守打法的基础上,MaNa已经积攒了一定的兵力,在发现AlphaStar兵力出巢瞬间,立即发动兵力进行攻击。同时也不忘建分基地,双线操作,十分稳。
而此时,AlphaStar的兵力并没有及时赶回救场,MaNa借此机会直接拆掉了分基地。
面对刚刚赶回的AlphaStar兵团,MaNa一顿操作猛如虎,直接击退其兵力,而后果断直捣黄龙。
最终,人类绝地反击,战胜了AI。
来自全球的看官瞬间不淡定了,评论区已然炸成锅——为人类的获胜欢呼雀跃——这或许也是为了挽回人类最后的颜面。
AlphaStar的行为是由一个深层神经网络生成的,该网络接收来自原始游戏interface的输入数据(单元及其属性的列表),并输出构成游戏内操作的指令序列。更具体地说,神经网络体系结构对单元应用一个转换器躯干,结合一个LSTM核心、一个带有指针网络的自回归策略头和一个集中的值基线。
DeepMind相信,这种先进的模型将有助于解决机器学习研究中涉及长期序列建模和大输出空间(如翻译、语言建模和视觉表示)的许多其他挑战。
AlphaStar还使用了一种新的多智能体学习算法。神经网络最初是由暴雪公司发布的匿名人类游戏中的监督学习训练出来的。这使得AlphaStar能够通过模仿StarCraft ladder上玩家使用的基本微观和宏观策略。这个最初的代理在95%的游戏中击败了内置的“精英”AI关卡——即人类玩家的黄金关卡。
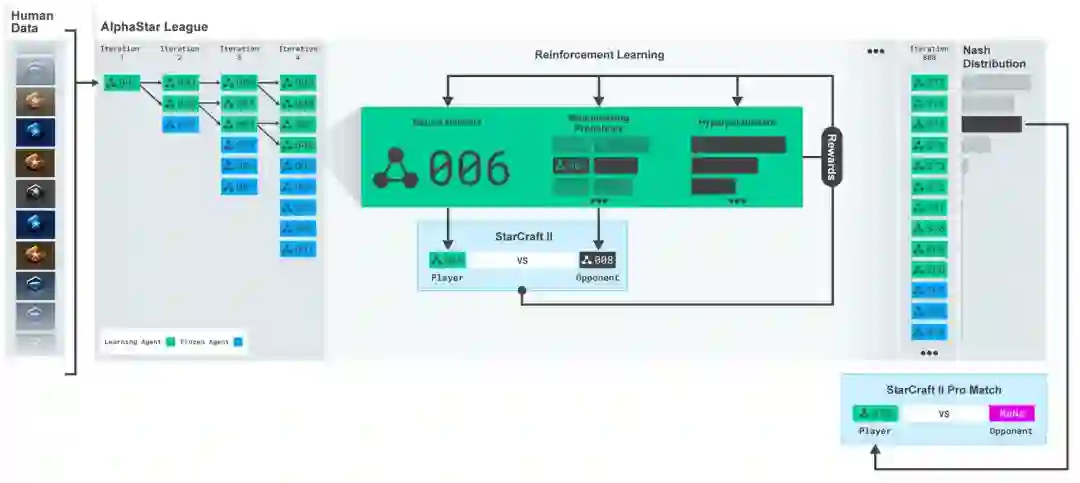
然后用它们来建立一个多主体强化学习过程。一个连续的联盟被创造出来,联盟的代理——竞争者——相互之间玩游戏,就像人类在StarCraft ladder玩游戏一样。
新的竞争者通过从现有竞争者中进行分支,动态地添加到联盟中;然后每个代理从与其他竞争对手的游戏中学习。这种新的训练形式将基于人群的强化学习理念进一步发扬光大,创造了一个不断探索《星际争霸》游戏玩法巨大战略空间的过程,同时确保每个竞争对手都能在最强的战略面前表现出色,并且不会忘记如何击败较早的战略。
随着联赛的发展和新的竞争对手的产生,新的对抗策略出现了,能够击败以前的策略。当一些新的竞争者执行一个仅仅是对以前的策略的改进的策略时,另一些人发现了包含全新构建订单、单元组合和微观管理计划的全新策略。
例如,在AlphaStar联盟早期,一些“俗套”的策略,如使用光子炮或黑暗圣堂武士进行非常快速的快攻,受到了玩家的青睐。随着训练的进行,这些冒险的策略被抛弃了,产生了其他的策略:例如,通过过度扩张拥有更多工人的基地来获得经济实力,或者牺牲两个神谕来破坏对手的工人和经济。这一过程类似于《星际争霸》发行多年以来玩家发现新策略并能够击败之前所青睐的方法的过程。
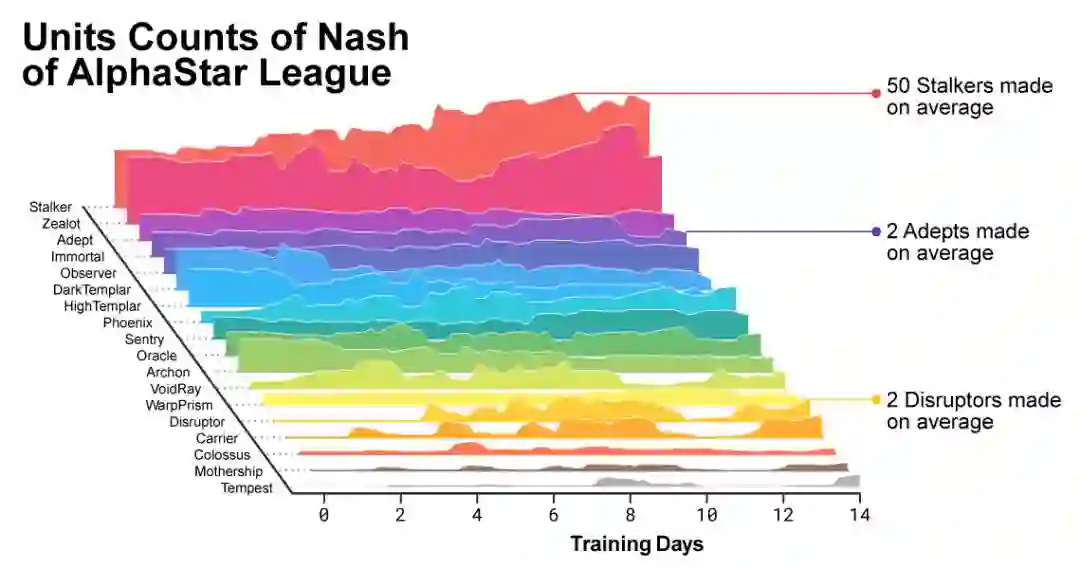
为了鼓励联盟的多样性,每个代理都有自己的学习目标:例如,这个代理的目标应该是打败哪些竞争对手,以及影响代理如何发挥的任何其他内部动机。一个代理可能有打败某个特定竞争对手的目标,而另一个代理可能必须打败整个竞争对手分布,但这是通过构建更多特定的游戏单元来实现的。这些学习目标在培训过程中得到了调整。
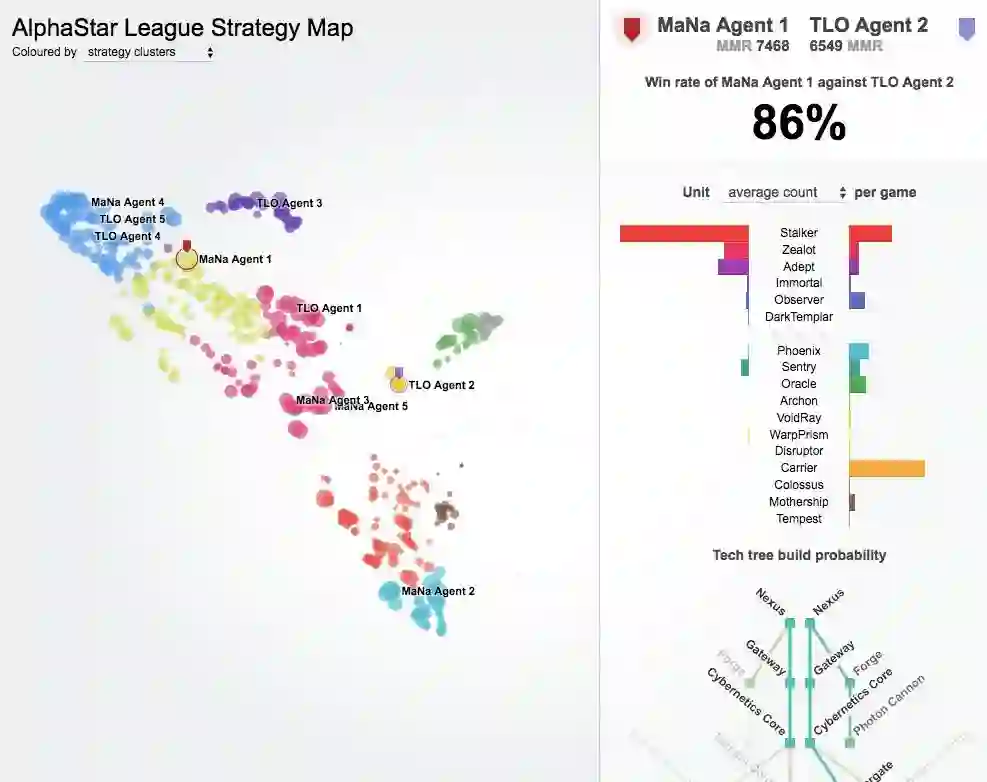
最好的结果可能是通过手工制作系统的主要元素,对游戏规则施加重大限制,赋予系统超人的能力,或者在简化的地图上进行游戏。即使有了这些改进,也没有一个系统能与职业选手的技术相媲美。相比之下,AlphaStar在星际争霸2中玩的是完整的游戏,它使用的深度神经网络是通过监督学习和强化学习直接从原始游戏数据中训练出来的。
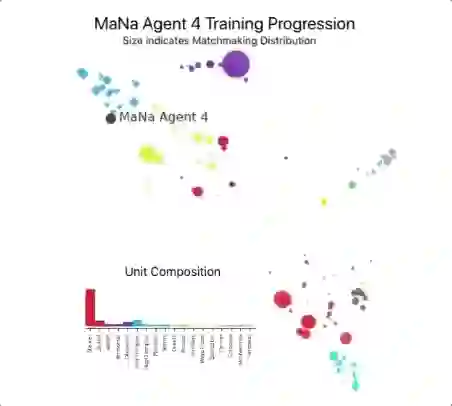
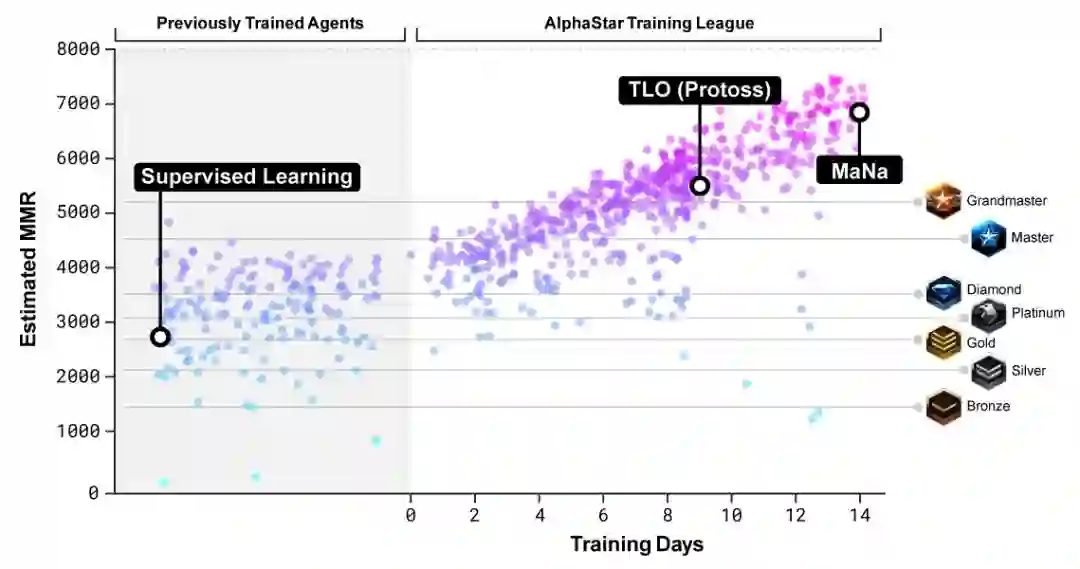
为了训练AlphaStar,DeepMind使用谷歌的v3版本的TPU构建了一个高度可伸缩的分布式训练设置,它支持大量代理从数以千计的星际争霸2并行实例中学习。AlphaStar联赛运行了14天,每个代理使用16个TPU。在训练期间,每个代理都经历了长达200年的星际争霸实时游戏。最终的AlphaStar代理由联盟的Nash分布组成——换句话说,已经发现的最有效的策略组合——运行在单个桌面GPU上。
另外,这项工作的论文也即将发布。
讲完AlphaStar的训练过程,再来分析下实战过程。
像TLO和MaNa这样的职业星际争霸玩家,平均每分钟可以做数百个操作(APM)。这远远少于大多数现有的机器人,它们独立控制每个单元,并始终保持数千甚至数万个APM。
在与TLO和MaNa的比赛中,AlphaStar的平均APM约为280,远低于职业选手,不过它的动作可能更精确。
造成APM较低的部分原因是AlphaStar使用回放开始训练,因此模仿了人类玩游戏的方式。此外,AlphaStar的反应在观察和行动之间的平均延迟350ms。
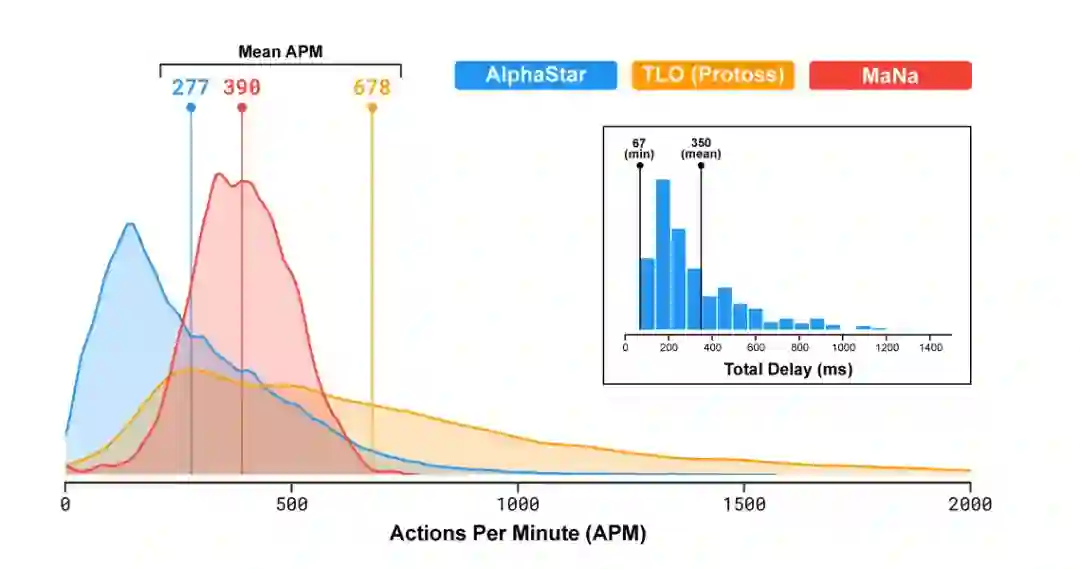
在与TLO和MaNa对弈过程中,AlphaStar通过原始界面与星际争霸2引擎连接,这就意味着它可以直接在地图上观察自己的属性和对手的可见单位,而无需移动相机。
相比之下,人类玩家必须明确管理“注意力经济(economy of attention)”,并决定在哪里对焦相机。
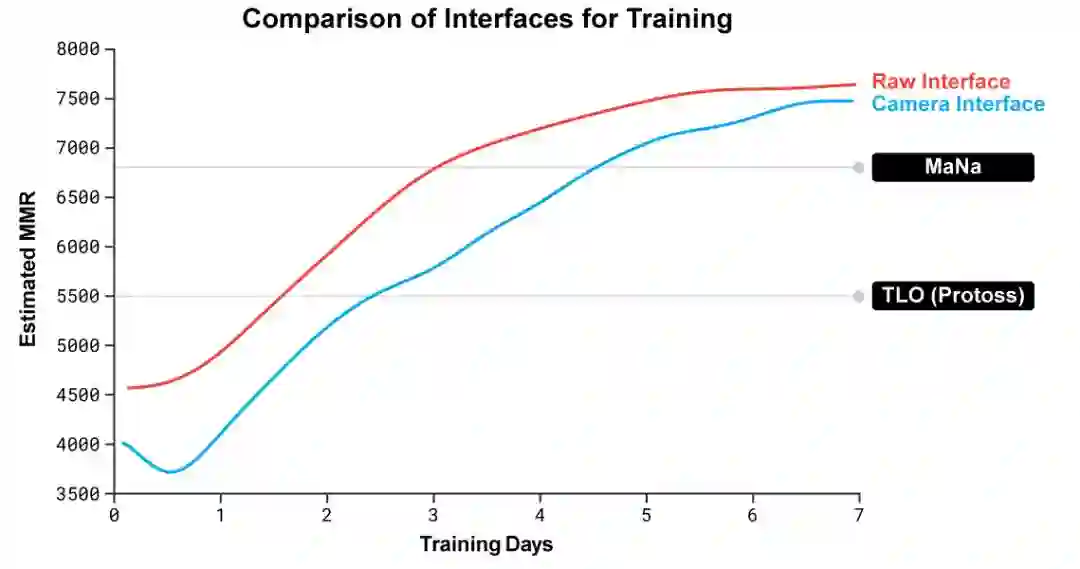
然而,对AlphaStar游戏的分析表明,它管理着一种隐性的注意力焦点。平均而言,智能体每分钟“切换内容”约30次,类似于MaNa或TLO的操作。
此外,在比赛之后,DeepMind还开发了AlphaStar的第二个版本。和人类玩家一样,这个版本的AlphaStar会选择何时何地移动摄像头,它的感知仅限于屏幕上的信息,行动地点也仅限于它的可视区域。
DeepMind训练了两个新智能体,一个使用raw interface,另一名必须学会控制摄像头,以对抗AlphaStar League。
每个智能体最初都是通过从人类数据中进行监督学习,然后按照强化学习过程进行训练的。使用摄像头界面的AlphaStar版本几乎和raw interface一样强大,在DeepMind内部排行榜上超过了7000 MMR。
在表演赛中,MaNa用camera interface击败了AlphaStar的一个原型版本,这个interface只训练了7天。
这些结果表明,AlphaStar对MaNa和TLO的成功实际上是由于优越的宏观和微观战略决策,而不是快速的操作、更快的反应时间或raw interface。
游戏规则规定,玩家必须选择三种不同的外星“种族”中的一种——虫族、神族或人族,它们都有各自的特点和能力(尽管职业玩家往往只专注于一种种族)。每个玩家从一些工作单元开始,收集基本资源来构建更多的单元和结构并创造新技术,这些反过来又允许玩家获取其他资源,建立更复杂的基地和结构,并开发新的能力,可以用来智胜对手。
游戏的难度在于,要想取胜,玩家必须在宏观经济的宏观管理和微观个体的控制之间保持谨慎的平衡。
平衡短期和长期目标以及适应意外情况的需要对往往脆弱和缺乏灵活性的系统提出了巨大的挑战。要想解决这个问题,需要突破AI研究的几个挑战,包括:
游戏理论:《星际争霸》是一款像剪刀石头布一样是没有最佳策略的游戏。因此,AI过程需要不断探索和拓展战略知识的前沿。
不完全信息:不像国际象棋或围棋那样,玩家什么信息都能看到,关键信息对星际玩家是隐藏的,必须通过“侦察”来主动发现。
长期规划:像许多现实世界中的问题一样,因果关系不是瞬间产生的。游戏也可以在任何地方花费一个小时完成,这意味着在游戏早期采取的行动可能在很长一段时间内都不会有回报。
实时:不像传统的棋类游戏,玩家在接下来的动作之间交替,《星际争霸》玩家必须随着游戏时间的推移不断地执行动作。
大型活动空间:数百个不同的单元和建筑必须同时被实时控制,从而形成一个可能性组合空间。
正是由于这些巨大的挑战,星际争霸已经成为人工智能研究的“大挑战”。自2009年发布BroodWar API以来,《星际争霸》和《星际争霸2》的竞赛一直在进行,包括AIIDE星际争霸AI竞赛、CIG星际争霸竞赛、学生星际争霸AI竞赛和《星际争霸2》AI阶梯赛。
DeepMind在2016年和2017年与暴雪合作发布了一套名为PySC2的开源工具,其中包括有史以来最大的一组匿名游戏回放。
现在,经过两年的打造,继AlphaGo之后,DeepMind刚刚问世的AlphaStar已经取得了飞速进展。
注:投稿请电邮至124239956@qq.com ,合作 或 加入未来产业促进会请加:www13923462501 微信号或者扫描下面二维码:

文章版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将删除内容或协商版权问题!联系QQ:124239956




